Hadoop Configuration介绍
配置信息来源
static{
// print deprecation warning if hadoop-site.xml is found in classpath
ClassLoader cL = Thread.currentThread().getContextClassLoader();
if (cL == null) {
cL = TestConf.class.getClassLoader();
}
if(cL.getResource("hadoop-site.xml")!=null) {
LOG.warn("DEPRECATED: hadoop-site.xml found in the classpath. " +
"Usage of hadoop-site.xml is deprecated. Instead use core-site.xml, "
+ "mapred-site.xml and hdfs-site.xml to override properties of " +
"core-default.xml, mapred-default.xml and hdfs-default.xml " +
"respectively");
}
if(cL.getResource("core-default.xml")!=null) {
LOG.warn("1:" + cL.getResource("core-default.xml"));
}
if(cL.getResource("core-site.xml")!=null) {
LOG.warn("2:" + cL.getResource("core-site.xml"));
}
addDefaultResource("core-default.xml");
addDefaultResource("core-site.xml");
}1、系统默认配置文件core-default.xml(位于hadoop-core-1.0.3.jar文件下);
2、项目classpath下的core-site.xml文件。
Configuration类的属性清单
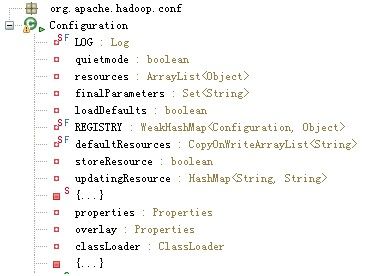
LOG是记录日志的对象。
quietmode对应的是配置信息加载过程中是否属于静默(安静、不写日志)的模式,如果处于静默的模式下,则在配置信息加载的过程中的一些信息不会被记录在日志中,默认情况是设置为true的。
resources是一个对象数组,用于存放有关包含配置信息的对象。
finalParameter是所有配置值被声明为final的变量的一个集合。
loadDefault从表面字段上可以理解为是否要加载默认的配置。
REGISTRY是一个WeakHashMap,用于多有个对象的相关配置的注册对它们进行管理,弱哈希可以自动清除不在正常使用的键对应的条目。
defaultResources是一个CopyOnWriteArrayList的字符串数组,用于存储默认的配置资源名或者路径。
{…}是一个静态初始化块,用于加载默认的配置资源。
overlay则是进行覆盖的属性。
properties存储的是Configuration对象中的全部配置信息,它的类型是Properties的,这个类型是Java提供的对KV配置的一个属性集,提高了对KV配置参数的存储和操作方法。
classLoader主要是用于配置冲根据配置的参数构造相应的对象实例时提供上下文环境的类加载器
MAX_SUBST是设定对带有环境变量的值所能够深入解析的层次数,超出这个最大的层数的值将不能够解析。
varPat是一个对含有环境变量的值的进行转换的正则表达式对象,比如我们设定的一个路径变量的值为$HOME/data,那么这个变量就会以一定的规则把该变量的值分为字串$HOME和/data,之后会把$HOME解析成系统上的目录了。
构造方法

第二个是可以指定是否加载默认设置,默认为true,第三个是用一个configuration对象构造一个新的configuration对象。
添加配置资源的方法

分别是添加默认的或者指定的各种来源的配置资源,而reloadConfiguration()则是一个清除所有原有配置信息,以便于重新加载配置信息的方法,这可以在值的覆盖中或者用新的配置资源覆盖之前的配置资源的时候用到。
获取一些配置信息的set或者get方法和其他方法


set和get方法主要是获取各种参数值的方法,它的主要机制是通过getPros()调用loadResources(Properties,ArrayList,boolean)方法再调用loadResource(Properties,Object,boolean)加载配置资源中的配置信息,而set(String,String)和get(String)的方法中会调用getPros()方法获取当前Configuration对象的properties对象,如果该对象为空,则调用loadResources(Properties,ArrayList,boolean)方法加载配置信息,之后的其他get和set方法都是通过调用get(String)和set (String,String)方法来实现对配置信息的操作的。
substituteVars(String)是配合正则表达式对象对含有环境变量的参数值进行解析的方法
size()方法是获取配置信息大小的
clear()方法是用于清除配置信息的
IntegerRanges是一个关于整型数范围的内部类
iterator()是配置对象的一个迭代器
readFields(DataInput)、write(DataOutput)是因为Configuration类实现了Writable接口的实现方法,这样Configuration类就可以在集群中进行分发,使得同一个作业的所有节点上的配置信息都完全相同。测试类
package com.test.conf;
import java.io.IOException;
import java.util.Iterator;
import java.util.Map;
import java.util.Map.Entry;
import org.apache.hadoop.conf.Configuration;
public class TestConfigration {
/**
* @param args
* @throws IOException
*/
public static void main(String[] args) throws IOException {
Configuration conf = new Configuration();
//配置参数个数
System.out.println(conf.size());
//查看配置参数信息
Iterator> it = conf.iterator();
while(it.hasNext()) {
Entry en = it.next();
String key = en.getKey();
String value = en.getValue();
System.out.println("key=" + key + " value=" + value);
}
conf.writeXml(System.out);
//显示配置文件路径
System.out.println("\n\n" + conf.getResource("core-default.xml"));
System.out.println("\n\n" + conf.getResource("core-site.xml"));
System.out.println(conf.get("test"));
conf.addResource("core-site-1.xml");
System.out.println(conf.get("test"));
conf.set("test", "123");
System.out.println(conf.get("test"));
}
}
core-site.xml
test
abc
true
core-site-1.xml
test
abc
输出:
55
key=io.seqfile.compress.blocksize value=1000000
key=io.skip.checksum.errors value=false
key=fs.checkpoint.size value=67108864
key=fs.default.name1 value=file:///abc
key=fs.s3n.impl value=org.apache.hadoop.fs.s3native.NativeS3FileSystem
key=fs.s3.maxRetries value=4
key=webinterface.private.actions value=false
key=fs.s3.impl value=org.apache.hadoop.fs.s3.S3FileSystem
key=hadoop.native.lib value=true
key=fs.checkpoint.edits.dir value=${fs.checkpoint.dir}
key=ipc.server.listen.queue.size value=128
key=fs.default.name value=file:///
key=ipc.client.idlethreshold value=4000
key=hadoop.tmp.dir value=/tmp/hadoop-${user.name}
key=fs.hsftp.impl value=org.apache.hadoop.hdfs.HsftpFileSystem
key=fs.checkpoint.dir value=${hadoop.tmp.dir}/dfs/namesecondary
key=fs.s3.block.size value=67108864
key=hadoop.security.authorization value=false
key=io.serializations value=org.apache.hadoop.io.serializer.WritableSerialization
key=hadoop.util.hash.type value=murmur
key=io.seqfile.lazydecompress value=true
key=io.file.buffer.size value=4096
key=io.mapfile.bloom.size value=1048576
key=fs.s3.buffer.dir value=${hadoop.tmp.dir}/s3
key=hadoop.logfile.size value=10000000
key=fs.webhdfs.impl value=org.apache.hadoop.hdfs.web.WebHdfsFileSystem
key=ipc.client.kill.max value=10
key=io.compression.codecs value=org.apache.hadoop.io.compress.DefaultCodec,org.apache.hadoop.io.compress.GzipCodec,org.apache.hadoop.io.compress.BZip2Codec,org.apache.hadoop.io.compress.SnappyCodec
key=topology.script.number.args value=100
key=fs.har.impl value=org.apache.hadoop.fs.HarFileSystem
key=io.seqfile.sorter.recordlimit value=1000000
key=fs.trash.interval value=0
key=local.cache.size value=10737418240
key=hadoop.security.authentication value=simple
key=hadoop.security.group.mapping value=org.apache.hadoop.security.ShellBasedUnixGroupsMapping
key=ipc.server.tcpnodelay value=false
key=hadoop.security.token.service.use_ip value=true
key=fs.ramfs.impl value=org.apache.hadoop.fs.InMemoryFileSystem
key=ipc.client.connect.max.retries value=10
key=hadoop.rpc.socket.factory.class.default value=org.apache.hadoop.net.StandardSocketFactory
key=fs.kfs.impl value=org.apache.hadoop.fs.kfs.KosmosFileSystem
key=fs.checkpoint.period value=3600
key=topology.node.switch.mapping.impl value=org.apache.hadoop.net.ScriptBasedMapping
key=hadoop.logfile.count value=10
key=hadoop.security.uid.cache.secs value=14400
key=fs.ftp.impl value=org.apache.hadoop.fs.ftp.FTPFileSystem
key=fs.file.impl value=org.apache.hadoop.fs.LocalFileSystem
key=fs.hdfs.impl value=org.apache.hadoop.hdfs.DistributedFileSystem
key=ipc.client.connection.maxidletime value=10000
key=io.mapfile.bloom.error.rate value=0.005
key=io.bytes.per.checksum value=512
key=fs.har.impl.disable.cache value=true
key=ipc.client.tcpnodelay value=false
key=fs.hftp.impl value=org.apache.hadoop.hdfs.HftpFileSystem
key=fs.s3.sleepTimeSeconds value=10
fs.file.impl org.apache.hadoop.fs.LocalFileSystem fs.default.name1 file:///abc fs.webhdfs.impl org.apache.hadoop.hdfs.web.WebHdfsFileSystem hadoop.logfile.count 10 fs.har.impl.disable.cache true ipc.client.kill.max 10 fs.s3n.impl org.apache.hadoop.fs.s3native.NativeS3FileSystem hadoop.security.token.service.use_ip true io.mapfile.bloom.size 1048576 fs.s3.sleepTimeSeconds 10 fs.s3.block.size 67108864 fs.kfs.impl org.apache.hadoop.fs.kfs.KosmosFileSystem ipc.server.listen.queue.size 128 hadoop.util.hash.type murmur ipc.client.tcpnodelay false io.file.buffer.size 4096 fs.s3.buffer.dir ${hadoop.tmp.dir}/s3 hadoop.tmp.dir /tmp/hadoop-${user.name} fs.trash.interval 0 io.seqfile.sorter.recordlimit 1000000 fs.ftp.impl org.apache.hadoop.fs.ftp.FTPFileSystem fs.checkpoint.size 67108864 fs.checkpoint.period 3600 fs.hftp.impl org.apache.hadoop.hdfs.HftpFileSystem hadoop.native.lib true fs.hsftp.impl org.apache.hadoop.hdfs.HsftpFileSystem ipc.client.connect.max.retries 10 fs.har.impl org.apache.hadoop.fs.HarFileSystem fs.s3.maxRetries 4 topology.node.switch.mapping.impl org.apache.hadoop.net.ScriptBasedMapping hadoop.logfile.size 10000000 fs.checkpoint.dir ${hadoop.tmp.dir}/dfs/namesecondary fs.checkpoint.edits.dir ${fs.checkpoint.dir} topology.script.number.args 100 fs.s3.impl org.apache.hadoop.fs.s3.S3FileSystem ipc.client.connection.maxidletime 10000 io.compression.codecs org.apache.hadoop.io.compress.DefaultCodec,org.apache.hadoop.io.compress.GzipCodec,org.apache.hadoop.io.compress.BZip2Codec,org.apache.hadoop.io.compress.SnappyCodec hadoop.security.uid.cache.secs 14400 ipc.server.tcpnodelay false io.serializations org.apache.hadoop.io.serializer.WritableSerialization ipc.client.idlethreshold 4000 fs.hdfs.impl org.apache.hadoop.hdfs.DistributedFileSystem io.bytes.per.checksum 512 hadoop.security.group.mapping org.apache.hadoop.security.ShellBasedUnixGroupsMapping io.mapfile.bloom.error.rate 0.005 io.seqfile.lazydecompress true local.cache.size 10737418240 hadoop.security.authorization false hadoop.security.authentication simple hadoop.rpc.socket.factory.class.default org.apache.hadoop.net.StandardSocketFactory io.skip.checksum.errors false io.seqfile.compress.blocksize 1000000 fs.ramfs.impl org.apache.hadoop.fs.InMemoryFileSystem webinterface.private.actions false fs.default.name file:///
jar:file:/F:/java/_1_doc/hadoop/soft/lib_hbase/hadoop-core-1.0.3-1.jar!/core-default.xml
file:/F:/eclipsews/testhadoop/bin/core-site.xml
abc
abc
123
12/10/15 15:51:13 WARN conf.Configuration: core-site-1.xml:a attempt to override final parameter: test; Ignoring.
总结以下几点:
1.需要提供各种的set和get方法,方便获取各种的配置参数值。
2.灵活使用集合、垃圾回收机制,采用合理的存储数据结构处理线程同步问题,比如这里用到的弱哈希和CopyOnWriteArrayList,还有在对Configuration.class进行的加锁。
3.分布式系统中的配置一定要实现序列化,这样才能在集群中保持配置信息的一致性,使得配置信息可以从流中来到流中去。
4.一个分布式系统的配置方法应该是至少分为3层的:
第一层就是全局的默认配置(core-default.xml);
第二层是针对某个项目总体配置(core-site.xml);
第三层针对某个作业或任务进行特定设置(通过set配置文件方法或set属性方法)。
这三层的作用域不同,每一层都可以覆盖前一层的参数值(final标记的配置属性特例)。
5.addResource方法说明:增加配置文件只需要将配置文件名放入resources中,然后将properties清空,再次获取配置信息时(调用getProps())重新加载(延迟加载)配置文件信息。
public void addResource(String name) {
addResourceObject(name);
}
private synchronized void addResourceObject(Object resource) {
resources.add(resource); // add to resources
reloadConfiguration();
}
public synchronized void reloadConfiguration() {
properties = null; // trigger reload
finalParameters.clear(); // clear site-limits
}
private synchronized Properties getProps() {
if (properties == null) {
properties = new Properties();
loadResources(properties, resources, quietmode);
if (overlay!= null) {
properties.putAll(overlay);
if (storeResource) {
for (Map.Entry item: overlay.entrySet()) {
updatingResource.put((String) item.getKey(), "Unknown");
}
}
}
}
return properties;
}