零拷贝
到目前为止,几乎每个人都听过 Linux 中所谓的零拷贝功能,但是我经常遇到对它不完全理解的人。基于此,我决定写一些文章深入探讨这个有用的功能。在这篇文章中,我们将从用户的角度讨论零拷贝,因此内核层次的细节将会省略。
什么是零拷贝?
为了更好地理解这个问题的解决方案,我们需要先理解这个问题本身。我们来看看网络服务器将存储在文件中的数据通过网络传输到客户端的简单过程。示例代码:
read(file, tmp_buf, len);
write(socket, tmp_buf, len);
看起来很简单。你可能认为就两次系统调用并没有什么开销。实际上,这可能是与真相相去甚远。这两次调用的背后,数据至少拷贝了四次,用户/内核上下文转换也几乎执行了相同的次数(这个执行过程比这复杂得多,但是我想先使它简单)。为了更好的理解这个执行过程,请看图1。上面部分展示的是上下文切换,下面部分展示的是拷贝操作。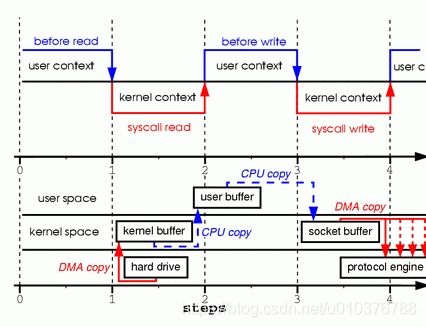
图1 两个系统调用中的拷贝过程
- 第一步:read 系统调用导致一次从用户态到内核态的上下文切换。这第一次拷贝在 DMA 引擎中执行,它从磁盘中读取文件内容,并且存入内核地址空间缓存中。
- 第二步:数据从内核缓存拷贝到用户缓存,同时 read 系统调用返回。read 调用的返回导致一次从内核态到用户态的上下文切换。现在数据用户地址空间缓存中,并且再次开始向下移动。
- 第三步:write 系统调用导致一次从用户态到内核态的上下文切换。第三次拷贝执行是为了再次把数据放到内核地址空间缓存中。此时,数据被放到一个不同的缓存中,一个和特定的 sockets 关联的缓存。
- 第四步:write 系统调用返回,并且造成第四次上下文切换。第四次拷贝在独立且异步的情况下,通过 DMA 引擎将数据从内核缓存拷贝到协议引擎中。你很可能要问,“独立且异步是什么意思?调用返回之前,难道没有数据传输吗?”事实上,调用返回不能保证数据传输;它甚至不能保证数据传输的开始。它仅仅意味着以太网驱动程序的队列中有空闲的描述符,可以接收我们的数据传输。在我们之前可能有很多数据包在排队。除非驱动程序或硬件实现优先级环或队列,否则数据按先进先出原则传输。(图1 中的 DMA 拷贝说明了最后一次拷贝可以被延迟的事实)。
如你所见,很多的数据复制并不是真正需要的。有些复制可以消除以减少开销,提升性能。作为一个驱动程序开发者,我工作中使用的硬件具有相当高级的特性。一些硬件可以完全绕过主存,直接传输数据到另一个设备。这个特性减少了一次在系统内存中的拷贝,是一个很好的特性,但是这不是所有硬件都支持的。数据从磁盘重新打包到网络中也是存在问题的,这引入了一些复杂性。为了减少开销,我们从减少内核缓存和用户缓存之间的拷贝开始。
mmap
一种减少拷贝的方法,是调用 mmap 代替调用 read。例如:
tmp_buf = mmap(file, len);
write(socket, tmp_buf, len);
为了更好地理解处理过程,请看图2。上下文切换保持不变。
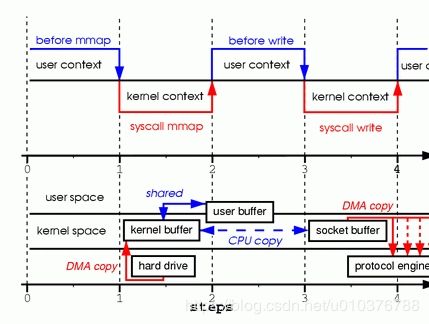
图2 mmap 调用
- 第一步:mmap 系统调用导致文件内容被 DMA 引擎拷贝到内核缓存中。这个缓存是和用户进程共享的,在内核和用户内存空间中没有执行任何拷贝。
- 第二步:write 系统调用导致内核从原始内核缓存拷贝数据到与 sockets 关联的内核缓存中。
- 第三步:当 DMA 引擎从内核 Socket 缓存中传输数据到协议引擎时,第三次拷贝发生。
通过使用 mmap 代替 read,我们将内核必须拷贝的数据量减少了一半。当大量的数据被传输时,这能产生相当好的效果。然而,这种提升不是没有代价的;使用 mmap+write 方法有些隐藏的陷阱。当你在内存映射一个文件,然后调用 write,同时另一个进程截断相同的文件时,你将会掉入其中的一个陷阱中。你的 write 系统调用将会被总线的错误信号 SIGBUG 中断,因为你执行了一个错误的内存访问。那个信号的默认行为是杀死该进程并转存内核——不是网络服务器最理想的处理方式。有两种方式解决这个问题。
第一种方式是为 SIGBUS 信号安装一个信号处理程序,然后在处理程序中简单地调用 return。通过这样做,write 系统调用返回在它被中断之前写的字节数,并且把 errno 置为 success。让我指出,这是一个不好的解决方案,一个解决治标不治本的方案。因为 SIGBUS 信号表示进程已经发生了非常严重的错误,我不鼓励使用这个解决方案。
第二种方式涉及到内核中的文件租赁(在 Microsoft Windows 中叫作 “机会锁定”)。这是这个问题正确的解决方案。通过在文件描述符中使用租赁,你可以使用内核租赁一个特殊的文件。然后你可以从内核请求读/写租约。当另一个进程尝试截断你正在传输的文件时,内核会给你发送一个实时信号——RT_SIGNAL_LEASE 信号。它告诉你内核正在破坏你在文件的读/写租约。你的 write 调用在你的程序访问到一个非法地址,并被 SIGBUS 信号杀死之前被中断。write 调用的返回值是在中断之前写的字节数,并且设置 errno 为 success。下面是示例代码,表示怎么从内核回的一个租约。
if(fcntl(fd, F_SETSIG, RT_SIGNAL_LEASE) == -1) {
perror("kernel lease set signal");
return -1;
}
/* l_type can be F_RDLCK F_WRLCK */
if(fcntl(fd, F_SETLEASE, l_type)){
perror("kernel lease set type");
return -1;
}
你应该在 mmaping 文件之前得到你的租约,并且在你完成之后将租约撕毁。这是通过使用 F_UNLCK 的租约类型调用 fcntl F_SETLEASE 实现的。
Sendfile
在内核 2.1 版本中,sendfile 系统调用被引入,以简化网络和两个本地文件之间的数据传输。sendfile 的引入不仅减少了数据拷贝,也减少了上下文切换。它使用起来像这样:
sendfile(socket, file, len);
为了更好地理解处理过程,请看图3:
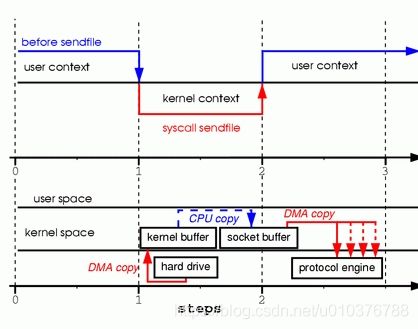
图3 使用 Sendfile 代替 read 和 write
- 第一步:sendfile 系统调用导致文件内容被 DMA 引擎拷贝到内核缓存中。然后数据被内核拷贝到与 sockets 关联的内核缓存中。
- 第二步:当 DMA 引擎将数据从内核 Socket 缓存中传输到协议引擎时,第三次拷贝发生。
你很可能想知道当另一个进程截断我们用 sendfile 系统调用传输的文件时,发生了什么。如果我们不注册任何信号处理程序,sendfile 只返回它在中断之前传输的字节数,而且 errno 会被设置为 success。
在我们调用 sendfile 之前,如果我们从内核获得文件租约,则行为和返回状态是完全一样的。在 sendfile 调用返回之前,我们也可以获得 RT_SIGNAL_LEASE 信号。
到此为止,我们已经能够避免内核发生一些拷贝,但是我们仍然还有一次拷贝。我们也可以避免麽?使用一点硬件帮助,绝对可以的。为了消除内核的数据拷贝,我们需要一个支持聚集操作的网络接口。这仅仅意味着等待传输的数据不需要连续的内存空间;它可以分散不同的内存位置。在内核 2.4 版本中,socket 缓存描述符被修改以适应这些需求——在 Linux 中被称作零拷贝(Zero Copy)。这种方式不仅减少了多个上下文切换,也减少了处理器的数据拷贝。因为用户级应用程序没有改变,所以代码看起来像这样:
sendfile(socket, file, len);
为了更好地理解处理过程,请看图4:
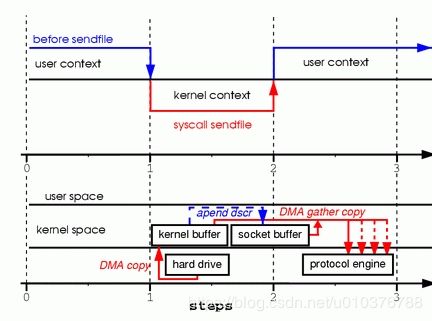
图4 支持聚集操作的硬件从内存的多个位置获取数据,消除内存拷贝
- 第一步:sendfile 系统调用导致文件内容被 DMA 引擎拷贝到内核缓存中。
- 第二步:没有数据被拷贝到 socket 缓存中。取而代之的是,只有关于数据的位置和长度的信息的描述符附加到套接字缓冲区。DMA 引擎直接将数据从内核缓存传输到协议引擎,因此消除了最后的拷贝。
因为数据仍然是从磁盘拷贝到内存,从内存到导线,有人可能会说这不是真正的零拷贝。站在操作系统的角度,这是零拷贝,因为在内核缓存之间没有了数据拷贝。当使用零拷贝时,不就有避免拷贝的性能收益,还有像更少的上下文切换,较少的 CPU 数据缓存污染和没有 CPU 校验和计算。
可移植性问题
一般来说,sendfile 系统调用的一个问题是,缺少标准的实现,像开源系统调用那样。sendfile 在 Linux、Solaris 或 HP-UX 上的实现是完全不同的。这对希望在他们的网络数据传输代码中使用零拷贝的开发者造成了困扰。
实现的不同点之一是,Linux 提供的 sendfile 定义了在两个文件描述符(文件到文件)和(文件到套接字)之间传输数据的接口。另一方面,HP-UX 和 Solaris 仅仅能使用了文件到套接字提交。
第二个不同点是,Linux 没有实现矢量传输。Solaris 和 HP-UX 的 sendfile 有额外的参数,可取消与将要发送的数据预置标头相关的开销。
展望未来
Linux 中的零拷贝的实现还远远没有完成,并且不久的将来很可能会发生改变。更多的功能会被添加。例如,sendfile 不支持矢量传输,Samba 和 Apache 这类服务器不得不使用具有 TCP_CORK 标志设置的多个 sendfile 调用。该标志告诉系统更多的数据将在下一个 sendfile 调用中通过。TCP_CORK 也和 TCP_NODELAY 不兼容,并且在我们想要给数据预置或追加头信息时使用。这是一个完美的例子,矢量调用可以消除多次 sendfile 调用的需要,以及当前实现强制要求的延迟。
现在的 sendfile 另一个令人相对不爽的限制是,它不能被用于传输超过 2GB 的文件。这样大小的文件在今天还不常见,同时在退出的过程中不得不复制所有这些数据,这相当令人失望。因为 sendfile 和 mmap 不能被用于这样的场景,所以 sendfile64 在将来的内核版本中使用会非常方便。
原文地址