任意形状文本检测:Look More Than Once
点击我爱计算机视觉标星,更快获取CVML新技术

本文简要介绍2019年6月被CVPR2019录用论文“Look More Than Once: An Accurate Detector for Text of Arbitrary Shapes”的主要工作,该论文主要解决了自然场景图像中进行长文本和不规则形状文本检测的问题。
一、研究背景
由于场景文字检测在现实生活中应用广泛,因此该领域受到了学术界和工业界的广泛关注。近年来,多种场景文字检测方法已经取得了巨大的进步并实现了不错的检测性能。
但是,由于卷积神经网络的感受野和例如矩形框或四边形等简单的目标表达方式的限制,过去的场景文字检测方法在检测较长的文字行或不规则形状的文字行时常常无法得到较好的检测结果。
二、LOMO原理简述
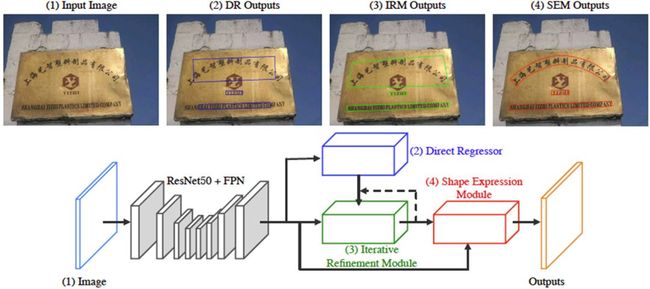
Fig 1. Overall architecture.
Fig 1是LOMO的整体网络结构。LOMO整体网络结构可以分成四个部分,包括主干网络、DirectRegressor (DR)、Iterative Refinement Module (IRM)和Shape Expression Module (SEM)。LOMO以ResNet50 [1]和FPN [2]作为主干网络,其中主干残差网络的第二、三、四和五阶段的特征图以FPN的形式有效的融合在一起。
然后,LOMO用一个类似EAST [3]和Deep Regression [4]的回归网络作为DirectRegressor分支,其每个像素点都预测文字或文字行四边形。
由于感受野的限制,DirectRegressor在检测长文字行时往往检测不全完整的文字行。为解决该问题,论文设计了一个Iterative Refinement Module,通过迭代修正来自DirectRegressor的文字行候选框,使预测框能逐渐覆盖完整文字行。此外,对于不规则文字行,四边形的候选框会包含较多背景区域。
为了得到更加紧致的文字行表达,论文设计了一个Shape Expression Module,通过学习文字行的几何特性,比如文字行区域、文字行中心线和文字行边界偏差(中心线到上下边界的距离)来重构文字行目标的形状表达。
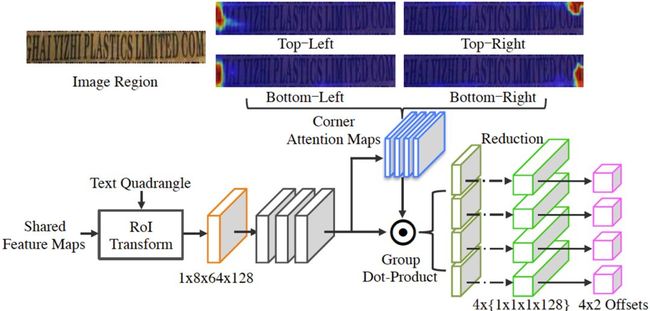
Fig 2. Architecture of the IRM.
Fig 2是论文Iterative Refinement Module(IRM)的详细网络结构。IRM的网络结构设计继承了基于区域的目标检测方法的精髓,把整个目标检测任务视为仅有包围框的回归任务。受通用目标检测模型Faster R-CNN [5]的启发,把DirectRegressor生成的检测框作为候选框,经过RoI transform层将不规则四边形转换成矩形。
IRM的设计切入点是在固定大小的感受野下,更靠近文字行角点的位置可以感知更加准确的边界信息。因此,对于RoItransform层之后的特征图,用卷积层和Sigmoid激活函数自适应学习4个角点注意力图。
角点注意力图的数值表示该位置对应角点坐标偏差回归的贡献权重。IRM可以根据每次迭代的收益来决定是否继续迭代,直到IRM的输出能够覆盖完整文字行。
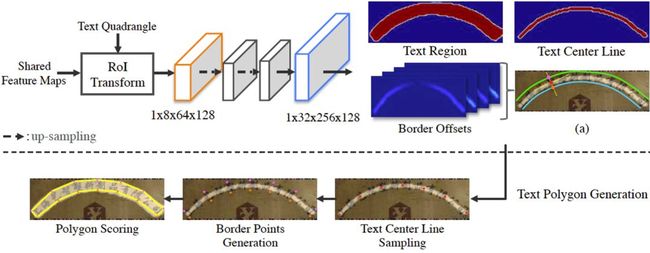
Fig 3. Architecture of the SEM.
Fig 3是论文Shape Expression Module(SEM)的详细网络结构。受Mask R-CNN [6]的启发,本文提出了一个基于候选框的SEM来解决形状不规则文字行的检测问题。
SEM是一个带有RoItransform层的全卷积网络,对RoItransform层后的特征图进行两次上采样操作,然后通过学习文字行的三种不同属性,包括文字行区域(Text Region)、文字行中心线(Text Center Line)和边界偏差(Border Offsets)来重构不规则文字行的精确形状表达。
三、主要实验结果及可视化效果
TABLE 1. Ablations for refinement times (RT) of IRM.

TABLE 2. Ablation study for SEM.

TABLE 3. Quantitative results of different methods on ICDAR2017-
RCTW. MS denotesmulti-scale testing.

TABLE 4. Quantitativeresults of different methods on SCUTCTW1500and Total-Text. “R”, “P” and “H”represent recall, precisionand Hmean respectively. Note that EAST is notfine-tunedin these two datasets and the results of it are just for reference.
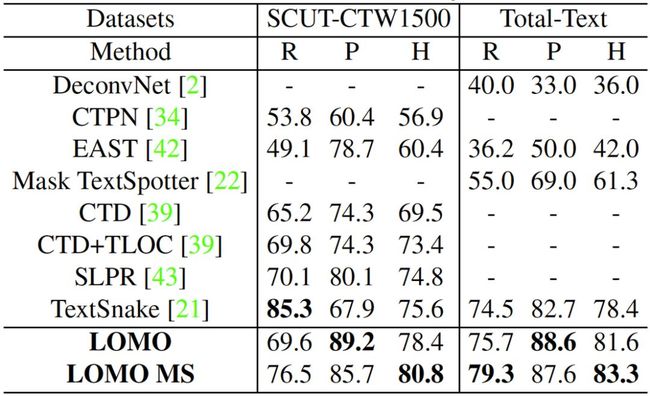
TABLE 5. Quantitativeresults of different methods on ICDAR 2015.
TABLE 6. Quantitativeresults of different methods on ICDAR2017-MLT.


Fig 4. The visualization of detection results. (a) (b) are sampled from ICDAR2017-RCTW, (c) (d) are from SCUT-CTW1500, (e) (f) arefrom Total-Text, (g)(h) are from ICDAR2015, and (i) (j) are from ICDAR2017-MLT. The yellow polygonsare ground truth annotations.The localization quadrangles in blue and in greenrepresent the detection results of DR and IRM respectively. The contours in redare thedetection results of SEM.
TABLE 1验证了IRM对长文字行检测的显著优势,随着迭代次数的增加,IRM的检测性能也会提高。为了兼顾性能与效率,本文将迭代次数设置为2。TABLE 2体现了SEM对不规则文字行检测的巨大收益,验证了本文设计的文字行表达方式可以灵活紧凑地表达不规则文字行。
由TABLE 3、TABLE 4、TABLE 5来看,本文所提方案在ICDAR2017-RCTW,SCUT-CTW1500, Total-Text, ICDAR2015以及ICDAR2017-MLT数据集上取得了state-of-the-art的结果。
Fig 4是LOMO不同模块在不同数据集上的检测结果可视化,Fig 4验证了IRM在检测长文字行时可以覆盖更完整的文字区域,SEM可以更加准确地检测不规则文字行。(更详细的内容请参考原文,链接附后)。
四、总结及讨论
1. 针对自然场景文字行检测中存在的长文字行检测不全和不规则文字行检测包含过多背景区域的问题,本文提出了一个可以端到端训练的文字检测方法(LOMO),其主要的网络结构包含了DR,IRM和SEM。DR生成文字行的初始检测候选框,IRM迭代修正候选框以解决长文字行的检测问题,SEM提出了一种灵活的文字形状表达方法以表达不规则形状文字行的几何属性。
2. 为了解决长文字行的检测问题,本文提出了一个原创的IRM,通过引入角点注意力图和迭代修正机制,充分利用候选框边界特征和长文字行的特性,对文字候选框进行迭代修正,使得IRM的检测结果可以覆盖完整的长文字行。
3. 为解决传统四边形检测框对不规则形状文字行检测不准的问题,本文设计了一个SEM,提出了针对不规则形状文字行的表达方式,通过回归文字行的Text Region,Text Center Line和Border Offsets来灵活重构文字行区域。此后,通过简单的中心点采样、边界点生成和文字多边形打分几个后处理步骤,得到不规则文字行的紧凑多边形包围框。
4. 充分的实验验证了LOMO整体网络结构和各模块设计的有效性和合理性,也证明了LOMO可以较好地解决长文字行和不规则文字行的检测问题。LOMO最终输出为文字行的多边形包围框,经过TPS变换便可以直接送入识别网络进行识别,无需复杂的后处理过程。
五、相关资源
LOMO论文地址:https://arxiv.org/pdf/1904.06535.pdf
Mask R-CNN论文地址:https://arxiv.org/pdf/1703.06870.pdf
ResNet论文地址:https://arxiv.org/pdf/1512.03385.pdf
Deep Regression论文地址:https://arxiv.org/pdf/1703.08289.pdf
Feature Pyramid Network论文地址:https://arxiv.org/pdf/1612.03144.pdf
Faster R-CNN论文地址:https://arxiv.org/pdf/1506.01497.pdf
EAST论文地址:https://arxiv.org/pdf/1704.03155.pdf
参考文献
[1] K. He, X. Zhang, S. Ren, and J. Sun. Deep residual learning for imagerecognition. In CVPR, pages 770–778, 2016. 3
[2] T.-Y. Lin, P. Doll´ar, R. B. Girshick, K. He, B. Hariharan, and S. J.Belongie. Feature pyramid networks for object detection. In CVPR, volume 1, page 4, 2017. 3
[3] X. Zhou, C. Yao, H. Wen, Y. Wang, S. Zhou, W. He, and J. Liang. East: anefficient and accurate scene text detector. In CVPR,pages 2642–2651, 2017. 1, 2, 3, 7, 8
[4] W. He, X.-Y. Zhang, F. Yin, and C.-L. Liu. Deep direct regression formulti-oriented scene text detection. arXivpreprintarXiv:1703.08289, 2017. 1, 2, 3, 8
[5] S. Ren, K. He, R. Girshick, and J. Sun. Faster r-cnn: Towards real-timeobject detection with region proposal networks. In NeurIPS,pages 91–99, 2015. 2, 4, 5
[6] K. He, G. Gkioxari, P. Doll´ar, and R. Girshick. Mask r-cnn. In ICCV, pages 2980–2988. IEEE, 2017. 2, 3, 4
原文作者:Chengquan Zhang*, Borong Liang*, Zuming Huang*, MengyiEn, Junyu Han, ErruiDing, Xinghao Ding
撰稿:梁柏荣
编排:高 学
审校:殷 飞
发布:金连文
免责声明:(1)本文仅代表撰稿者观点,个人理解及总结不一定准确及全面,论文完整思想及论点应以原论文为准。(2)本文观点不代表本公众号立场。
OCR交流群
关注最新最前沿的文本检测、识别、校正、预处理等技术,扫码添加CV君拉你入群,(如已为CV君其他账号好友请直接私信)
(请务必注明:OCR)

喜欢在QQ交流的童鞋,可以加52CV官方QQ群:805388940。
(不会时时在线,如果没能及时通过验证还请见谅)

长按关注我爱计算机视觉