Apache Atlas 2.0 安装部署详解 Atlas自带Hbase/Solr部署 && 独立部署
Apache Atlas 2.0 安装部署详解
- 背景
- 环境配置
- Atlas嵌入式Hbase与Solr的部署方式
- 1、下载源码并编译
- 2、Atlas 启动
- Atlas独立部署
- 1、Atlas独立编译
- 2、Kafka,Zookeeper安装
- 3、Hadoop安装
- 3.1、解压
- 3.2 、查看本机hostname
- 3.3、修改 hadoop-env.sh 配置文件
- 3.4、修改 core-site.xml 配置文件
- 3.5、修改 hdfs-site.xml 配置文件
- 3.6、复制 mapred-site.xml 文件并修改
- 3.7、修改 yarn-site.xml 配置文件
- 3.8、修改 start-yarn.sh 和 stop-yarn.sh 文件,在文件开头添加如下信息
- 3.9、修改 start-dfs.sh 和 stop-dfs.sh 文件,在文件开头添加如下信息
- 3.10、hdfs格式化
- 3.11、配置系统环境变量
- 3.12、设置免密登陆
- 3.13、启动Hadoop
- 4、Hive安装
- 4.1、解压
- 4.2、配置系统环境变量
- 4.3、修改 hive-site.xml 配置文件
- 4.4、将MySQL驱动放到如下目录
- 4.5、Mysql创建hive库
- 4.6、初始化hive库
- 4.7、执行hive命令并测试
- 5、Hbase安装
- 5.1、解压
- 5.2、配置系统环境变量
- 5.3、修改 hbase-env.sh 配置文件
- 5.4、修改 hbase-site.xml 配置文件
- 5.5、启动Hbase
- 6、Solr安装
- 6.1、解压
- 6.2、配置并启动Solr
- 7、Atlas配置并启动
- 7.1、修改 atlas-env.sh 配置文件
- 7.2、修改 atlas-application.properties 配置文件
- 7.3、Atlas 与 Hive 集成
- 7.3.1、修改hive-site.xml
- 7.3.2、修改hive-env.sh
- 7.3.3、hook-hive文件
- 7.3.4、atlas-application.properties 复制文件到 Hive 的conf目录下
- 7.3.5、Hive批量导入工具
- 7.4、Atlas 与 Sqoop 集成
- 7.4.1、解压
- 7.4.2、配置系统环境变量
- 7.4.3、修改sqoop-env.sh配置文件
- 7.4.4、修改sqoop-site.xml 配置文件
- 7.4.5、hook-sqoop文件
- 7.4.6、atlas-application.properties 复制文件到 Sqoop 的conf目录下
- 7.4.7、将/hook/sqoop/*.jar 复制到 Sqoop 的lib目录下
- 7.4.8、将数据库的驱动放到 Sqoop 的lib目录下
- 7.5、启动Atlas
- 7.5、使用Sqoop将DB中的数据导入Atlas
背景
公司在做一个数据治理的售前,选型为Apache Atlas 和 Azure Data Catalog,所以让我拥有了一次研究Apache Atlas的机会。之前从未接触过Atlas,发现网上相关的资料还不是很多,因此记录我在本地搭建Atlas的过程,供各位指正。
在搭建过程中,我分别使用了两种不同的搭建方式:
1、Atlas使用嵌入式Hbase与Solr的部署方式
2、Atlas独立部署(针对环境中已经存在了Hbase、Solr、Zookeeper以及Kafka的情况)
同时各位也可以参考Atlas官方:http://atlas.apache.org.
环境配置
1、Apache Atlas 2.0
2、JDK 1.8.0_251
3、Maven 3.6.3
4、Git
如果是使用Atlas内嵌Hbase与Solr的部署方式,只需上面的环境配置即可。
以下为独立部署时的配置:
5、Hadoop 3.1.1
6、Hbase 2.2.2
7、Hive 3.1.0
8、Solr 7.7.2
9、Zookeeper 3.4.14
10、Kafka 2.0.0
11、Sqoop 1.4.6
注意:Maven的版本需要3.5.0及以上版本,JDK需要Java 8 (Update 151)及以上版本,不然在报如下错误信息:
** MAVEN VERSION ERROR ** Maven 3.5.0 or above is required. See https://maven.apache.org/install.html
** JAVA VERSION ERROR ** Java 8 (Update 151) or above is required.
如果使用Java 9的话,会有如下警告:
** JAVA VERSION WARNING ** Java 9 and above has not been tested with Atlas.
Atlas嵌入式Hbase与Solr的部署方式
1、下载源码并编译
用户从Atlas官网下载Apache Atlas 2.0版本的源码

将源码 apache-atlas-2.0.0-sources.tar.gz 上传至对应的Linux服务器,并解压
tar -zxf apache-atlas-2.0.0-sources.tar.gz
配置 Maven 镜像仓库
vi $MAVEN_HOME/conf/settings.xml
在
repo1
central
Human Readable Name for this Mirror.
https://repo1.maven.org/maven2/
repo2
central
Human Readable Name for this Mirror.
https://repo2.maven.org/maven2/
进入到解压后的 Atlas 的根目录下
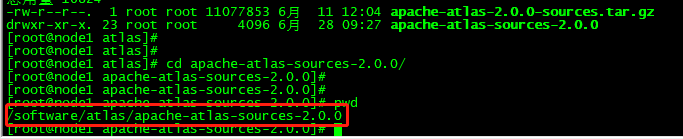
执行Maven编译打包
export MAVEN_OPTS="-Xms2g -Xmx2g"
mvn clean -DskipTests package -Pdist,embedded-hbase-solr
在编译过程中可能会发生编译中断的情况,请使用 mvn 命令进行多次编译,直至编译成功

使用此方式编译部署后,Hbase 和 Solr 服务将与Apache Atlas服务器一起启动 / 停止
此种方式仅用于单节点开发,不用于生产
2、Atlas 启动
Atlas编译成功后,会将编译好的文件放置在如下目录中
$Atlas_Source_Home/distro/target
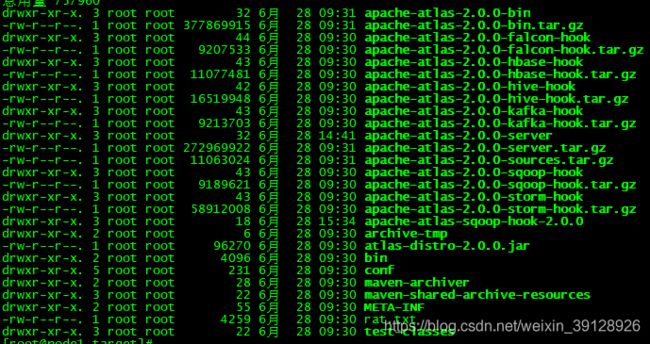
tar -xzvf apache-atlas-{project.version}-server.tar.gz
cd atlas-{project.version}
启动 Atlas
export MANAGE_LOCAL_HBASE=true (设置使用内嵌的zk和hbase)
export MANAGE_LOCAL_SOLR=true (设置使用内嵌的solr)
bin/atlas_start.py
启动完成后,可以使用如下命令验证
curl -u admin:admin http://localhost:21000/api/atlas/admin/version
{"Description":"Metadata Management and Data Governance Platform over Hadoop","Version":"1.0.0","Name":"apache-atlas"}
Atlas 初始化用户名密码为 admin
如果发生异常,请查看 Atlas 的日志
cat logs/application.log
在 Web 访问 Atlas
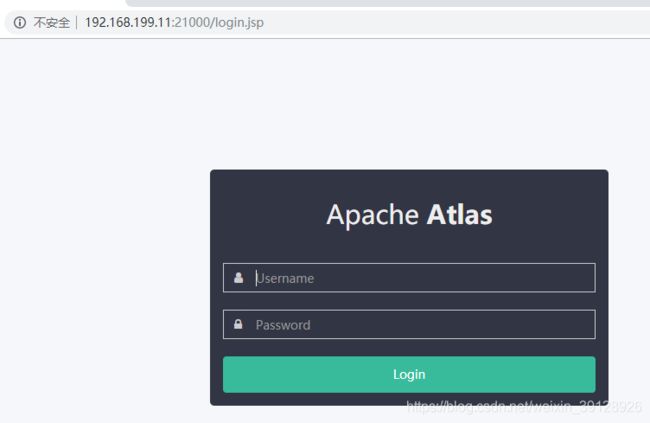
使用如下命令停止 Atlas
bin/atlas_stop.py
另外官网说可以使用
bin/quick_start.py
导入简单示例,但是我在本地报错,原因暂未找到
Atlas独立部署
1、Atlas独立编译
修改atlas源码工程的pom.xml,将hbase zookeeper hive等依赖的版本修改成自己环境中一致的版本
vim apache-atlas-sources-2.0.0/pom.xml
3.4.14
2.2.2
7.7.2
保存退出后,进入到 apache-atlas-sources-2.0.0 目录下,执行如下编译语句
mvn clean -DskipTests install
tar -xzvf apache-atlas-{project.version}-server.tar.gz
cd atlas-{project.version}
2、Kafka,Zookeeper安装
如果安装了docker,可以直接使用docker进行部署,使用镜像如下:
wurstmeister/kafka:2.11-2.0.0
zookeeper:3.4.14
3、Hadoop安装
下载:hadoop-3.1.1.tar.gz
3.1、解压
tar -zxvf hadoop-3.1.1.tar.gz
mkdir -p data/hadoop_repo
cd hadoop-3.1.1/
3.2 、查看本机hostname
![]()
3.3、修改 hadoop-env.sh 配置文件
vim etc/hadoop/hadoop-env.sh
export JAVA_HOME=/software/jdk/jdk1.8.0_251
3.4、修改 core-site.xml 配置文件
vim etc/hadoop/core-site.xml
fs.defaultFS
hdfs://node1:9000
hadoop.tmp.dir
/software/hadoop/data/hadoop_repo
3.5、修改 hdfs-site.xml 配置文件
vim etc/hadoop/hdfs-site.xml
dfs.replication
1
3.6、复制 mapred-site.xml 文件并修改
cp etc/hadoop/mapred-site.xml.template etc/hadoop/mapred-site.xml
vim etc/hadoop/mapred-site.xml
mapreduce.framework.name
yarn
3.7、修改 yarn-site.xml 配置文件
vim etc/hadoop/yarn-site.xml
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.nodemanager.env-whitelist
JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME
3.8、修改 start-yarn.sh 和 stop-yarn.sh 文件,在文件开头添加如下信息
vim sbin/start-yarn.sh
vim sbin/stop-yarn.sh
#!/usr/bin/env bash
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root
3.9、修改 start-dfs.sh 和 stop-dfs.sh 文件,在文件开头添加如下信息
vim sbin/start-dfs.sh
vim sbin/stop-dfs.sh
#!/usr/bin/env bash
HDFS_DATANODE_USER=root
HADOOP_SECURE_DN_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
3.10、hdfs格式化
hdfs使用前需要进行格式化(和格式化磁盘类似):不要频繁执行,如果出错,把hadoop_repo目录删除,在执行格式化
确保路径 /software/hadoop/data/hadoop_repo 存在
bin/hdfs namenode -format
3.11、配置系统环境变量
vim /etc/profile
#Hadoop
export HADOOP_HOME=/software/hadoop/hadoop-3.1.1
export HADOOP_COMMON_LIB_NATIVE_DIR=/software/hadoop/hadoop-3.1.1/lib/native
export HADOOP_OPTS="-Djava.library.path=/software/hadoop/hadoop-3.1.1/lib"
export PATH=$PATH:/software/hadoop/hadoop-3.1.1/sbin:/software/hadoop/hadoop-3.1.1/bin
保存退出并使之生效
source /etc/profile
3.12、设置免密登陆
ssh localhost
如果需要输入密码,则需要设置免密登陆
ssh-keygen -t rsa
三次回车
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
3.13、启动Hadoop
sbin/start-all.sh
访问:http://192.168.199.11:8088
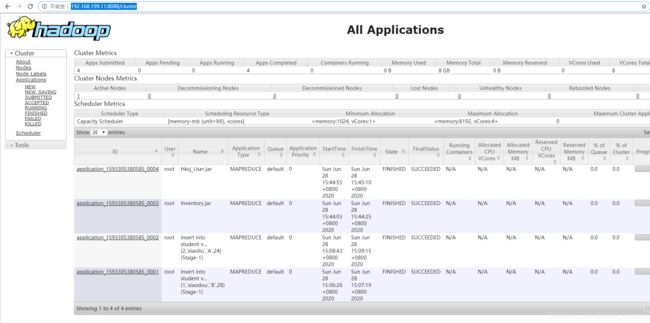
4、Hive安装
下载:apache-hive-3.1.0-bin.tar.gz
4.1、解压
tar -zxvf apache-hive-3.1.0-bin.tar.gz
cd apache-hive-3.1.0-bin/
4.2、配置系统环境变量
vim /etc/profile
#Hive
export HIVE_HOME=/software/hive/apache-hive-3.1.0-bin
export PATH=$HIVE_HOME/bin:$PATH
保存退出并使之生效
source /etc/profile
4.3、修改 hive-site.xml 配置文件
cp conf/hive-default.xml.template conf/hive-site.xml
vim conf/hive-site.xml
javax.jdo.option.ConnectionUserName
root
javax.jdo.option.ConnectionPassword
root
javax.jdo.option.ConnectionURL
jdbc:mysql://192.168.199.11:3306/hive
javax.jdo.option.ConnectionDriverName
com.mysql.jdbc.Driver
4.4、将MySQL驱动放到如下目录
$Hive_Home/lib
4.5、Mysql创建hive库
4.6、初始化hive库
cd bin/
schematool -dbType mysql -initSchema
4.7、执行hive命令并测试
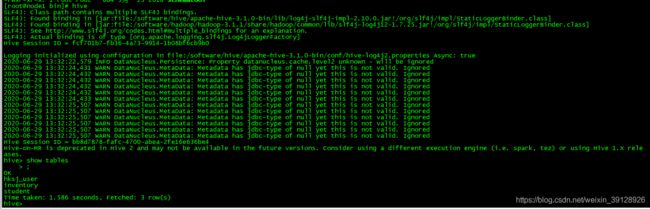
5、Hbase安装
下载:hbase-2.2.2-bin.tar.gz
5.1、解压
tar -zxvf hbase-2.2.2-bin.tar.gz
cd hbase-2.2.2/
5.2、配置系统环境变量
vim /etc/profile
#Hbase
HBASE_HOME=/software/hbase/hbase-2.2.2
export PATH=${HBASE_HOME}/bin:${PATH}
保存退出并使之生效
source /etc/profile
5.3、修改 hbase-env.sh 配置文件
vim conf/hbase-env.sh
export JAVA_HOME=/software/jdk/jdk1.8.0_251
5.4、修改 hbase-site.xml 配置文件
vim conf/hbase-site.xml
hbase.rootdir
hdfs://node1:9000/hbase
hbase.zookeeper.property.clientPort
2181
Property from ZooKeeper'sconfig zoo.cfg. The port at which the clients will connect.
hbase.tmp.dir
/software/hbase/data
hbase.zookeeper.quorum
node1
hbase.cluster.distributed
true
The mode the cluster will be in. Possible values are
false: standalone and pseudo-distributed setups with managed Zookeeper
true: fully-distributed with unmanaged Zookeeper Quorum (see hbase-env.sh)
hbase.unsafe.stream.capability.enforce
false
5.5、启动Hbase
bin/start-hbase.sh
查看Hbase的两个服务是否全部启动
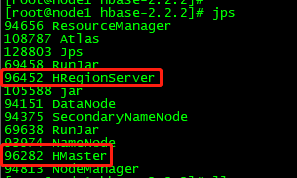
如果两个服务有未启动成功的,请查看具体日志
cat logs/hbase-root-master-node1.log
6、Solr安装
下载:solr-7.7.2.tgz
6.1、解压
tar -zxvf solr-7.7.2.tgz
cd solr-7.7.2/
6.2、配置并启动Solr
mkdir apache-atlas-conf
将$Atlas_Home下的solr conf复制到 $Solr_Home/apache-atlas-conf 目录下
cp -r /software/atlas/apache-atlas-sources-2.0.0/distro/target/apache-atlas-2.0.0-server/apache-atlas-2.0.0/conf/solr/ /software/solr/solr-7.7.2/apache-atlas-conf/
启动服务
./bin/solr start -c -z -p 8983
创建 collection
bash ./bin/solr create -c vertex_index -d ./apache-atlas-conf -shards 2 -replicationFactor 2 -force
bash ./bin/solr create -c edge_index -d ./apache-atlas-conf -shards 2 -replicationFactor 2 -force
bash ./bin/solr create -c fulltext_index -d ./apache-atlas-conf -shards 2 -replicationFactor 2 -force
7、Atlas配置并启动
7.1、修改 atlas-env.sh 配置文件
vim conf/atlas-env.sh
export HBASE_CONF_DIR=/software/hbase/hbase-2.2.2/conf
7.2、修改 atlas-application.properties 配置文件
vim conf/atlas-application.properties
atlas.graph.storage.backend=hbase
atlas.graph.storage.hbase.table=atlas
atlas.graph.storage.hostname=localhost:2181
#Solr
#Solr cloud mode properties
atlas.graph.index.search.solr.mode=cloud
atlas.graph.index.search.solr.zookeeper-url=localhost:2181
atlas.graph.index.search.solr.zookeeper-connect-timeout=60000
atlas.graph.index.search.solr.zookeeper-session-timeout=60000
atlas.graph.index.search.solr.wait-searcher=true
######### Notification Configs #########
atlas.kafka.zookeeper.connect=localhost:2181/kafka
atlas.kafka.bootstrap.servers=localhost:9092
atlas.kafka.zookeeper.session.timeout.ms=60000
atlas.kafka.zookeeper.connection.timeout.ms=30000
atlas.kafka.zookeeper.sync.time.ms=20
atlas.kafka.auto.commit.interval.ms=1000
atlas.kafka.hook.group.id=atlas
######### Entity Audit Configs #########
atlas.audit.zookeeper.session.timeout.ms=60000
atlas.audit.hbase.zookeeper.quorum=node1:2181
######### Hive Hook Configs #######
atlas.hook.hive.synchronous=false
atlas.hook.hive.numRetries=3
atlas.hook.hive.queueSize=10000
######### Sqoop Hook Configs #######
atlas.hook.sqoop.synchronous=false
atlas.hook.sqoop.numRetries=3
atlas.hook.sqoop.queueSize=10000
storage.cql.protocol-version=3
storage.cql.local-core-connections-per-host=10
storage.cql.local-max-connections-per-host=20
storage.cql.local-max-requests-per-connection=2000
storage.buffer-size=1024
atlas.ui.editable.entity.types=*
7.3、Atlas 与 Hive 集成
7.3.1、修改hive-site.xml
vim hive-site.xml
hive.exec.post.hooks
org.apache.atlas.hive.hook.HiveHook
7.3.2、修改hive-env.sh
vim hive-env.sh
export HIVE_AUX_JARS_PATH=/software/atlas/apache-atlas-sources-2.0.0/distro/target/apache-atlas-2.0.0-bin/apache-atlas-2.0.0/hook/hive
7.3.3、hook-hive文件
复制 apache-atlas-sources-2.0.0/distro/target/apache-atlas-hive-hook-${project.version}/hook/hive 全部内容到 apache-atlas-sources-2.0.0/distro/target/apache-atlas-2.0.0-server/apache-atlas-2.0.0/hook/hive
7.3.4、atlas-application.properties 复制文件到 Hive 的conf目录下
7.3.5、Hive批量导入工具
Usage 1: /hook-bin/import-hive.sh
Usage 2: /hook-bin/import-hive.sh [-d OR --database ] [-t OR --table ]
Usage 3: /hook-bin/import-hive.sh [-f ]
File Format:
database1:tbl1
database1:tbl2
database2:tbl1
如果在 hook-bin 目录下未找到 import-hive.sh
可以将下面路径下的文件复制过来
apache-atlas-sources-2.0.0/addons/hive-bridge/src/bin/import-hive.sh
7.4、Atlas 与 Sqoop 集成
下载:sqoop-1.4.6.bin__hadoop-2.0.4-alpha.tar.gz
7.4.1、解压
tar -zxvf sqoop-1.4.6.bin__hadoop-2.0.4-alpha.tar.gz
cd sqoop-1.4.6.bin__hadoop-2.0.4-alpha/
7.4.2、配置系统环境变量
vim /etc/profile
#Sqoop
export SQOOP_HOME=/software/sqoop/sqoop-1.4.6.bin__hadoop-2.0.4-alpha
export PATH=${SQOOP_HOME}/bin:$PATH
保存退出并使之生效
source /etc/profile
7.4.3、修改sqoop-env.sh配置文件
cp conf/sqoop-env-template.sh conf/sqoop-env.sh
export HADOOP_COMMON_HOME=/software/hadoop/hadoop-3.1.1
export HADOOP_MAPRED_HOME=/software/hadoop/hadoop-3.1.1
export HIVE_HOME=/software/hive/apache-hive-3.1.0-bin
7.4.4、修改sqoop-site.xml 配置文件
vim conf/sqoop-site.xml
sqoop.job.data.publish.class
org.apache.atlas.sqoop.hook.SqoopHook
7.4.5、hook-sqoop文件
复制 apache-atlas-sources-2.0.0/distro/target/apache-atlas-sqoop-hook-${project.version}/hook/sqoop全部内容到 apache-atlas-sources-2.0.0/distro/target/apache-atlas-2.0.0-server/apache-atlas-2.0.0/hook/sqoop
7.4.6、atlas-application.properties 复制文件到 Sqoop 的conf目录下
7.4.7、将/hook/sqoop/*.jar 复制到 Sqoop 的lib目录下
7.4.8、将数据库的驱动放到 Sqoop 的lib目录下
7.5、启动Atlas
bin/atlas_start.py
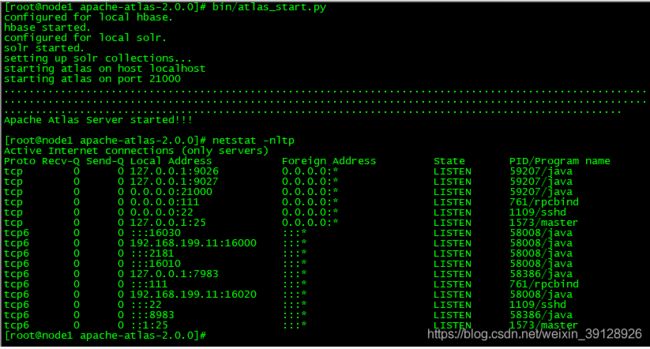
7.5、使用Sqoop将DB中的数据导入Atlas
sqoop import-all-tables --connect 'jdbc:sqlserver://192.168.199.11:1433;username=sa;password=Qq104105;database=TestDB' --hive-import --create-hive-table -m 1
参考文献:
https://blog.csdn.net/coderblack/article/details/104283606/
https://www.jianshu.com/p/8dc3cb5266e3
你可能感兴趣的:(Apache Atlas 2.0 安装部署详解 Atlas自带Hbase/Solr部署 && 独立部署)