Netty源码阅读之解码器简析
通过网络传输过来的数据,需要通过netty中的解码器进行处理,其中抽象类ByteToMessageDecoder中定义了相应的处理方法。
不妨先来围观下该类的继承关系:

由上图可以明白,该类实现了ChannelHandler这个接口,所以,说到底,解码器就是一个特殊的handler而已。
查看channelRead()方法:
public void channelRead(ChannelHandlerContext ctx, Object msg) throws Exception {
if (msg instanceof ByteBuf) { //查看是否是ByteBuf类型的数据
CodecOutputList out = CodecOutputList.newInstance();
try {
ByteBuf data = (ByteBuf) msg;
first = cumulation == null;
if (first) {
cumulation = data;//第一次进来,初始化累加器
} else {
cumulation = cumulator.cumulate(ctx.alloc(), cumulation, data);//对累加器进行累加操作
}
callDecode(ctx, cumulation, out);//调用子类进行解码操作
} catch (DecoderException e) {
throw e;
} catch (Throwable t) {
throw new DecoderException(t);
} finally {
if (cumulation != null && !cumulation.isReadable()) {
numReads = 0;
cumulation.release();
cumulation = null;
} else if (++ numReads >= discardAfterReads) {
// We did enough reads already try to discard some bytes so we not risk to see a OOME.
// See https://github.com/netty/netty/issues/4275
numReads = 0;
discardSomeReadBytes();
}
int size = out.size();
decodeWasNull = !out.insertSinceRecycled();
fireChannelRead(ctx, out, size);//向后传播channelRead事件
out.recycle();
}
} else {
ctx.fireChannelRead(msg);
}
}那么,通过上边的源码我们不难总结出解码的步骤:
1.累加字节流,也即想对ByteBuf进行写入等操作
2.调用子类的解码逻辑
3.将解码后的数据(ByteBuf)向后传播,提交给下一个步骤进行业务处理。
这里主要分析一下累加器的逻辑:
public static final ByteToMessageDecoder.Cumulator MERGE_CUMULATOR = new ByteToMessageDecoder.Cumulator() {
public ByteBuf cumulate(ByteBufAllocator alloc, ByteBuf cumulation, ByteBuf in) {
ByteBuf buffer;
if (cumulation.writerIndex() <= cumulation.maxCapacity() - in.readableBytes() && cumulation.refCnt() <= 1) {
buffer = cumulation;
} else {
buffer = ByteToMessageDecoder.expandCumulation(alloc, cumulation, in.readableBytes());//进行扩容操作
}
buffer.writeBytes(in);//向原有的缓存中添加数据
in.release();//释放新添加的资源
return buffer;
}
};Netty中预置了一些丰富的解码器,这里简单介绍下:
1.LineBasedFrameDecoder解码器
遇到\n或者\r\n将当前的数据段当做一个完整报文。
2.DelimiterBasedFrameDecoder解码器
以特定的结束符号作为消息结束的标志,分隔符号可以自己指定。
3.FixedLengthFrameDecoder 解码器
使用固定的长度进行解码,使用的时候并不需要考虑TCP的黏包/拆包问题。
4.LengthFieldBasedFrameDecoder 解码器
将报文分为报文头/报文体,根据报文中的LENGTH字段确定报文的长度。
对比前面三种解码器这个解码器略显复杂,
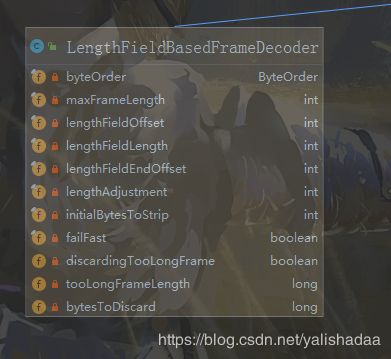
其中,maxFrameLength为发送的数据帧最大长度;lengthFieldOffset为长度区域初始下标;lengthFieldLength用于描述长度区域的长度;lengthAdjustment 为(发送字节的长度-长度域的大小);initialBytesToStrip为接收的数据发送包去除前initialBytesToStrip位;
failFast 默认值为true,读取到长度域超过maxFrameLength,就抛出一个 TooLongFrameException,当设置为false时,只有真正读取完长度域的字节之后,才会抛出 TooLongFrameException,默认情况下设置为true;
ByteOrder表示数据存储采用大端模式或者小端模式;
不妨通过官方给出的几个例子来做下简要说明:
ex1:
* lengthFieldOffset = 0
* lengthFieldLength = 2
* lengthAdjustment = 0
* initialBytesToStrip = 0
* 解码前 (14 bytes) 解码后 (14 bytes)
* +--------+----------------+ +--------+----------------+
* | Length | Actual Content |----->| Length | Actual Content |
* | 0x000C | "HELLO, WORLD" | | 0x000C | "HELLO, WORLD" |
* +--------+----------------+ +--------+----------------+ex2:
* lengthFieldOffset = 0
* lengthFieldLength = 2
* lengthAdjustment = 0
* initialBytesToStrip = 2
* 解码前 (14 bytes) 解码后 (12 bytes)
* +--------+----------------+ +----------------+
* | Length | Actual Content |----->| Actual Content |
* | 0x000C | "HELLO, WORLD" | | "HELLO, WORLD" |
* +--------+----------------+ +----------------+ex3:
* lengthFieldOffset = 0
* lengthFieldLength = 2
* lengthAdjustment = -2 (= the length of the Length field)
* initialBytesToStrip = 0
* 解码前 (14 bytes) 解码后 (14 bytes)
* +--------+----------------+ +--------+----------------+
* | Length | Actual Content |----->| Length | Actual Content |
* | 0x000E | "HELLO, WORLD" | | 0x000E | "HELLO, WORLD" |
* +--------+----------------+ +--------+----------------+ex4:
* lengthFieldOffset = 2
* lengthFieldLength = 3
* lengthAdjustment = 0
* initialBytesToStrip = 0
* 解码前 (17 bytes) 解码后 (17 bytes)
* +----------+----------+----------------+ +----------+----------+----------------+
* | Header 1 | Length | Actual Content |----->| Header 1 | Length | Actual Content |
* | 0xCAFE | 0x00000C | "HELLO, WORLD" | | 0xCAFE | 0x00000C | "HELLO, WORLD" |
* +----------+----------+----------------+ +----------+----------+----------------+ex5:
* lengthFieldOffset = 0
* lengthFieldLength = 3
* lengthAdjustment = 2 (= the length of Header 1)
* initialBytesToStrip = 0
* 解码前 (17 bytes) 解码后 (17 bytes)
* +----------+----------+----------------+ +----------+----------+----------------+
* | Length | Header 1 | Actual Content |----->| Length | Header 1 | Actual Content |
* | 0x00000C | 0xCAFE | "HELLO, WORLD" | | 0x00000C | 0xCAFE | "HELLO, WORLD" |
* +----------+----------+----------------+ +----------+----------+----------------+ex6:
* lengthFieldOffset = 1 (= the length of HDR1)
* lengthFieldLength = 2
* lengthAdjustment = 1 (= the length of HDR2)
* initialBytesToStrip = 3 (= the length of HDR1 + LEN)
* 解码前 (16 bytes) 解码后 (13 bytes)
* +------+--------+------+----------------+ +------+----------------+
* | HDR1 | Length | HDR2 | Actual Content |----->| HDR2 | Actual Content |
* | 0xCA | 0x000C | 0xFE | "HELLO, WORLD" | | 0xFE | "HELLO, WORLD" |
* +------+--------+------+----------------+ +------+----------------+相信通过以上的几个例子,相信读者能够大致了解LengthFieldBasedFrameDecoder 这个解码器的使用方法了。
注:参考内容
Netty黏包以及拆包相关资料:
什么是 TCP 拆、粘包?如何解决?