mysql中常见函数详解(建议收藏)
目录
前言:
一、单行函数(这里可以简单的理解为函数只处理单行字段,以此分类,那么后面就是分组函数或者叫聚集函数,意味处理多行字段,但都是输出一行字段)。
(一)字符函数
(二)数学函数
(三)日期函数
(四)其它函数
(五)流程控制函数
二、分组函数(聚集函数)
总结:
前言:
距离上一篇博客已经有一个多月了(劳逸结合emmmmm),这里对于mysql常见的函数做一个归纳,方便查询以及系统化的学习,建议多看多用->(调用方式均为select 函数名(实参列表) 【from 表】)。
一、单行函数
(这里可以简单的理解为函数只处理单行字段,以此分类;那么后面就是分组函数或者叫聚集函数,意味处理多行字段,但是输出都是一行字段)。
(一)字符函数
#1.length 获取参数值的字节个数(每个英文一个字节;中文需要看编码,utf8编码一个中文3个字节)
eg:
SELECT LENGTH('john'); 显示为4 #mysql中代码不区分大小写,但是建议关键字、函数大写,常量小写,所以以下均为此规范。
查看数据库编码集可以为:
SHOW VARIABLES LIKE '%char%'

#2.concat 拼接字符串
SELECT CONCAT(last_name,'_',first_name) FROM student; 从student表中查找姓名连接在一起
例如输出结果为: jack_john
#3.upper、lower 将字符变为大写/小写
SELECT UPPER('john');
#4.substr、substring 从下标pos开始往后截取字符输出,索引从1开始
#截取从索引处后面所有字符
SELECT SUBSTRING('读者是最棒的',4) 大实话;![]()
#截取从指定索引处指定字符长度的字符
SELECT SUBSTRING('读者是最棒的',1,2) 大实话;![]()
#5.instr 查询子串在主串中第一次出现的下标,找不到返回0
SELECT INSTR('你好吗','好');

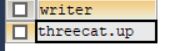
#6.trim 去掉前后空格/或指定字符
SELECT TRIM(' threecat.up ') AS 作者;

SELECT TRIM('a' FROM 'aaaaathreecat.upaaaaaa') AS writer;
#7.lpad 用指定的字符实现左填充指定长度
SELECT LPAD('threecat',10,'*');
![]()
#8.rpad用指定的字符实现右填充指定长度
SELECT RPAD('threecat',12,'~');
![]()
#9.replace 替换
SELECT REPLACE('threecat.up','th','qq') AS out_put;
![]()
(二)数学函数
#1.round 四舍五入
SELECT ROUND(-1.55);
![]()
SELECT ROUND(1.567,2);
![]()
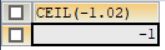
#2.ceil 向上取整,返回>=该参数的最小整数(向上记住其实就是找比它大的整数就好)
SELECT CEIL(-1.02);
#3.floor 向下取整,返回<=该参数的最大整数
SELECT FLOOR(-9.99);
![]()
#4.truncate 截断(其实就是截断小数点后面的几位,和round不同,简单的保留)
SELECT TRUNCATE(1.69999,1);
![]()
#5.mod取余
SELECT MOD(10,3);
(三)日期函数
#1.now 返回当前系统日期+时间
SELECT NOW();
#2.curdate 返回当前系统日期,不包括时间
SELECT CURDATE();
#3.curtime 返回当前时间,不包含日期
SELECT CURTIME();
#4.year month monthname day hour minute second可以获取时间指定的部分,年、月、日、小时、分钟、秒
SELECT YEAR(NOW()) 年;

SELECT MONTH(NOW()) 月;

SELECT MONTHNAME(NOW()) month; 返回英文的月份

#5.str_to_date 将日期格式的字符转换成指定格式的日期
SELECT STR_TO_DATE('9-13-1999','%m-%d-%Y');

#6.date_format:将日期转换成字符
SELECT DATE_FORMAT('2018/6/6','%Y年%m月%d日');
![]()
补充:其中上面的格式符规范如下
| 序号 | 格式符 | 功能 |
| 1 | %Y | 四位的年份 |
| 2 | %y | 两位的年份 |
| 3 | %m | 月份(01,02...12) |
| 4 | %c | 月份(1,2,...12) |
| 5 | %d | 日(01,02...) |
| 6 | %H | 小时(24小时制) |
| 7 | %h | 小时(12小时制) |
| 8 | %i | 分钟(00,01,...59) |
| 9 | %s | 秒(00,01...59) |
(四)其它函数
#1.VERSION(); 查看mysql版本
#2.DATABASE(); 查看当前数据库
#3.USER();查看当前用户
![]()
(五)流程控制函数
#1.if函数:if else的效果
SELECT IF(10>4,'大','小');
![]()
#2.case 函数
第一种效果格式如下(类似于switch case语句效果,等值判断):
case 要判断的字段或表达式
when 常量1 then 要显示的值1或语句1
when 常量2 then 要显示的值2或语句2
...
else 要显示的值n或语句n;
end
例如:查询员工工资,要求
部门号=30,显示的工资为1.1倍
部门号=40,显示的工资为1.1倍
部门号=50,显示的工资为1.1倍
其它部门,显示的工资为原工资
SELECT salary 原始工资,department_id,
CASE department_id
WHEN 30 THEN salary*1.1
WHEN 40 THEN salary*1.2
WHEN 50 THEN salary*1.3
ELSE salary
END AS 新工资
FROM employees;
第二种效果格式(区别在于CASE后面没有语句,所以类似于多重if功能,区间判断)
case
when 条件1 then 要显示的值1或语句1
when 条件2 then 要显示的值2或语句2
...
else 要显示的值n或语句n;
end
例如:查询员工的工资情况
如果工资>20000,显示A级别
如果工资>15000,显示A级别
如果工资>10000,显示A级别
否则,显示D级别
SELECT salary,
CASE
WHEN salary>20000 THEN 'A'
WHEN salary>15000 THEN 'B'
WHEN salary>10000 THEN 'C'
ELSE 'D'
END AS 工资级别
FROM employees;
二、分组函数(聚集函数)
sum求和、avg平均值、max最大值、min最小值、count计算个数。
例如:
SELECT SUM(salary) FROM employees;
SELECT AVG(salary) FROM employees;
需要注意的几个点:
1、sum、avg一般用于处理数值型,max、min、count可以处理任何类型
2、以上的分组函数都忽略null值.
3、可以和distinct搭配使用去重的运算
SELECT SUM(DISTINCT salary) FROM employees;
4、对于count函数的效率如下介绍:
MYISAM存储引擎下,COUNT(*)的效率高
INNODB存储引擎下,COUNT(*)和COUNT(1)的效率差不多,比COUNT(字段)要高一些
所以我们优先使用COUNT(*)。
5、和分组函数一同查询的字段要求是group by后的字段,否则会有限制(因为分组函数一般输出行,而其它的可能输出N行,不匹配显示就不完整了)。
总结:
建议收藏哦,希望有帮助,下次再见,拜拜~