Pytorch 基于Resnet-18 实战Cifar-10
前言:这段时间一直在研究深度学习的相关内容,也依据工作需要从github上研究了一些项目,对基础知识有了一定的了解,但是从学习到完全掌握和应用是两回事并且有相当大的一段距离,这里我通过从头开始准备数据,构建网络的,调整参数,整个流程完整跑了一遍,才对之前只知其一不知其二的问题有了更好的理解,这里通过文字分享出来,欢迎指正!再次,强烈建议,如果想认认真真学深度学习,一定要做一次完整的项目,才能收获更大,废话不多说了,言归正传。
一、Resnet网络初探
Resnet名为残差网络,关于它的由来这里就不多介绍了,有兴趣的可以自行百度,这里主要要说明一下的就是它之所以产生如此优良的效果的最本质的原因:在残差块中,输入可以跨层向前传播。说到这里,还是深度神经网络的问题,网络层数越多,深度越大,就无可避免地在越深的层中丢掉之前的信息,因此,resnet很好地解决了这一问题,输入可以跨层传播,只要保证在最终连接处的输入channels一致即可,Resnet到目前有多种结构resnet18,resnet50,resnet101,这里主要以简单的结构resnet18为例进行分析。
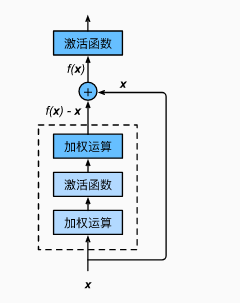
首先,比较重要的一点是,这些基础的模型,在主流深度学习框架中已经有预训练好的模型,一般可以拿来直接做迁移学习。关于如何做迁移学习,请参考我的另一篇博客,我这里想说的并不是直接拿来做迁移学习,而是利用其网络结构构建自己的训练模型,在CiFar-10中图片大小是32*32,如果直接用resnet18,那么最终得到size为-5 * -5,显然这是不合理,到这里有童鞋就会说了,把图片size调大,不就可以了嘛,但是我建议,最好不要这样做,图片size随意调大,会丢失像素信息影响最终结果,那是不是说不能用这个模型了呢,答案肯定是可以用的,只是需要我们自己重新构建模型,设定kernel_size,stride等这些参数,从而适配我们自己的数据。
二、数据集准备
首先我们拿到的cifar-10数据集结构是一个train.7z、一个test.7z以及一个trainlabels,这里我们需要整理数据集,我们知道cifar-10一共是10类,那么我们需要按照每一类别划分数据集,这样便于我们使用pytorch中对数据处理的方法,另外,我们需要划分训练集和验证集,验证集的作用主要是便于优选合适的模型以及调整超参数,一般比例为0.1
1.根据标签文件计算每一类别个数与标签字典
def read_label_file(data_dir, label_file, train_dir, valid_ratio):
with open(os.path.join(data_dir, label_file), 'r')as f:
lines = f.readlines()[1:]
tokens = [l.rstrip().split(',') for l in lines]
idx_label = dict(((int(idx), label) for idx, label in tokens))
labels = set(idx_label.values())
n_train_valid = len(os.listdir(os.path.join(data_dir, train_dir)))
n_train = int(n_train_valid * (1 - valid_ratio))
assert 0 < n_train < n_train_valid
return n_train // len(labels), idx_label2.构建训练与验证数据集
def reorg_train_valid(data_dir, train_dir, input_dir, n_train_per_label, idx_label):
label_count = {}
for train_file in os.listdir(os.path.join(data_dir, train_dir)):
# print(train_file)
idx = int(train_file.split('.')[0])
label = idx_label[idx]
mkdir_if_not_exist([data_dir, input_dir, 'train_valid', label])
shutil.copy(os.path.join(data_dir, train_dir, train_file),
os.path.join(data_dir, input_dir, 'train_valid', label))
if label not in label_count or label_count[label] < n_train_per_label:
mkdir_if_not_exist([data_dir, input_dir, 'train', label])
shutil.copy(os.path.join(data_dir, train_dir, train_file),
os.path.join(data_dir, input_dir, 'train', label))
label_count[label] = label_count.get(label, 0) + 1
else:
mkdir_if_not_exist([data_dir, input_dir, 'valid', label])
shutil.copy(os.path.join(data_dir, train_dir, train_file),
os.path.join(data_dir, input_dir, 'valid', label))
def reorg_test(data_dir, test_dir, input_dir):
mkdir_if_not_exist([data_dir, test_dir, input_dir, 'test', 'unknown'])
for test_file in os.listdir(os.path.join(data_dir, test_dir)):
shutil.copy(os.path.join(data_dir, test_dir, test_file), os.path.join(data_dir, input_dir, 'test', 'unknown'))
def reorg_cifar10_data(data_dir, label_file, train_dir, test_dir, input_dir, valid_ratio):
n_train_per_label, idx_label = read_label_file(data_dir, label_file, train_dir, valid_ratio)
reorg_train_valid(data_dir, train_dir, input_dir, n_train_per_label, idx_label)
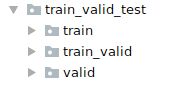
# reorg_test(data_dir,test_dir,input_dir)这样就构造好了数据集,目录结构如图
三、数据集预处理
单单准备好了数据还是远远不够的,我们的数据是一系列的图片,我们需要转换为计算机可以读取的数值才能计算,这里需要将图片转化为对应的多维数组,至此,pytorch丰富以及强大的功能就出场了,除此之外,我们还可以利用pytorch进行可视化,以及对图片做剪切、旋转等增强处理
1.利用transform可以对图片做简单的随机剪切,其中 transforms.ToTensor()比较重要,这里强调一下,pytorch中对tensor和numpy有一个转换,主要是为了便于计算
transform_train = transforms.Compose([transforms.Resize(40), transforms.RandomResizedCrop(32), transforms.ToTensor(),transforms.Normalize([0.4914, 0.4822, 0.4465], [0.2023, 0.1994, 0.2010])])
2.Pytorch中有一个ImageFolder方法能够很好地读取训练数据中文件夹内容
train_ds = ImageFolder(os.path.join(data_dir, input_dir, 'train'), transform=transform_train)
3.利用DataLoader方法就可以按照设定一次读取一定批次的数据了,当然你也可以自己定义数据类,然后利用DataLoader加载数据
train_data = DataLoader(train_ds, batch_size=batch_size, shuffle=True)
四、模型构建
在前面的步骤中,数据已经准备好了,米已经准备好,就等锅烧热了(^_^)
1.构建基础残差块
这里是两个卷积加上一个残差连接卷积层
class Residual(nn.Module):
def __init__(self,in_channels,num_channels,use_conv11=False,strides=1):
super(Residual,self).__init__()
self.conv1=nn.Conv2d(in_channels=in_channels,out_channels=num_channels,kernel_size=3,padding=1,stride=strides)
self.conv2=nn.Conv2d(num_channels,num_channels,kernel_size=3,padding=1)
if use_conv11:
self.conv3=nn.Conv2d(in_channels,num_channels,kernel_size=3,stride=strides,padding=1)
else:
self.conv3=None
self.b1=nn.BatchNorm2d(num_channels)
self.b2=nn.BatchNorm2d(num_channels)
def forward(self, input):
#print(input.shape)
y=F.relu(self.b1(self.conv1(input)))
y=self.b2(self.conv2(y))
if self.conv3:
input=self.conv3(input)
#print(y.shape,input.shape)
return F.relu(y+input)
def resnet18(num_classes, input_channels):
net = nn.Sequential(
nn.Conv2d(in_channels=input_channels, out_channels=64, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(64),
nn.ReLU(),)
#print(net)
def resnet_block(input_channel, num_channels, num_residuals, first_block=False):
blk = nn.Sequential()
for i in range(num_residuals):
if i == 0 and not first_block:
blk.add_module('Residual1', Residual(input_channel, num_channels, use_conv11=True, strides=2))
else:
blk.add_module('Residual', Residual(num_channels, num_channels,use_conv11=False))
return blk
net.add_module('block1', resnet_block(64, 64, 2, first_block=True))
net.add_module('block2', resnet_block(64, 128, 2))
net.add_module('block3', resnet_block(128, 256, 2))
net.add_module('block4', resnet_block(256, 512, 2))
net.add_module('pool', nn.AvgPool2d(3))
net.add_module('dense1', nn.Conv2d(512,num_classes,kernel_size=1))
#net.add_module('dense1', nn.Linear(120, num_classes))
return net整个模型就是首先是一个卷积层,初步提取特征,然后是四个计算块,每个计算块重复残差两次,注意,当strides=2时,表示图像size要除以2,所以整体一共是3个strides为2,下来是32*32、16 * 16、8 *8、4 *4,最后有一个pool层,kernel_size为3因此最后是128 *512 *1 * 1,由于在构建模型时,没有之间构建类,导致debug不方便,在最后一层出了很多问题,这里是需要对维度处理的,要将128 *512 *1 * 1处理成128 *512 才能做nn.Linear,我这里为了简洁直接做了一个卷积
五、训练过程
这里米准备好了,锅也烧热了,可以下锅了
需要注意的是,这里用了gpu训练,所以需要将数据和模型移到GPU上,也很简单
def get_net():
num_classes=10
net=resnet18(10,3)
return net
#Wmodel_fit = models.resnet18(pretrained=True)
model_fit=get_net()
print(model_fit)
#print(help(models))
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
model_fit=model_fit.to(device)
#print(model_fit)
optimizer = optim.SGD(model_fit.parameters(), lr=0.001, momentum=0.9)
print(model_fit.parameters())
criterion = nn.CrossEntropyLoss()此外,也可以定义学习率自动下降训练
def adjust_learning_rate(optimizer,lr):
lr=lr*0.1
for param_group in optimizer.param_groups:
param_group['lr']=lr
def trainCIFAR(net, train_iter, num_epochs):
for epoch in range(num_epochs):
train_l_sum, train_acc_sum, n, start = 0.0, 0.0, 0, time.time()
running_loss=0.0
running_corrects=0
if epoch>0 and (epoch+1)%80==0:
adjust_learning_rate(optimizer,0.001)
if (epoch+1)%2==0:
torch.save(net, 'model_'+str(epoch)+'.pkl')
for x ,y in train_iter:
x=x.to(device)
#print(x.shape,y.shape)
y=y.to(device)
#print(type(x))
optimizer.zero_grad()
#print(x,y)
#print(x.size()
y_hat=net(x)
y_hat=y_hat.view(y_hat.size(0),-1)
#print(y_hat.shape)
_,pred=torch.max(y_hat,1)
#print(pred.shape)
loss=criterion(y_hat,y)
#print(loss)
loss.backward()
optimizer.step()
running_loss+=loss.item()
#print(torch.sum(pred==y))
running_corrects+=torch.sum(pred==y).item()
epoch_loss=running_loss/(len(train_iter))
epoch_acc=running_corrects/(batch_size*len(train_iter))
print(len(train_iter))
print('epoch_loss',epoch_loss)
print('epoch_correct',running_corrects,epoch_acc)至此,整个过程介绍完毕
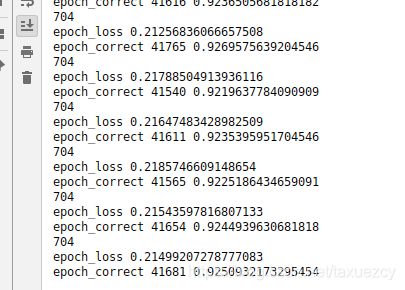
差不多100个epoch后精度达到92.5%,还可以调整参数修改
本文代码参考了gluon深度学习,不过它的框架是mxnet,地址为http://zh.gluon.ai/chapter_computer-vision/kaggle-gluon-cifar10.html