MyBatis-Plus使用笔记(二):MyBatis-Plus增删改查、Wapper条件查询、分页、逻辑删除、性能分析、
一、insert
1、插入操作
测试:
@SpringBootTest
class MybatisPlusApplicationTests {
@Autowired
UserMapper userMapper;
@Test
void insertUser() {
User user = new User();
user.setName("Ada");
user.setAge(30);
user.setEmail("[email protected]");
int i = userMapper.insert(user);
System.out.println("insert : " + i);
}
}结果:
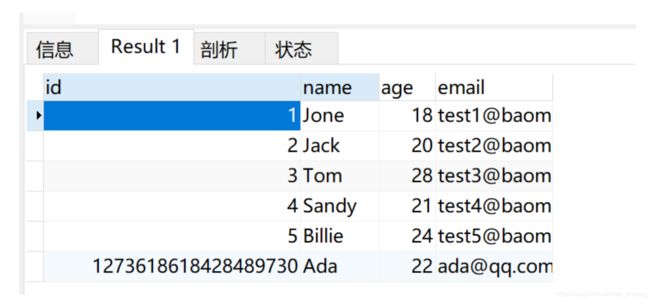
**注意:**数据库插入id值默认为:全局唯一id(雪花算法生成,下面会介绍)
2、常见主键生成策略
1)数据库自增长序列或字段
最常见的方式。利用数据库,全数据库唯一。
优点:
- 简单,代码方便,性能可以接受。
- 数字ID天然排序,对分页或者需要排序的结果很有帮助。
缺点:
- 在单个数据库或读写分离或一主多从的情况下,只有一个主库可以生成。有单点故障的风险。
- 如果遇见多个系统需要合并或者涉及到数据迁移会相当痛苦。
- 分表分库的时候会有麻烦。
2)UUID
常见的方式。可以利用数据库也可以利用程序生成,一般来说全球唯一。
优点:
- 简单,代码方便。
- 生成ID性能非常好,基本不会有性能问题。
- 全球唯一,在遇见数据迁移,系统数据合并,或者数据库变更等情况下,可以从容应对。
缺点:
- 没有排序,无法保证趋势递增
- UUID往往是使用字符串存储,查询的效率比较低。
- 存储空间比较大,如果是海量数据库,就需要考虑存储量的问题。
- 传输数据量大
3)Redis生成ID
当使用数据库来生成ID性能不够要求的时候,我们可以尝试使用Redis来生成ID。这主要依赖于Redis是单线程的,所以也可以用生成全局唯一的ID。可以用Redis的原子操作 INCR和INCRBY来实现。
可以使用Redis集群来获取更高的吞吐量。假如一个集群中有5台Redis。可以初始化每台Redis的值分别是1,2,3,4,5,然后步长都是5。各个Redis生成的ID为:
A:1,6,11,16,21
B:2,7,12,17,22
C:3,8,13,18,23
D:4,9,14,19,24
E:5,10,15,20,25
优点:
- 不依赖于数据库,灵活方便,且性能优于数据库。
- 数字ID天然排序,对分页或者需要排序的结果很有帮助。
缺点:
- 如果系统中没有Redis,还需要引入新的组件,增加系统复杂度。
- 需要编码和配置的工作量比较大。
4)Twitter的snowflake算法
snowflake是Twitter开源的分布式ID生成算法,结果是一个long型的ID。其核心思想是:使用41bit作为毫秒数,10bit作为机器的ID(5个bit是数据中心,5个bit的机器ID),12bit作为毫秒内的流水号(意味着每个节点在每毫秒可以产生 4096 个 ID),最后还有一个符号位,永远是0。具体实现的代码可以参看https://github.com/twitter-archive/snowflake/releases/tag/snowflake-2010
snowflake算法可以根据自身项目的需要进行一定的修改。比如估算未来的数据中心个数,每个数据中心的机器数以及统一毫秒可以能的并发数来调整在算法中所需要的bit数。
优点:
- 不依赖于数据库,灵活方便,且性能优于数据库。
- ID按照时间在单机上是递增的。
缺点:
- 在单机上是递增的,但是由于涉及到分布式环境,每台机器上的时钟不可能完全同步,也许有时候也会出现不是全局递增的情况。
3、MP的主键生成策略
1)ID_WORKER
MyBatis-Plus默认的主键策略是:ID_WORKER 全局唯一ID(雪花算法)
2)自增策略
要想主键自增需要配置如下主键策略:
- 需要在创建数据表的时候设置主键自增
- 实体字段中配置 @TableId(type = IdType.AUTO)
@TableId(type = IdType.AUTO)
private Long id;要想影响所有实体的配置,可以设置全局主键配置
#全局设置主键生成策略
mybatis-plus.global-config.db-config.id-type=auto
其它主键策略:分析 IdType 源码可知:
public enum IdType {
/**
* 数据库ID自增
*/
AUTO(0),
/**
* 该类型为未设置主键类型
*/
NONE(1),
/**
* 用户输入ID
* 该类型可以通过自己注册自动填充插件进行填充
*/
INPUT(2),
/* 以下3种类型、只有当插入对象ID 为空,才自动填充。 */
/**
* 全局唯一ID (idWorker)
*/
ID_WORKER(3),
/**
* 全局唯一ID (UUID)
*/
UUID(4),
/**
* 字符串全局唯一ID (idWorker 的字符串表示)
*/
ID_WORKER_STR(5);
private final int key;
IdType(int key) {
this.key = key;
}
}二、update
1、根据Id更新操作
@Autowired
UserMapper userMapper;
@Test
void updateUser() {
User user = new User();
user.setId(2L);
user.setAge(120);
int row = userMapper.updateById(user);
System.out.println(row);
}此时自动生成的SQL语句为:UPDATE user SET age=? WHERE id=?
2、自动填充
项目中经常会遇到一些数据,每次都使用相同的方式填充,例如记录的创建时间,更新时间等。
我们可以使用MyBatis Plus的自动填充功能,完成这些字段的赋值工作:
1)数据库表中添加自动填充字段
在User表中添加datetime类型的新的字段 create_time、update_time
2)实体类上添加属性以及注解
@Data
public class User {
...
//注意使用小驼峰,框架会自动将下划线转为小驼峰
//设置自动填充时机
@TableField(fill = FieldFill.INSERT)
private Date createTime;
@TableField(fill = FieldFill.INSERT_UPDATE)
private Date updateTime;
}3)实现元对象处理器接口
@Component
public class MyMetaObjectHandler implements MetaObjectHandler {
//使用mp实现添加的自动填充时,这个方法就会执行
@Override
public void insertFill(MetaObject metaObject) {
this.setFieldValByName("createTime", new Date(), metaObject);
this.setFieldValByName("updateTime", new Date(), metaObject);
}
//使用mp实现更新的自动填充时,这个方法就会执行
@Override
public void updateFill(MetaObject metaObject) {
this.setFieldValByName("updateTime", new Date(), metaObject);
}
}注意:不要忘记添加 @Component 注解
4)测试
添加:
@Test
void insertUser() {
User user = new User();
user.setName("Eva");
user.setAge(22);
user.setEmail("[email protected]");
int i = userMapper.insert(user);
System.out.println("insert : " + i);
}
修改:
@Test
void updateUser() {
User user = new User();
user.setId(1273807629415706625L);
user.setAge(22);
int row = userMapper.updateById(user);
System.out.println(row);
}
3、乐观锁
**主要适用场景:**当要更新一条记录的时候,希望这条记录没有被别人更新,也就是说实现线程安全的数据更新
乐观锁实现方式:
- 取出记录时,获取当前version
- 更新时,带上这个version
- 执行更新时,
set version = newVersion where version = oldVersion - 如果version不对,就更新失败

1)数据库中添加version字段
ALTER TABLE `user` ADD COLUMN `version` INT2)实体类添加version字段
并添加 @Version 注解
@Version
@TableField(fill = FieldFill.INSERT)
private Integer version; //版本号,用于乐观锁3)元对象处理器接口添加version的insert默认值
//使用mp实现添加的自动填充时,这个方法就会执行
@Override
public void insertFill(MetaObject metaObject) {
this.setFieldValByName("version", 1, metaObject);
...
}特别说明:
- 支持的数据类型只有 int,Integer,long,Long,Date,Timestamp,LocalDateTime
- 整数类型下
newVersion = oldVersion + 1 newVersion会回写到entity中- 仅支持
updateById(id)与update(entity, wrapper)方法 - 在
update(entity, wrapper)方法下,wrapper不能复用!!!
4)创建配置类 MybatisPlusConfig 并注册 Bean
//不要忘了@Configuration注解
@Configuration
@MapperScan("cn.hanzhuang42.mybatisplus.mapper")
public class MyBatisPlusConfig {
/**
*乐观锁插件
*/
@Bean
public OptimisticLockerInterceptor optimisticLockerInterceptor() {
return new OptimisticLockerInterceptor();
}
}5)测试乐观锁
插入数据:
@Test
void insertUser() {
User user = new User();
user.setName("奎托斯");
user.setAge(99);
user.setEmail("[email protected]");
int i = userMapper.insert(user);
System.out.println("insert : " + i);
}
更新数据:
@Test
void testOptimisticLocker() {
//先查询
User user = userMapper.selectById(1273814734310735873L);
//再修改
user.setAge(200);
userMapper.updateById(user);
}
三、select
1、根据id查询记录
@Test
void testOptimisticLocker() {
//先查询
User user = userMapper.selectById(1273814734310735873L);
//再修改
user.setAge(200);
userMapper.updateById(user);
}2、通过多个id批量查询
//多个id批量查询
@Test
void testSelectBatch(){
List<User> users = userMapper.selectBatchIds(Arrays.asList(1, 2, 3));
System.out.println(users);
}SQL语句用的时IN
==> Preparing: SELECT id,name,age,email,create_time,update_time,version FROM user WHERE id IN ( ? , ? , ? )
==> Parameters: 1(Integer), 2(Integer), 3(Integer)
<== Columns: id, name, age, email, create_time, update_time, version
<== Row: 1, Jone, 18, test1@baomidou.com, null, null, null
<== Row: 2, Jack, 120, test2@baomidou.com, null, null, null
<== Row: 3, Tom, 28, test3@baomidou.com, null, null, null
<== Total: 33、分页查询
MyBatis Plus自带分页插件,只要简单的配置即可实现分页功能
1)创建配置类
//分页插件
@Bean
public PaginationInterceptor paginationInterceptor() {
return new PaginationInterceptor();
}2)测试selectPage分页
@Test
void testPage() {
//1、创建page对象
//传入两个参数:当前页码 和 每页显示记录数
Page<User> page = new Page<User>(1, 3);
//2、调用mp的分页查询方法
userMapper.selectPage(page, null);
//3、通过page获取分页数据
//分页的所有信息都会封装到page对象中
System.out.println(page.getCurrent());//当前页码
System.out.println(page.getRecords());//每个页的数据
System.out.println(page.getSize());//每页的记录数量
System.out.println(page.getTotal());//表中的总记录数
System.out.println(page.getPages()); //总页数
System.out.println(page.hasNext()); //是否有下一页
System.out.println(page.hasPrevious()); //是否有前一页
}可以在控制台看到首先使用SELECT COUNT(1) FROM user查询了数据的总个数,然后使用LIMIT进行了分页查询
==> Preparing: SELECT COUNT(1) FROM user
==> Parameters:
<== Columns: COUNT(1)
<== Row: 8
==> Preparing: SELECT id,name,age,email,create_time,update_time,version FROM user LIMIT ?,?
==> Parameters: 0(Long), 3(Long)
<== Columns: id, name, age, email, create_time, update_time, version
<== Row: 1, Jone, 18, test1@baomidou.com, null, null, null
<== Row: 2, Jack, 120, test2@baomidou.com, null, null, null
<== Row: 3, Tom, 28, test3@baomidou.com, null, null, null
<== Total: 3
Closing non transactional SqlSession [org.apache.ibatis.session.defaults.DefaultSqlSession@68b58644]四、delete
1、根据id删除记录
//测试删除,物理删除
@Test
void testDelete() {
int row = userMapper.deleteById(1L);
System.out.println(row);
}可以看到id为1的数据被删除

2、批量删除
//批量物理删除
@Test
void testDeleteBatch(){
int row = userMapper.deleteBatchIds(Arrays.asList(2, 3, 4));
System.out.println(row);
}3、逻辑删除
- 物理删除:真实删除,将对应数据从数据库中删除,之后查询不到此条被删除数据
- 逻辑删除:假删除,将对应数据中代表是否被删除字段状态修改为“被删除状态”,之后在数据库中仍旧能看到此条数据记录
1)数据库中添加 deleted字段
ALTER TABLE `user` ADD COLUMN `deleted` boolean DEFAULT 0![]()
2)实体类添加deleted 字段
@TableLogic
private Integer deleted;3)application.properties 加入配置
此为默认值,如果你的默认值和mp默认的一样,该配置可无
mybatis-plus.global-config.db-config.logic-delete-value=1
mybatis-plus.global-config.db-config.logic-not-delete-value=0
4)在 MybatisPlusConfig 中注册 逻辑删除Bean
//逻辑删除插件
@Bean
public ISqlInjector sqlInjector() {
return new LogicSqlInjector();
}5)测试
首先插入一条数据,可以看到deleted默认值为0
@Test
void insertUser() {
User user = new User();
user.setName("里昂");
user.setAge(99);
user.setEmail("[email protected]");
int i = userMapper.insert(user);
System.out.println("insert : " + i);
}
然后将这条数据进行删除
//测试删除,逻辑删除
@Test
void testLogicDelete() {
int row = userMapper.deleteById(1273835938400808961L);
System.out.println(row);
}从控制台的sql语句可以看出,执行的操作时update,并不是delete
==> Preparing: UPDATE user SET deleted=1 WHERE id=? AND deleted=0
==> Parameters: 1273835938400808961(Long)
<== Updates: 1数据库中deleted的值也被设为1

如果这时进行查询所有操作可以看到,无法将上述数据查出:
@Test
void findAll() {
List<User> userList = userMapper.selectList(null);
System.out.println(userList);
}可以看到查询时也加了deleted=0的判断条件
==> Preparing: SELECT id,name,age,email,create_time,update_time,version,deleted FROM user WHERE deleted=0
==> Parameters:
<== Columns: id, name, age, email, create_time, update_time, version, deleted
<== Row: 2, Jack, 120, test2@baomidou.com, null, null, null, 0
<== Row: 3, Tom, 28, test3@baomidou.com, null, null, null, 0
<== Row: 4, Sandy, 21, test4@baomidou.com, null, null, null, 0
<== Row: 5, Billie, 24, test5@baomidou.com, null, null, null, 0
<== Row: 1273618618428489730, Ada, 22, ada@qq.com, null, null, null, 0
<== Row: 1273807629415706625, Eva, 22, Eva@qq.com, 2020-06-19 10:39:40, 2020-06-19 10:43:32, null, 0
<== Row: 1273814734310735873, 奎托斯, 200, Eva@qq.com, 2020-06-19 11:07:54, 2020-06-19 11:11:29, 2, 0
<== Total: 7五、性能分析
1、配置插件
1)在 MybatisPlusConfig 中配置
/**
* SQL执行效率插件
* 该插件只用于开发环境,不建议生产环境使用。
* dev: 开发环境
* test:测试环境
* prod:生产环境
*/
@Bean
@Profile({"dev","test"})// 设置 dev test 环境开启
public PerformanceInterceptor performanceInterceptor() {
PerformanceInterceptor performanceInterceptor = new PerformanceInterceptor();
performanceInterceptor.setMaxTime(1000); //ms, maxTime SQL 执行最大时长,超过自动停止运行
performanceInterceptor.setFormat(true); //format SQL SQL是否格式化,默认false。
return performanceInterceptor;
}2)Spring Boot 中设置dev环境
#环境设置:dev、test、prod
spring.profiles.active=dev
2、测试
1)常规测试
@Test
void findAll() {
List<User> userList = userMapper.selectList(null);
System.out.println(userList);
}控制台输出:
Time:98 ms - ID:cn.hanzhuang42.mybatisplus.mapper.UserMapper.selectList
Execute SQL:SELECT id,name,age,email,create_time,update_time,version,deleted FROM user WHERE deleted=02)将maxTime 改小之后再次进行测试
performanceInterceptor.setMaxTime(1);如果执行时间过长,则抛出异常:The SQL execution time is too large,
Time:279 ms - ID:cn.hanzhuang42.mybatisplus.mapper.UserMapper.selectList
...
com.baomidou.mybatisplus.core.exceptions.MybatisPlusException: The SQL execution time is too large, please optimize ! 六、wapper介绍
1、相关类

- Wrapper : 条件构造抽象类,最顶端父类
- AbstractWrapper : 用于查询条件封装,生成 sql 的 where 条件
- QueryWrapper : Entity 对象封装操作类,不使用lambda语法(常用)
- UpdateWrapper : Update 条件封装,用于Entity对象更新操作
- AbstractLambdaWrapper : Lambda 语法使用 Wrapper统一处理解析 lambda 获取 column。
- LambdaQueryWrapper :看名称也能明白就是用于Lambda语法使用的查询Wrapper
- LambdaQueryWrapper :看名称也能明白就是用于Lambda语法使用的查询Wrapper
- LambdaUpdateWrapper : Lambda 更新封装Wrapper
2、QueryWrapper 使用
具体参考官网:https://mp.baomidou.com/guide/wrapper.html
//测试条件查询
@Test
void testSelectQuery(){
//1、创建QueryWrapper对象
QueryWrapper<User> wrapper = new QueryWrapper<>();
//ge、gt、le、lt:大于等于 、大于、小于等于 、小于
//查询age大于等30的用户
// wrapper.ge("age", 30);
// List users = userMapper.selectList(wrapper);
// users.forEach(System.out::println);
//eq、ne: 等于、不等于
// wrapper.eq("name", "奎托斯");
// wrapper.ne("name", "奎托斯");
// userMapper.selectList(wrapper).forEach(System.out::println);
//between
//查询年龄在20到30之间的
// wrapper.between("age", 20, 30);
// userMapper.selectList(wrapper).forEach(System.out::println);
//like
// wrapper.like("name", "a");
// userMapper.selectList(wrapper).forEach(System.out::println);
//orderBy
// wrapper.orderByDesc("id");
// userMapper.selectList(wrapper).forEach(System.out::println);
//last:直接在sql语句后追加语句
// wrapper.between("age",20,30)
// .last("limit 1");
// userMapper.selectList(wrapper).forEach(System.out::println);
//指定查询的列
wrapper.select("id","name");
userMapper.selectList(wrapper).forEach(System.out::println);
}