python实战笔记之(5):使用Redis+Flask维护动态代理池
在做爬虫的时候,可能会遇到IP被封的问题,利用代理就可以伪装自己的IP进行爬虫请求。在做爬虫请求的时候需要很多代理IP,所以我们可以建立一个代理池,对代理池中的IP进行定期的检查和更新,保证里面所有的代理都是可用的。这里我们使用Redis和Flask维护一个代理池,Redis主要用来提供代理池的队列存储,Flask是用来实现代理池的一个接口,用它可以从代理池中拿出一个代理,即通过web形式把代理返回过来,就可以拿到可用的代理了。
(1)为什么要用代理池
- 许多网站有专门的反爬虫措施,可能遇到封IP等问题。
- 互联网上公开了大量免费代理,要利用好资源。
- 通过定时的检测维护同样可以得到多个可用代理。
(2)代理池的要求
- 多站抓取,异步检测
- 定时筛选,持续更新
- 提供接口,易于提取
(3)代理池架构
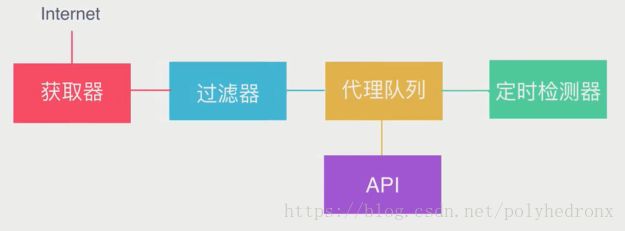
架构最核心的部分是“代理队列”,我们要维护的就是这个队列,里面存了很多代理,队列可以用python的数据结构来存,也可以用数据库来存。维护好队列我们需要做两件事情:第一,就是向队列里添加一些可用的代理,获取器从各大网站平台上把代理抓取下来,临时存到一个数据结构里面,然后用过滤器对这些代理进行筛选。筛选的方法也很简单,拿到代理之后,用它请求百度之类的网站,如果可以正常地请求网站,就说明代理可用,否则就将它剔除。过滤完之后将剩余可用的代理放入代理队列。第二,就是对代理队列进行定时检测,因为经过一段时间之后,代理队列里的部分代理可能已经失效,这就需要定时地从里面拿出一些代理,重新进行检测,保留可用的代理,剔除已经失效的代理。最后我们还需要做一个API,通过接口的形式拿到代理队列里面的一些代理。
(4)代理池实现
项目参考来源:https://github.com/germey/proxypool
修改后的程序可以直接下载
各模块功能
-
getter.py
爬虫模块
-
class proxypool.getter.FreeProxyGetter
爬虫类,用于抓取代理源网站的代理,用户可复写和补充抓取规则。
-
-
schedule.py
调度器模块
-
class proxypool.schedule.ValidityTester
异步检测类,可以对给定的代理的可用性进行异步检测。
-
class proxypool.schedule.PoolAdder
代理添加器,用来触发爬虫模块,对代理池内的代理进行补充,代理池代理数达到阈值时停止工作。
-
class proxypool.schedule.Schedule
代理池启动类,运行RUN函数时,会创建两个进程,负责对代理池内容的增加和更新。
-
-
db.py
Redis数据库连接模块
-
class proxypool.db.RedisClient
数据库操作类,维持与Redis的连接和对数据库的增删查该,
-
-
error.py
异常模块
-
class proxypool.error.ResourceDepletionError
资源枯竭异常,如果从所有抓取网站都抓不到可用的代理资源,则抛出此异常。
-
class proxypool.error.PoolEmptyError
代理池空异常,如果代理池长时间为空,则抛出此异常。
-
-
api.py
API模块,启动一个Web服务器,使用Flask实现,对外提供代理的获取功能。
-
utils.py
工具箱
-
setting.py
设置
使用示例
import os
import sys
import requests
from bs4 import BeautifulSoup
dir = os.path.dirname(os.path.dirname(os.path.abspath(__file__)))
sys.path.insert(0, dir)
def get_proxy():
r = requests.get('http://127.0.0.1:5000/get')
proxy = BeautifulSoup(r.text, "lxml").get_text()
return proxy
def crawl(url, proxy):
proxies = {'http': proxy}
r = requests.get(url, proxies=proxies)
return r.text
def main():
proxy = get_proxy()
html = crawl('http://docs.jinkan.org/docs/flask/', proxy)
print(html)
if __name__ == '__main__':
main()
Last but not least:
如果程序运行过程中出现错误,很有可能是部分代理网站发生了变化,但“getter.py”文件里请求代理网站程序没有更新导致的。比如有的代理网站不再能够访问,或网站不能正常请求,返回503之类的错误,就需要对程序作出更改,或者直接去掉不能正常访问的网站,重新找一些新的可用的代理网站加进去。
另外,这套程序还有一个不足之处,就是代理池中的代理IP很有可能是重复的,而且重复率会随着运行时间的增加而提高。要解决这个问题,一个是可以增加代理网站的数量,使代理池中的代理有更丰富的来源,此外,还可以在向代理池中增加新的代理时进行重复性检查,如果代理池中已经有该代理IP,则放弃存入代理池。
更新(2018/8/9/01:20):
针对代理池中的代理IP可能会重复的问题,提出了一种解决方法,实测可行。
代理IP之所以会重复,和Redis数据库使用的数据结构有很大关系,原程序使用的是列表(list)结构,数据以列表形式存入数据库后是有序但允许重复的,当有新的数据存入时,并不会对数据的重复性进行检查和处理。但Redis不仅有列表结构,常见的Redis数据结构有String、Hash、List、Set(集合)和Sorted Set(有序集合),使用Set和Sorted Set结构就不会出现重复元素。
Set是无序集合,元素无序排列,当有重复元素存入时,数据库是不会发生变化的;Sorted Set是有序集合,有序集合是可排序的,但是它和列表使用索引下标进行排序依据不同的是,它给每个元素设置一个分数(score)作为排序的依据,当存入一个元素时,同时需要存入该元素的分数。
Sorted Set使用起来较复杂,主要是分数分配问题比较难搞,所以这里使用Set代替原程序中的List作为数据库的数据结构,将以下内容代替原来的“db.py”文件中的内容即可:
# db.py
import redis
from proxypool.error import PoolEmptyError
from proxypool.setting import HOST, PORT, PASSWORD
class RedisClient(object):
def __init__(self, host=HOST, port=PORT):
if PASSWORD:
self._db = redis.Redis(host=host, port=port, password=PASSWORD)
else:
self._db = redis.Redis(host=host, port=port)
def get(self, count=1):
"""
get proxies from redis
"""
proxies = []
for i in range(count):
proxies.append(self._db.spop("proxies"))
return proxies
def put(self, proxy):
"""
add proxy to right top
"""
self._db.sadd("proxies", proxy)
def pop(self):
"""
get proxy from right.
"""
try:
return self._db.spop("proxies").decode('utf-8')
except:
raise PoolEmptyError
@property
def queue_len(self):
"""
get length from queue.
"""
return self._db.scard("proxies")
def flush(self):
"""
flush db
"""
self._db.flushall()
if __name__ == '__main__':
conn = RedisClient()
print(conn.pop())
将数据结构改为Set以后,便不会出现代理池中代理IP重复的问题,但这样做也是有弊端的,因为Set是无序的,所以更新代理池的过程中每次弹出的代理IP也是随机的,这样代理池中的某些代理可能永远也不会被更新,而我们获取代理时采用pop方法得到的也是代理池中随机弹出的代理,该代理有可能是很久没有被更新的已经失效的代理。
总结一下就是使用Set结构可以保证代理池中的代理不会重复,但不能保证调用代理池获取代理时得到的代理是最新的和可用的,而List结构可以保证当前获取的代理是最新的,但代理池中的代理可能会有很大的重复。总之,两种方法都是有利有弊的,当然也可以尝试用有序集合(Sorted Set)构建一种完美的方法了。
参考内容:
python redis-string、list、set操作
Python操作redis学习系列之(集合)set,redis set详解 (六)
Redis 有序集合
redis学习笔记(三):列表、集合、有序集合