1、用于处理内存中的数据
像SQL语句来操作数据库一样的形式。
2、Stream流的特点
(1)Stream流不可变,每次改变就会创建一个新的流
(2)Stream流也不会改变数据源的数据
(3)Stream的中间操作是一个延迟操作,一直到终结操作时,一起完成。
3、Stream API的使用分为三个步骤
(1)创建Stream
(2)0-n步中间操作
(3)终结操作
4、四种方式创建Stream
(1)通过Arrays.stream(数组)
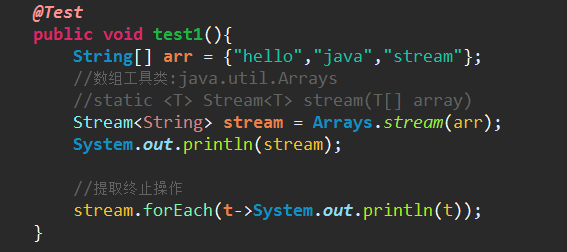
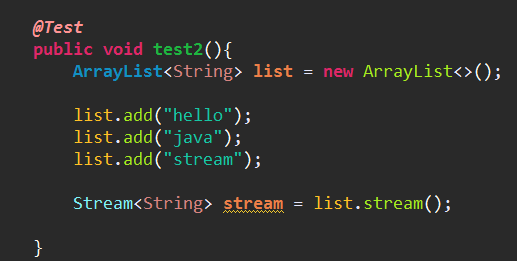
(2)通过集合对象.stream()
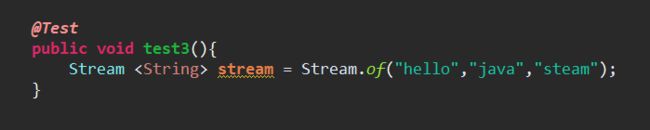
(3)Stream.of(…)
(4)创建无限流
Stream.generate(Supplier)
Stream.iterate(T seed,UnaryOperator)
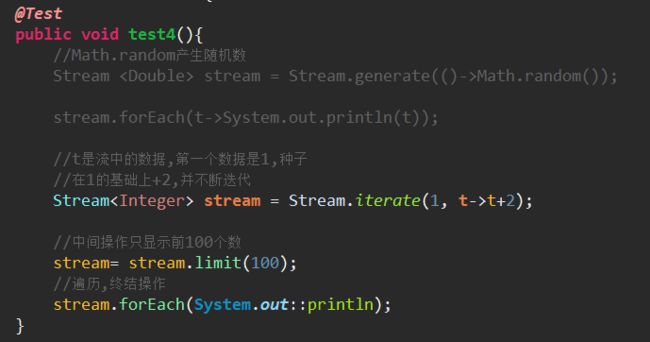
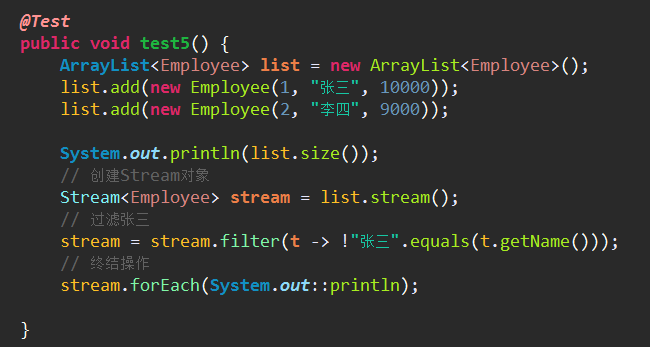
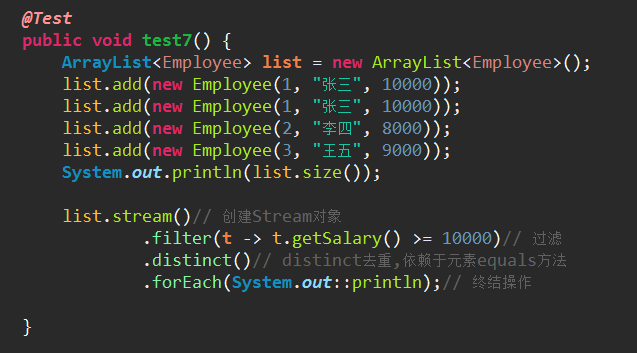
5、中间操作:这些方法的返回值类型还是Stream,所以可以继续再操作
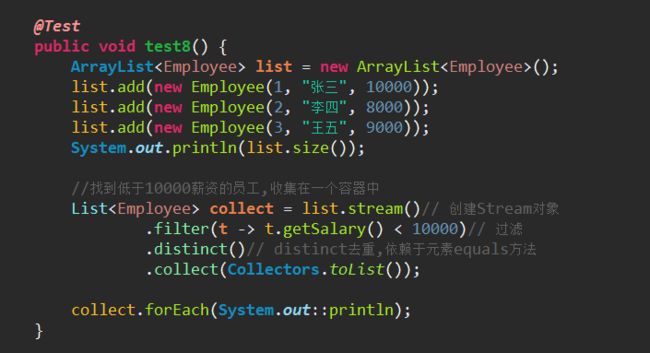
(1)filter(Predicate p):按照p的条件过滤
(2)distinct():去重复
(3)limit(long maxSize)取流中的前maxSize个
(4)skip(long n):跳过前n个
(5)peek(Consumer action):对流中的元素,挨个执行consumer接口的action操作
(6)map(Function f):对流中的每一个元素,都映射f指定的操作
(7)flatMap (Function f)
(8)sorted()
sorted(Comparator com)
6、终结操作:这些方法的返回值类型不是Stream,所以不能继续再操作,所以对Stream的操作就结束
一个流一旦终结就结束了,就不能用了,要再使用,需要重写创建新的Stream
(1)forEach(Consumer c)
(2)long count()
(3)Optional max(Comparatorc)
(4)0ptional min(Comparator c)
(5)boolean allMatch(Predicate p):所有都匹配
boolean anyMatch(Predicate p):有任一个匹配
boolean noneMatch(Predicate p):都不匹配
(6)R collect(Collector c)
Collectors 工具类提供了很多静态方法,可以方便地创建常见收集器实例。