muduo异步日志——core dump后查找还未来得及写出的日志
目录
前言
生成core文件
gdb调试Core文件
前言
通过异步日志的实现可以知道,日志消息并不是生成后立刻就会写出,而是先存放在前端缓冲区currentBuffer或者前端缓冲区队列buffers中,每过一段时间才会将缓冲区中的日志消息写到日志文件中。那么这就会有问题了:如果程序在中途core dump了,那么在缓冲区中还未来得及写出的日志消息该如何找回呢?
core dump的原因有多种,现在来构造这样的场景:主线程开启日志线程,写入100万条日志,那么会调用100万次append函数,在前端调用第50000次append函数的时候,让程序执行abort(),如下所示:
int cnt = 0;
void AsyncLogging::append(const char* logline, int len)
{
if(cnt++ == 50000)abort();
muduo::MutexLockGuard lock(mutex_);
if (currentBuffer_->avail() > len)
...
}
muduo::AsyncLogging* g_asyncLog = NULL;
void asyncOutput(const char* msg, int len)
{
g_asyncLog->append(msg, len);
}
int main(int argc, char* argv[])
{
muduo::AsyncLogging log("test", 10000000);
log.start(); //开启日志线程
g_asyncLog = &log;
int msgcnt = 0;
muduo::Logger::setOutput(asyncOutput);//设置日志输出函数
for(int i=0;i<1000000;i++) //写入100万条日志消息
LOG_INFO << "Hello 0123456789" << " abcdefghijklmnopqrstuvwxyz "
<< ++msgcnt;
}这样一来,当程序调用了50000次append函数,就会自动abort,也就引发了core dump。
下面就来看看,如何在这种情况下,去找回还未来得及写出到日志文件中的日志消息。
生成core文件
要寻找还未写出的日志消息,需要用到core dump时生成的core文件,但是在默认情况下是不生成的,因此需要先开启。
通过ulimit -c可查看core文件是否开启:
![]()
如果显示为0,说明未开启,此时可以通过ulimit -c unlimited开启,这里unlimited指的是core文件的最大大小,可以设置为其它数字:

此时可以发现,core文件就开启了。
不过这种方式只对当前会话有效,关掉就没了,也有设置永久有效的方法,这里就不多说了。
接下来执行添加了abort后代码:
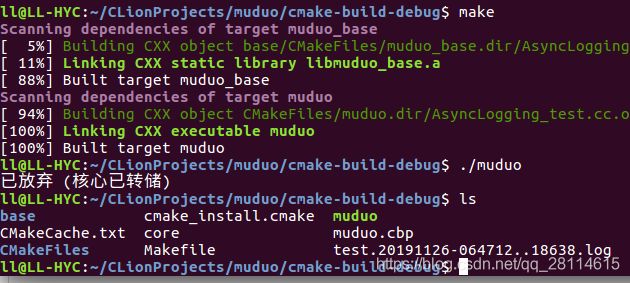
可以看到,运行程序生成的可执行文件muduo,程序发生了异常退出,此时生成了名为"core"的文件,这个文件就记录了程序崩溃的信息。此外还可以看到,已经生成了一个.log日志文件,打开这个日志文件,如下所示:
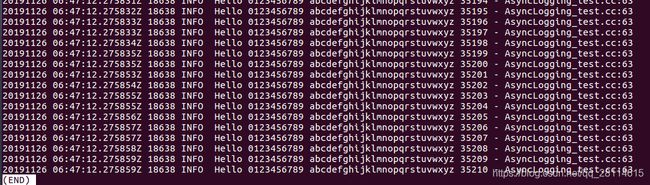
如果没有发生core dump,由于此时在第50000次调用append时abort,那么日志文件也应当有50000条日志消息,而现在可以看到,只有35210条日志消息,也就是说,剩下的近15000条日志消息都还未来得及写出,下面就来寻找这15000条消息。
gdb调试Core文件
从core文件中去获得需要的信息。
通过gdb [execfile] [corefile]进行调试,如下所示:(注意:调试所用的execfile必须是debug生成的!!!否则很多关键信息都看不到)

通过gdb信息可以看到,coredump是由SIGABRT信号,也就是我们调用abort函数导致的。LWP是线程的标识,这里当前线程的LWP为18638,一共有两个线程:LWP 18638和LWP18639,这个数字相当于线程的tid,每个线程都是不同的,无论是否在同一进程。
通过thread info 查看线程信息:
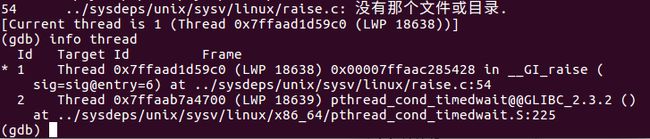
可以看到,这里有两个线程,可以看到,Id2线程abort时位于pthread_cond_timewait,因此这显然就是后端日志线程,而调用abort的线程显然就是Id1线程了,thread 1切换到该线程:

用bt(即backtrace)查看线程的调用栈信息:

从#5到#0,可以看到发生abort的整个过程,输入frame 2选取append所在栈#2:

到这里就可以看到,append函数是在哪里停止的了。此时所在的环境,就相当于是append函数的栈帧,前面说过,未写出的日志消息,只可能存在于currentBuffer或buffers中,而currentBuffer实际上是一个unique_ptr,因此可以通过currentBuffer.get()来获取currentBuffer所指向的LogStream,用print打印变量,用p打印指针如下所示:

这里报错是因为FixedBuffer中的值太大,超过了max-value-size,因此重新设置max-value-size为无限大:

可以看到此时已经在data_后面显示了一部分日志消息,不过还有很多被省略了,这是因为gdb的终端输出长度有限制,默认为200个字符,可以修改这个限制,如下所示:

然后重新打印变量值,如下所示:

可以看到满屏幕都是一条一条的日志消息,如果我们想把这些消息全部输出到外部的文件中,可以通过logging实现,即在print之前通过set logging file [filename]来指定输出文件,然后set logging on来开启拷贝,此后终端上的所有打印的信息都会拷贝到指定的输出文件中,通过set logging off来停止拷贝。
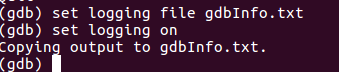
此时就可以进行print了,此后直到调用set logging off,所有终端上的打印信息都会拷贝到gdbInfo.txt中。
然后就可以用vim打开gdbInfo.txt:

此时所有数据都被当作了一行,这是因为在拷贝时,将‘\n’作为了两个普通的字符而不是换行符。因此在vim中将其进行查找替换即可:在命令模式下输入:%s/\\n/\r/g回车即可。

这是文件尾部内容,可以看到刚好写到了第50000条日志,然后再在命令模式下输入0跳转到文件头部:

可以看到,第一条消息的编号为35211,而这一条消息,恰好对应了abort前输出的最后一条消息的编号为35210,也就是说,gdbInfo.txt中的日志消息,就是所需要找的还未来得及写出到日志文件中的日志消息。