motivation
想在脱离实验室,实际环境中使用
要做到:
强:要对噪音robust
对付来自人类的恶意:要对恶意的骗过机器的数据robust
侦测带有恶意的东西:垃圾邮件,恶意软件检测,网络侵入等
攻击
例子
在图片上加上特制的噪声,网络会得到不同的答案
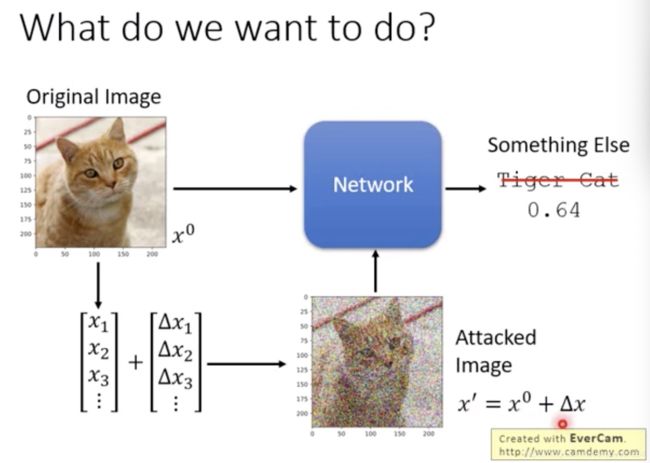
如何找出特制的噪声
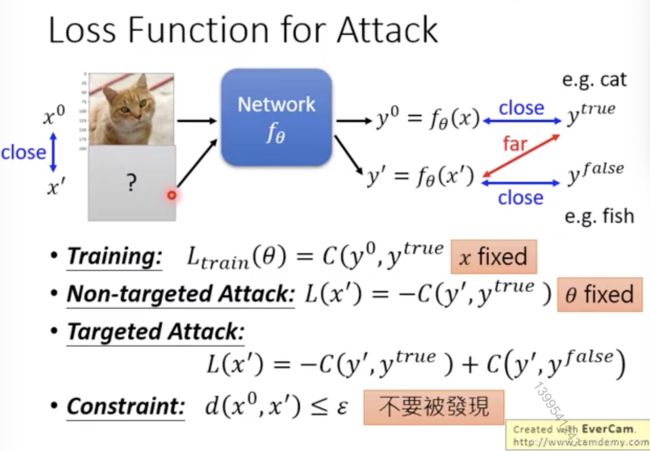
通常训练过程,最小化y‘和y_true间的距离
训练时:x是不变的,获得theta
攻击时,网络是不变的,固定theta,获得x’
没有目标的攻击:加上x‘,希望y’跟y_true越小越好
有目标的攻击:加上x‘,希望y’跟y_true越小越好,同时跟一个错误答案越近越好
额外的限制:x’和x越接近越好,不能被人发现
限制
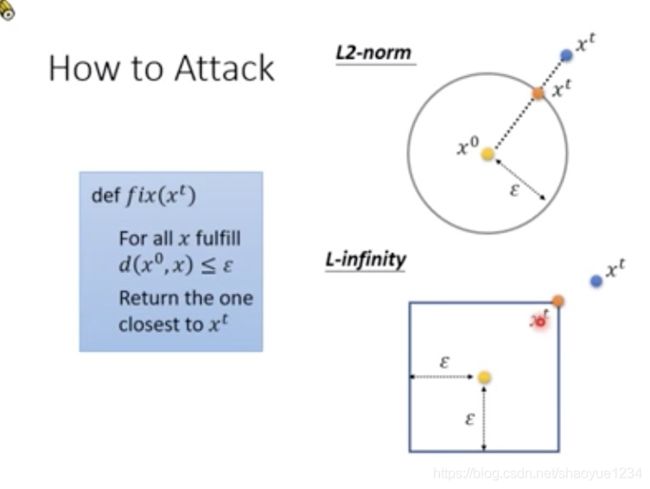
如何定义distance
图中的例子表示,在使用l-infinity时,值越大,人眼的分辨更明显些

how to Attack
想法:像训练神经网络一样,但是不是最小化时的参数theta,而是x’
做法:gradient Descent,但是加上限制
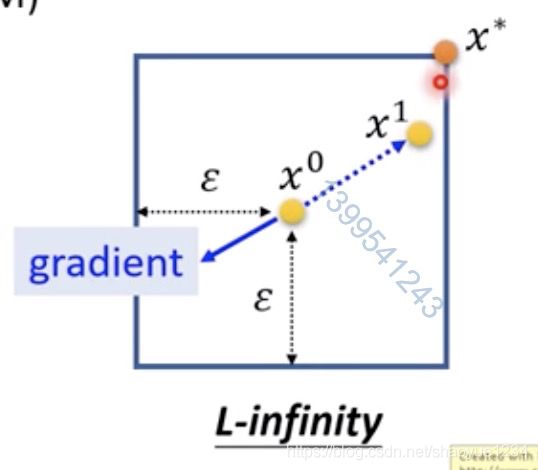
。判断xt是否符合限制,如果不符合,那么要修正xt
修正方法:穷举x0附近的所有xt,用符合限制的xt来取代

修正算法的图形化表示如下图,如果xt跑出圈圈范围外了,就把它抓回来。
实例
使用一个猫,让它输出海星

分析两张图片的不同,很小,要乘以50倍才能看出
把猫变成键盘

是否是因为网络很弱呢?
随机加噪声,但是对结果的影响不大,加的噪声逐渐增大以后会有影响
到底是因为什么呢?
x0随机移动,多数时候,在该点附近,网络判断为tiger cat的confidence很高
对于在高维空间中的一个点,有某些神奇的方向会出现这种现象:只要稍微推一点,预测为某个不相干的东西的confidence就会很高。但是整个网络在其他方向上比较长,在某个特定的方向比较窄。

攻击方法
不同方法主要区别在不同的限制和不同的优化方法。

FGSM(Fast Gradient Sign Method)
FGSM一种非常简单的方法。只更新一次,一次攻击成功

具体的做法是先求gradient,然后更新x0,它并不在意gradient的值,只在乎方向。
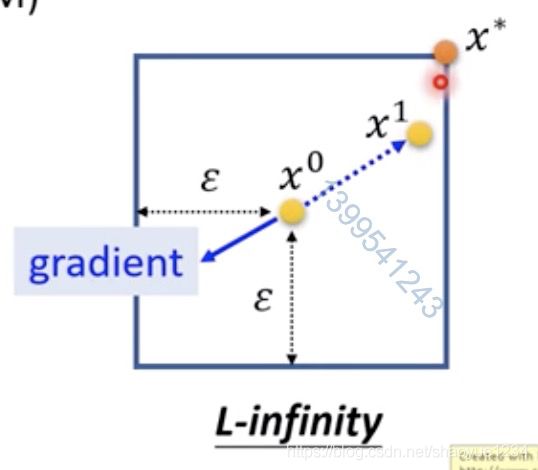
它的原理等于给了一个非常大的learning rate,所以一次update就能跑出范围,然后把它拉回对应的角。
它还有一种进阶的方法,可以多次更新。
白盒和黑盒
在之前的攻击中,我们都知道theta,去寻找最有的x’。
为了攻击,需要知道网络的参数theta,这种就是白盒攻击。
如果我们不知道网络,就安全了吗?
并不是的,因为可以进行黑箱攻击。
黑盒攻击
如果你能够得到目标网络的训练数据
可以训练一个proxy network网络
然后利用proxy network网络得到攻击数据,再来攻击原网络,往往能够成功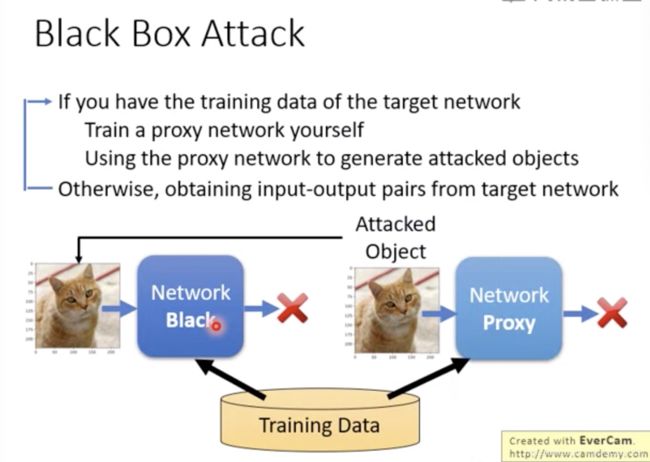
所以应该保护好训练资料,但是即便没有训练资料,也有可能进行攻击。
只要丢大量的数据过去,获得输出的结果,也能进行黑箱攻击。
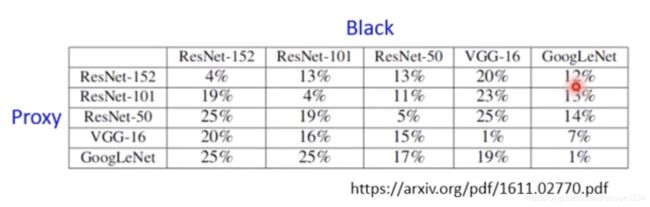
下表中表示黑箱攻击时,系统辨识的正确率。列表示用的proxy,行表示实际用的模型。数据越低,说明攻击效果越好。
衍生研究
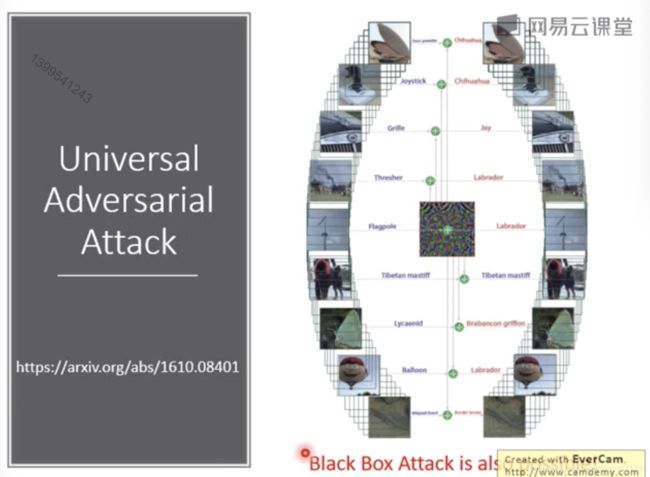
Universal Adversarial Attack
之前提到的攻击,对于每个图片x,会有不同的噪声x‘进行攻击,有人提出了通用的噪声,可以让所有图片的辨识结果都出错。
这个也可以做黑箱。
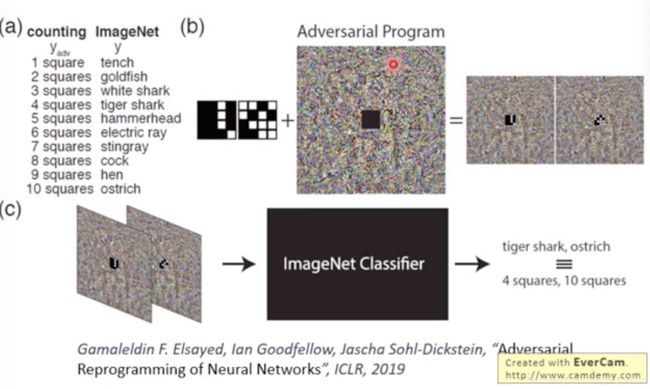
Adversarial Reprogramming
有一个辨识鱼的网络,可以将它改造成数方块的网络,根据方块的不同进行输出。
加一噪声,就能变成别的网络
真实世界的攻击
有人做实验,把攻击的图像打印出来,然后用图片放在摄像头上进行攻击。证明这种攻击时可以在现实生活中做到的。
可以对人脸识别上进行攻击,把噪声变成眼镜,带着眼镜就可以实现攻击。
结果表示,可以被辨识成其他人。
在现实生活中需要做的以下几点。
- 要保证多角度都是成功的
- 噪声不要有非常大的变化(比如只有1像素与其他不同),要以色块方式呈现,这样方便摄像头能看清
- 不要用打印机打不出来的颜色
在交通符号上加噪声。
其他方向的攻击
语音
文字

防御
有人说现在网络之所以会被攻击,是因为overfit,其实不然。通过regularization,dropout或者esemble时不能解决
两种类型
被动防御
不处理网络另外加一个防护罩,可以视为一种特殊的异常检测。

主动防御
主动攻击是在训练模型是就加上防御的思想。
被动防御
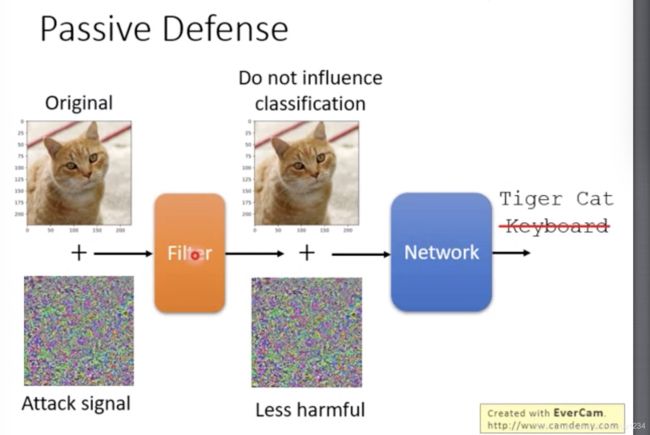
filter的一个例子:可以直接对图像进行平滑化。这种方法能够成功的原因,是改变了某个方向上突变的样子,但是不会改变图片的原意。
feature Squeeze
squeezer指的是不同的filter
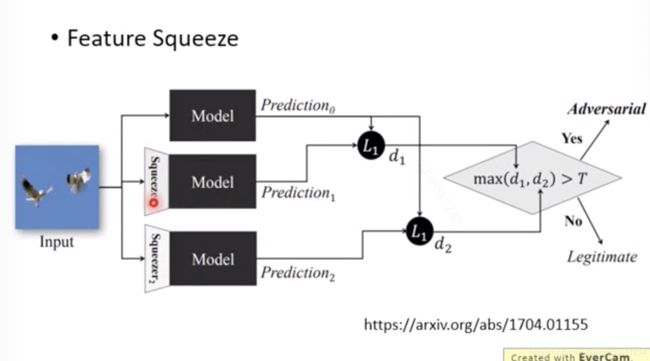
比较这些输出,如果区别很大就有问题。
Randomization at Inference Phase
稍微做些改变,看输出是否会有变化
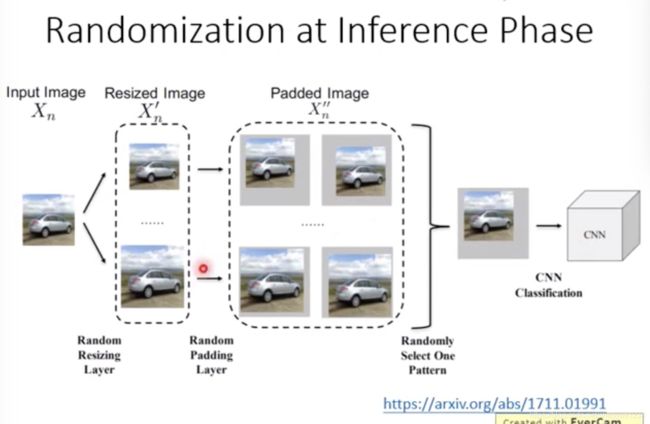
在model前面加盾牌的方法,如果filter被泄漏,仍然可能被攻击
主动防御
精神:训练network时把漏洞找出来,补好
给定训练资料,然后用训练集来训练模型
如何找漏洞呢?
训练T轮,找出每一个输入对应的的attack,然后把可以被attack成功的数据找出来,再把这些数据加上正确的label,当作新的资料,进行训练。
训练T轮是因为训练时参数会变,所以要找出新的漏洞,再补起来
如果你用A方法来找漏洞,但是被B方法攻击,可能仍然防不住
假设你的找漏洞的方法被泄漏出去,别人就可以不用这种方法,换一种方法攻击。
