缓存学习(七):Redis的高级机制:管道、事务、脚本、发布订阅、持久化
目录
1.管道
1.1 RESP
1.2 通过管道交互
2 事务操作
3.脚本
4. 发布/订阅模式
5.持久化
5.1 RDB
5.2 AOF
1.管道
1.1 RESP
Redis的协议称为RESP,它将协议数据分为不同类型,根据数据的首字符决定,不过所有类型的数据均以CRLF(即“\r\n”)结束。
1)简单字符串
首字符为“+”,后续为字符串内容,字符串内容不能包括'\r'或'\n'。例如“+OK\r\n”,经过客户端转换就变成了“OK”。由于简单字符串没有转义的情况,所以反序列化就是直接把“+”和“\r\n”之间的部分复制出去。
2)块字符串
如果发送的字符串本身包含了'\r'或'\n',就不能使用简单字符串,此时有两种解决方案:一是加入转义机制,这种方式效率比较低;二是在字符串前/后加上一个数字,表示整个字符串的长度。Redis使用了后者。块字符串的首字符是'$',后面跟着整个字符串的长度,以“\r\n”分隔后,跟上字符串内容,最后以“\r\n”结尾。例如:“$12\r\nhello\r\nworld\r\n”转换后就是:
hello
world如果字符串长度为0,说明是空字符串,如果为-1("$-1\r\n"),则说明是null
3)错误字符串
正常的字符串是“+”开头,所以错误字符串就是“-”开头,剩下的和简单字符串一样
4)数字
以“:”开头,紧跟着数字本身,以“\r\n”结尾
5)数组
以“*”开头,紧跟着数组长度,类似于块字符串,长度为0代表空数组,为-1代表null,数组内容夹在两个“\r\n”中间,每一个数组元素都是这五种类型的数据,例如:"*2\r\n+hello\r\n+world\r\n"代表["hello","world"],数组内元素类型可以不一样,也支持嵌套数组。
客户端在向服务端发送数据时,参数以块字符串的形式发送,命令本身因为不属于以上任何类型,所以以原型发送
服务器向客户端发送消息时,有两种情况:第一种是对客户端的命令返回响应,可以返回以上五种类型;第二种是对Pub/Sub模式的订阅者推送消息,此时以数组类型发送。
1.2 通过管道交互
在Linux中,管道是进程间通信的重要手段,可以让前一条命令的结果传递给下一条命令作为参数,但是Redis的管道和Linux的不太一样,它的作用是将一批命令序列化地发送到服务端,执行后再将结果集序列化发送回客户端,从而节约网络I/O的时间。
Redis是单线程架构,即一次只能处理一条命令,在串行实现中,客户端命令的执行有如下四个步骤:
- 命令发送
- 命令排队
- 命令执行
- 返回结果
该实现的优点在于简单,缺点则是效率低,因为每一条命令必须等待前一条命令完全执行后才会执行,同样地,从客户端角度来看,每一条命令的发送都需要前一条命令的响应被接收,导致吞吐量很低,尤其是内存速度比网络I/O快太多,会导致客户端空等待。
为了解决这个问题,Redis提供了两种方案:
第一种就是如mget、mset这样的批量操作,这种操作具有很多优点,如原子执行、原生支持等,缺点也很明显,并不是所有操作都有批量版本;
第二种就是管道机制,Redis管道可以将一批命令一次性发送出去,和原生批量操作的区别在于:首先,管道不是原子操作;其次,批量操作是对多个key执行相同操作,而管道可以将不同的操作封装成一批;最后,管道的实现需要客户端和服务端共同完成。
对于Redis自带的客户端,即redis-cli,在启动时加上--pipe选项即可使用pipe机制,例如:
root@Yhc-Surface:~# echo -en '*3\r\n$3\r\nset\r\n$5\r\nhello\r\n$5\r\nworld\r\n*2\r\n$4\r\nincr\r\n$9\r\ntestcount\r\
n' | redis-cli --pipe
All data transferred. Waiting for the last reply...
Last reply received from server.
errors: 0, replies: 2该命令将 set hello world 和 incr testcount 两个命令合并,通过管道发送给服务端,美中不足的是看不到服务端响应内容,下面的用法可以看到服务端响应:
root@Yhc-Surface:~# printf '*3\r\n$3\r\nset\r\n$5\r\nhello\r\n$5\r\nworld\r\n*2\r\n$4\r\nincr\r\n$9\r\ntestcount\r\n'
| nc localhost 6379
+OK
:2可以看到,服务端返回了一条简单字符串和一个数字。
现在计算pipeline的性能提升幅度:
对于串行模式,每一条命令都有两倍的网络延迟RTT(一收一发),还要加上客户端和服务端对命令的处理时间,分别设为m和n,则其吞吐量公式为:
![]()
对于管道模式,设一批执行了k条命令,仍然只有两倍的网络延迟,不过客户端和服务端的处理时间变成了k*m、k*n,即:
![]()
当k足够大时,可以忽略网络延迟,即TPS=1/(m+n)。如果假设网络I/O所需时间是命令处理时间的10倍,那么使用管道最大可以将性能提升10倍。
2 事务操作
事务是数据库的重要特性,可以保证操作全部或全不执行,从而保障写安全。Redis也支持事务操作,以下是一个例子:
127.0.0.1:6379> multi
OK
127.0.0.1:6379> set hello world
QUEUED
127.0.0.1:6379> incr testcount
QUEUED
127.0.0.1:6379> exec
1) OK
2) (integer) 1可以看到,事务中的命令在调用了exec之后才全部执行。且命令成功进入事务队列中时,会输出QUEUED。
Redis事务由五个命令组成:
- multi:标记事务开始
- exec:标记事务结束,开始执行
- discard:标记事务取消
- watch key... :监视某个对象,如果在事物编写过程中,该对象的值发生了变化,则事务不执行
- unwatch:清除所有设置过的watch
watch的一个例子如下:
| 操作 | 客户端1 | 客户端2 |
| 1 | set user:tom:age 5 | |
| 2 | watch user:tom:age | |
| 3 | multi | |
| 4 | incr user:tom:age | |
| 5 | incr user:tom:age | |
| 6 | exec |
执行以上命令最终的结果如下:
127.0.0.1:6379> set user:tom:age 5
OK
127.0.0.1:6379> watch user:tom:age
OK
127.0.0.1:6379> multi
OK
127.0.0.1:6379> incr user:tom:age
QUEUED
127.0.0.1:6379> exec
(nil)
//另一个客户端
127.0.0.1:6379> incr user:tom:age
(integer) 6watch的实质是一个乐观锁。
与关系型数据库,如MySQL不同的是,Redis事务不支持回滚。根据官方的解释,如果在事务中出现错误,那肯定是因为出现编程错误,例如:命令拼写错误、数据类型错误等,这些错误一般不会发生在生产环境中,而且即便可以回滚,还会再次出现这个错误,那么回滚意义不大,相反地,没有回滚机制还能简化Redis的实现、加快Redis运行。
如果需要防止脏读、读未提交、不可重复读等问题,可以利用watch实现。
在上一节我们提到,管道中的命令相互独立,互不影响,但如果以事务的形式发出命令,就可以做到原子执行:
root@Yhc-Surface:~# printf 'multi\r\n*3\r\n$3\r\nset\r\n$5\r\nhello\r\n$5\r\nworld\r\n*2\r\n$4\r\nincr\r\n$9\r\ntestcount\r\nexec\r\n' | nc localhost 6379
+OK
+QUEUED
+QUEUED
*2
+OK
:3可以看到,两条指令在exec之后一起执行,即事务对管道起作用了。
事务的实现依靠multiState结构体(位于server.h):
typedef struct multiState {
multiCmd *commands; /* Array of MULTI commands */
int count; /* Total number of MULTI commands */
int cmd_flags; /* The accumulated command flags OR-ed together.
So if at least a command has a given flag, it
will be set in this field. */
int minreplicas; /* MINREPLICAS for synchronous replication */
time_t minreplicas_timeout; /* MINREPLICAS timeout as unixtime. */
} multiState;commands数组存放事务中执行的命令,watch则位于redisDb结构体:
typedef struct redisDb {
dict *dict; /* The keyspace for this DB */
dict *expires; /* Timeout of keys with a timeout set */
dict *blocking_keys; /* Keys with clients waiting for data (BLPOP)*/
dict *ready_keys; /* Blocked keys that received a PUSH */
dict *watched_keys; /* WATCHED keys for MULTI/EXEC CAS */
int id; /* Database ID */
long long avg_ttl; /* Average TTL, just for stats */
list *defrag_later; /* List of key names to attempt to defrag one by one, gradually. */
} redisDb;
watched_keys是dict类型,键为被watch的key,值则是这些key的redisClient结构体指针组成的链表(multiState实例存放在redisClient结构体中),如果redis执行写命令时,被写入的key在watched_keys中,则将其对应的redisClient的flags字段置为REDIS_DIRTY_CAS,当客户端exec时,如果发现了flags字段被标记,则拒绝执行。
而unwatch就不难理解了:读取watched_keys,从key对应的链表中,去除目标redisClient即可:
void unwatchAllKeys(client *c) {
listIter li;
listNode *ln;
if (listLength(c->watched_keys) == 0) return;
listRewind(c->watched_keys,&li);
while((ln = listNext(&li))) {
list *clients;
watchedKey *wk;
/* Lookup the watched key -> clients list and remove the client
* from the list */
wk = listNodeValue(ln);
clients = dictFetchValue(wk->db->watched_keys, wk->key);
serverAssertWithInfo(c,NULL,clients != NULL);
listDelNode(clients,listSearchKey(clients,c));
/* Kill the entry at all if this was the only client */
if (listLength(clients) == 0)
dictDelete(wk->db->watched_keys, wk->key);
/* Remove this watched key from the client->watched list */
listDelNode(c->watched_keys,ln);
decrRefCount(wk->key);
zfree(wk);
}
}3.脚本
Redis支持执行Lua脚本。该机制也是事务性的,即它是原子操作。
脚本的执行有三种方式:
1)eval script num_of_keys key ... arg ...:其中script就是Lua脚本的内容
2)script load script 配合 evalsha sha1 num_of_keys key ... arg ...:script还是Lua脚本的内容,不过可借助cat命令读取文件,例如:script load "${cat ~/test.lua}",script load命令会返回脚本的sha1值,将此作为参数传递给evalsha命令即可调用脚本
3)redis-cli --eval lua:这里的lua是指脚本文件的全路径
Redis提供的脚本管理命令有:
- script kill:杀掉正在运行中、且没有进行写操作的的脚本
- script exists sha1...:检查给定的这些sha1值有没有对应的脚本
- script flush:清空脚本缓存
- script debug yes|sync|no:设置脚本调试模式,yes代表非阻塞异步调试,但不会保留对数据的更改,sync代表阻塞的同步调试,并且保留对数据的更改(即脚本会真实执行),no代表关闭调试。关于脚本调试,可参阅:Redis Lua调试器
下面是一个eval的例子,注意这里的KEYS必须大写,如果要访问传入的参数,可以使用ARGV:
127.0.0.1:6379> eval 'return KEYS[1]' 1 hello
"hello"这个例子非常简单,如果想调用Redis API,可以使用redis.call()和redis.pcall(),两者的区别是,call方法遇到错误后会退出,pcall会继续执行:
127.0.0.1:6379> eval "return redis.call('get',KEYS[1])" 1 hello
"world"需要注意的是,Lua和Redis的数据格式不是完全相同的,不过可以自动转换:
- Redis数字< -> Lua数字
- Redis块 <-> Lua字符串
- Redis多重块 <-> Lua表
- Redis成功信息 <-> 仅包含一个'ok'行的表
- Redis错误信息 <-> 仅包含一个'error'行的表
- Redis nil <-> Lua中的false
- Redis 中的1 <- Lua 中的 true
此外,成功和失败信息还可以通过redis.status_reply()和redis.error_reply()函数返回,以下两个写法是等价的:
return {err="Error"}
return redis.error_reply("Error")众所周知,Lua脚本的一大特性就是可以利用C、C++进行扩展,Redis基于C编写,也因此为Lua提供了丰富的库,官方介绍有如下库:
- base
- table
- string
- math
- struct
- cjson
- cmsgpack
- bitop
- redis.sha1hex
- redis.breakpoint、redis.debug
详细介绍可参见:https://redis.io/commands/eval
4. 发布/订阅模式
在缓存学习(六):Redis的数据结构及基本命令中提到了Redis 5新加入的streams数据结构,它引入了Producer、Consumer、Consumer Group的概念,实现了类似于Kafka这样的 生产/消费 模式,但是在Redis 5之前,Redis提供了另一种数据交互模式,即 发布/订阅(Pub/Sub)模式。
和其他交互模式中客户端触发,服务端接收不同,发布订阅模式是客户端触发,其他客户端接收,服务端仅作为中转。涉及的命令如下:
- publish channel message:向指定频道发送消息
- subscribe channel ...:从一或多个频道订阅消息
- psubscribe pattern...:向匹配的频道订阅消息
- unsubscribe [channel ...]:取消对指定频道的订阅,如果不写明频道,则全部取消
- punsubscribe [channel ...]:取消对匹配到的频道的订阅,不写明匹配样式则全部取消
- pubsub subcommand [argument...]:用于检查Pub/Sub系统的情况,subcommand有如下可选值
- channels [pattern]:列出所有至少有一个订阅者,且不匹配pattern的频道
- numsub [channel ...]:返回指定频道的订阅数
- numpat:返回所有客户端订阅了哪些pattern,以及订阅数
这里可以看出,频道有两种:
- 普通频道:订阅者通过subscribe/unsubscribe将自己绑定到频道上,当发布者通过publish发送消息时,服务器会将消息转发给订阅者
- 模式频道:订阅者将自己绑定到模式频道上,当有消息发出时,服务端将普通频道和模式频道进行匹配,符合则将消息转发过去
匹配支持三种符号:?代表任意一个字符,*代表零到多个任意字符,[...]表示中括号内的某个字符出现一次
该机制在pubsub.c中实现,依赖了server.h中的redisServer结构体:
struct redisServer {
...
dict *pubsub_channels; /* channels a client is interested in (SUBSCRIBE) */
list *pubsub_patterns; /* patterns a client is interested in (SUBSCRIBE) */
...
}
typedef struct pubsubPattern {
client *client;
robj *pattern;
} pubsubPattern;
pubsub_channels的键是频道名称,值是其订阅者链表,pubsub_patterns维护了模式频道和订阅者的关系,内容就是pubsubPattern结构体实例,包含了模式和订阅它的客户端指针。
5.持久化
Redis本身是一个内存数据库,虽然一般用作缓存,但是本质上还是有持久化数据的需求,因此Redis提供了RDB(全量)和AOF(增量)两种持久化模式。
5.1 RDB
RDB在持久化触发时,将节点所有数据库的所有数据完全保存下来,形成快照。
它有如下优点:
- 完整持久化,适合用做备份
- 适合作为新节点数据同步,或灾难恢复的依据
- 默认使用LZF算法进行压缩,格式紧凑,占用空间比较小
- 在数据量较大时,相比AOF,RDB重启速度更快
- 可以使用子进程持久化,而不影响主进程提供服务
其缺点如下:
- 由于需要调用fork,如果数据量很大,会非常耗时
- 由于上一条原因,RBD持久化频率比较低,可能会导致较多的数据丢失
- 此外,RDB使用特定格式保存,可能由于版本更新导致的不兼容问题
RDB的触发主要有三种方式:
- save:主动触发持久化,将会以同步的方式备份数据,即此时服务器会停止对外服务
- bgsave:产生一个子进程在后台执行备份,主进程继续提供服务
- 自动触发:以上两种方式是用户手动进行触发,在缓存学习(五):Redis安装、配置介绍过,Redis提供了基于配置的自动触发机制,此外,在主从节点进行全量同步、执行shutdown且没有开启AOF、debug reload重启Redis这三种情况下,也会自动触发持久化
由于RDB持久化都需要fork子进程,所以bgsave其实也会阻塞一段时间,但是很短,影响不大。
RDB持久化的流程如下:
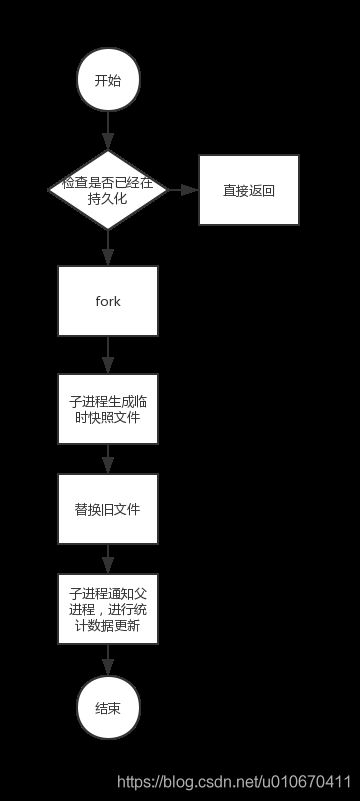
由于bgsave以异步方式备份,执行后立即返回“Background saving started”,如果要查询bgsave是否成功备份,可以用lastsave命令,检查在bgsave执行前后返回值是否改变。
RDB的自动备份时间点、文件名、存储位置都可以通过redis.conf配置,也可以通过config set dir、config set dbfilename在线修改。
如果RDB文件损坏,可以尝试使用redis-check-rdb工具进行检查。
5.2 AOF
RDB最大的问题就是无法实时备份,有数据丢失的风险,AOF可以记录服务器接受的写入操作(读取操作没有影响不必记录),在服务器启动时重新执行,即可实现状态的恢复。
AOF的原理是将写入操作记录到aof_buf中,然后根据指定的fsync策略定期刷写到磁盘中。
AOF的优点:
- 由于执行频率高,持久化效果更好,默认的fsync策略为每秒执行一次,即最多丢失1秒的写入操作
- AOF为仅附加日志,即使某次写入恰好遇到停电、宕机等异常,损失范围也很有限,之前的正常写入日志也可以用redis-check-aof工具修复
- 当aof文件过大时,Redis会可以通过重写来减少日志量
- RBD为十六进制文件,可读性不够好,AOF格式更容易阅读,因此可以直接编辑,这就意味着一旦因为失误调用了某些危害性大的命令,如flushall,完全可以立即强制关闭redis,然后修改aof文件,删除掉相关语句,再重启恢复
AOF的缺点主要是相同数据量下,AOF文件要比RDB大。
处于性能和效率的考量,一般将AOF和RDB结合使用,如果两者同时启用,会优先使用AOF。从server.c的main函数中,可以看到调用了loadDataFromDisk函数,它主要就是两个分支:
void loadDataFromDisk(void) {
if (server.aof_state == AOF_ON) {
...
} else {
...
}
}可见AOF启用后,Redis就不会主动加载RDB。原因很简单,一般而言AOF的数据都比RDB完整,兼容性和容错性也更好。
AOF重写的函数为bgrewriteaof,不过也会根据配置自动重写。
下面是一个破坏AOF文件并修复的例子:
首先开启AOF,然后进行一次set操作:
127.0.0.1:6379> config set appendonly yes
OK
127.0.0.1:6379> set 20190426 Friday
OK然后使用kill命令强制关闭Redis,并打开appendonly.aof文件(默认在~目录下),可以发现,它实际就是在RDB后面追加写日志,我们将set^M到Friday^M的部分删掉,再次启动Redis,可以发现,不但刚刚新增的键没了,之前加入的数据也没了:
127.0.0.1:6379> keys *
(empty list or set)再次关闭Redis,使用redis-check-aof工具检查aof文件,输出如下:
root@Yhc-Surface:~# redis-check-aof ~/appendonly.aof
The AOF appears to start with an RDB preamble.
Checking the RDB preamble to start:
[offset 0] Checking RDB file /root/appendonly.aof
[offset 26] AUX FIELD redis-ver = '5.0.4'
[offset 40] AUX FIELD redis-bits = '64'
[offset 52] AUX FIELD ctime = '1556263650'
[offset 67] AUX FIELD used-mem = '914520'
[offset 83] AUX FIELD aof-preamble = '1'
[offset 85] Selecting DB ID 0
[offset 842] Checksum OK
[offset 842] \o/ RDB looks OK! \o/
[info] 19 keys read
[info] 0 expires
[info] 0 already expired
RDB preamble is OK, proceeding with AOF tail...
0x 369: Expected to read 5 bytes, got 1 bytes
AOF analyzed: size=874, ok_up_to=865, diff=9
AOF is not valid. Use the --fix option to try fixing it.可见由于刚刚的修改使得aof文件中记录的日志长度和实际长度不符,于是没有进行数据恢复,我们按照提示使用--fix选项进行修复并启动Redis,此时发现以前的数据都回来了:
127.0.0.1:6379> keys *
1) "key1"
2) "key2"
3) "key3"
... //后略