MachO文件格式
目录
0x1 前言
0x2 例子程序
0x3 MachO文件格式分析
0xx1 Mach Header-可执行文件头
0xx2 Load Commands-加载命令
segment_command结构体定义:
dyld_info_command结构体
LC_SYMTAB结构体
LC_LOAD_DYLINKER结构体
LC_UUID结构体
LC_LOAD_DYLIB结构体
LC_RPATH结构体
0xx3 DATA(Section64)
0xx4 Dynamic Loader Info
0xx5 Function Starts、Symbol Table、Dynamic Symbol Table、String Table、Code Signature
可执行文件运行过程
0x1 前言
刚刚接触IOS逆向,要从最基础的开始学起,看了一些视频之后,发现MachO文件挺重要的,HOOK的时候会用到,当然不止hook,理解他的文件格式显得很重要,今天就自己总结一下。
0x2 例子程序
例子程序就拿我写好的一个fishhook的好了,代码主要代码和工程目录如下:
//
// ViewController.m
// fishhook
//
// Created by yrl on 2019/7/26.
// Copyright © 2019 apple. All rights reserved.
//
#import "ViewController.h"
#import "fishhook.h"
@interface ViewController ()
@end
@implementation ViewController
- (void)viewDidLoad {
[super viewDidLoad];
NSLog(@"123");//NSLog属于懒加载,调用才能看到
//实现交换
//定义rebinding结构体
struct rebinding nslog;
nslog.name = "NSLog";
nslog.replacement = myNSLog;
nslog.replaced = (void **)&sys_nslog;
//定义结构体数组
struct rebinding rebs[1] = {nslog};
/* 用来重新绑定符号
* arg1 存放rebinding结构体的数组
* arg2 数组长度
*/
rebind_symbols(rebs, 1);//两个参数 结构体数组、数组长度
printf("修改完毕!!");
}
//-------------更改系统NSLOG函数-------------
//函数指针,用来保存原来的函数地址
static void(*sys_nslog)(NSString *format,...);
//定义一个新的函数
void myNSLog(NSString *format, ...){
format = [format stringByAppendingString:@"\n勾上了!!"];
sys_nslog(format);
}
-(void)touchesBegan:(NSSet *)touches withEvent:(UIEvent *)event{//屏幕触发事件
NSLog(@"点击屏幕!!");
}
@end
0x3 MachO文件格式分析
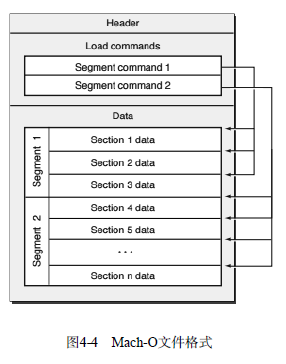
可以看出,Mach-O主要由以下3部分组成。
Mach-O头部(mach header)。描述了Mach-O的CPU架构、文件类型以及加载命令等信息。
加载命令(load command)。描述了文件中数据的具体组织结构,不同的数据类型使用不同的加载命令表示。
Data。Data中每个段(segment)的数据都保存在这里,段的概念与ELF文件中段的概念类似。每个段都有一个或多个Section,它们存放了具体的数据与代码。
这里结束可视化工具,烂苹果(MachOview)来查看其文件格式,也可以用苹果自带的otool工具查看,其内容是一样的,不过MachO会显示的人性化一点。如下图:

两种方法得到的结果是一样的,不过个人觉得MachO会更直观和全面。
MachO文件格式,有这几个部分(下面的每一个部分都是代表一个结构体):

| mach64 Header | 文件头 |
| Load Commands | 加载命令 |
| __TEXT | 文本(代码)段 |
| __DATA | 数据段 |
| Dynamic Loader Info | 动态加载信息 |
| Function Starts | 入口函数 |
| Symbol Table | 符号表 |
| Dynamic Symbol Table | 动态库符号表 |
| String Table | 字符串表 |
| Code Signature | 代码签名 |
0xx1 Mach Header-可执行文件头
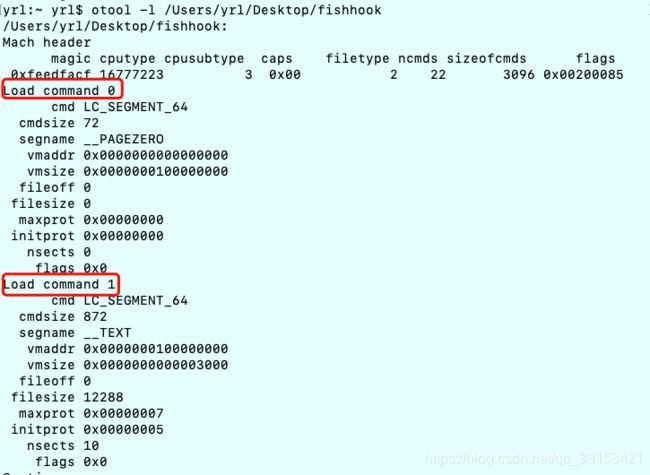
用mac下的工具otool查看macho文件头信息:otool -h fishhook
Mach header
magic cputype cpusubtype caps filetype ncmds sizeofcmds flags
0xfeedfacf 16777223 3 0x00 2 22 3096 0x00200085上面是macho标准的文件头格式,对应的数据结构如下:
/*
* The 32-bit mach header appears at the very beginning of the object file for
* 32-bit architectures.
*/
struct mach_header {
uint32_t magic; /* mach magic number identifier */
cpu_type_t cputype; /* cpu specifier */
cpu_subtype_t cpusubtype; /* machine specifier */
uint32_t filetype; /* type of file */
uint32_t ncmds; /* number of load commands */
uint32_t sizeofcmds; /* the size of all the load commands */
uint32_t flags; /* flags */
};
/* Constant for the magic field of the mach_header (32-bit architectures) */
#define MH_MAGIC 0xfeedface /* the mach magic number */
#define MH_CIGAM 0xcefaedfe /* NXSwapInt(MH_MAGIC) */
/*
* The 64-bit mach header appears at the very beginning of object files for
* 64-bit architectures.
*/
struct mach_header_64 {
uint32_t magic; /* mach magic number identifier */
cpu_type_t cputype; /* cpu specifier */
cpu_subtype_t cpusubtype; /* machine specifier */
uint32_t filetype; /* type of file */
uint32_t ncmds; /* number of load commands */
uint32_t sizeofcmds; /* the size of all the load commands */
uint32_t flags; /* flags */
uint32_t reserved; /* reserved */
};
/* Constant for the magic field of the mach_header_64 (64-bit architectures) */
#define MH_MAGIC_64 0xfeedfacf /* the 64-bit mach magic number */
#define MH_CIGAM_64 0xcffaedfe /* NXSwapInt(MH_MAGIC_64) */字段解释和举例解释如下:
| 字段 | 说明 | 例子(举例) |
| magic | 魔数头,系统加载器通过该字段快速判断文件适用于32位还是64位。0xfeedface是32位,0xfeedfacf是64位。 | 例子中是0xfeedfacf为64位文件 |
| cputype | CPU类型,该字段确保系统可以将合适的二进制文件在当前架构下运行 | 例子中的值为 16777223(0x100007)为CPU_TYPE_X86_64 |
| cpusubtype | CPU指定子类型,inter、arm、powerpc等,详细描述其支持的CPU子类型 #define CPU_SUBTYPE_MASK 0xff000000 #define CPU_SUBTYPE_LIB64 0x80000000 #define CPU_SUBTYPE_X86_ALL ((cpu_subtype_t)3) #define CPU_SUBTYPE_X86_64_ALL ((cpu_subtype_t)3) #define CPU_SUBTYPE_X86_ARCH1 ((cpu_subtype_t)4) #define CPU_SUBTYPE_X86_64_H ((cpu_subtype_t)8)
|
例子中的为3,定义为CPU_SUBTYPE_X86_64_ALL |
| filetype | 说明文件类型(可执行文件、库文件、核心转储文件、内河扩展文件、DYSM文件、动态库等) #define MH_OBJECT 0x1 编译过程中产生的 obj文件 (gcc -c xxx.c 生成xxx.o文件) #define MH_EXECUTE 0x2 可执行二进制文件 (/usr/bin/ls) #define MH_FVMLIB 0x3 #define MH_CORE 0x4 CoreDump (崩溃时的Dump文件) #define MH_PRELOAD 0x5 #define MH_DYLIB 0x6 动态库(/usr/lib/里面的那些共享库文件) #define MH_DYLINKER 0x7 连接器linker(/usr/lib/dyld文件) #define MH_BUNDLE 0x8 #define MH_DYLIB_STUB 0x9 #define MH_DSYM 0xa #define MH_KEXT_BUNDLE 0xb 内核扩展文件 (自己开发的简单内核模块 |
例子中值为2MH-EXECUTE,二进制可执行文件 |
| ncmds | 说明加载命令的条数 | 例子中为22,说明有22条加载命令,对应Load Commands中的22项 |
| sizeofcmds | 表示加载命令的大小 | 例子中为3096字节 |
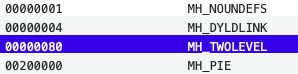
| flags | 标志位,表示二进制文件支持的功能,主要是和系统加载,链接相关 #define MH_NOUNDEFS 0x1 #define MH_INCRLINK 0x2 #define MH_DYLDLINK 0x4 #define MH_LAZY_INIT 0x40 #define MH_TWOLEVEL 0x80 #define MH_PIE 0x200000 |
例子中为0x200085,
MH-NOUNDEFS表示:目标没有未定义的符号,不存在链接依赖 MH-DYLDLINK表示:该目标文件是dyld的输入文件,无法被再次的静态链接 MH-TWOLEVEL表示:动态加载二级名称空间 MH-PIE表示:地址空间布局随机化 |
| reserved | 64位的保留字段 | 详细请看loader.h |
系统先解释头文件、获得文件支持位数(32 、64),获得CPU类型,获得文件类型,加载命令条数和大小,获得文件标识。
0xx2 Load Commands-加载命令
在mach_header之后是Load Command加载命令,这些加载命令在Mach-O文件加载解析时,会被内核加载器或者动态链接器调用,基本的加载命令的数据结构如下:
struct load_command {
uint32_t cmd; /* type of load command */
uint32_t cmdsize; /* total size of command in bytes */
};此结构对应的成员只有两个:cmd字段代表当前加载命令的类型,cmdsize字段代表当前加载命令的大小。
cmd的类型不同,所代表的加载命令的类型就不同,它的结构体也会有所不同。不同类型的加载命令会在load_command结构体后面加上一个或多个字段来表示特定的结构体信息。
在macOS系统进化的过程中,加载命令是更新比较频繁的一个数据结构体。加载命令的类型cmd的取值共有0x22种,它们的定义如下:
#define LC_SEGMENT 0x1 /* segment of this file to be mapped */
#define LC_SYMTAB 0x2 /* link-edit stab symbol table info */
#define LC_SYMSEG 0x3 /* link-edit gdb symbol table info (obsolete) */
#define LC_THREAD 0x4 /* thread */
#define LC_UNIXTHREAD 0x5 /* unix thread (includes a stack) */
#define LC_LOADFVMLIB 0x6 /* load a specified fixed VM shared library */
#define LC_IDFVMLIB 0x7 /* fixed VM shared library identification */
#define LC_IDENT 0x8 /* object identification info (obsolete) */
#define LC_FVMFILE 0x9 /* fixed VM file inclusion (internal use) */
#define LC_PREPAGE 0xa /* prepage command (internal use) */
#define LC_DYSYMTAB 0xb /* dynamic link-edit symbol table info */
#define LC_LOAD_DYLIB 0xc /* load a dynamically linked shared library */
#define LC_ID_DYLIB 0xd /* dynamically linked shared lib ident */
#define LC_LOAD_DYLINKER 0xe /* load a dynamic linker */
#define LC_ID_DYLINKER 0xf /* dynamic linker identification */
#define LC_PREBOUND_DYLIB 0x10 /* modules prebound for a dynamically */
/* linked shared library */
#define LC_ROUTINES 0x11 /* image routines */
#define LC_SUB_FRAMEWORK 0x12 /* sub framework */
#define LC_SUB_UMBRELLA 0x13 /* sub umbrella */
#define LC_SUB_CLIENT 0x14 /* sub client */
#define LC_SUB_LIBRARY 0x15 /* sub library */
#define LC_TWOLEVEL_HINTS 0x16 /* two-level namespace lookup hints */
#define LC_PREBIND_CKSUM 0x17 /* prebind checksum */
/*
* load a dynamically linked shared library that is allowed to be missing
* (all symbols are weak imported).
*/
#define LC_LOAD_WEAK_DYLIB (0x18 | LC_REQ_DYLD)
#define LC_SEGMENT_64 0x19 /* 64-bit segment of this file to be
mapped */
#define LC_ROUTINES_64 0x1a /* 64-bit image routines */
#define LC_UUID 0x1b /* the uuid */
#define LC_RPATH (0x1c | LC_REQ_DYLD) /* runpath additions */
#define LC_CODE_SIGNATURE 0x1d /* local of code signature */
#define LC_SEGMENT_SPLIT_INFO 0x1e /* local of info to split segments */
#define LC_REEXPORT_DYLIB (0x1f | LC_REQ_DYLD) /* load and re-export dylib */
#define LC_LAZY_LOAD_DYLIB 0x20 /* delay load of dylib until first use */
#define LC_ENCRYPTION_INFO 0x21 /* encrypted segment information */
#define LC_DYLD_INFO 0x22 /* compressed dyld information */
#define LC_DYLD_INFO_ONLY (0x22|LC_REQ_DYLD) /* compressed dyld information only */所有这些加载命令由系统内核加载器直接使用,或由动态链接器处理。其中几个常见的加载命令为LC_SEGMENT、LC_LOAD_DYLINKER、LC_LOAD_DYLIB、LC_MAIN、LC_CODE_SIGNATURE、LC_ENCRYPTION_INFO等。下面进行分析:
segment_command结构体定义:
/*
* The segment load command indicates that a part of this file is to be
* mapped into the task's address space. The size of this segment in memory,
* vmsize, maybe equal to or larger than the amount to map from this file,
* filesize. The file is mapped starting at fileoff to the beginning of
* the segment in memory, vmaddr. The rest of the memory of the segment,
* if any, is allocated zero fill on demand. The segment's maximum virtual
* memory protection and initial virtual memory protection are specified
* by the maxprot and initprot fields. If the segment has sections then the
* section structures directly follow the segment command and their size is
* reflected in cmdsize.
*/
struct segment_command { /* for 32-bit architectures */
uint32_t cmd; /* LC_SEGMENT */
uint32_t cmdsize; /* includes sizeof section structs */
char segname[16]; /* segment name */
uint32_t vmaddr; /* memory address of this segment */
uint32_t vmsize; /* memory size of this segment */
uint32_t fileoff; /* file offset of this segment */
uint32_t filesize; /* amount to map from the file */
vm_prot_t maxprot; /* maximum VM protection */
vm_prot_t initprot; /* initial VM protection */
uint32_t nsects; /* number of sections in segment */
uint32_t flags; /* flags */
};
/*
* The 64-bit segment load command indicates that a part of this file is to be
* mapped into a 64-bit task's address space. If the 64-bit segment has
* sections then section_64 structures directly follow the 64-bit segment
* command and their size is reflected in cmdsize.
*/
struct segment_command_64 { /* for 64-bit architectures */
uint32_t cmd; /* LC_SEGMENT_64 */
uint32_t cmdsize; /* includes sizeof section_64 structs */
char segname[16]; /* segment name */
uint64_t vmaddr; /* memory address of this segment */
uint64_t vmsize; /* memory size of this segment */
uint64_t fileoff; /* file offset of this segment */
uint64_t filesize; /* amount to map from the file */
vm_prot_t maxprot; /* maximum VM protection */
vm_prot_t initprot; /* initial VM protection */
uint32_t nsects; /* number of sections in segment */
uint32_t flags; /* flags */
};例子:

| 段 | 含义 |
|---|---|
| _PAGEZERO | 空指针陷阱段,映射到虚拟内存空间第一页,捕捉对NULL指针的引用 |
| _TEXT | 代码段、只读数据段 |
| _DATA | 读取和写入数据段 |
| _LINKEDIT | dyld需要使用的信息,包括重定位、绑定、懒加载信息等 |
dyld_info_command结构体
/*
* The dyld_info_command contains the file offsets and sizes of
* the new compressed form of the information dyld needs to
* load the image. This information is used by dyld on Mac OS X
* 10.6 and later. All information pointed to by this command
* is encoded using byte streams, so no endian swapping is needed
* to interpret it.
*/
struct dyld_info_command {
uint32_t cmd; /* LC_DYLD_INFO or LC_DYLD_INFO_ONLY */
uint32_t cmdsize; /* sizeof(struct dyld_info_command) */
/*
* Dyld rebases an image whenever dyld loads it at an address different
* from its preferred address. The rebase information is a stream
* of byte sized opcodes whose symbolic names start with REBASE_OPCODE_.
* Conceptually the rebase information is a table of tuples:
*
* The opcodes are a compressed way to encode the table by only
* encoding when a column changes. In addition simple patterns
* like "every n'th offset for m times" can be encoded in a few
* bytes.
*/
uint32_t rebase_off; /* file offset to rebase info */
uint32_t rebase_size; /* size of rebase info */
/*
* Dyld binds an image during the loading process, if the image
* requires any pointers to be initialized to symbols in other images.
* The rebase information is a stream of byte sized
* opcodes whose symbolic names start with BIND_OPCODE_.
* Conceptually the bind information is a table of tuples:
*
* The opcodes are a compressed way to encode the table by only
* encoding when a column changes. In addition simple patterns
* like for runs of pointers initialzed to the same value can be
* encoded in a few bytes.
*/
uint32_t bind_off; /* file offset to binding info */
uint32_t bind_size; /* size of binding info */
/*
* Some C++ programs require dyld to unique symbols so that all
* images in the process use the same copy of some code/data.
* This step is done after binding. The content of the weak_bind
* info is an opcode stream like the bind_info. But it is sorted
* alphabetically by symbol name. This enable dyld to walk
* all images with weak binding information in order and look
* for collisions. If there are no collisions, dyld does
* no updating. That means that some fixups are also encoded
* in the bind_info. For instance, all calls to "operator new"
* are first bound to libstdc++.dylib using the information
* in bind_info. Then if some image overrides operator new
* that is detected when the weak_bind information is processed
* and the call to operator new is then rebound.
*/
uint32_t weak_bind_off; /* file offset to weak binding info */
uint32_t weak_bind_size; /* size of weak binding info */
/*
* Some uses of external symbols do not need to be bound immediately.
* Instead they can be lazily bound on first use. The lazy_bind
* are contains a stream of BIND opcodes to bind all lazy symbols.
* Normal use is that dyld ignores the lazy_bind section when
* loading an image. Instead the static linker arranged for the
* lazy pointer to initially point to a helper function which
* pushes the offset into the lazy_bind area for the symbol
* needing to be bound, then jumps to dyld which simply adds
* the offset to lazy_bind_off to get the information on what
* to bind.
*/
uint32_t lazy_bind_off; /* file offset to lazy binding info */
uint32_t lazy_bind_size; /* size of lazy binding infs */
/*
* The symbols exported by a dylib are encoded in a trie. This
* is a compact representation that factors out common prefixes.
* It also reduces LINKEDIT pages in RAM because it encodes all
* information (name, address, flags) in one small, contiguous range.
* The export area is a stream of nodes. The first node sequentially
* is the start node for the trie.
*
* Nodes for a symbol start with a byte that is the length of
* the exported symbol information for the string so far.
* If there is no exported symbol, the byte is zero. If there
* is exported info, it follows the length byte. The exported
* info normally consists of a flags and offset both encoded
* in uleb128. The offset is location of the content named
* by the symbol. It is the offset from the mach_header for
* the image.
*
* After the initial byte and optional exported symbol information
* is a byte of how many edges (0-255) that this node has leaving
* it, followed by each edge.
* Each edge is a zero terminated cstring of the addition chars
* in the symbol, followed by a uleb128 offset for the node that
* edge points to.
*
*/
uint32_t export_off; /* file offset to lazy binding info */
uint32_t export_size; /* size of lazy binding infs */
};
例子:
| dymanic load info |
说明 |
举例 |
| 重定向数据 rebase |
demo中该段数据位 11 22 10 51 |
11: 高位0x10表示设置立即数类型,低位0x01表示立即数类型为指针
22: 表示REBASE_OPCODE_SET_SEGMENT_AND_OFFSET_ULEB + 2 重定向到数据段2。结合上面的信息,就是重定向到数据段2,该段数据信息为一个指针
结合数据段2的数据,获得一个重定向符号指针[0x100001924 -> _NSLog] |
| 绑定数据 bind |
在demo中进行动态绑定依赖的dyld的函数 |
U dyld_stub_binder |
| 弱绑定数据 weak bind |
用于弱绑定动态库,就像weak_framework一样 |
|
| 懒绑定数据 lazy bind |
对于需要从动态库加载的函数符号 |
demo中有一个: _NSLog |
| export数据 |
用于对外开放的函数 |
demo中有: 0x10000442f __mh_execute_header 0x100004453 myNSLog 0x10000445b main |
LC_SYMTAB结构体
/*
* The symtab_command contains the offsets and sizes of the link-edit 4.3BSD
* "stab" style symbol table information as described in the header files
* and .
*/
struct symtab_command {
uint32_t cmd; /* LC_SYMTAB */
uint32_t cmdsize; /* sizeof(struct symtab_command) */
uint32_t symoff; /* symbol table offset */
uint32_t nsyms; /* number of symbol table entries */
uint32_t stroff; /* string table offset */
uint32_t strsize; /* string table size in bytes */
}; 例子:

LC_LOAD_DYLINKER结构体
/*
* A program that uses a dynamic linker contains a dylinker_command to identify
* the name of the dynamic linker (LC_LOAD_DYLINKER). And a dynamic linker
* contains a dylinker_command to identify the dynamic linker (LC_ID_DYLINKER).
* A file can have at most one of these.
*/
struct dylinker_command {
uint32_t cmd; /* LC_ID_DYLINKER or LC_LOAD_DYLINKER */
uint32_t cmdsize; /* includes pathname string */
union lc_str name; /* dynamic linker's path name */
};例子:

LC_UUID结构体
/*
* The uuid load command contains a single 128-bit unique random number that
* identifies an object produced by the static link editor.
*/
struct uuid_command {
uint32_t cmd; /* LC_UUID */
uint32_t cmdsize; /* sizeof(struct uuid_command) */
uint8_t uuid[16]; /* the 128-bit uuid */
};例子:

LC_LOAD_DYLIB结构体
/*
* Dynamicly linked shared libraries are identified by two things. The
* pathname (the name of the library as found for execution), and the
* compatibility version number. The pathname must match and the compatibility
* number in the user of the library must be greater than or equal to the
* library being used. The time stamp is used to record the time a library was
* built and copied into user so it can be use to determined if the library used
* at runtime is exactly the same as used to built the program.
*/
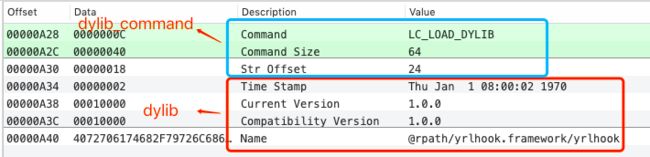
struct dylib {
union lc_str name; /* library's path name */
uint32_t timestamp; /* library's build time stamp */
uint32_t current_version; /* library's current version number */
uint32_t compatibility_version; /* library's compatibility vers number*/
};
/*
* A dynamically linked shared library (filetype == MH_DYLIB in the mach header)
* contains a dylib_command (cmd == LC_ID_DYLIB) to identify the library.
* An object that uses a dynamically linked shared library also contains a
* dylib_command (cmd == LC_LOAD_DYLIB, LC_LOAD_WEAK_DYLIB, or
* LC_REEXPORT_DYLIB) for each library it uses.
*/
struct dylib_command {
uint32_t cmd; /* LC_ID_DYLIB, LC_LOAD_{,WEAK_}DYLIB,
LC_REEXPORT_DYLIB */
uint32_t cmdsize; /* includes pathname string */
struct dylib dylib; /* the library identification */
};例子:
LC_RPATH结构体
/*
* The rpath_command contains a path which at runtime should be added to
* the current run path used to find @rpath prefixed dylibs.
*/
struct rpath_command {
uint32_t cmd; /* LC_RPATH */
uint32_t cmdsize; /* includes string */
union lc_str path; /* path to add to run path */
};
例子:

| segname cmd | 说明 | 举例 |
| LC_SEGMENT_64 | 表示这是一个段加载命令,需要将它加载到对应的进程空间中 | |
| LC_DYLD_INFO_ONLY | 动态库信息,根据该命令是真正动态库绑定,地址重定向重要的信息 | |
| LC_SYMTAB | 符号表地址 | |
| LC_DYSYMTAB | 动态符号表地址 | |
| LC_LOAD_DYLINKER | 使用何种动态加载库,dyld的默认路径 | 例子中用的是/usr/lib/dyld |
| LC_UUID | 文件的唯一标识,crash解析中也会有该只,去确定dysm文件和crash文件是匹配的 | |
| LC_BUILD_VERSION |
二进制文件要求的sdk的build版本 | sdk 12.4 |
| LC_SOURCE_VERSION | 构建该二进制文件使用的源代码版本 | 例子中是 0.0 |
| LC_MAIN |
设置程序主线程的入口地址和栈大小 | 例子中是入口地址:0x0000000000000EF0,栈大小:0 |
| LC_LOAD_DYLIB | 加载额外的动态库,仔细看这个命令格式,动态库地址和名,当前版本号,兼容版本号,该设计比较合理,如果对于动态库有版本管理能力 | |
| LC_RPATH | rpath_命令包含运行时应添加到的路径 用于查找前缀为@rpath的dylibs的当前运行路径 |
例子中为 @executable_path/Frameworks |
| LC_FUNCTION_STARTS | 函数起始地址表,指向了FUNCTION_STARTS的首地址 | 例子中0x000044E0 |
| LC_DATA_IN_CODE | 代码签名信息 |
0xx3 DATA(Section64)
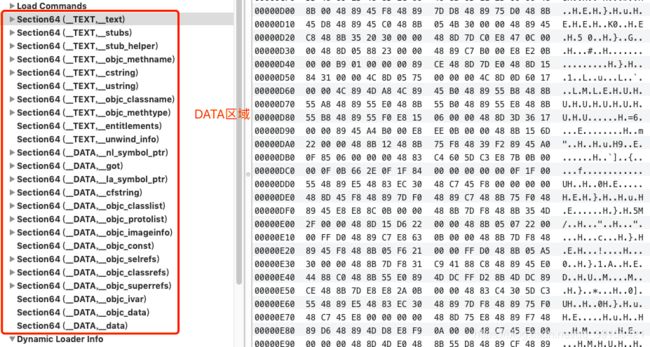
Load Commands区域下来接着就是DATA区域,展开Load Commands下的LC_SEGMENT_64可以看到多个Section64,各个Section的具体信息可以在Load Commands紧接着的部分查看,它们是一一对应的:
section的数据结构如下:
/*
* A segment is made up of zero or more sections. Non-MH_OBJECT files have
* all of their segments with the proper sections in each, and padded to the
* specified segment alignment when produced by the link editor. The first
* segment of a MH_EXECUTE and MH_FVMLIB format file contains the mach_header
* and load commands of the object file before its first section. The zero
* fill sections are always last in their segment (in all formats). This
* allows the zeroed segment padding to be mapped into memory where zero fill
* sections might be. The gigabyte zero fill sections, those with the section
* type S_GB_ZEROFILL, can only be in a segment with sections of this type.
* These segments are then placed after all other segments.
*
* The MH_OBJECT format has all of its sections in one segment for
* compactness. There is no padding to a specified segment boundary and the
* mach_header and load commands are not part of the segment.
*
* Sections with the same section name, sectname, going into the same segment,
* segname, are combined by the link editor. The resulting section is aligned
* to the maximum alignment of the combined sections and is the new section's
* alignment. The combined sections are aligned to their original alignment in
* the combined section. Any padded bytes to get the specified alignment are
* zeroed.
*
* The format of the relocation entries referenced by the reloff and nreloc
* fields of the section structure for mach object files is described in the
* header file .
*/
struct section { /* for 32-bit architectures */
char sectname[16]; /* name of this section */
char segname[16]; /* segment this section goes in */
uint32_t addr; /* memory address of this section */
uint32_t size; /* size in bytes of this section */
uint32_t offset; /* file offset of this section */
uint32_t align; /* section alignment (power of 2) */
uint32_t reloff; /* file offset of relocation entries */
uint32_t nreloc; /* number of relocation entries */
uint32_t flags; /* flags (section type and attributes)*/
uint32_t reserved1; /* reserved (for offset or index) */
uint32_t reserved2; /* reserved (for count or sizeof) */
};
struct section_64 { /* for 64-bit architectures */
char sectname[16]; /* name of this section */
char segname[16]; /* segment this section goes in */
uint64_t addr; /* memory address of this section */
uint64_t size; /* size in bytes of this section */
uint32_t offset; /* file offset of this section */
uint32_t align; /* section alignment (power of 2) */
uint32_t reloff; /* file offset of relocation entries */
uint32_t nreloc; /* number of relocation entries */
uint32_t flags; /* flags (section type and attributes)*/
uint32_t reserved1; /* reserved (for offset or index) */
uint32_t reserved2; /* reserved (for count or sizeof) */
uint32_t reserved3; /* reserved */
};
section节已经是最小的分类,大部分内容集中在__TEXT,__DATA这两段中,部分内容如下:
| 名称 | 作用 |
|---|---|
| TEXT.text | 只有可执行的机器码 |
| TEXT.cstring | 去重后的C字符串 |
| TEXT.const | 初始化过的常量 |
| TEXT.stubs | 符号桩。本质上是一小段会直接跳入lazybinding的表对应项指针指向的地址的代码。 |
| TEXT.stub_helper | 辅助函数。上述提到的lazybinding的表中对应项的指针在没有找到真正的符号地址的时候,都指向这。 |
| TEXT.unwind_info | 用于存储处理异常情况信息 |
| TEXT.eh_frame | 调试辅助信息 |
| DATA.data | 初始化过的可变的数据 |
| DATA.nl_symbol_ptr | 非lazy-binding的指针表,每个表项中的指针都指向一个在装载过程中,被动态链机器搜索完成的符号 |
| DATA.la_symbol_ptr | lazy-binding的指针表,每个表项中的指针一开始指向stub_helper |
| DATA.const | 没有初始化过的常量 |
| DATA.mod_init_func | 初始化函数,在main之前调用 |
| DATA.mod_term_func | 终止函数,在main返回之后调用 |
| DATA.bss | 没有初始化的静态变量 |
| DATA.common | 没有初始化过的符号声明 |
0xx4 Dynamic Loader Info
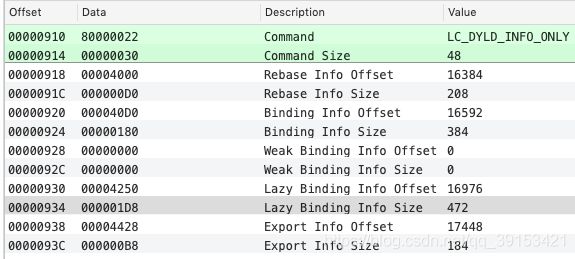
在:Loader Commands下的LC_DYLD_INFO_ONLY指向了它,分别有rebase info、Binding info、Weak Binding info、Lazy Binding info、Export Info。
几个重要的参数:
| dymanic load info | |
|---|---|
| Rebase info | 重定向数据 |
| Binding info | 进行动态绑定依赖的dyld的函数 |
| Lazy Binding info | 需要从动态库加载的函数符号 |
| Export info | 对外开放的函数 |
rebase修复的是指向当前镜像内部的资源指针(mach-o每次加载到内存中不是固定的地址)
binding就是将这个二进制调用的外部符号进行绑定的过程。 比如我们objc代码中需要使用到NSObject, 即符号OBJC_CLASS$_NSObject,但是这个符号又不在我们的二进制中,在系统库 Foundation.framework中,因此就需要binding这个操作将对应关系绑定到一起。
lazyBinding就是在加载动态库的时候不会立即binding, 当时当第一次调用这个方法的时候再实施binding。 做到的方法也很简单: 通过dyld_stub_binder 这个符号来做。 lazy binding的方法第一次会调用到dyld_stub_binder, 然后dyld_stub_binder负责找到真实的方法,并且将地址bind到桩上,下一次就不用再bind了。
weakBinding针对弱符号进行绑定的过程, 在c语言中,函数、初始化的全局变量、static变量是强符号,未初始化的全局变量是弱符号。 weakBinding这一步会把AllImages中所有含有弱符号的映像合并成一个列表,再进行binding. 所以这一步放在最后,等加载完成后在做操作。
Rebase Info表示重定位,数据是以命令码(命令码就是一个字节码)的形式,传递具体内容。高四位表示真正命令名,低四位表示一个立即数。00表示该类型命令结束.
定义的数据:
/*
* The following are used to encode rebasing information
*/
#define REBASE_TYPE_POINTER 1
#define REBASE_TYPE_TEXT_ABSOLUTE32 2
#define REBASE_TYPE_TEXT_PCREL32 3
#define REBASE_OPCODE_MASK 0xF0
#define REBASE_IMMEDIATE_MASK 0x0F
#define REBASE_OPCODE_DONE 0x00
#define REBASE_OPCODE_SET_TYPE_IMM 0x10
#define REBASE_OPCODE_SET_SEGMENT_AND_OFFSET_ULEB 0x20
#define REBASE_OPCODE_ADD_ADDR_ULEB 0x30
#define REBASE_OPCODE_ADD_ADDR_IMM_SCALED 0x40
#define REBASE_OPCODE_DO_REBASE_IMM_TIMES 0x50
#define REBASE_OPCODE_DO_REBASE_ULEB_TIMES 0x60
#define REBASE_OPCODE_DO_REBASE_ADD_ADDR_ULEB 0x70
#define REBASE_OPCODE_DO_REBASE_ULEB_TIMES_SKIPPING_ULEB 0x80
/*
* The following are used to encode binding information
*/
#define BIND_TYPE_POINTER 1
#define BIND_TYPE_TEXT_ABSOLUTE32 2
#define BIND_TYPE_TEXT_PCREL32 3
#define BIND_SPECIAL_DYLIB_SELF 0
#define BIND_SPECIAL_DYLIB_MAIN_EXECUTABLE -1
#define BIND_SPECIAL_DYLIB_FLAT_LOOKUP -2
#define BIND_SYMBOL_FLAGS_WEAK_IMPORT 0x1
#define BIND_SYMBOL_FLAGS_NON_WEAK_DEFINITION 0x8
#define BIND_OPCODE_MASK 0xF0
#define BIND_IMMEDIATE_MASK 0x0F
#define BIND_OPCODE_DONE 0x00
#define BIND_OPCODE_SET_DYLIB_ORDINAL_IMM 0x10
#define BIND_OPCODE_SET_DYLIB_ORDINAL_ULEB 0x20
#define BIND_OPCODE_SET_DYLIB_SPECIAL_IMM 0x30
#define BIND_OPCODE_SET_SYMBOL_TRAILING_FLAGS_IMM 0x40
#define BIND_OPCODE_SET_TYPE_IMM 0x50
#define BIND_OPCODE_SET_ADDEND_SLEB 0x60
#define BIND_OPCODE_SET_SEGMENT_AND_OFFSET_ULEB 0x70
#define BIND_OPCODE_ADD_ADDR_ULEB 0x80
#define BIND_OPCODE_DO_BIND 0x90
#define BIND_OPCODE_DO_BIND_ADD_ADDR_ULEB 0xA0
#define BIND_OPCODE_DO_BIND_ADD_ADDR_IMM_SCALED 0xB0
#define BIND_OPCODE_DO_BIND_ULEB_TIMES_SKIPPING_ULEB 0xC0
/*
* The following are used on the flags byte of a terminal node
* in the export information.
*/
#define EXPORT_SYMBOL_FLAGS_KIND_MASK 0x03
#define EXPORT_SYMBOL_FLAGS_KIND_REGULAR 0x00
#define EXPORT_SYMBOL_FLAGS_KIND_THREAD_LOCAL 0x01
#define EXPORT_SYMBOL_FLAGS_WEAK_DEFINITION 0x04
#define EXPORT_SYMBOL_FLAGS_INDIRECT_DEFINITION 0x08
#define EXPORT_SYMBOL_FLAGS_HAS_SPECIALIZATIONS 0x10
如在这段中读到的第一个字节是0x11,那么这个命令掩码=0x10和立即数1
#define REBASE_OPCODE_SET_TYPE_IMM 0x10 说明当前命令是在选择重定位的数据的类型后面的立即数就是类型。
#define REBASE_TYPE_POINTER 1
#define REBASE_TYPE_TEXT_ABSOLUTE32 2
#define REBASE_TYPE_TEXT_PCREL32 3
上面综合起来,就是设置当前的重定位类型为指针,这也是最多见的类型。
这个重定位命令就结束了,再读取下一个字节,同样的方法判断命令掩码。
如果是0x21,那么就是REBASE_OPCODE_SET_SEGMENT_AND_OFFSET_ULEB + 1。这个代表着定位重定位段到第1个段(通常是数据段),因为代码段只读,代码段的内容已经设计成位置无关(PIC position indepent code)。后面还有一个ULEB类型的数据,代表在这个段中偏移多少。每当遇到DO_REBASE开头的命令,才会真正对上面一段关于重定位的信息来做重定位,具体怎么做我们不需要关心,编译器和链接器已经把哪些东西需要重定位写入了重定位表。
可以用dylyinfo获取这部分信息:xcrun dyldinfo -opcodes
rebase opcodes:
0x0000 REBASE_OPCODE_SET_TYPE_IMM(1)
0x0001 REBASE_OPCODE_SET_SEGMENT_AND_OFFSET_ULEB(2, 0x00000028)
0x0003 REBASE_OPCODE_DO_REBASE_ULEB_TIMES(19)
0x0005 REBASE_OPCODE_ADD_ADDR_IMM_SCALED(0x10)
0x0006 REBASE_OPCODE_DO_REBASE_ADD_ADDR_ULEB(32)
0x0008 REBASE_OPCODE_DO_REBASE_ADD_ADDR_ULEB(32)
0x000A REBASE_OPCODE_DO_REBASE_ADD_ADDR_ULEB(16)
0x000C REBASE_OPCODE_DO_REBASE_IMM_TIMES(4)
0x000D REBASE_OPCODE_ADD_ADDR_IMM_SCALED(0x20)
0x000E REBASE_OPCODE_DO_REBASE_ADD_ADDR_ULEB(56)
0x0010 REBASE_OPCODE_DO_REBASE_IMM_TIMES(6)
......
binding opcodes:
0x0000 BIND_OPCODE_SET_DYLIB_ORDINAL_IMM(3)
0x0001 BIND_OPCODE_SET_SYMBOL_TRAILING_FLAGS_IMM(0x00, _OBJC_METACLASS_$_NSObject)
0x001D BIND_OPCODE_SET_TYPE_IMM(1)
0x001E BIND_OPCODE_SET_SEGMENT_AND_OFFSET_ULEB(0x02, 0x00000DA0)
0x0021 BIND_OPCODE_DO_BIND_ADD_ADDR_IMM_SCALED(0x00000028)
0x0022 BIND_OPCODE_DO_BIND()
0x0023 BIND_OPCODE_SET_SYMBOL_TRAILING_FLAGS_IMM(0x00, __objc_empty_cache)
0x0037 BIND_OPCODE_ADD_ADDR_ULEB(0xFFFFFFB8)
......+ __stubs区和__stub_helper区是帮助动态链接器找到指定数据段__nl_symbol_ptr区,二进制文件用0x0000000000000000进行占位,在运行时,系统根据dynamic loader info信息,把占位符换为调用dylib的dyld_stub_binder函数的汇编指令。
+ 当第一次调用完动态库中的符号后,动态链接器会根据dynamic loader info信息,把数据段__la_symbol_ptr指向正在的符号地址,而不是指向_nl_symbol_ptr区
0xx5 Function Starts、Symbol Table、Dynamic Symbol Table、String Table、Code Signature
Function Starts指明了函数的起始地址,描述(uleb128)、value的值
下面的按例子程序加载的流程说:
程序通过动态加载NSLog函数到DATA段的Lazy Symbol Pointers,(在加载之前vlaue值是不对的(站位的))加载后dyld将真实的NSLog的地址写入到Lazy Symbol Pointers中,这个表与Dynamic Symbol Table下的Indirect Symbols的表项一一对应,在Indirect Symbols表项的第一位找到NSLog函数的偏移0x79,然后在Symbol Table下的Symbols表的第0x79项找到NSLog函数,得到它在String Table中的索引(0x9b),然后在StringTable中找到NSLog字符串,在String Table定位:基址加偏移 0x4f1c+0x9b = 0x4fb7 ,在StringTable中找到对应位置0x4fb7

这就是这几个表之间的联系和作用,最后Code Signature是用来代码签名的文件。
可执行文件运行过程
根据上面总结。该段总结下可执行文件运行过程。
我总结如下:
- 解析mach-o文件
- 设置运行环境参数
- 文本段VM映射参数
- 加载命令
- 动态库信息
- 符号表地址信息
- 动态符号表地址信息
- 常亮字符串表地址信息
- 动态库加载信息
- 符号函数地址
- 依赖动态库信息
- 动态链接器地址信息
- 根据动态库加载信息,把桩占位符,填写为指定调用_nl_symbol_ptr的汇编指令
- 根据LC_MAIN的entry point调用指定entry offset偏移地址
- 执行entry offset相关二进制(逻辑是按照汇编指令,进行运行)
- 第一次运行到动态库函数时,进行一次懒加载动态绑定,并且动态链接器自动修改_la_symbol_ptr区的地址,指向动态库对应符号的地址
- 第二次运行到动态库函数时,直接jmp到指定的符号地址
注意:系统很多动态库都是共有的,所以XOS做了共享库缓存优化,只要有相关进程使用过相关动态库,在另一进程,动态链接器在填桩时,直接会把桩_la_symbol_ptr区的地址,指向动态库对应符号的地址。
参考链接:
Mach-O文件格式和程序从加载到执行过程
解析Mach-O文件
macOS软件内幕
MAC系统中可执行文件格式(Mach-O)的学习(四)
Mach-O --- 动态库与静态库
深入剖析Macho (1)