MySQL底层架构:游走在缓冲与磁盘之间2w字(详细的不能再详细)
前言
提起MySQL,其实网上已经有一大把教程了,为什么我还要写这篇文章呢,大概是因为网上很多网站都是比较零散,而且描述不够直观,不能系统对MySQL相关知识有一个系统的学习,导致不能形成知识体系。为此我撰写了这篇文章,试图让这些底层架构相关知识更加直观易懂:
- 尽量以图文的方式描述技术原理;
- 涉及到关键的技术,附加官网或者技术书籍来源,方便大家进一步扩展学习;
- 涉及到的背景知识尽可能做一个交代,比如讨论到log buffer的刷盘方式,延伸一下IO写磁盘相关知识点。
好了,MySQL从不会到精通系列马上就要开始了(看完之后还是不会的话..请忽略这句话)。

可能会有同学问:为啥不直接学更加先进的TiDB,或者是强大的OceanBase。
其实,MySQL作为老牌的应用场景广泛的关系型开源数据库,其底层架构是很值得我们学习的,吸收其设计精华,那么我们在平时的方案设计工作中也可以借鉴,如果项目中用的是MySQL,那么就能够把数据库用的更好了,了解了MySQL底层的执行原理,对于调优工作也是有莫大帮助的。本文我重点讲述MySQL底层架构,涉及到:
- 内存结构:buffer pool、log buffer、change buffer,buffer pool的页淘汰机制是怎样的;
- 磁盘结构:系统表空间、独立表空间、通用表空间、undo表空间、redo log;
- 以及IO相关底层原理、查询SQL执行流程、数据页结构和行结构描述、聚集索引和辅助索引的底层数据组织方式、MVCC多版本并发控制的底层实现原理,以及可重复读、读已提交是怎么通过MVCC实现的。

看完文本文,您将了解到:
- 整体架构:InnoDB存储架构是怎样的 (1、MySQL架构)
- 工作原理:查询语句的底层执行流程是怎样的 (2、查询SQL执行流程)
- IO性能:文件IO操作写磁盘有哪几种方式,有什么IO优化方式 (3.1.2、关于磁盘IO的方式)
- 缓存:InnoDB缓存(buffer pool, log buffer)的刷新方式有哪些(3.1.2.2、innodb_flush_method)
- 缓存:log buffer是在什么时候写入到磁盘的(3.10.2、如何保证数据不丢失 - 其中第四步log buffer持久化到磁盘的时机为)
- 缓存:为什么redo log prepare状态也要写磁盘?(3.10.2、如何保证数据不丢失 - 为什么第二步redo log prepare状态也要写磁盘?)
- 缓存:脏页写盘一般发生在什么时候(3.10.2、如何保证数据不丢失 - 其中第五步:脏页刷新到磁盘的时机为)
- 缓存:为什么唯一索引的更新不可以借助change buffer(3.2、Change Buffer)
- 缓存:log buffer的日志刷盘控制参数innodb_flush_log_at_trx_commit对写性能有什么影响(3.4.1、配置参数)
- 缓存:buffer pool的LRU是如何实现的,为什么要这样实现(3.1.1、缓冲池LRU算法)
- 表存储:系统表空间的结构,MySQL InnoDB磁盘存储格式,各种表空间(系统表空间,独立表空间,通用表空间)的作用和优缺点是什么,ibdata、ibd、frm文件分别是干嘛的(3.5、表空间)
- 行字段存储:底层页和行的存储格式(3.6、InnoDB底层逻辑存储结构)
- 行字段存储:varchar,null底层是如何存储的,最大可用存储多大的长度(3.6.3.1、MySQL中varchar最大长度是多少)
- 行字段存储:行记录太长了,一页存不下,该怎么存储?(3.6.3.2、行记录超过页大小如何存储)
- 索引:数据库索引的组织方式是怎样的,明白为什么要采用B+树,而不是哈希表、二叉树或者B树(3.7、索引 - 为什么MySQL使用B+树)
- 索引:索引组织方式是怎样的,为什么大字段会影响表性能(查询性能,更新性能)(3.7、索引)
- 索引:覆盖索引、联合索引什么情况下会生效(3.7.2、辅助索引)
- 索引:什么是索引下推,索引下推减少了哪方面的开销?(3.7.2、辅助索引 - 索引条件下推)
- 索引:Change Buffer对二级索引DML语句有什么优化(3.2、Change Buffer)
- 数据完整性:MySQL是如何保证数据完整性的,redo log、undo log和buffer pool数据完整性的关键作用分别是什么(3.10.2、如何保证数据不丢失)
- MVCC:MVCC底层是怎么实现的,可重复读和读已提交是怎么实现的(3.11.2、MVCC实现原理)
- 双写缓冲区有什么作用(3.9、Doublewrite Buffer)
- Redo Log在一个事务中是在什么时候写入的?binlog和Redo Log有什么区别?(3.10.1、Redo Log在事务中的写入时机)
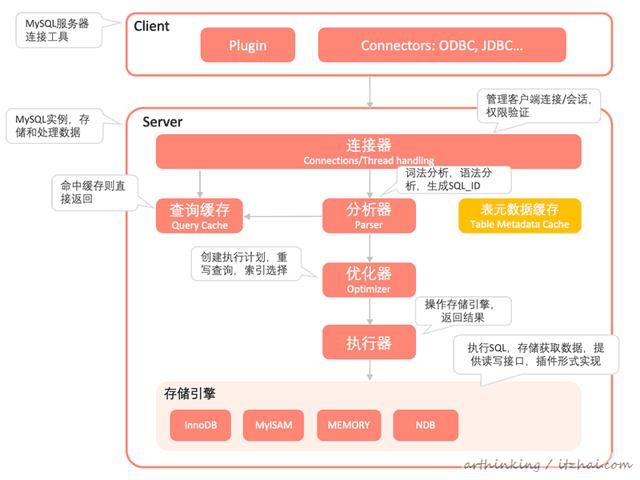
1、MySQL架构
如下图为MySQL架构涉及到的常用组件:
2、查询SQL执行流程
有如下表格:
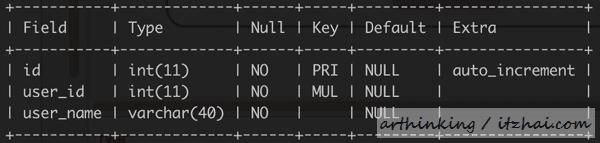
我们执行以下sql:
select * from t_user where user_id=10000; 2.1、MySQL客户端与服务器建立连接
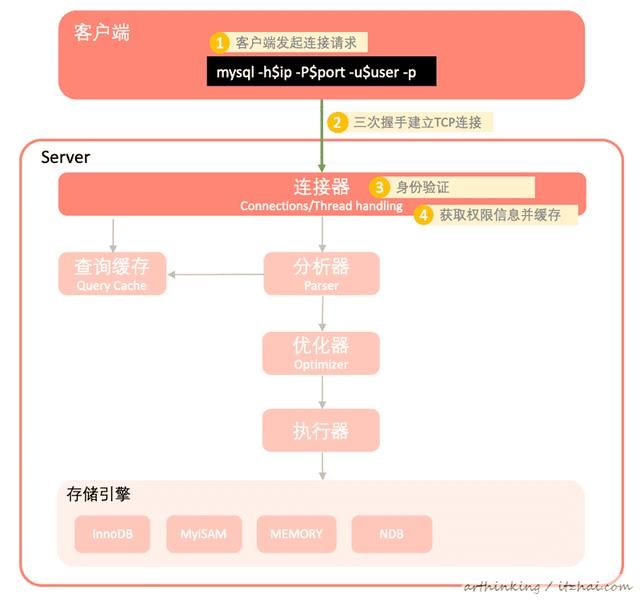
如下图,建立过程:
- 客户端通过mysql命令发起连接请求;
- 经过三次握手后与服务端建立TCP连接;
- 连接器接收到请求之后使用用户密码进行身份验证;
- 验证通过之后,获取用户的权限信息缓存起来,该连接后面都是基于该缓存中的权限执行sql;
对于Java应用程序来说,一般会把建立好的连接放入数据库连接池中进行复用,只要这个连接不关闭,就会一直在MySQL服务端保持着,可以通过show processlist命令查看,如下:

注意,这里有个Time,表示这个连接多久没有动静了,上面例子是656秒没有动静,默认地,如果超过8个小时还没有动静,连接器就会自动断开连接,可以通过wait_timeout参数进行控制。
2.2、执行SQL
如下图,执行sql:
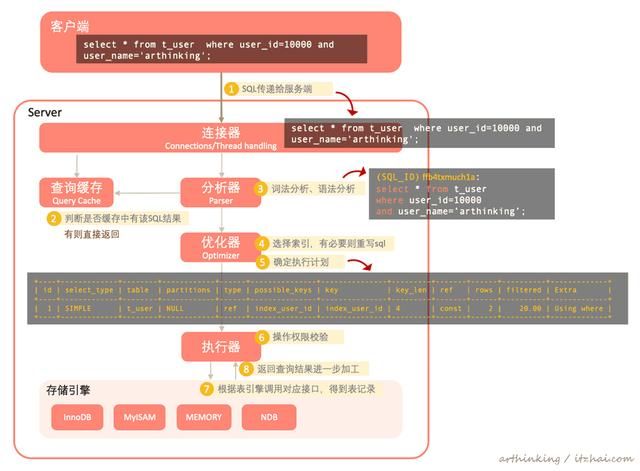
- 服务端接收到客户端的查询sql之后,先尝试从查询缓存中查询该sql是否已经有缓存的结果了,如果有则直接返回结果,如果没有则执行下一步;
- 分析器拿到sql之后会尝试对sql语句进行词法分析和语法分析,校验语法的正确性,通过之后继续往下执行;
- 优化器拿到分析器的sql之后,开始继续解析sql,判断到需要走什么索引,根据实际情况重写sql,最终生成执行计划;
- 执行器根据执行计划执行sql,执行之前会先进行操作权限校验;然后根据表存储引擎调用对饮接口进行查询数据,这里的扫描行数就是指的接口返回的记录数,执行器拿到返回记录之后进一步加工,如本例子:执行器拿到select * from t_user where user_id=10000的所有记录,在依次判断user_name是不是等于"arthinking",获取到匹配的记录。
3、InnoDB引擎架构
如下图,为存储引擎的架构:
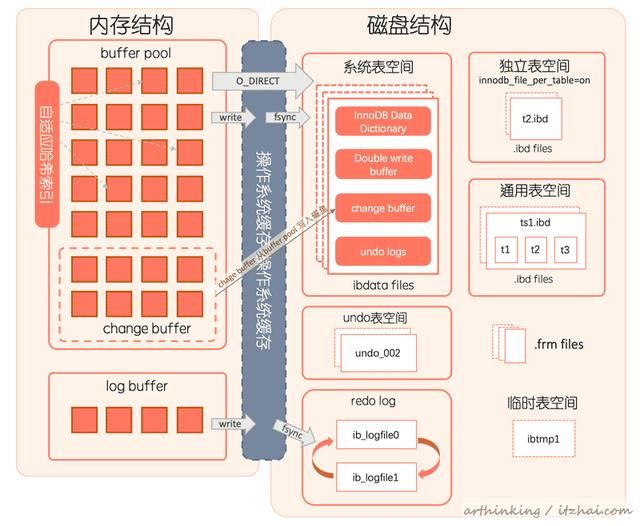
其实内存中的结构不太好直接观察到,不过磁盘的还是可以看到的,我们找到磁盘中MySQL的数据文件夹看看:
cd innodb_data_home_dir 查看MySQL 数据目录:
|- ib_buffer_pool // 保存缓冲池中页面的表空间ID和页面ID,用于重启恢复缓冲池 |- ib_logfile0 // redo log 磁盘文件1 |- ib_logfile1 // redo log 磁盘文件2,默认情况下,重做日志存在磁盘的这两个文件中,循环的方式写入重做日志 |- ibdata1 // 系统表空间文件 |- ibtmp1 // 默认临时表空间文件,可通过innodb_temp_data_file_path属性指定文件位置 |- mysql/ |- mysql-bin.000001 // bin log文件 |- mysql-bin.000001 // bin log文件 ... |- mysql-bin.index // bin log文件索引 |- mysqld.local.err // 错误日志 |- mysqld.local.pid // mysql进程号 |- performance_schema/ // performance_schema数据库 |- sys/ // sys数据库 |- test/ // 数据库文件夹 |- db.opt // test数据库配置文件,包含数据库字符集属性 |- t.frm // 数据表元数据文件,不管是使用独立表空间还是系统表空间,每个表都对应有一个 |- t.ibd // 数据库表独立表空间文件,如果使用的是独立表空间,则一个表对应一个ibd文件,否则保存在系统表空间文件中 innodb_data_home_dir[1]
ib_buffer_pool[2]
ib_logfile0[3]
ibtmp1[4]
db.opt[5]
接下来我们逐一来介绍。
3.1、buffer pool
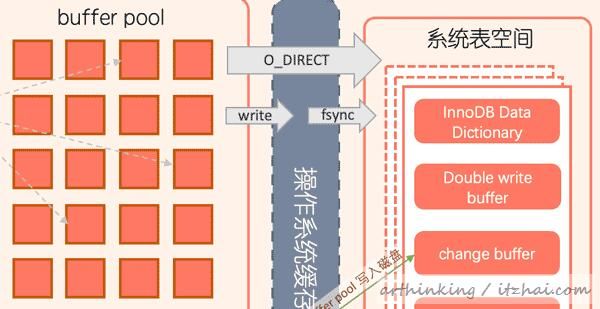
buffer pool(缓冲池)是主内存中的一个区域,在InnoDB访问表数据和索引数据的时候,会顺便把对应的数据页缓存到缓冲池中。如果直接从缓冲池中直接读取数据将会加快处理速度。在专用服务器上,通常将80%左右的物理内存分配给缓冲池。
为了提高缓存管理效率,缓冲池把页面链接为列表,使用改进版的LRU算法将很少使用的数据从缓存中老化淘汰掉。
3.1.1、缓冲池LRU算法
通过使用改进版的LRU算法来管理缓冲池列表。
当需要把新页面存储到缓冲池中的时候,将淘汰最近最少使用的页面,并将新页面添加到旧子列表的头部。
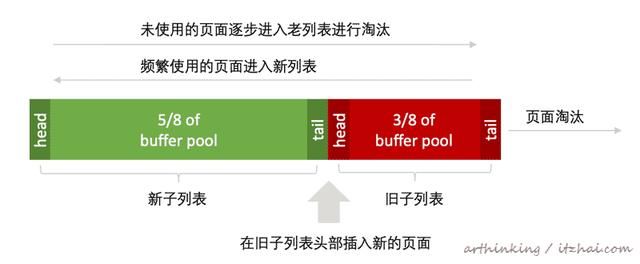
该算法运行方式:
- 默认 3/8缓冲池用于旧子列表;
- 当新页面如缓冲池时,首先将其插入旧子列表头部;
- 重复访问旧子列表的页面,将使其移动至新子列表的头部;
- 随着数据库的运行,页面逐步移至列表尾部,缓冲池中未被方位的页面最终将被老化淘汰。
相关优化参数:
- innodb_old_blocks_pct:控制LRU列表中旧子列表的百分比,默认是37,也就是3/8,可选范围为5~95;
- innodb_old_blocks_time :指定第一次访问页面后的时间窗口,该时间窗口内访问页面不会使其移动到LRU列表的最前面。默认是1000,也就是1秒。
innodb_old_blocks_time很重要,有了这1秒,对于全表扫描,由于是顺序扫描的,一般同一个数据页的数据都是在一秒内访问完成的,不会升级到新子列表中,一直在旧子列表淘汰数据,所以不会影响到新的列表的缓存。
3.1.2、关于磁盘IO的方式
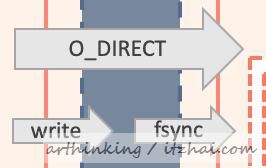
O_DIRECT是innodb_flush_method参数的一个可选值。
这里先介绍下和数据库性能密切相关的文件IO操作方法
3.1.2.1、文件IO操作方法
数据库系统是基于文件系统的,其性能和设备读写的机制有密切的关系。
open:打开文件[6]
int open(const char *pathname, int flags); 系统调用Open会为该进程一个文件描述符fd,常用的flags如下:
- O_WRONLY:表示我们以"写"的方式打开,告诉内核我们需要向文件中写入数据;
- O_DSYNC:每次write都等待物理I/O完成,但是如果写操作不影响读取刚写入的数据,则不等待文件属性更新;
- O_SYNC:每次write都等到物理I/O完成,包括write引起的文件属性的更新;
- O_DIRECT:执行磁盘IO时绕过缓冲区高速缓存(内核缓冲区),从用户空间直接将数据传递到文件或磁盘设备,称为直接IO(direct IO)。因为没有了OS cache,所以会O_DIRECT降低文件的顺序读写的效率。
write:写文件[7]
ssize_t write(int fd, const void *buf, size_t count); 使用open打开文件获取到文件描述符之后,可以调用write函数来写文件,具体表现根据open函数参数的不同而不同弄。
fsync & fdatasync:刷新文件[8]
#include int fsync(int fd); int fdatasync(int fd); - fdatasync:操作完write之后,我们可以调用fdatasync将文件数据块flush到磁盘,只要fdatasync返回成功,则可以认为数据已经写到磁盘了;
- fsync:与O_SYNC参数类似,fsync还会更新文件metadata到磁盘;
- sync:sync只是将修改过的块缓冲区写入队列,然后就返回,不等实际写磁盘操作完成;
为了保证文件更新成功持久化到硬盘,除了调用write方法,还需要调用fsync。
大致交互流程如下图:
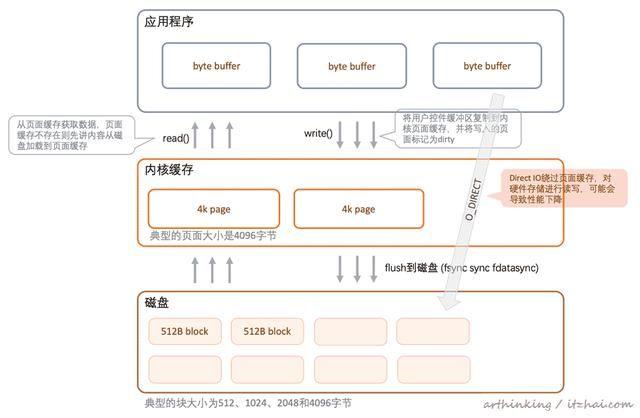
更多关于磁盘IO的相关内容,可以阅读:On Disk IO, Part 1: Flavors of IO[9]
fsync性能问题:除了刷脏页到磁盘,fsync还会同步文件metadata,而文件数据和metadata通常存放在磁盘不同地方,所以fsync至少需要两次IO操作。
对fsync性能的优化建议:由于以上性能问题,如果能够减少metadata的更新,那么就可以使用fdatasync了。因此需要确保文件的尺寸在write前后没有发生变化。为此,可以创建固定大小的文件进行写,写完则开启新的文件继续写。
3.1.2.2、innodb_flush_method
innodb_flush_method定义用于将数据刷新到InnoDB数据文件和日志文件的方法,这可能会影响I/O吞吐量。
以下是具体参数说明:
属性值命令行格式--innodb-flush-method=value系统变量innodb_flush_method范围全局默认值(Windows)unbuffered默认值(Unix)fsync有效值(Windows)unbuffered, normal有效值(Unix)fsync, O_DSYNC, littlesync, nosync, O_DIRECT, O_DIRECT_NO_FSYNC
比较常用的是这三种:
fsync
默认值,使用fsync()系统调用来flush数据文件和日志文件到磁盘;
O_DSYNC
由于open函数的O_DSYNC参数在许多Unix系统上都存中问题,因此InnoDB不直接使用O_DSYNC。
InnoDB用于O_SYNC 打开和刷新日志文件,fsync()刷新数据文件。
表现为:写日志操作是在write函数完成,数据文件写入是通过fsync()系统调用来完成;
O_DIRECT
使用O_DIRECT (在Solaris上对应为directio())打开数据文件,并用于fsync()刷新数据文件和日志文件。此选项在某些GNU/Linux版本,FreeBSD和Solaris上可用。
表现为:数据文件写入直接从buffer pool到磁盘,不经过操作系统缓冲,日志还是需要经过操作系统缓存;
O_DIRECT_NO_FSYNC
在刷新I/O期间InnoDB使用O_DIRECT,并且每次write操作后跳过fsync()系统调用。
此设置适用于某些类型的文件系统,但不适用于其他类型的文件系统。例如,它不适用于XFS。如果不确定所使用的文件系统是否需要fsync()(例如保留所有文件元数据),请改用O_DIRECT。
如下图所示:

为什么使用了O_DIRECT配置后还需要调用fsync()?
参考MySQL的这个bug:Innodb calls fsync for writes with innodb_flush_method=O_DIRECT[10]
Domas进行的一些测试表明,如果没有fsync,某些文件系统(XFS)不会同步元数据。如果元数据会更改,那么您仍然需要使用fsync(或O_SYNC来打开文件)。
例如,如果在启用O_DIRECT的情况下增大文件大小,它仍将写入文件的新部分,但是由于元数据不能反映文件的新大小,因此如果此刻系统发生崩溃,文件尾部可能会丢失。
为此:当重要的元数据发生更改时,请继续使用fsync或除O_DIRECT之外,也可以选择使用O_SYNC。
MySQL从v5.6.7起提供了O_DIRECT_NO_FSYNC选项来解决此类问题。
3.2、Change Buffer
change buffer是一种特殊的数据结构,当二级索引页(非唯一索引)不在缓冲池中时,它们会缓存这些更改 。当页面通过其他读取操作加载到缓冲池中时,再将由INSERT,UPDATE或DELETE操作(DML)产生的change buffer合并到buffer pool的数据页中。
为什么唯一索引不可以使用chage buffer?
针对唯一索引,如果buffer pool不存在对应的数据页,还是需要先去磁盘加载数据页,才能判断记录是否重复,这一步避免不了。
而普通索引是非唯一的,插入的时候以相对随机的顺序发生,删除和更新也会影响索引树中不相邻的二级索引树,通过使用合并缓冲,避免了在磁盘产生大量的随机IO访问获取普通索引页。
问题
当有许多受影响的行和许多辅助索引要更新时,change buffer合并可能需要几个小时,在此期间,I/O会增加,可能会导致查询效率大大降低,即使在事务提交之后,或者服务器重启之后,change buffer合并操作也会继续发生。相关阅读:Section 14.22.2, “Forcing InnoDB Recovery”
3.3、自适应哈希索引
自适应哈希索引功能由innodb_adaptive_hash_index变量启用 ,或在服务器启动时由--skip-innodb-adaptive-hash-index禁用。
3.4、Log Buffer
log buffer(日志缓冲区)用于保存要写入磁盘上的log file(日志文件)的数据。日志缓存区的内容会定期刷新到磁盘。
日志缓冲区大小由innodb_log_buffer_size变量定义 。默认大小为16MB。较大的日志缓冲区可以让大型事务在提交之前无需将redo log写入磁盘。
如果您有更新,插入或者删除多行的事务,尝试增大日志缓冲区的大小可以节省磁盘I/O。
3.4.1、配置参数
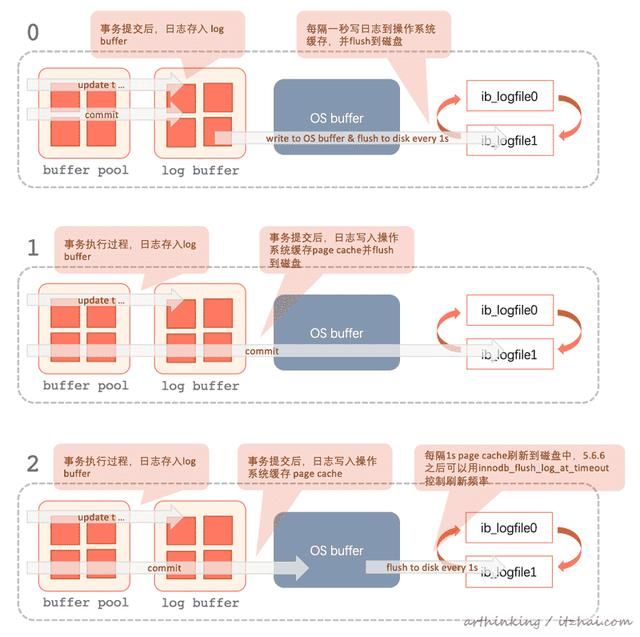
innodb_flush_log_at_trx_commit
innodb_flush_log_at_trx_commit 变量控制如何将日志缓冲区的内容写入并刷新到磁盘。
该参数控制是否严格存储ACID还是尝试获取更高的性能,可以通过该参数获取更好的性能,但是会导致在系统崩溃的过程中导致数据丢失。
可选参数:
- 0,事务提交之后,日志只记录到log buffer中,每秒写一次日志到缓存并刷新到磁盘,尚未刷新的日志可能会丢失;
- 1,要完全符合ACID,必须使用该值,表示日志在每次事务提交时写入缓存并刷新到磁盘;
- 2,每次事务提交之后,日志写到page cache,每秒刷一次到磁盘,尚未刷新的日志可能会丢失;
innodb_flush_log_at_timeout
innodb_flush_log_at_timeout 变量控制日志刷新频率。可让您将日志刷新频率设置为N秒(其中N为1 ... 2700,默认值为1)
为了保证数据不丢失,请执行以下操作:
如果启用了binlog,则设置:sync_binlog=1;innodb_flush_log_at_trx_commit=1;
配置效果如下图所示:
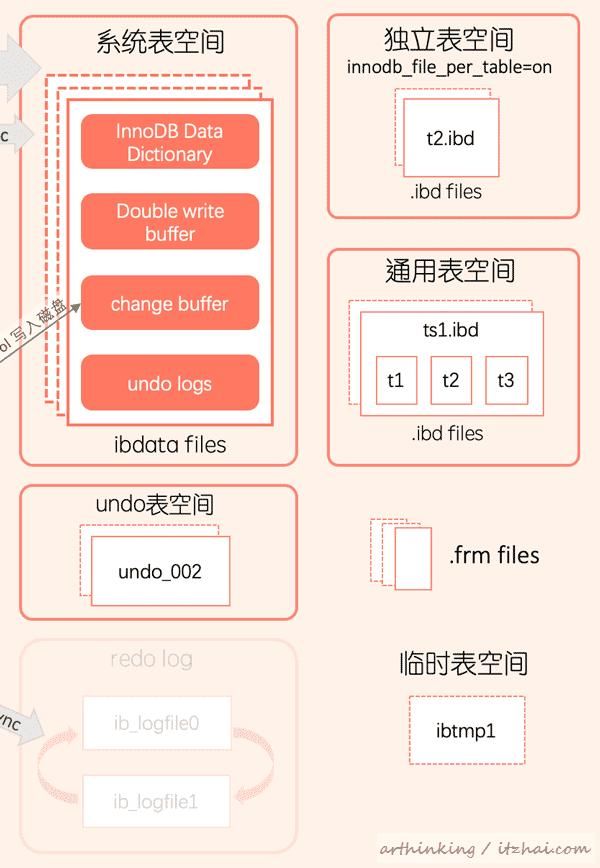
3.5、表空间
一个InnoDB表及其索引可以在建在系统表空间中,或者是在一个 独立表空间 中,或在 通用表空间。
- 当innodb_file_per_table启用时,通常是将表存放在独立表空间中,这是默认配置;
- 当innodb_file_per_table禁用时,则会在系统表空间中创建表;
- 要在通用表空间中创建表,请使用 CREATE TABLE ... TABLESPACE语法。有关更多信息,请参见官方文档 14.6.3.3 General Tablespaces。
表空间概览图:
表空间涉及的文件
相关文件默认在磁盘中的innodb_data_home_dir目录下:
|- ibdata1 // 系统表空间文件 |- ibtmp1 // 默认临时表空间文件,可通过innodb_temp_data_file_path属性指定文件位置 |- test/ // 数据库文件夹 |- db.opt // test数据库配置文件,包含数据库字符集属性 |- t.frm // 数据表元数据文件,不管是使用独立表空间还是系统表空间,每个表都对应有一个 |- t.ibd // 数据库表独立表空间文件,如果使用的是独立表空间,则一个表对应一个ibd文件,否则保存在系统表空间文件中 frm文件
创建一个InnoDB表时,MySQL 在数据库目录中创建一个.frm文件。frm文件包含MySQL表的元数据(如表定义)。每个InnoDB表都有一个.frm文件。
与其他MySQL存储引擎不同, InnoDB它还在系统表空间内的自身内部数据字典中编码有关表的信息。MySQL删除表或数据库时,将删除一个或多个.frm文件以及InnoDB数据字典中的相应条目。
因此,在InnoDB中,您不能仅通过移动.frm 文件来移动表。有关移动InnoDB 表的信息,请参见官方文档14.6.1.4 Moving or Copying InnoDB Tables。
ibd文件
对于在独立表空间创建的表,还会在数据库目录中生成一个 .ibd表空间文件。
在通用表空间中创建的表在现有的常规表空间 .ibd文件中创建。常规表空间文件可以在MySQL数据目录内部或外部创建。有关更多信息,请参见官方文档14.6.3.3 General Tablespaces。
ibdata文件
系统表空间文件,在 InnoDB系统表空间中创建的表在ibdata中创建。
3.5.1、系统表空间
系统表空间由一个或多个数据文件(ibdata文件)组成。其中包含与InnoDB相关对象有关的元数据(InnoDB 数据字典 data dictionary),以及更改缓冲区(change buffer), 双写缓冲区(doublewrite buffer)和撤消日志(undo logs)的存储区 。
InnoDB 如果表是在系统表空间中创建的,则系统表空间中也包含表的表数据和索引数据。
系统表空间的问题
在MySQL 5.6.7之前,默认设置是将所有InnoDB表和索引保留 在系统表空间内,这通常会导致该文件变得非常大。因为系统表空间永远不会缩小,所以如果先加载然后删除大量临时数据,则可能会出现存储问题。
在MySQL 5.7中,默认设置为 独立表空间模式,其中每个表及其相关索引存储在单独的 .ibd文件中。此默认设置使使用Barracuda文件格式的InnoDB功能更容易使用,例如表压缩,页外列的有效存储以及大索引键前缀(innodb_large_prefix)。
将所有表数据保留在系统表空间或单独的 .ibd文件中通常会对存储管理产生影响。
InnoDB在MySQL 5.7.6中引入了通用表空间[11],这些表空间也由.ibd文件表示 。通用表空间是使用CREATE TABLESPACE语法创建的共享表空间。它们可以在MySQL数据目录之外创建,能够容纳多个表,并支持所有行格式的表。
3.5.2、独立表空间
MySQL 5.7中,配置参数:innodb_file_per_table,默认处于启用状态,这是一个重要的配置选项,会影响InnoDB文件存储,功能的可用性和I/O特性等。
启用之后,每个表的数据和索引是存放在单独的.ibd文件中的,而不是在系统表空间的共享ibdata文件中。
优点
- 您可以更加灵活的选择数据压缩[12]的行格式,如:默认情况下(innodb_page_size=16K),前缀索引[13]最多包含768个字节。如果开启innodb_large_prefix,且Innodb表的存储行格式为 DYNAMIC 或 COMPRESSED,则前缀索引最多可包含3072个字节,前缀索引也同样适用;
- TRUNCATE TABLE执行的更快,并且回收的空间不会继续保留,而是让操作系统使用;
- 可以在单独的存储设备上创建每表文件表空间数据文件,以进行I / O优化,空间管理或备份。请参见 14.6.1.2 Creating Tables Externally;
缺点
- 独立表空间中的未使用空间只能由同一个表使用,如果管理不当,会造成空间浪费;
- 多个表需要刷盘,只能执行多次fsync,无法合并多个表的写操作,这可能会导致更多的fsync操作总数;
- mysqld必须为每个表文件空间保留一个打开的文件句柄,如果表数量多,可能会影响性能;
- 每个表都需要自己的数据文件,需要更多的文件描述符;
即使启用了innodb_file_per_table参数,每张表空间存放的只是数据、索引和插入缓存Bitmap页,其他数据如回滚信息、插入缓冲索引页、系统事务信息、二次写缓冲等还是存放在原来的共享表空间中。
3.5.3、通用表空间
通用表空间使用CREATE TABLESPACE语法创建。
类似于系统表空间,通用表空间是共享表空间,可以存储多个表的数据。
通用表空间比独立表空间具有潜在的内存优势,服务器在表空间的生存期内将表空间元数据保留在内存中。一个通用表空间通常可以存放多个表数据,消耗更少的表空间元数据内存。
数据文件可以放置在MySQL数据目录或独立于MySQL数据目录。
3.5.4、undo表空间
undo表空间包含undo log。
innodb_rollback_segments变量定义分配给每个撤消表空间的回滚段的数量。
undo log可以存储在一个或多个undo表空间中,而不是系统表空间中。
在默认配置中,撤消日志位于系统表空间中。SSD存储更适合undo log的I/O模式,为此,可以把undo log存放在有别于系统表空间的ssd硬盘中。
innodb_undo_tablespaces 配置选项控制undo表空间的数量。
3.5.5、临时表空间
由用户创建的非压缩临时表和磁盘内部临时表是在共享临时表空间中创建的。
innodb_temp_data_file_path 配置选项指定零时表空间文件的路径,如果未指定,则默认在 innodb_data_home_dir目录中创建一个略大于12MB 的自动扩展数据文件ibtmp1 。
使用ROW_FORMAT=COMPRESSED属性创建的压缩临时表,是在独立表空间中的临时文件目录中创建的 。
服务启动的时候创建临时表空间,关闭的时候销毁临时表空间。如果临时表空间创建失败,则意味着服务启动失败。
3.6、InnoDB底层逻辑存储结构
在介绍索引之前,我们有必要了解一下InnoDB底层的逻辑存储结构,因为索引是基于这个底层逻辑存储结构创建的。截止到目前,我们所展示的都仅仅是物理磁盘中的逻辑视图,接下来我们就来看看底层的视图。
3.6.1、ibd文件组织结构
现在我们打开一个表空间ibd文件,看看里面都是如何组织数据的?
如下图,表空间由段(segment)、区(extent)、页(page)组成。
InnoDB最小的存储单位是页,默认每个页大小是16k。
而InnoDB存储引擎是面向行的(row-oriented),数据按行进行存放,每个页规定最多允许存放的行数=16k/2 - 200,即7992行。
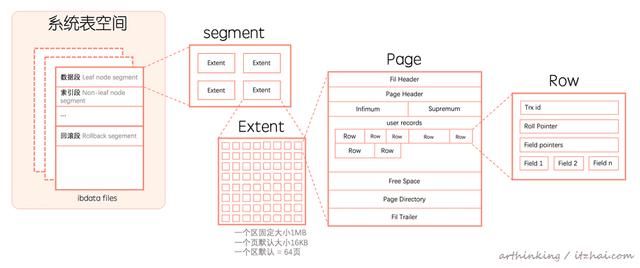
段:如数据段、索引段、回滚段等。InnoDB存储引擎是B+树索引组织的,所以数据即索引,索引即数据。B+树的叶子节点存储的都是数据段的数据。
3.6.2、数据页结构[14]
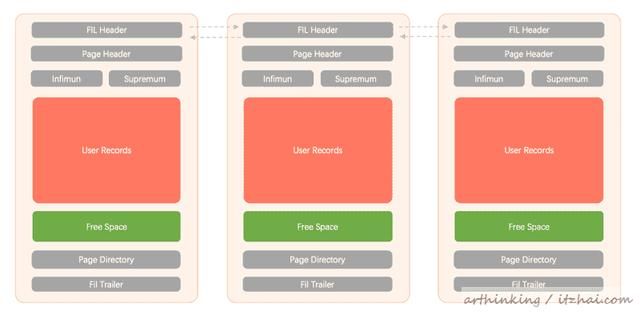
名称占用空间描述Fil Header38 byte页的基本信息,如所属表空间,上一页和下一页指针。Page Header56 byte数据页专有的相关信息Infimun + Supremum26 byte两个虚拟的行记录,用于限定记录的边界User Records动态分配实际存储的行记录内容Free Space动态调整尚未使用的页空间Page Directory动态调整页中某些记录的相对位置Fil Trailer8 byte校验页是否完整
关于Infimun和Supremum:首次创建索引时,InnoDB会在根页面中自动设置一个最小记录和一个最高记录,并且永远不会删除它们。最低记录和最高记录可以视为索引页开销的一部分。最初,它们都存在于根页面上,但是随着索引的增长,最低记录将存在于第一或最低叶子页上,最高记录将出现在最后或最大关键字页上。
3.6.3、行记录结构描述[15]
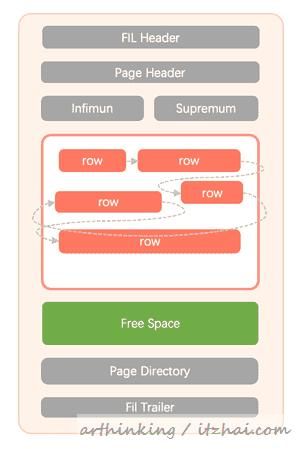
先来讲讲Compact行记录格式,Compact是MySQL5.0引入的,设计目标是高效的存储数据,让一个页能够存放更多的数据,从而实现更快的B+树查找。
名称描述变长字段长度列表字段大小最多用2个字节表示,也就是最多限制长度:2^16=65535个字节;字段大小小于255字节,则用1个字节表示;NULL标志位记录该行哪些位置的字段是null值记录头信息记录头信息信息,固定占用5个字节列1数据实际的列数据,NULL不占用该部分的空间列2数据...
记录头用于将连续的记录链接在一起,并用于行级锁定。
每行数据除了用户定义的列外,还有两个隐藏列:
- 6个字节的事务ID列;
- 7个字节的回滚指针列;
- 如果InnoDB没有指定主键,还会增加一个6个字节的rowid列;
而记录头信息表[16]含如下内容:
名称大小(bit)描述()1未知()1未知deleted_flag1该行是否已被删除min_rec_flag1如果该记录是预定义的最小记录,则为1n_owned4该记录拥有的记录数heap_no13索引堆中该条记录的排序号record_type3记录类型:000 普通,001 B+树节点指针,010 Infimum,011 Supremum,1xx 保留next_record16指向页中下一条记录

更详细的页结构参考官网:22.2 InnoDB Page Structure
更详细的行结构参考官网:22.1 InnoDB Record Structure
更详细的行格式参考官网:14.11 InnoDB Row Formats
根据以上格式,可以得出数据页内的记录组织方式:
3.6.3.1、MySQL中varchar最大长度是多少
上面表格描述我们知道,一个字段最长限制是65535个字节,这是存储长度的限制。
而MySQL中对存储是有限制的,具体参考:8.4.7 Limits on Table Column Count and Row Size
- MySQL对每个表有4096列的硬限制,但是对于给定的表,有效最大值可能会更少;
- MySQL表的每行行最大限制为65,535字节,这是逻辑的限制;实际存储的时候,表的物理最大行大小略小于页面的一半。如果一行的长度少于一页的一半,则所有行都将存储在本地页面内。如果它超过一页的一半,那么将选择可变长度列用于外部页外存储,直到该行大小控制在半页之内为止。
而实际能够存储的字符是跟编码有关的。
背景知识:
MySQL 4.0版本以下,varchar(10),代表10个字节,如果存放UTF8汉字,那么只能存3个(每个汉字3字节);
MySQL 5.0版本以上,varchar(10),指的是10个字符,无论存放的是数字、字母还是UTF8汉字(每个汉字3字节),都可以存放10个,最大大小是65532字节;
因此,Mysql5根据编码不同,存储大小也不同。
那么假设我们使用的是utf8编码,那么每个字符最多占用3个字节,也就是最多定义varchar(21845)个字符,如果是ascii编码,一个字符相当于一个字节,最多定义varchar(65535)个字符,下面我们验证下。
我们尝试创建一个这样的字段:
CREATE TABLE `t10` ( `id` int(11) NOT NULL, `a` int(11) NOT NULL, PRIMARY KEY (`id`) ) ENGINE=InnoDB CHARSET=ascii ROW_FORMAT=Compact; alter table t10 add `str` varchar(21845) DEFAULT NULL; alter table t10 add `str` varchar(65535) DEFAULT NULL; 发现提示这个错误:
mysql> alter table t10 add `str` varchar(65535) DEFAULT NULL; ERROR 1118 (42000): Row size too large. The maximum row size for the used table type, not counting BLOBs, is 65535. This includes storage overhead, check the manual. You have to change some columns to TEXT or BLOBs 原因是按照以上的行格式介绍,变长字段长度列表记录也需要占用空间,占用2个字节,另外这里是允许为空字段,在8位之内,所以NULL标志位占用1个字节,所以我们总共可以存储的字符数是:
65535 - 2 - 2 - 4 - 4=65534
其中 -2 个字节表示变长字段列表,-1表示NULL标志位,两个-4表示两个int类型字段占用大小
所以实际上能够容纳的varchar大小为:65524,我们验证下:

3.6.3.2、行记录超过页大小如何存储
MySQL表的内部表示具有65,535字节的最大行大小限制。InnoDB 对于4KB,8KB,16KB和32KB innodb_page_size 设置,表的最大行大小(适用于本地存储在数据库页面内的数据)略小于页面的一半 。如果包含 可变长度列的InnoDB 行超过最大行大小,那么将选择可变长度列用于外部页外存储。
可变长度列由于太长而无法容纳在B树页面上,这个时候会把可变长度列存储在单独分配的磁盘页面上,这些页面称为溢出页面,这些列称为页外列。页外列的值存储在由溢出页面构成的单链接列表中。
InnoDB存储引擎支持四种行格式:REDUNDANT,COMPACT, DYNAMIC,和COMPRESSED。不同的行格式,对溢出的阈值和处理方式有所区别,详细参考:14.11 InnoDB Row Formats。
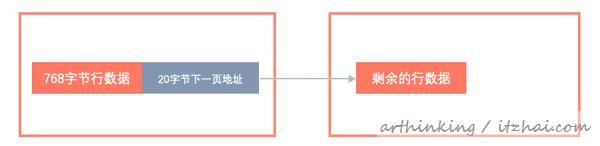
COMPACT行格式处理方式
使用COMPACT行格式的表将前768个字节的变长列值(VARCHAR, VARBINARY和 BLOB和 TEXT类型)存储在B树节点内的索引记录中,其余的存储在溢出页上。
如果列的值等于或小于768个字节,则不使用溢出页,因此可以节省一些I / O。
如果查过了768个字节,那么会按照如下方式进行存储:
DYNAMIC行格式处理方式
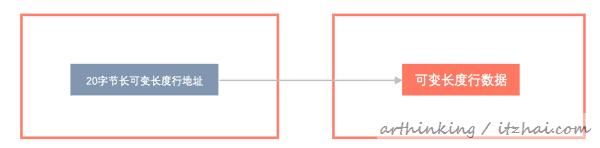
DYNAMIC行格式提供与COMPACT行格式相同的存储特性,但改进了超长可变长度列的存储能力和支持大索引键前缀。
InnoDB 可以完全在页外存储过长的可变长度列值(针对 VARCHAR, VARBINARY和 BLOB和 TEXT类型),而聚集索引记录仅包含指向溢出页的20字节指针。大于或等于768字节的固定长度字段被编码为可变长度字段。
表中大字段引发的问题
如果一个表中有过多的可变长度大字段,导致一行记录太长,而整个时候使用的是COMPACT行格式,那么就可能会插入数据报错。
如,页面大小事16k,根据前面描述我们知道,MySQL限制一页最少要存储两行数据,如果很多可变长度大字段,在使用COMPACT的情况下,仍然会把大字段的前面768个字节存在索引页中,可以算出最多支持的大字段:1024 * 16 / 2 / 768 = 10.67,那么超过10个可变长度大字段就会插入失败了。
这个时候可以把row format改为:DYNAMIC。
3.7、索引
前面我们了解了InnoDB底层的存储结构,即:以B+树的方式组织数据页。另外了解了数据页中的数据行的存储方式。
而构建B+树索引的时候必须要选定一个或者多个字段作为索引的值,如果索引选择的是主键,那么我们就称为聚集索引,否则就是二级索引。
为什么MySQL使用B+树?
哈希表虽然可以提供O(1)的单行数据操作性能,但却不能很好的支持排序和范围查找,会导致全表扫描;B树可以再非叶子节点存储数据,但是这可能会导致查询连续数据的时候增加更多的I/O操作;而B+树数据都存放在叶子节点,叶子节点通过指针相互连接,可以减少顺序遍历时产生的额外随机I/O
更新详细解释: 为什么 MySQL 使用 B+ 树[17]
3.7.1、聚集索引
了解到上面的底层逻辑存储结构之后,我们进一步来看看InnoDB是怎么通过B+树来组织存储数据的。
首先来介绍下聚集索引。
聚集索引
主键索引的InnoDB术语。
下面我们创建一张测试表,并插入数据,来构造一颗B+树:
CREATE TABLE t20 ( id int NOT NULL, a int NOT NULL, b int, c int, PRIMARY KEY (`id`) ) ENGINE=InnoDB; insert into t20 values(20, 1, 2, 1); insert into t20 values(40, 1, 2, 5); insert into t20 values(30, 3, 2, 4); insert into t20 values(50, 3, 6, 2); insert into t20 values(10, 1, 1, 1); 可以看到,虽然我们是id乱序插入的,但是插入之后查出来的确是排序好的:

这个排序就是B+索引树构建的。
我们可以通过这个在线的动态演示工具来看看B+树的构造过程,最终结果如下:
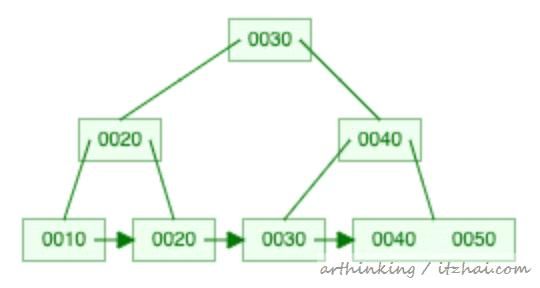
实际存放在数据库中的模型因页面大小不一样而有所不同,这里为了简化模型,我们按照B+树的通用模型来解释数据的存储结构。
类似的,我们的数据也是这种组织形式的,该B+树中,我们以主键为索引进行构建,并且把完整的记录存到对应的页下面:
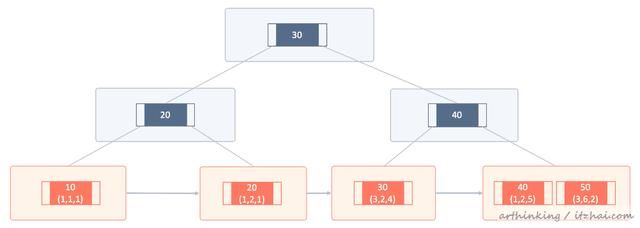
其中蓝色的是索引页,橙色的是数据页。
每个页的大小默认为16k,如果插入新的数据行,这个时候就要申请新的数据页了,然后挪动部分数据过去,重新调整B+树,这个过程称为页分裂,这个过程会影响性能。
相反的,如果InnoDB索引页的填充因子下降到之下MERGE_THRESHOLD,默认情况下为50%(如果未指定),则InnoDB尝试收缩索引树以释放页面。
自增主键的插入是递增顺序插入的,每次添加记录都是追加的,不涉及到记录的挪动,不会触发叶子节点的分裂,而一般业务字段做主键,往往都不是有序插入的,写成本比较高,所以我们更倾向于使用自增字段作为主键。
聚集索引注意事项
- 当在表上面定义了PRIMARY KEY之后,InnoDB会把它作为聚集索引。为此,为你的每个表定义一个PRIMARY KEY。如果没有唯一并且非空的字段或者一组列,那么请添加一个自增列;
- 如果您没有为表定义PRIMARY KEY,则MySQL会找到第一个不带null值的UNIQUE索引,并其用作聚集索引;
- 如果表没有PRIMARY KEY或没有合适的UNIQUE索引,则InnoDB 内部会生成一个隐藏的聚集索引GEN_CLUST_INDEX,作为行ID,行ID是一个6字节的字段,随着数据的插入而自增。
聚集索引查找
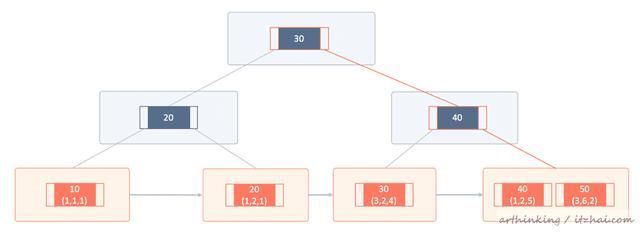
根据索引进行查找id=50的记录,如下图,沿着B+树一直往下寻找,最终找到第四页,然后把该页加载到buffer pool中,在缓存中遍历对比查找,由于里面的行记录是顺序组织的,所以很快就可以定位到记录了。
3.7.2、辅助索引
除了聚集索引之外的所有索引都称为辅助索引(二级索引)。在InnoDB中,辅助索引中每个记录都包含该行的主键列以及为辅助索引指定的列。
在辅助索引中查找到记录,可以得到记录的主键索引ID,然后可以通过这个主键索引ID去聚集索引中搜索具体的记录,这个过程称为回表操作。
如果主键较长,则辅助索引将使用更多空间,因此具有短的主键是有利的。
下面我们给刚刚的表添加一个组合联合索引
-- 添加多一个字段 alter table t20 add column d varchar(20) not null default ''; -- 添加一个联合索引 alter table t20 add index idx_abc(a, b, c); 添加之后组合索引B+树如下,其中索引key为abc三个字段的组合,索引存储的记录为主键ID:
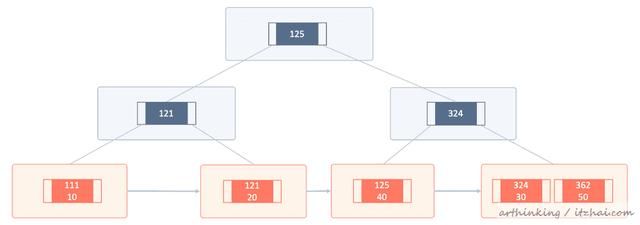
覆盖索引(Using index)
InnoDB存储引擎支持覆盖索引,即从辅助索引中就可以得到查询的记录,而不需要回表去查询聚集索引中的记录,从而减少大量的IO操作。下面的查询既是用到了覆盖索引 idx_abc:
select a, b from t20 where a > 2; 执行结果如下:
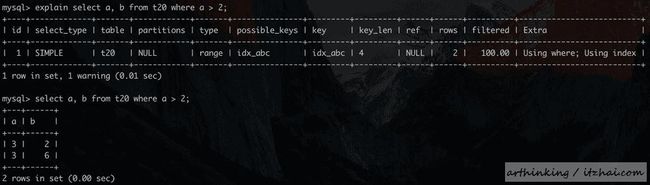
可以发现,Extra这一列提示Using index,使用到了覆盖索引,扫描的行数为2。注意:这里的扫描行数指的是MySQL执行器从引擎取到两条记录,引擎内部可能会遍历到多条记录进行条件比较。
最左匹配原则
由于InnoDB索引式B+树构建的,因此可以利用索引的“最左前缀”来定位记录。
也就是说,不仅仅是用到索引的全部定义字段会走索引,只要满足最左前缀,就可以利用索引来加速检索。这个最左前缀可以是联合索引的最左n个字段。
索引条件下推(Using index condition)
索引条件下推 Index Condition Pushdown (ICP),是针对MySQL使用索引从表中检索行的情况的一种优化。
为什么叫下推呢,就是在满足要求的情况下,把索引的条件丢给存储引擎去判断,而不是把完整的记录传回MySQL Server层去判断。
ICP支持range, ref, eq_ref, 和 ref_or_null类型的查找,支持MyISAM和InnoDB存储引擎。
不能将引用子查询的条件下推,触发条件不能下推。详细规则参考:Index Condition Pushdown
如果不使用ICP,则存储引擎将遍历索引以在聚集索引中定位行,并将结果返回给MySQL Server层,MySQL Server层继续根据WHERE条件进行筛选行。
启用ICP后,如果WHERE可以仅使用索引中的列来评估部分条件,则MySQL Server层会将这部分条件压入WHERE条件下降到存储引擎。然后,存储引擎通过使用索引条目来判断索引条件,在满足条件的情况下,才回表去查找记录返回给MySQL Server层。
ICP的目标是减少回表扫描的行数,从而减少I / O操作。对于InnoDB表,ICP仅用于二级索引。
使用索引下推的时候,执行计划中的Extra会提示:Using index condition,而不是Using index,因为必须回表查询整行数据。Using index代表使用到了覆盖索引。
3.8、InnoDB Data Directory
InnoDB数据字典(Data Directory)存放于系统表空间中,主要包含元数据,用于追踪表、索引、表字段等信息。由于历史的原因,InnoDB数据字典中的元数据与.frm文件中的元数据重复了。
3.9、Doublewrite Buffer
双写缓冲区(Doublewrite Buffer)是一个存储区,是InnoDB在tablespace上的128个页(2个区),大小是2MB[18]。
版本区别:在MySQL 8.0.20之前,doublewrite缓冲区存储区位于InnoDB系统表空间中。从MySQL 8.0.20开始,doublewrite缓冲区存储区位于doublewrite文件中。
本文基于MySQL 5.7编写。
操作系统写文件是以4KB为单位的,那么每写一个InnoDB的page到磁盘上,操作系统需要写4个块。如果写入4个块的过程中出现系统崩溃,那么会导致16K的数据只有一部分写是成功的,这种情况下就是partial page write(部分页写入)问题。
InnoDB这个时候是没法通过redo log来恢复的,因为这个时候页面的Fil Trailer(Fil Trailer 主要存放FIL_PAGE_END_LSN,主要包含页面校验和以及最后的事务)中的数据是有问题的。
为此,每当InnoDB将页面写入到数据文件中的适当位置之前,都会首先将其写入双写缓冲区。只有将缓冲区安全地刷新到磁盘后,InnoDB才会将页面写入最终的数据文件。
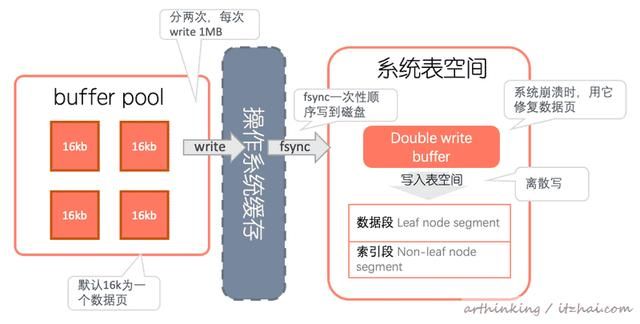
如果在页面写入过程中发生操作系统或者mysqld进程崩溃,则InnoDB可以在崩溃恢复期间从双写缓冲区中找到页面的完好副本用于恢复。恢复时,InnoDB扫描双写缓冲区,并为缓冲区中的每个有效页面检查数据文件中的页面是否完整。
如果系统表空间文件(“ ibdata文件 ”)位于支持原子写的Fusion-io设备上,则自动禁用双写缓冲,并且将Fusion-io原子写用于所有数据文件。
3.10、Redo Log
重做日志(Redo Log)主要适用于数据库的崩溃恢复,用于实现数据的完整性。
重做日志由两部分组成:
- 重做日志缓冲区 Log Buffer;
- 重做日志文件,重做日志文件在磁盘上由两个名为ib_logfile0和ib_logfile1的物理文件表示。
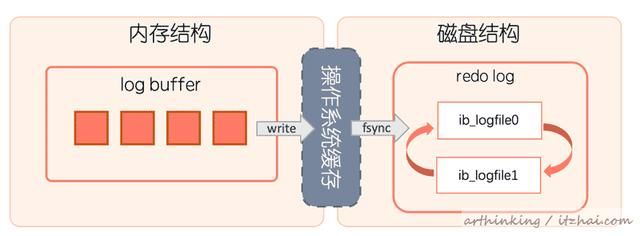
为了实现数据完整性,在脏页刷新到磁盘之前,必须先把重做日志写入到磁盘。除了数据页,聚集索引、辅助索引以及Undo Log都需要记录重做日志。
3.10.1、Redo Log在事务中的写入时机
在事务中,除了写Redo log,还需要写binlog,为此,我们先来简单介绍下binlog。
3.10.1.1、binlog
全写:Binary Log,二进制log。二进制日志是一组日志文件。其中包含有关对MySQL服务器实例进行的数据修改的信息。
Redo Log是InnoDB引擎特有的,而binlog是MySQL的Server层实现的,所有引擎都可以使用。
Redo Log的文件是循环写的,空间会用完,binlog日志是追加写的,不会覆盖以前的日志。
binlog主要的目的:
- 主从同步,主服务器将二进制日志中包含的事件发送到从服务器,从服务器执行这些事件,以保持和主服务器相同的数据更改;
- 某些数据恢复操作需要使用二进制日志,还原到某一个备份点。
binlog主要是用于主从同步和数据恢复,Redo Log主要是用于实现事务数据的完整性,让InnoDB具有不会丢失数据的能力,又称为crash-safe。
binlog日志的两种记录形式:
- 基于SQL的日志记录:事件包含产生数据更改(插入,新增,删除)的SQL语句;
- 基于行的日志记录:时间描述对单个行的更改。
混合日志记录默认情况下使用基于语句的日志记录,但根据需要自动切换到基于行的日志记录。
3.10.1.2、Redo Log在事务中的写入时机
简单的介绍完binlog,我们再来看看Redo Log的写入流程。
假设我们这里执行一条sql
update t20 set a=10 where id=1; 执行流程如下:
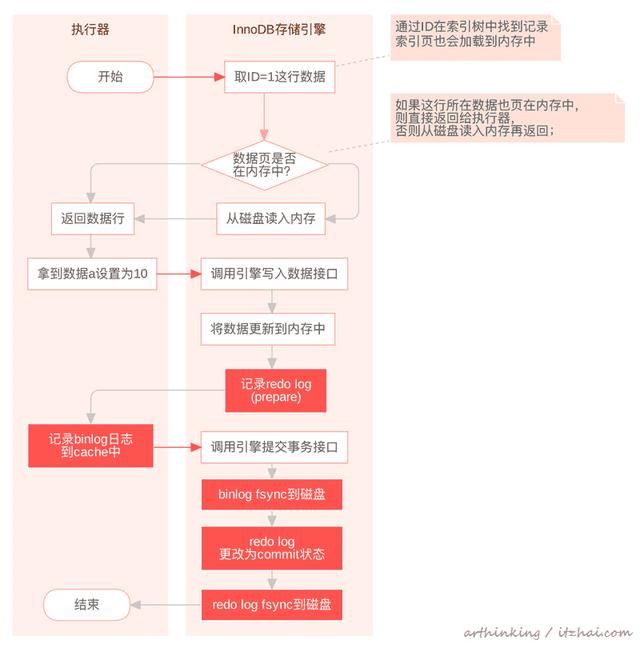
3.10.2、如何保证数据不丢失
前面我们介绍Log Buffer的时候,提到过,为了保证数据不丢失,我们需要执行以下操作:
- 如果启用了binlog,则设置:sync_binlog=1;
- innodb_flush_log_at_trx_commit=1;
sync_binlog=0:表示每次提交事务都只 write,不 fsync;sync_binlog=1:表示每次提交事务都会执行 fsync;sync_binlog=N(N>1) :表示每次提交事务都 write,但累积 N 个事务后才 fsync。
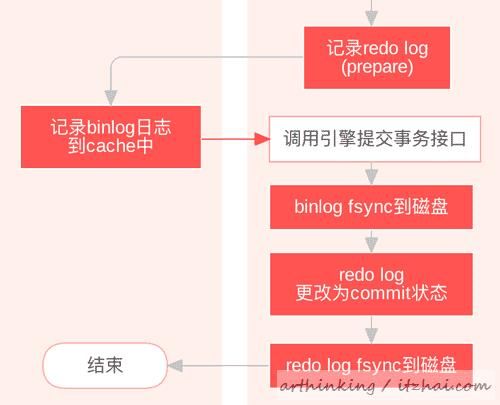
这两个的作用相当于在上面的流程最后一步,提交事务接口返回Server层之前,把binlog cache和log buffer都fsync到磁盘中了,这样就保证了数据的落盘,不会丢失,即使奔溃了,也可以通过binlog和redo log恢复数据相关流程如下:
在磁盘和内存中的处理流程如下面编号所示:
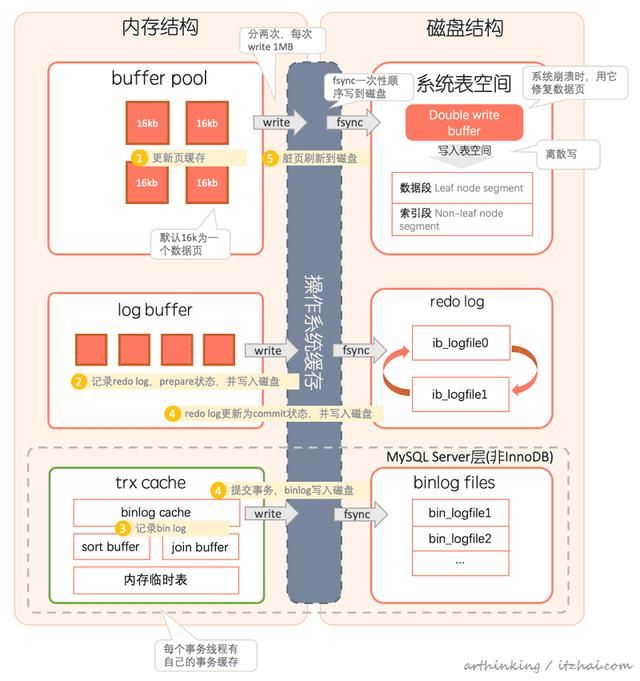
其中第四步log buffer持久化到磁盘的时机为:
- log buffer占用的空间即将达到innodb_log_buffer_size一半的时候,后台线程主动写盘;
- InnoDB后台有个线程,每隔1秒会把log buffer刷到磁盘;
- 由于log buffer是所有线程共享的,当其他事务线程提交时也会导致已写入log buffer但还未提交的事务的redo log一起刷新到磁盘
其中第五步:脏页刷新到磁盘的时机为:
- 系统内存不足,需要淘汰脏页的时候,要把脏页同步回磁盘;
- MySQL空闲的时候;
- MySQL正常关闭的时候,会把脏页flush到磁盘。
参数innodb_max_dirty_pages_pct是脏页比例上限,默认值是 75%。
为什么第二步 redo log prepare状态也要写磁盘?
因为这里先写了,才能确保在把binlog写到磁盘后崩溃,能够恢复数据:如果判断到redo log是prepare状态,那么查看是否存XID对应的binlog,如果存在,则表示事务成功提交,需要用prepare状态的redo log进行恢复。
这样即使崩溃了,也可以通过redo log来进行恢复了,恢复流程如下:
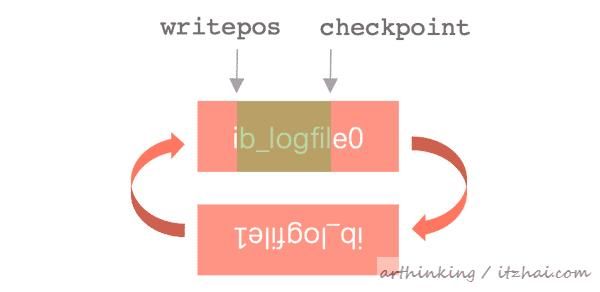
Redo Log是循环写的,如下图:
- writepos记录了当前写的位置,一边写位置一边往前推进,当writepos与checkpoint重叠的时候就表示logfile写满了,绿色部分表示是空闲的空间,红色部分是写了redo log的空间;
- checkpoint处标识了当前的LSN,每当系统崩溃重启,都会从当前checkpoint这个位置执行重做日志,根据重做日志逐个确认数据页是否没问题,有问题就通过redo log进行修复。
LSN Log Sequence Number的缩写。代表日志序列号。在InnoDB中,LSN占用8个字节,单调递增,LSN的含义:
重做日志写入的总量;checkpoint的位置;页的版本;
除了重做日志中有LSN,每个页的头部也是有存储了该页的LSN,我们前面介绍页面格式的时候有介绍过。
该页中LSN表示该页最后刷新时LSN的大小。[19]
3.11、Undo Logs
上面说的redo log记录了事务的行为,可以通过其对页进行重做操作,但是食物有时候需要进行回滚,这时候就需要undo log了。[20]
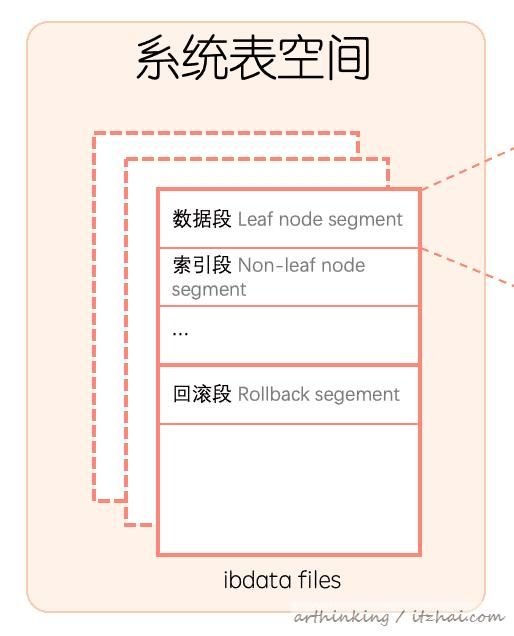
关于Undo Log的存储:InnoDB中有回滚段(rollback segment),每个回滚段记录1024个undo log segment,在每个undo log segment段中进行申请undo页。系统表空间偏移量为5的页记录了所有的rollback segment header所在的页。
3.11.1、undo log的格式
根据行为不同分为两种:
insert undo log
insert undo log:只对事务本身可见,所以insert undo log在事务提交后可直接删除,无需执行purge操作;
insert undo log主要记录了:
next记录下一个undo log的位置type_cmplundo的类型:insert or update*undo_no记录事务的ID*table_id记录表对象*len1, col1记录列和值*len2, col2记录列和值......start记录undo log的开始位置
假设在事务1001中,执行以下sql,t20的table_id为10:
insert into t20(id, a, b, c, d) values(12, 2, 3, 1, "init") 那么对应会生成一条undo log:

update undo log
update undo log:执行update或者delete会产生undo log,会影响已存在的记录,为了实现MVCC(后边介绍),update undo log不能再事务提交时立刻删除,需要将事务提交时放入到history list上,等待purge线程进行最后的删除操作。
update undo log主要记录了:
next记录下一个undo log的位置type_cmplundo的类型:insert or update*undo_noundo日志编号*table_id记录表对象info_bits*DATA_TRX_ID事务的ID*DATA_ROLL_PTR回滚指针*len1, i_col1n_unique_index*len2, i_col2...n_update_fields以下是update vector信息,表示update操作导致发送改变的列*pos1, *len1, u_old_col1*pos2, *len2, u_old_col2...n_bytes_below*pos, *len, col1*pos, *len, col2...start记录undo log的开始位置
假设在事务1002中,执行以下sql,t20的table_id为10:
update t20 set d="update1" where id=60; 那么对应会生成一条undo log:
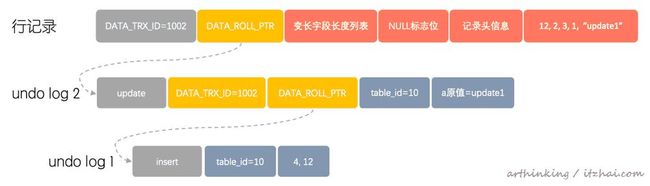
如上图,每回退应用一个undo log,就回退一个版本,这就是MVCC(Multi versioning concurrency control)的实现原理。
下面我们在执行一个delete sql:
delete from t20 where id=60; 对应的undo log变为如下:
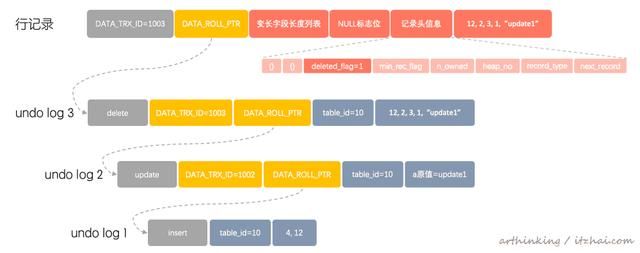
如上图,实际的行记录不会立刻删除,而是在行记录头信息记录了一个deleted_flag标志位。最终会在purge线程purge undo log的时候进行实际的删除操作,这个时候undo log也会清理掉。
3.11.2、MVCC实现原理
如上图所示,MySQL只会有一个行记录,但是会把每次执行的sql导致行记录的变动,通过undo log的形式记录起来,undo log通过回滚指针连接在一起,这样我们想回溯某一个版本的时候,就可以应用undo log,回到对应的版本视图了。
我们知道InnoDB是支持RC(Read Commit)和RR(Repeatable Read)事务隔离级别的,而这个是通过一致性视图(consistent read view)实现的。
一个事务开启瞬间,所有活跃的事务(未提交)构成了一个视图数组,InnoDB就是通过这个视图数组来判断行数据是否需要undo到指定的版本:

RR事务隔离级别
假设我们使用了RR事务隔离级别。我们看个例子:
如下图,假设id=60的记录a=1

事务C启动的瞬间,活跃的事务如下图黄色部分所示:

也就是对于事务A、事务B、事务C,他们能够看到的数据只有是行记录中的最大事务IDDATA_TRX_ID<=11的,如果大于,那么只能通过undo进行回滚了。如果TRX_ID=当前事务id,也可以看到,即看到自己的改动。
另外有一个需要注意的:
- 在RR隔离级别下,当事务更新事务的时候,只能用当前读来获取最新的版本数据来更新,如果当前记录的行锁被其他事务占用,就需要进入所等待;
- 在RC隔离级别下,每个语句执行都会计算出新的一致性视图。
所以我们分析上面的例子的执行流程:
- 事务C执行update,执行当前读,拿到的a=1,然后+1,最终a=2,同时添加一个TRX_ID=11的undo log;
- 事务B执行select,使用快照读,记录的DATA_TRX_ID > 11,所以需要通过undo log回滚到DATA_TRX_ID=11的版本,所以拿到的a是1;
- 事务B执行update,需要使用当前读,拿到最新的记录,a=2,然后加1,最终a=3;
- 事务B执行select,拿到当前最新的版本,为自己的事务id,所以得到a=3;
- 事务A执行select,使用快照读,记录的DATA_TRX_ID > 11,所以需要通过undo log回滚到DATA_TRX_ID=11的版本,所以拿到的a是1。
- 如果是RC隔离级别,执行select的时候会计算出新的视图,新的视图能够看到的最大事务ID=14,由于事务B还没提交,事务C提交了,所以可以得到a=2:
总结
- 数据完整性依靠:redo log
- 事务隔离级别的实现依靠MVCC,MVCC依靠undo log实现
- IO性能提升方式:buffer pool加快查询效率和普通索引更新的效率,log buffer对日志写的性能提升
- 查询性能提升依赖于索引,底层用页存储,字段越小页存储越多行记录,查询效率越快;自增字段作为聚集索引可以加快插入操作;
- 故障恢复:双写缓冲区、redo log
- 主从同步:binlog
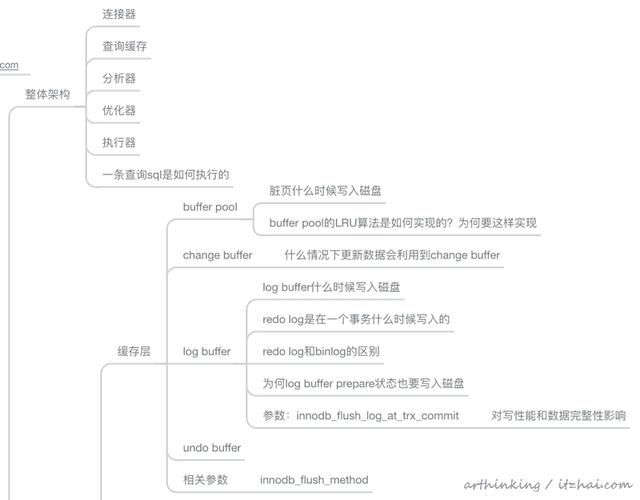
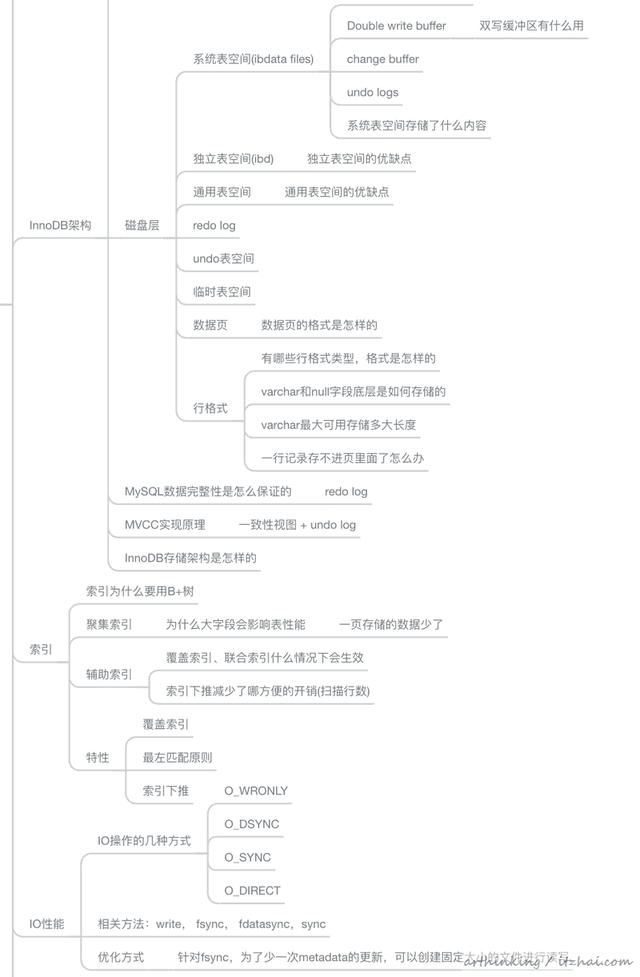
本文内容比较多,看完之后需要多梳理,最后大家可以对照着这个思维导图回忆一下,这些内容是否都记住了:
这篇文章的内容就差不多介绍到这里了,能够阅读到这里的朋友真的是很有耐心,为你点个赞。
本文为arthinking基于相关技术资料和官方文档撰写而成,确保内容的准确性,如果你发现了有何错漏之处,烦请高抬贵手帮忙指正,万分感激。
大家可以关注我,持续更新更多文章,我将持续更新后端相关技术,涉及JVM、Java基础、架构设计、网络编程、数据结构、数据库、算法、并发编程、分布式系统等相关内容。
如果您觉得读完本文有所收获的话,可以关注我的账号,或者点赞吧,码字不易,您的支持就是我写作的最大动力,再次感谢!
最后给大家准备了一些Mysql技术的pdf和Mysql面试题以及答案,需要的小伙伴私信[学习]即可!
![]()
