移动安全--45--我设计的Java代码混淆解决方案
特别声明:本文是博主阅读大量硕博论文和知网文献后原创,非公司内部解决方案。
一 、Java代码混淆方案图
Java代码混淆方案整体架构图如下:
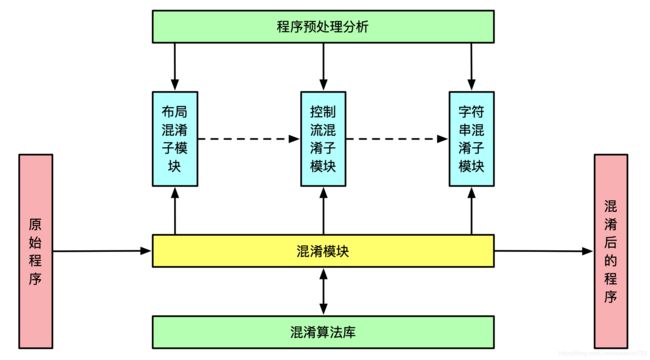
各模块功能简介:
程序预处理分析:对原应用程序进行程序分析预处理,为后续混淆奠定结构基础。
布局混淆模块:对代码中有意义的标识符进行重命名。
控制流混淆模块:对程序进行控制流混淆,包括插入多余的分支路径、压扁控制流、强化不透明谓词。
字符串混淆模块:加密隐藏代码中的常量字符串。
混淆算法库:对程序的混淆处理主要依靠混淆算法库支撑,算法库中包含一系列的基本块混淆算法。混淆算法库为可扩展。
本文先讲理论,后附上demo代码
二、混淆模块整体设计
混淆模块包括三部分:布局混淆、控制流混淆和字符串混淆。

三、布局混淆子模块
本模块核心思想:对代码中有意义的标识符进行重命名。
主要包括三步:构造包结构、构造继承树和标识符混淆。
3.1、混淆标识符说明
可以混淆的标识符包括:
1、包名
2、类或者接口名称
3、字段名
4、方法名
5、方法参数
6、局部变量
不可以混淆的标识符包括:
1、该实例方法实现父类抽象方法或接口方法
2、该实例方法覆盖父类的实例方法
3、被外部调用的方法
4、该方法为回调方法
5、系统不可混淆方法
3.2、布局混淆方法
Java应用代码主要有包结构和继承结构。每个类必定继承一个父类,默认为java.lang.Object类。每个类可以实现0个或多个接口,接口也可以继承接口。通过继承结构,可以识别出上面描述的前两类方法,并对其进行统一命名来保证多态性。
下图显示了一个Java程序的包结构图:

其对应的继承结构图如下所示:

3.3、布局混淆方法实行步骤
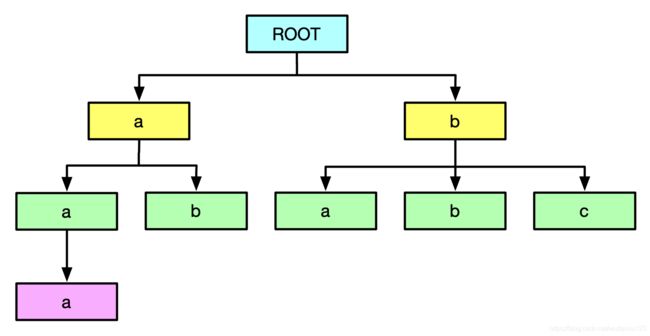
1、遍历类信息结构,构建包结构和继承结构,初始化包结构根节点为ROOT,继承结构根节点为Object。
2、从根节点遍历包结构,对于每个包节点的子节点,使用顺序生成名称代替原来的包结构名称。如果生成的名称序列为a、b、c、……,那么对于上图包结构图中所示,其混淆后的包结构将如下图所示:
3、遍历从根节点到叶子节点的继承结构,对于每种类型,执行以下操作:
1)为每个字段重新顺序生成名称。对于相同字段,使用相同的名称进行混淆。
2)为每个方法名重新顺序生成名称。需要注意的是,要保存其父节点已经遍历过的方法名,并判断该方法名是否可混淆,对于不可混淆的,不能混淆。
3)替换Java文件中所有的混淆名称。
3.4、布局混淆示例代码
源码:
public class Family{
static String father;
static String mother;
static String son;
static String daughter;
public void FamilyA(){
father = "wangjianlin";
mother = "liujuan";
son = "wangsicong";
daughter = "wangli";
}
public void FamilyB(){
father = "mayun";
mother = "zhangying";
son = "mahuateng";
daughter = "madongmei";
}
public static void main(String[] args) {
Family Family = new Family();
Family.FamilyA();
Family.FamilyB();
}
}
布局混淆后的代码:
public class a{
static String a;
static String b;
static String c;
static String d;
public void a(){
a = "wangjianlin";
b = "liujuan";
c = "wangsicong";
d = "wangli";
}
public void b(){
a = "mayun";
b = "zhangying";
c = "mahuateng";
d = "madongmei";
}
public static void main(String[] args) {
a a = new a();
a.a();
a.b();
}
}
四、控制流混淆子模块
说明:通过对Android源程序源码文件遍历,得到符合混淆条件的代码块;对代码块进行混淆操作,主要分为插入多余的分支路径、压扁控制流、强化不透明谓词三个步骤。
4.1、控制流混淆算法
在混淆方案中,为了控制性能开销,插入的分支路径实际上并不执行,压扁的结构中的语句包括实际路径和不执行的分支路径,而不透明谓词采用建立访问控制策略的形式的强化。
控制流混淆方案OBJ(P、Q、R、W、O)定义:
P:为原始程序代码
Q:为混淆后程序代码
B={b1,b2,b3,……,bn}:为原始程序代码中符合混淆条件的n个代码块的集合
BR:经过插入多余分支路径后的程序代码块集合
Bw:经过压扁控制流后的程序代码块集合。
R={r1,r2,r3,……,rn}:为n种不同类型的代码块对应可插入多余分支路径的集合
w={w1,w2,w3,……,wn}:为n种不同类型的代码块对应压扁控制流方法的集合
O:不透明谓词强化方法
●:插入多余分支路径
ⓧ:进行压扁控制流操作
⊕:强化不透明谓词操作
终极公式:Q=(B●Rⓧw)⊕O
语言描述:符合混淆条件的代码块集合先进行插入多余分支路径,再进行压扁控制流,最后强化不透明谓词。
控制流详细混淆方案详细过程如下:
1、对于P进行词法语法分析,遍历得到符合混淆条件的代码块集合B。
2、对代码块集合B分别进行插入多余的分支路径操作。对每一个属于B的代码块,在R中找到相应的插入分支代码类型,进行插入操作:(BR=B●R)
3、对插入多余路径后的代码块进行压扁控制流操作。对每一个属于BR的代码块,在w中找到相应的压扁控制流方法,进行压扁操作:(Bw=BRⓧw)
4、对压扁控制流后代码块进行不透明谓词强化操作:
(Q=Bw⊕O=(B●Rⓧw)⊕O)
5、将混淆后的程序Q返回给用户。
控制流混淆方案架构图:
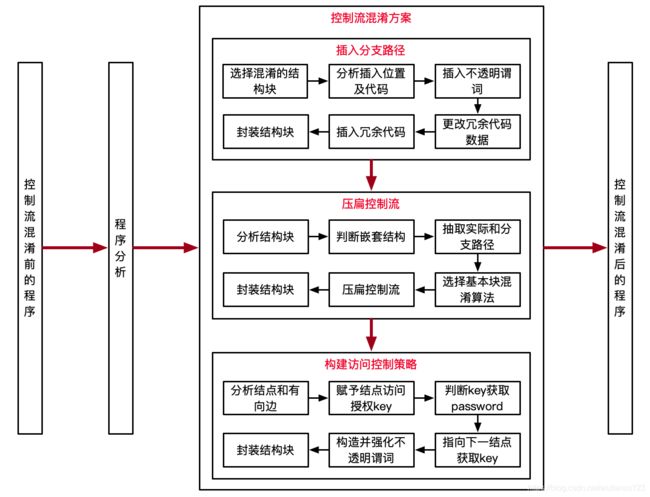
架构图解读:
1、在程序中插入实际并不执行的多余控制流路径。
首先,在分析完程序控制流结构的基础上,选取程序中完整的结构块,其控制结构可能包含多个判断或循环条件基本块,每个判断或条件基本块与其相关语句组成一个基本结构块,基本结构块中仍含有判断或条件基本块的结构块定义为嵌套结构块。
其次,在结构块中的嵌套结构前插入一个一定为真的不透明谓词,不透明谓词为假的一边中插入与嵌套结构块结构相同但数据按条件随机生成的代码,作为不执行的冗余结构块,冗余结构块最后的有向边指向代码中的下一个结构块。
最后,将它们封装成一个结构块。
2、对部分实际执行路径与插入的不执行的分支路径进行压扁处理,再封装。
3、构建访问控制策略,强化不透明谓词。
将整个程序不透明谓词的判断转化为图遍历问题,构建访问控制策略。每个封装好的结构块作为一个节点,节点之间的跳转作为一条边,每个节点的访问都需要该节点的key,以及通往下一个节点的password,程序通过这条边后,也就运行到了下一个节点,同时得到了访问下一个节点的key。
大致如下:

4.2、插入分支路径
插入多余的分支路径图:
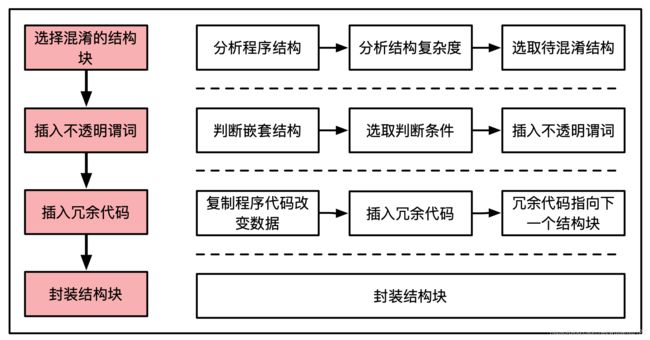
1、结构分析:
在程序中插入多余的分支路径的第一步就是要判断插入位置,这是在程序分析的基础上进行的。程序分析从最外层的结构开始,一层一层的分析程序嵌套结构和并列结构,直至最简单的基本块结构。
具体步骤为:
1)将最外层的结构视为一个结构块,分析其内部包含的判断或循环结构块,无论判断或循环结构块内部是否包含嵌套结构,都将其视为结构块;
2)重复上一步骤,对分析出的判断或循环结构块使用上一步的方法继续分析,直到分析的结构块为基本块。
说明:只选择结构嵌套层数为两层及以上的结构块进行控制流混淆。因为一层没有必要也没有意义做控制流混淆。
2、插入位置:
因为不透明谓词是判断条件,所以在嵌套结构中的第一个判断条件或循环条件前插入,使得添加插入的不透明谓词一定为真,保证控制流只会执行实际需要执行的路径。也可以插入一段不执行的嵌套结构,使得后续的压扁控制流后的结构看起来更复杂。
3、插入冗余代码:
在不透明谓词为假的边中插入不会执行的冗余代码,冗余的控制流在复制原基本块的基础上对数据进行改变。具体方法:
1)增加多余控制流中循环执行的次数以及将嵌套结构中的判断条件置反,并且将嵌套结构中执行的语句改为对变量的增减语句,如果嵌套结构中循环条件有上限,则执行语句中的变量增,反之,变量减,若为判断条件,则统一改为对变量的增语句。
2)然后插入不透明谓词为假的路径中,冗余的控制流最终指向下一个结构块。冗余代码中数据大小的改变必须与原语句不同,且在数据量级上保持同一水平,使得冗余代码看上去像原程序中实际执行的代码,能极大地保证混淆代码的隐蔽性。
4、将原结构块与插入的不透明谓词以及冗余代码封装成一个结构块,以进行压扁控制流处理。
4.3、压扁控制流
架构图如下:
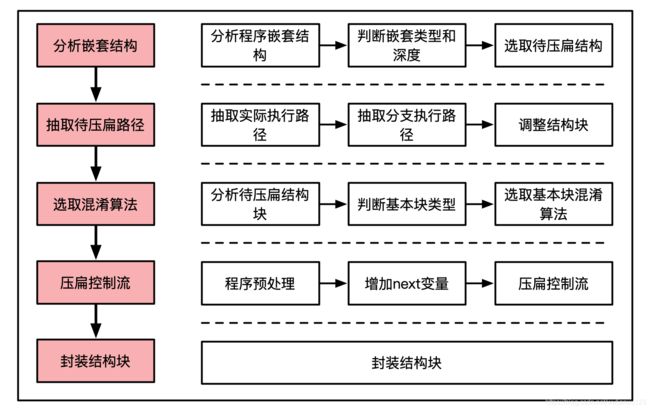
压扁前需要通过分析程序嵌套结构和条件基本块的类型确定压扁执行的次数以及调用基本块压扁控制流算法的类型。压扁控制流相关算法包括压扁控制流算法、条件基本块压扁控制流算法。
4.3.1、压扁控制流算法
功能:主要包括分析结构块嵌套深度(只分析原结构块),判断条件基本块类型以调用相关基本块压扁控制流算法,以及控制根据嵌套深度控制压扁次数。

4.3.2、条件基本块压扁控制流算法
压扁控制流实际上就是压扁程序中的嵌套结构,使之扁平化,破坏其控制流结构,增加分析程序的难度。
在进行压扁控制流处理时,需将嵌套结构视为一个条件基本块,逐层分析其嵌套类型,之后逐层的将嵌套结构中部分实际和分支控制流结构进行压扁。
4.3.2.1、if语句基本块压扁控制流算法
功能:主要是对if语句基本块进行抽取部分实际和分支路径进行压扁。
如果仅有一个if-else结构则直接退出,不进行压扁处理。
如果有多个if-else结构,则抽取实际和分支路径的前半部分作为待压扁结构,将其转换为switch结构,switch结构的输出作为余下实际路径的输入,继续执行if-else流程,剩下的分支路径将进行删除操作,以控制混淆带来的文件大小增长。
构造switch结构前,需要添加一个next变量和一个for循环,以支撑switch结构的运行。
构造switch结构时,优先实际执行的路径,每添加一条case语句,next增加1,按照控制流图中从上至下,从左至右的顺序依次添加至多余路径语句的case语句,但是最后一条case语句为嵌套结构中实际执行路径的最后一个子节点,插入的多余的分支路径按同样的步骤构造case语句插入到最后一条case语句之前。
if语句基本块压扁控制流算法图:

4.3.2.2、while语句基本块压扁控制流算法
功能:主要是对while语句基本块进行抽取部分实际和分支路径进行压扁。
对while语句基本块进行压扁前需要将循环条件构造为if语句,通过该if语句判断while语句基本块中的语句是否执行,以及执行的次数。
通过if条件分析出循环次数n,若n为偶数,保留前n/2次循环为原始结构,剩下后半部分n/2语句构造case语句。若n为奇数,则原始结构保留前(n+1)/2次循环,分支路径抽取的语句为循环次数比实际循环次数多的部分,构造case语句。
例如:循环了10次,前5次循环保留,后5次循环用来构造case语句。循环了9次,前5次循环保留,后4次用来构造case语句。
构造switch结构前,需要添加一个next变量和一个for循环,以支撑switch结构的运行。构造switch结构时,优先实际执行的路径,每添加一条case语句,next增加1,按照控制流图中从上至下,从左至右的顺序依次添加至多余路径语句的case语句,但是最后一条case语句为嵌套结构中实际执行路径的最后一个子节点。分支路径case语句插入最后一条case语句之前。
while语句基本块压扁控制流算法图:

4.3.2.3、for语句基本块压扁控制流算法
功能:主要是对for语句基本块进行抽取部分实际和分支路径进行压扁。
对for语句基本块进行压扁的首要步骤是分析循环执行的次数n,类似while语句基本块压扁控制流算法,抽取前半部分作为原始结构,仅对后半部分进行压扁控制流操作。然后,将其循环判断条件和语句中对循环判断因子进行操作的语句提取出来,分别对其构造case语句,使得压扁后的switch结构能实现for循环。
for语句基本块压扁控制流算法图:

4.3.2.4、switch语句基本块压扁控制流算法
功能:主要是对switch语句基本块进行抽取部分实际和分支路径进行压扁。
由于switch语句基本块的语句已经是case语句不需要再重新构造,但是由于需要抽取部分实际路径和分支路径,需要对next变量进行操作。
与其他条件基本块一样,对其抽取前半部分的实际和分支路径,然后分别对抽取的和未抽取的路径进行switch结构重包装。与压扁其他基本块不同,未抽取的switch结构中的多余的分支路径语句并不进行删除操作。对switch语句基本块的压扁操作实际上并不能算是压扁,仅仅是对其语句的结构进行重组。
switch语句基本块压扁控制流算法图:

4.3.2.5、do-while语句基本块压扁控制流算法
功能:主要是对do-while语句基本块进行抽取部分实际和分支路径进行压扁。
对do-while语句基本块的压扁控制流算法类似于while语句基本块压扁控制流算法,区别在于循环体的case语句要先执行,即其next的值相较于循环条件较小。在构造case语句时,应先对循环体中的语句进行case语句的构造,保证其next的值从0开始。
do-while语句基本块压扁控制流算法图:

4.3.2.6、try-catch语句基本块压扁控制流算法
将程序中try-catch结构的基本块分别放到相应的case语句块中,再压扁成一个switch结构。进行压扁操作时,将try、catch、finally基本块都看作一个整体,对这个整体进行case语句的构造,按照程序中异常处理的方式添加next变量,构造成switch结构。
需要注意的是,如果函数中有个循环会被频繁的执行,那么可以把这个循环归结为一个节点,然后再进行压扁。这样,循环中的各个基本块仍能集中在同一个case语句中,保持原有结构和执行效率不变,而不会被打散到各个case语句块中,引发较大的性能开销。
4.4、构建访问控制策略(强化不透明谓词)
构造访问控制策略:
将程序中各个封装好的结构块作为结点,结构块之间的执行顺序即结点之间的跳转作为一条边,每个结点的访问都需要该结点的key以及通往下一个节点的边的password,通过整合key、password以及访问路径可以构建程序访问控制策略。
每个结点的key为插入的不透明谓词的判断条件,即不透明谓词的构建可以通过构造一个单点函数(该函数只有在某个特殊的点上才会为真,其他情况全部为假),在计算判断结果的过程中,只有当输入正确的信息后,布尔值才会为真。如果判断条件有多个输入,可以把有限多个单点函数组合在一起,构成多点函数, 即只在一个给定的情况集合下为真,其他情况下均为假的函数。
不透明谓词的判断条件可以利用hash来进行保护,构建访问控制策略时,可以将key值事先保存在程序中的其他位置,在判断是否能访问节点时,将不透明谓词的条件的hash值与相应的key值进行匹配。
4.5、控制流混淆示例代码
源码:
public static void P(){
int x = 3;
int i = 0;
while (i < 4){
if (x <= 3){
x = 3;
i++;
}else{
x = 3;
}
}
}
插入冗余结构:
public static void P(){
int x = 3;
int i = 0;
if (x = 3){
while (i < 4){
if (x <= 3){
x = 3;
i++;
}else{
x = 3;
}
}
}else{ //if条件永远为真,此处永不执行
while (i < 6){
if (x <= 3){
x = 3;
i++;
}else{
x = 3;
}
}
}
}
压扁控制流:
public static void P(){
int x = 3;
int i = 0;
int next = 0;
if (x = 3){
while (i < 2){ //总共循环4次,保留前2次不变
if (x <= 3){
x = 3;
i++;
}else{
x = 3;
}
}
for ( ; ; ){ //for(i; i<4; i++)
switch(next){ //总共循环4次,后2次写入switch结构
//常规路径的case语句
case 0: if (1<i<4) next = 1; break;
case 1: if (x <= 3) next = 2; else next = 7; break;
case 2: x = 3; i++; next = 0; break;
//分支路径的case语句。分支路径中多余的while直接删除
case 3: if (4<i<6) next = 4; break;
case 4: if (x > 3) next = 5; else next = 6; break;
case 5: x++; i++; next = 3; break;
case 6: x++; break;
case 7: x = 3; break;
}
}
}
}
强化不透明谓词:
//对3进行SHA-256计算。该代码保存于其它位置
hash_x = 4e07408562bedb8b60ce05c1decfe3ad16b72230967de01f640b7e4729b49fce
强化不透明谓词之后的代码
public static void P(){
int x = 3;
int i = 0;
int next = 0;
//强化不透明谓词
if (x = hash_x){ //hash_x是对变量x(也就是数值3)进行SHA-256后的值
while (i < 2){ //总共循环4次,保留前2次不变
if (x <= 3){
x = 3;
i++;
}else{
x = 3;
}
}
for ( ; ; ){ //for(i; i<4; i++)
switch(next){ //总共循环4次,后2次写入switch结构
//常规路径
case 0: if (1<i<4) next = 1; break;
case 1: if (x <= 3) next = 2; else next = 7; break;
case 2: x = 3; i++; next = 0; break;
//分支路径。分支路径中多余的while直接删除(前3次)
case 3: if (4<i<6) next = 4; break;
case 4: if (x > 3) next = 5; else next = 6; break;
case 5: x++; i++; next = 3; break;
case 6: x++; break;
case 7: x = 3; break;
}
}
}
}
未做混淆的代码执行分析:
结果:
x = 3
i = 4
第一遍
i = 0
x = 3
第二遍
i = 1
x = 3
第三遍
i = 2
x = 3
第四遍
i = 3
x = 3
第五遍
i = 4
while循环失败,退出循环,程序执行结束。
做了混淆的代码执行分析:
结果:
x = 3
i = 4
第一遍
i = 0
x = 3
ne = 0
第二遍
i = 1
x = 3
ne = 0
第三遍
i = 2
while循环失败,退出while循环,进入switch
case 0
ne = 1
第四遍
case 1
i = 2
x = 3
ne = 2
第五遍
case 2
x = 3
i = 3
ne = 0
第六遍
case 0
i = 3
x = 3
ne = 1
第七遍
case 1
i = 3
x = 3
ne = 2
第八遍
case 2
x = 3
i = 4
ne = 0
第九遍
for循环失败,退出循环,程序执行结束。
五、字符串混淆子模块
本模块核心思想:隐藏代码中的常量字符串。
字符串混淆方法首先提取出定义的常量字符串,然后调用加密算法将字符串加密为字节数组,最后构造Java代码来存储得到的加密字节数组。
字符串混淆转换图:

5.1、关于密钥存储
博主之前也设计过一个密钥存储解决方案,不过被公司商用了,既然商用了那就不能公开了。整个方案还是非常复杂的!
大致原理是:先对待加密数据做对称加密处理,同时将密钥打散成若干密钥片段,将这些密钥片段运用拉格朗日插值多项式得出另外一串无关的字符串,之后删除原密钥与原密钥片段,并将该无关字符串再打散保存在图片的各个像素点中。解密时,从各个像素点中找回打散的无关字符串,对其并进行拉格朗日逆运算,得出若干密钥片段并组合成密钥,再运用密钥解密得出原文。
也可以使用其他安全的存储方案。
5.2、字符串混淆示例代码
我们继续使用布局混淆后的代码作为源代码使用
源代码:
public class a{
static String a;
static String b;
static String c;
static String d;
public void a(){
a = "wangjianlin";
b = "liujuan";
c = "wangsicong";
d = "wangli";
}
public void b(){
a = "mayun";
b = "zhangying";
c = "mahuateng";
d = "madongmei";
}
public static void main(String[] args) {
a a = new a();
a.a();
a.b();
}
}
提取常量字符串并加密为字节数组(此处使用了AES加密,密钥为123456):
这里需要构造Java代码来存储得到的加密字节数组,就不演示了。
String[] AES_data = {
"U2FsdGVkX1+MKsFUub3iw735uDNLcrqTf7IFoV+5SP0=",
"U2FsdGVkX18t8qdG8edKuvxuY9Sc9RtwR5ixY0nPkrM=",
"U2FsdGVkX1+j21T/0UxVBt+B2vj9bptp7GORCo8nO+E=",
"U2FsdGVkX18X4ibKJpnPwB6x+aC+RUUKUbnu5+fnXnQ=",
"U2FsdGVkX19AE6biwPt7TIWdMD4zbNtC5pjELU5/vEw=",
"U2FsdGVkX1+64L50tNYrncjYtzyzQO6/vCJN/Ew9v4s=",
"U2FsdGVkX18qy5BJf6Njw0tqeXObe0Nl6X1OvlGdVbY=",
"U2FsdGVkX18bHmicwKHTSKNtSga+gvBoN+XnGOz4bhU=",
};
字符串混淆后的代码:
public class a{
static String a;
static String b;
static String c;
static String d;
public void a(){
a = AES_data[0]; //此处时为了简写说明,实际中不能这样写,下同
b = AES_data[1];
c = AES_data[2];
d = AES_data[3];
}
public void b(){
a = AES_data[4];
b = AES_data[5];
c = AES_data[6];
d = AES_data[7];
}
public static void main(String[] args) {
a a = new a();
a.a();
a.b();
}
}
六、后记
本解决方案从三方面入手,通过布局混淆、控制流混淆、字符串常量混淆三管齐下对Java代码进行混淆,混淆强度大,破译难度高。但性能也会受影响,影响程度未做测试。
Java代码混淆还可以结合防调试、完整性保护、防HOOK注入等安全措施一起使用,效果会更好。至于这些安全措施的实现细节,博主日后再做研究。