Solr 7 - 中文分词、数据导入、查询 基本使用篇
接着之前的 Solr 7 - CentOS 部署篇 继续 Go!
准备一下
/opt/solr-7.6.0 实际安装目录
/opt/solr 指向实际安装目录的链接
我们先链接一份 solr 命令到 /usr/local/bin 内
ln -s /opt/solr/bin/solr /usr/local/bin/solr
现在我们就能在任何地方使用 solr 命令了
创建 Core
上一篇提到过,不建议通过 Web 页面去添加,-。- 会出问题的!
正确添加 Core 方式如下(确保当前 solr 服务正常运行):
solr create -c MyCore
如果提示 Failed to determine the port of a local Solr instance, cannot create MyCore! 说明当前并没有运行 solr 服务
启动一下即可:service solr start
注意,使用 root 用户直接执行创建 Core 的命令会得到下方警告:
WARNING: Using _default configset with data driven schema functionality. NOT RECOMMENDED for production use.
To turn off: bin/solr config -c MyCore -p 8983 -action set-user-property -property update.autoCreateFields -value false
WARNING: Creating cores as the root user can cause Solr to fail and is not advisable. Exiting.
If you started Solr as root (not advisable either), force core creation by adding argument -force
Solr 并不建议使用 root 用户创建 Core,如果非要用就加一个 -force 参数
当然,加上这个参数后我并没有成功创建 Core,在这儿我们通过 su 命令使用 solr 用户创建 Core:
su solr -c "solr create -c MyCore"
刷新网页,左下角已经变成 Core Selector,通过点击弹出的下拉列表我们可以看到刚刚创建的 MyCore
中文分词器 IK-Analyzer
Solr 7 建议使用这个版本的 IK-Analyzer,词库量非常丰富:https://github.com/magese/ik-analyzer-solr7
此处数据我们从 MySQL 中导入,所以我们还得需要一个 MySQL 驱动:https://dev.mysql.com/downloads/connector/j/5.1.html
MySQL 驱动已更新至 8.0(支持 5.5 - 8.0):https://dev.mysql.com/downloads/connector/j/8.0.html
选择 Platform Independent,下载任意格式的压缩包,解压后得到 mysql-connector-java-8.*.jar 文件
-
创建
/var/solr/data/MyCore/libs目录 -
将上方下载的 IK 分词器和 MySQL 驱动的两个
jar文件复制到/var/solr/data/MyCore/libs -
编辑
/var/solr/data/MyCore/conf/solrconfig.xml文件:<lib dir="./libs" regex=".*\.jar" /> -
编辑
/var/solr/data/MyCore/conf/managed-schema文件:<fieldType name="text_ik" class="solr.TextField"> <analyzer type="index"> <tokenizer class="org.wltea.analyzer.lucene.IKTokenizerFactory" useSmart="false" conf="ik.conf"/> <filter class="solr.LowerCaseFilterFactory"/> analyzer> <analyzer type="query"> <tokenizer class="org.wltea.analyzer.lucene.IKTokenizerFactory" useSmart="true" conf="ik.conf"/> <filter class="solr.LowerCaseFilterFactory"/> analyzer> fieldType> -
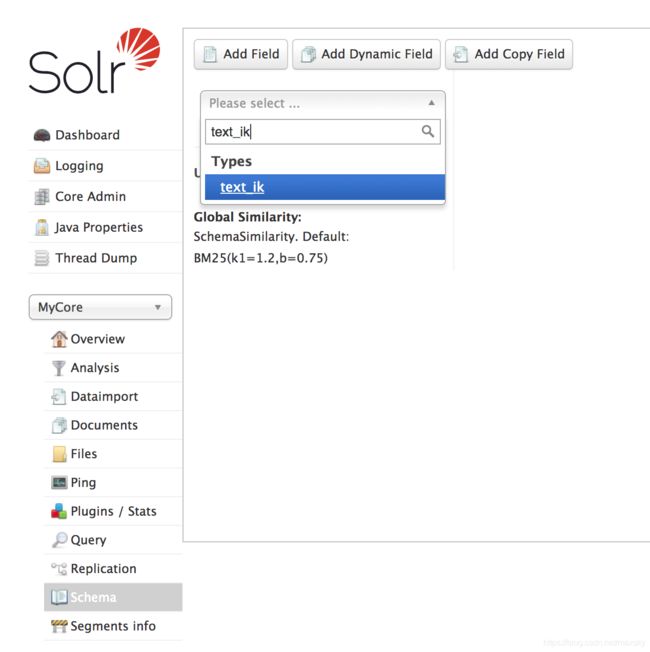
在 Core Admin 中点击 Reload 重载 MyCore,然后在 Schema 中确认
text_ik字段类型已添加成功:
-
如果页面并冇什么红色的错误,我们可以戳开 Analysis 测试一下分词器:
左边 Index 部分为索引测试,右边 Query 为查询测试,果然 180w+ 的词库还是很稳
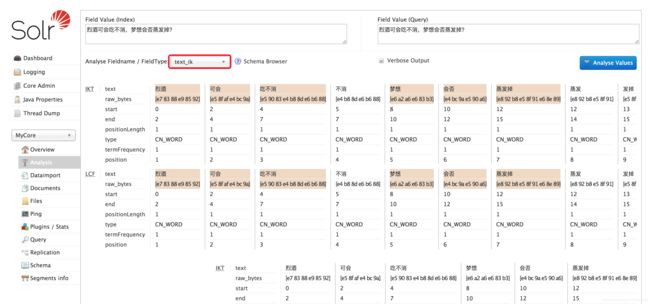
至此分词器配置搞定,下一步导入数据建立 Solr 索引
数据导入
首先编辑 /var/solr/data/MyCore/conf/solrconfig.xml 文件,启用数据导入处理器:
<lib dir="./libs" regex=".*\.jar" />
<lib dir="${solr.install.dir:../../../..}/contrib/dataimporthandler-extras/lib" regex=".*\.jar" />
<lib dir="${solr.install.dir:../../../..}/dist/" regex="solr-dataimporthandler-.*\.jar" />
然后在 680 行左右的 注释下添加下方内容以激活数据导入处理器:
<requestHandler name="/dataimport" class="org.apache.solr.handler.dataimport.DataImportHandler">
<lst name="defaults">
<str name="config">./data-config.xmlstr>
lst>
requestHandler>
此时如果我们重载 MyCore,点击 Dataimport,就能看到导入功能已经能正常显示了:
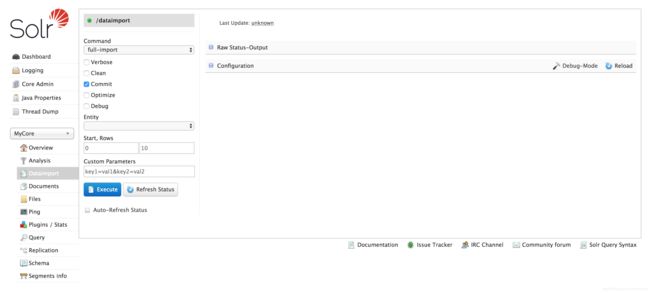
此时我们并没配置数据实体,Entity 里面什么也没有,所以还不能导入数据到 Solr 中,我们接着操作:
-
创建
/var/solr/data/MyCore/conf/data-config.xml文件,内容如下(注意替换相关说明):<dataConfig> <dataSource name="MySQLDB" type="JdbcDataSource" driver="com.mysql.jdbc.Driver" url="jdbc:mysql://localhost:3306/数据库名称" user="root" password="root" /> <document> <entity name="product" dataSource="MySQLDB" pk="id" query="SELECT id, product_name, cat_id FROM exp_products WHERE status = 1" deltaQuery="SELECT id FROM exp_products WHERE FROM_UNIXTIME(add_time, '%Y-%m-%d %T') > '${dih.last_index_time}' AND status = 1" deltaImportQuery="SELECT id, product_name, cat_id FROM exp_products WHERE id = '${dih.delta.id}' AND status = 1"> <field column="id" name="product_id" /> <field column="product_name" name="product_name" /> <field column="cat_id" name="cat_id" /> <entity name="product_cat" query="SELECT name FROM exp_product_categories WHERE id = '${product.cat_id}'"> <field column="name" name="cat_name" /> entity> entity> document> dataConfig>以上数据源做了一个商品表及商品分类表的示例,更多配置参考官方文档[英文]:Configuring the DIH Configuration File
-
回到浏览器,点击 Schema 建立查询字段:
点击 Add Field 添加字段,此处
name对应data-config.xml文件里name属性field type根据实际情况选择,如product_name我们需要模糊查询,在这儿就可以选择text_ik,表示使用 IK 分词器(注意:关联查询中多字段使用text_ik可能会造成数据错乱)如果只是普通字符串,则可以使用
string;ID 类的数字可以使用pintstored和indexed确保勾选。参考下图依次添加需要的字段: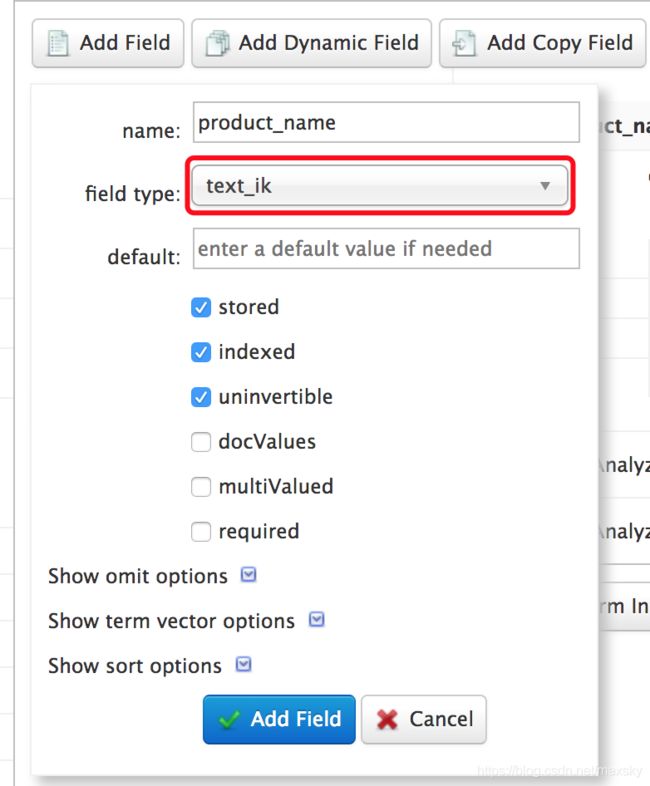
-
回到 Dataimport 执行数据导入:
按照下图勾选后点击 Execute 开始导入
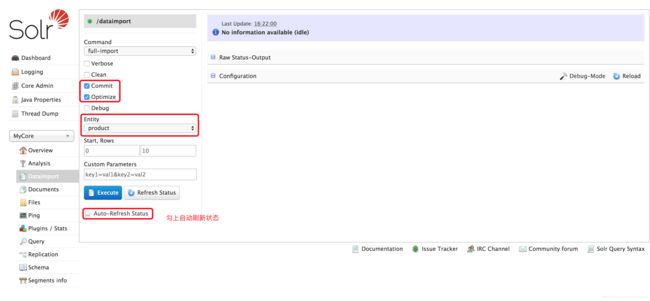
-
状态会一直不停刷新,显示下图内容表示正在建立索引:

直到显示绿色界面表明索引完成
测试查询
点击 Query 进入查询测试界面
参数 q 中输入查询内容,如:product_name:电饭锅,点击下方 Execute Query 执行查询:
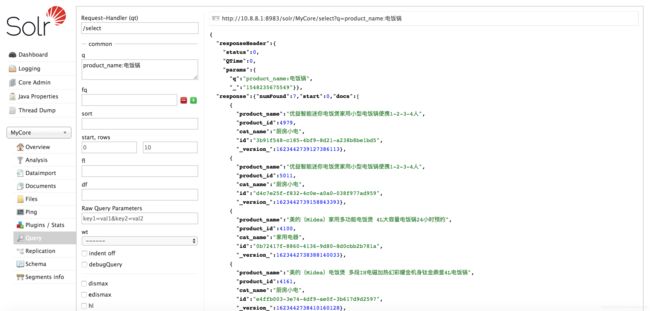
更多查询参数参考官方文档:Common Query Parameters
到此一个简单的 Solr 搜索引擎就搭建完成了,但是 q 参数那儿我们只能查询某一个字段,感觉是不是特别不方便?
下一篇我们再结合 PHP 来实现简单的 Solr 搜索调用。