MySQL binlog 增量数据解析服务
1. 起因
做过后端开发的同学都知道, 经常会遇到如下场景:
- 后端程序根据业务逻辑, 更新数据库记录
- 过了几天, 业务需求需要更新搜索索引
- 又过了几天, 随着数据需求方的增多, 结构改成发送数据到消息中间件(例如 Kafka), 其他系统自行从消息中间件订阅数据
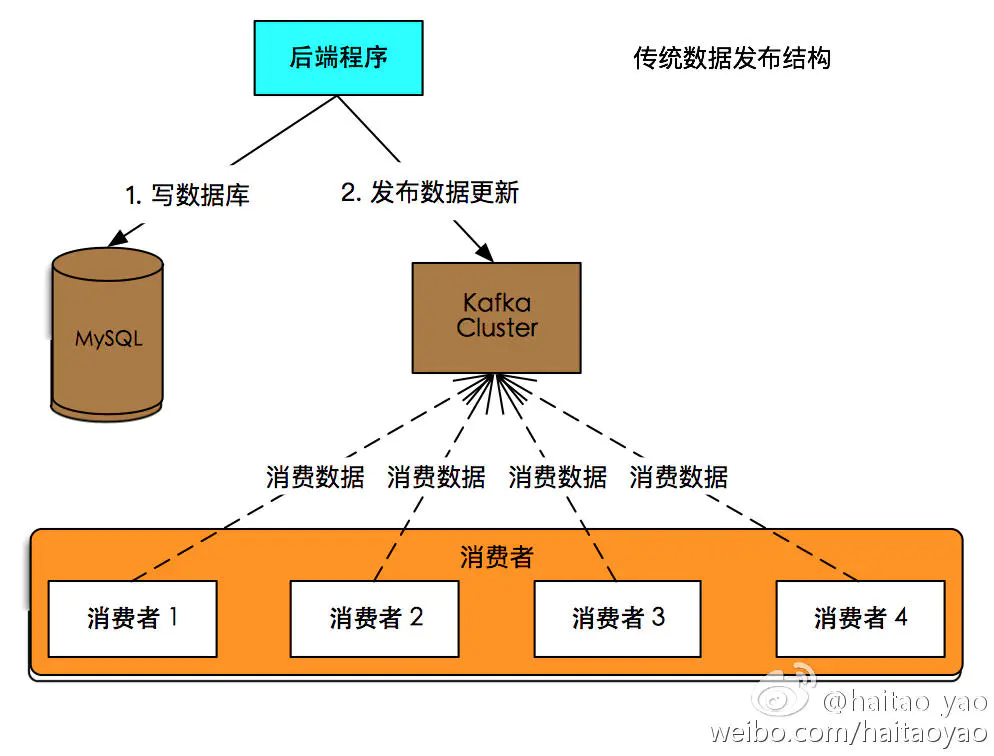
传统程序结构
所有涉及到类似需求的代码中都写了各种发送消息中间件的代码, 冗余, 易错, 而且难以保证一致性. 那么问题来了:
数据都在 MySQL 中, 是否可以实现仅仅更新 MySQL 就实现数据更新和发布逻辑?
2. Linkedin Databus
最早我听说的解决方案是 Linkedin 实现的, 参见
- Highscalability 文章: LinkedIn: Creating A Low Latency Change Data Capture System With Databus
- 论文: All aboard the Databus Linkedin's scalable consistent change data capture platform
核心思路就是通过数据库的 binary log(简称: binlog) 来实现数据库更新的自动获取. Linkedin 自己实现了 MySQL 版本和 Oracle 版本。
3. 原理
以 MySQL 为例, 数据库为了主从复制结构和容灾,都会有一份提交日志 (commit log),通过解析这份日志,理论上说可以获取到每次数据库的数据更新操作。获取到这份日志有两种方式:
- 在 MySQL server 上通过外部程序监听磁盘上的 binlog 日志文件
- 借助于 MySQL 的 Master-Slave 结构,使用程序伪装成一个单独的 Slave,通过网络获取到 MySQL 的binlog 日志流
这里有一个注意的点: MySQL 的 binlog 支持三种格式:Statement 、 Row 和 Mixed 格式:
Statement格式就是说日志中记录 Master 执行的 SQLRow格式就是说每次讲更改的数据记录到日志中Mixed格式就是让 Master 自主决定是使用Row还是Statement格式
由于伪装成 Slave 的解析程序很难像 MySQL slave 一样通过 Master 执行的 SQL 来获取数据更新,因此要将 MySQL Master 的 binlog 格式调整成 Row 格式才方便实现数据更新获取服务
至于 Oracle 的实现,我厂没用 Oracle。。。。
4. 数据增量同步服务拆解
好了, 如果想自己写一个 Databus 服务, 就需要如下几个核心模块:
- 4.1、MySQL binlog 解析类库
- 4.2、部署方式
- 4.3、binlog 状态维护模块
- 4.4、消息中间件(大多数人会选择 Kafka 吧)
- 4.5、数据发布策略
- 4.6、数据序列化方式
- 将获取到的 binlog 序列化成其他可识别格式
- AVRO、protocol buffer、JSON,哪个喜欢选哪个,但注意跨平台,别用 Java 原生的序列化 =.=|||
- 4.7、集群管理服务
- 4.8、服务监控
4.1、协议解析可选方案
时至今日, 已经有很多大厂开源了自己的 MySQL binlog 解析方案,Java 语言可选的有:
- mysql-binlog-connector-java
- 阿里巴巴开源的 Canal
- 点评开源的 Puma
想自己造轮子实现协议的,也可以参考 MySQL 官方文档
4.2、部署方式
由于 binlog 可以通过网络协议获取,也可以直接通过读取磁盘上的 binlog 文件获取, 因此同步服务就有两种部署方式:
- 通过读取 binlog 文件的话, 就要跟 MySQL Master 部署到同一台服务器
- 系统隔离性不好,高峰期会不会跟 MySQL master 争抢系统资源
- 类似 AWS RDS 这种云数据库服务,不允许部署程序到 RDS 节点
- 通过 relay-log 协议通过网络读取,同步服务就方便部署到任意地方

部署方式
4.3、binlog 状态维护模块
在 MySQL 中, Master-slave 之间只用标识:
- serverId:master一般设置为1, 各个 server 之间必须不同
- binlog 文件名称:当前读取到了哪一个 binlog 文件
- binlog position:当前读取的 binlog 文件的位置
由于同步服务会重启,因此必须自行维护 binlog 的状态。一般存储到 MySQL 或者 Zookeeper 中。当服务重启后,自动根据存储的 binlog 位置,继续同步数据。
4.4、消息中间件可选方案
虽然现在 Kafka 如日中天,大多数情况下大家都会选择 Kafka 作为消息中间件缓冲数据。选择其他的消息中间件也未尝不可。 但有一点注意:
- MySQL 中的数据更新是有顺序的
- 数据更新发布到消息中间件中,也建议能够保序,例如事务中经典的转账的例子,试想一下如果消息队列不保序, 其他数据服务消费到不保序的数据是否还能满足业务需求
由于上诉原因,类似 AWS SQS 这样的消息队列就不满足此处对消息队列的需求(参见:AWS SQS 官方文档关于保序方面的解释)
4.5、数据发布策略
解析到了数据,现在要做的就是将数据发布到消息中间件中。有一下几个方面需要注意:
4.5.1、topic 策略
一个 MySQL 节点中可以有多个数据库, 每个数据库有多张表,是采用一个节点一个 Kafka Topic,还是一个数据库一个 Topic, 还是一张表一个 Topic?
4.5.2、数据分区策略
Kafka 中数据是根据 key 进行分区, 同一个分区下保证消息的顺序。
如何选择数据的key的限制因素就是看数据消费端是否希望同一个表的同一条数据的更新记录都落到同一个 Kafka 分区上,进而不需要消费端做多进程间的状态维护, 简化消费端逻辑。例如: 一个Kafka Topic 有20个分区,同一个表 table_1 中 ID 为1的数据前后两次更新被发送到了不同的 partition,这就要求消费端必须每个 partition 保持lag一致, 并且及时同步数据状态到其他消费进程可见才可以保证保序; 但如果同一个表 table_1 中 ID 为1的数据前后两次更新被发送到了同一个 partition, 由于 Kafka 保证同一个 partition 保序,消费端就简化了很多。
如下图展示数据乱序问题:
- 假设 kafka 中
A2为新的数据,A1为同一个 ID 的老数据 - 由于
慢消费进程数据堆积,导致A2这个新数据先被消费, 当老数据A1被消费时有可能覆盖之前的结果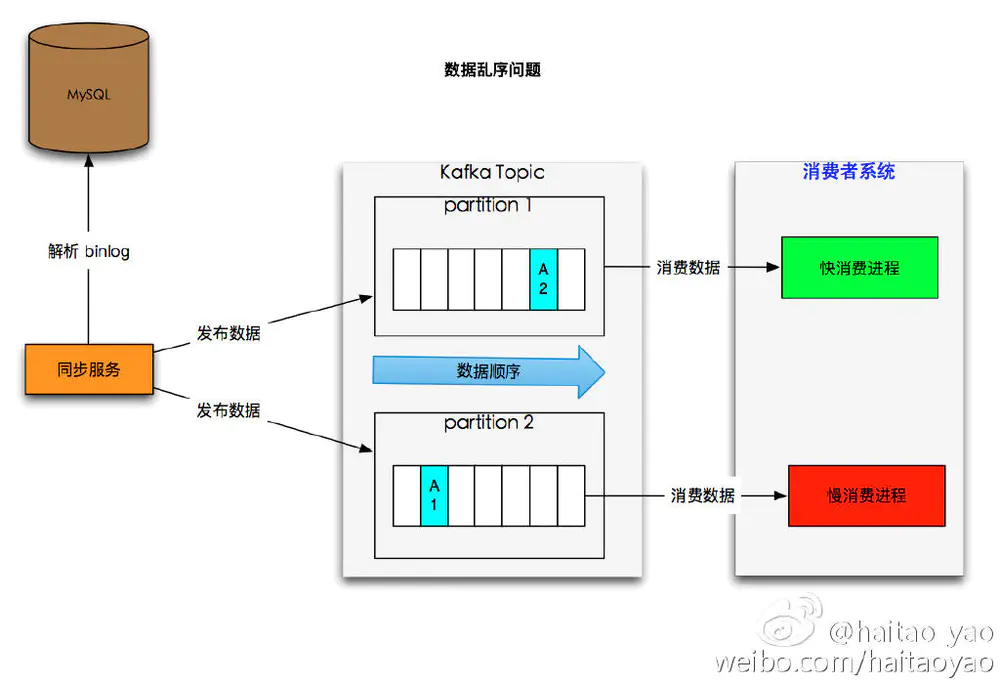
数据乱序问题
要实现上述的逻辑, 就要求在 Kafka 数据的 Key 的选择上做文章:
- 一种方式是使用 table 的名称作为 Kafka 的 key,这样同一张表的数据一定在一个 partition 上保序。 但这样的坏处是,如果数据集中在某一张表频繁更新,会造成某一个 partition 上数据量远大于其他 partition,消费端无法通过并行方式提高扩展性。
- 另一种方式就是,在 db 层面保证每张表的第一个 column 是主键,这样采用 binlog 中第一个 column 的数据作为 Kafka 的 key, 数据的平衡性会好很多,易于消费端扩容。
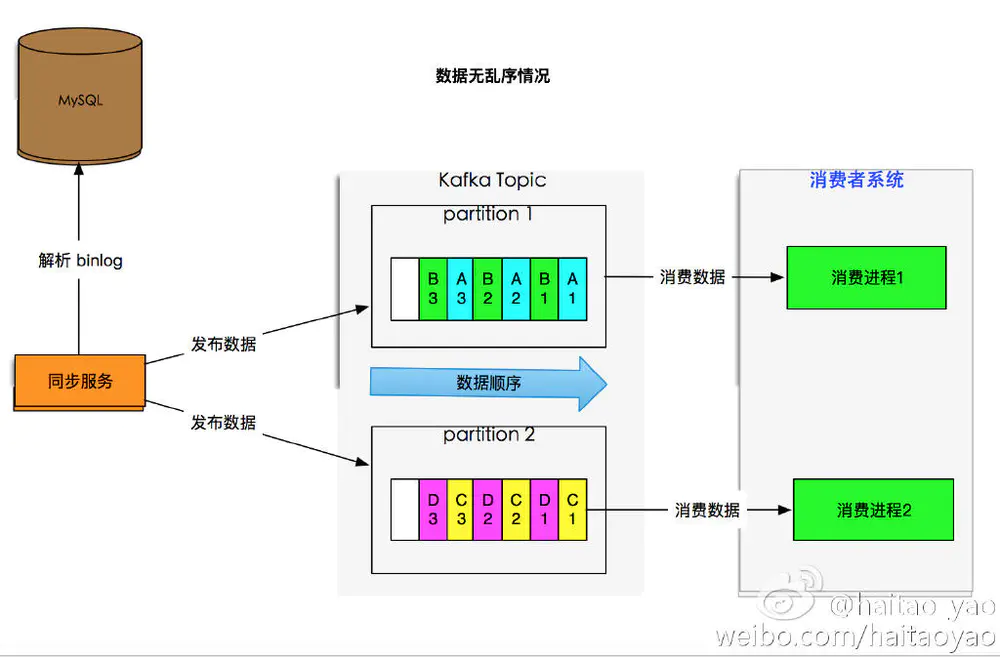
如下图,消息无乱序情况:
- 数据
A和C的每个版本由于 Hash 值 % 分区数量相同,同属于同一个分区, 并且按数据版本保序 - 数据
B和D同A、C, 数据按修改时间顺序保序但属于不同分区
4.6、数据序列化方式选择
读取到 binlog 数据后, 需要将数据序列化成更简单易用的格式,发送到 Kafka。如果选择 Avro 作为序列化方式的话,可以考虑集成 Kafka 背后的公司 Confluent 提出的一个新的方法:Schema Registry,具体信息参见 Confluent 公司官网。
4.7、集群管理服务
随着业务的扩展,越来越多的 MySQL 接入了数据同步服务。运维管理的压力也就随之而来。因此可能最后系统演变成如下结构:
- 独立一个集群管理程序,负责管理解析程序节点,分配任务
- 各个解析程序启动后,首先在 Zookeeper 注册,然后领取同步节点任务,启动解析过程
- 类似的任务管理结构很常见,比如 Storm 中 Nimbus 节点管理 worker 节点等。
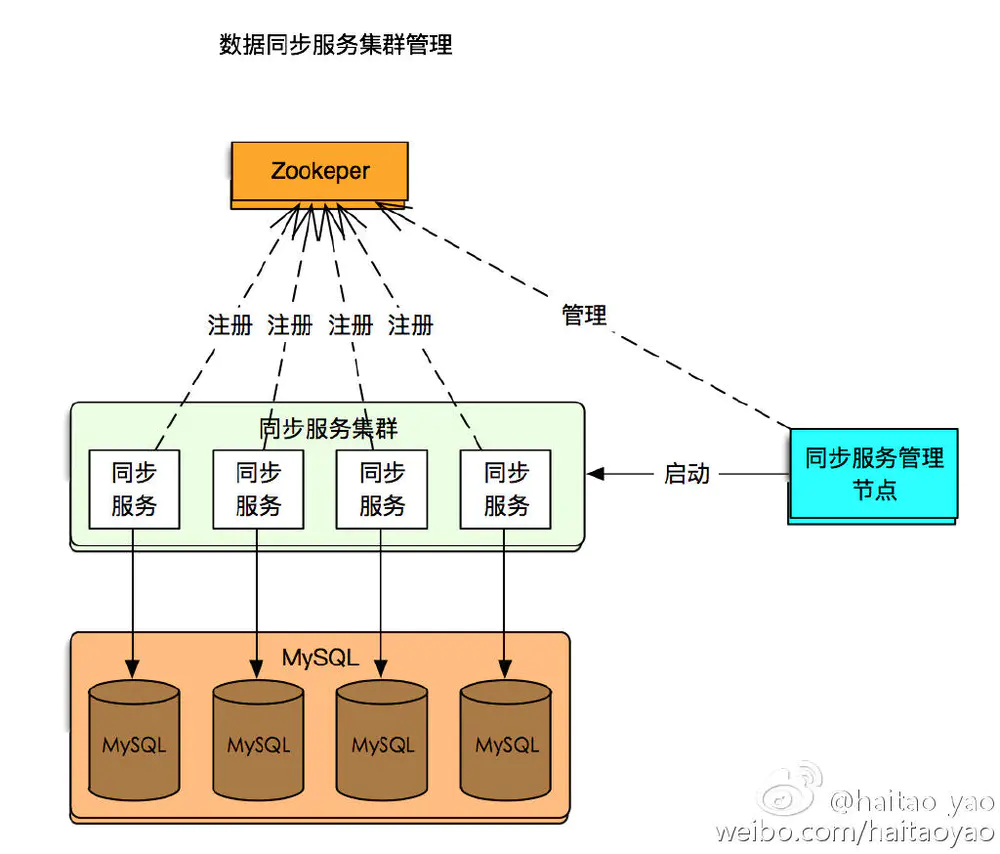
集群管理
4.8 服务监控
服务的监控必不可少。除了基础的进程监控,数据同步服务的关键是 binlog 解析服务与 MySQL master 之间的延迟监控,避免在 MySQL 写入高峰期导致数据延迟,影响后面的数据消费服务。
获取延迟的方法也很简单:
- 在 MySQL master 上实行
SHOW MASTER STATUS获取到 Master 节点当前的文件 ID 和 binlog 位置 - 获取同步服务当前处理的 binlog 文件 ID 和位置:
- 将相减的结果发送到监控服务(例如 open-falcon),后续根据需求报警
- 一般文件 ID 相减结果 N 大于1, 表示同步服务已经落后 MySQL Master N 个文件,情况比较严重(除非是 MySQL Master 刚刚 rotate 新文件)
- 文件 ID 相同,binlog 位置相减结果 M 就是相差的 binlog 文件大小, 单位: bytes
- 此计算公式仅仅为近似估算,建议在差距持续一段时间(比如持续2分钟)的情况下再报警。
5、踩过的坑
Canal Blob 类型字段编码
由于 Canal 将 binlog 中的值序列化成了 String 格式给下游程序,因此在 Blob 格式的数据序列化成 String 时为了节省空间,强制使用了 IOS_8859_0 作为编码。因此,在如下情况下会造成中文乱码:
- 同步服务 JVM 使用了 UTF-8 编码
- BLOB 字段中存储有中文字符
参见:
// com.alibaba.otter.canal.parse.inbound.mysql.dbsync.LogEventConvert 第541行起:
case Types.BINARY:
case Types.VARBINARY:
case Types.LONGVARBINARY:
// fixed text encoding
// https://github.com/AlibabaTech/canal/issues/18
// mysql binlog中blob/text都处理为blob类型,需要反查table
// meta,按编码解析text
if (fieldMeta != null && isText(fieldMeta.getColumnType())) {
columnBuilder.setValue(new String((byte[]) value, charset));
javaType = Types.CLOB;
} else {
// byte数组,直接使用iso-8859-1保留对应编码,浪费内存
columnBuilder.setValue(new String((byte[]) value, ISO_8859_1));
javaType = Types.BLOB;
}
break;
总结
通过实现数据同步服务,可以在一定程度上实现数据消费端与后端程序解耦。但凡事皆有成本,是否值得引入到现有系统架构中,还需要架构师自己斟酌。
-- EOF --
作者:haitaoyao
链接:https://www.jianshu.com/p/be3f62d4dce0
來源:简书
简书著作权归作者所有,任何形式的转载都请联系作者获得授权并注明出处。