MySQL · 引擎特性 · InnoDB文件系统管理(一)
综述
从上层的角度来看,InnoDB层的文件,除了redo日志外,基本上具有相当统一的结构,都是固定block大小,普遍使用的btree结构来管理数据。只是针对不同的block的应用场景会分配不同的页类型。通常默认情况下,每个block的大小为UNIV_PAGE_SIZE,在不做任何配置时值为16kb,你还可以选择在安装实例时指定一个块的block大小。 对于压缩表,可以在建表时指定block size,但在内存中表现的解压页依旧为统一的页大小。
从物理文件的分类来看,有日志文件,主系统表空间文件ibdata,undo tablespace文件,临时表空间文件,用户表空间。
日志文件主要用于记录redo log,InnoDB采用循环使用的方式,你可以通过参数指定创建文件的个数和每个文件的大小。默认情况下,日志是以512字节的block单位写入。由于现代文件系统的block size通常设置到4k,InnoDB提供了一个选项,可以让用户将写入的redo日志填充到4KB,以避免read-modify-write的现象;而Percona Server则提供了另外一个选项,支持直接将redo日志的block size修改成指定的值。
ibdata是InnoDB最重要的系统表空间文件,它记录了InnoDB的核心信息,包括事务系统信息,元数据信息,记录InnoDB change buffer的btree, 防止数据损坏的double write buffer等等关键信息。我们稍后会展开描述。
undo独立表空间是一个可选项,通常默认情况下,undo数据是存储在ibdata中的,但你也可以通过配置选项innodb_undo_tablespaces来将undo 回滚段分配到不同的文件中,目前开启undo tablespace只能在install阶段进行。在主流版本进入5.7时代后,我们建议开启独立undo表空间,只有这样才能利用到5.7引入的新特效:online undo truncate。
MySQL 5.7新开辟了一个临时表空间,默认的磁盘文件命名为ibtmp1,所有非压缩的临时表都存储在该表空间中。由于临时表的本身属性,该文件在重启时会重新创建。对于云服务提供商而言,通过ibtmp文件,可以更好的控制临时文件产生的磁盘存储。
用户表空间,顾名思义,就是用于自己创建的表空间,通常分为两类,一类是一个表空间一个文件,另外一种则是5.7版本引入的所谓General Tablespace,在满足一定约束条件下,可以将多个表创建到同一个文件中。除此之外,InnoDB还定义了一些特殊用途的ibd文件,例如全文索引相关的表文件。而针对空间数据类型,也构建了不同的数据索引格式R-tree。
为了管理磁盘文件的读写操作,InnoDB设计了一套文件IO操作接口,提供了同步IO和异步IO两种文件读写方式。针对异步IO,支持两种方式:一种是Native AIO,这需要你在编译阶段加上LibAio的Dev包,另外一种是simulated aio模式,InnoDB早期实现了一套系统来模拟异步IO,但现在Native Aio已经很成熟了,并且Simulated Aio本身存在性能问题,建议生产环境开启Native Aio模式。
对于数据读操作,通常用户线程触发的数据块请求读是同步读,如果开启了数据预读机制的话,预读的数据块则为异步读,由后台IO线程进行。其他后台线程也会触发数据读操作,例如Purge线程在无效数据清理,会读undo页和数据页;Master线程定期做ibuf merge也会读入数据页。崩溃恢复阶段也可能触发异步读来加速recover的速度。
对于数据写操作,InnoDB和大部分数据库系统一样,都是WAL模式,即先写日志,延迟写数据页。事务日志的写入通常在事务提交时触发,后台master线程也会每秒做一次redo fsync。数据页则通常由后台Page cleaner线程触发。但当buffer pool空闲block不够时,或者没做checkpoint的lsn age太长时,也会驱动刷脏操作,这两种场景由用户线程来触发。Percona Server据此做了优化来避免用户线程参与。MySQL5.7也对应做了些不一样的优化。
除了数据块操作,还是物理文件级别的操作,例如truncate, drop table,rename table等DDL操作,InnoDB需要对这些操作进行协调,目前的解法是通过特殊的flag和计数器的方式来解决。
当文件读入内存后,我们需要一种统一的方式来对数据进行管理,在启动实例时,InnoDB会按照instance分区分配多个一大块内存(在5.7里则是按照可配置的chunk size进行内存块划分),每个chunk又以UNIV_PAGE_SIZE为单位进行划分。数据读入内存时,会从buffer pool的free list中分配一个空闲block。所有的数据页都存储在一个LRU链表上。修改过的block被加到flush_list上,解压的数据页被放到unzip_LRU链表上。我们可以配置buffer pool为多个instance,以降低对链表的竞争开销。
从物理文件到内存管理是一个相对比较庞大的架构,本文将一一为读者进行分析解读,以让读者对InnoDB的文件系统管理有个更加全面的认识。在关键的地方本文注明了代码函数,建议读者边参考代码边阅读本文。
本文的代码部分基于MySQL 5.7.11版本,不同的版本函数名或逻辑可能会有所不同。请读者阅读本文时尽量选择该版本的代码。
物理文件
本小节主要从文件的物理结构的角度阐述InnoDB在最底层如何对物理文件进行管理,再分别介绍各类文件的不同结构。
文件管理页
InnoDB的每个数据文件都归属于一个表空间,不同的表空间使用一个唯一标识的space id来标记。例如ibdata1, ibdata2...归属系统表空间,拥有相同的space id。用户创建表产生的ibd文件,则认为是一个独立的tablespace,只包含一个文件。
每个文件按照固定的page size进行区分,默认情况下,非压缩表的page size为16Kb。而在文件内部又按照64个Page(总共1M)一个Extent的方式进行划分并管理。对于不同的page size,对应的Extent大小也不同,对应为:
| page size | file space extent size |
|---|---|
| 4 KiB | 256 pages = 1 MiB |
| 8 KiB | 128 pages = 1 MiB |
| 16 KiB | 64 pages = 1 MiB |
| 32 KiB | 64 pages = 2 MiB |
| 64 KiB | 64 pages = 4 MiB |
尽管支持更大的Page Size,但目前还不支持大页场景下的数据压缩,原因是这涉及到修改压缩页中slot的固定size(其实实现起来也不复杂)。在不做声明的情况下,下文我们默认使用16KB的Page Size来阐述文件的物理结构。
为了管理整个Tablespace,除了索引页外,数据文件中还包含了多种管理页,如下图所示,一个用户表空间大约包含这些页来管理文件,下面会一一进行介绍。

文件链表
首先我们先介绍基于文件的一个基础结构,即文件链表。为了管理Page,Extent这些数据块,在文件中记录了许多的节点以维持具有某些特征的链表,例如在在文件头维护的inode page链表,空闲、用满以及碎片化的Extent链表等等。
在InnoDB里链表头称为FLST_BASE_NODE,大小为FLST_BASE_NODE_SIZE(16个字节)。BASE NODE维护了链表的头指针和末尾指针,每个节点称为FLST_NODE,大小为FLST_NODE_SIZE(12个字节)。相关结构描述如下:
FLST_BASE_NODE:
| Macro | bytes | Desc |
|---|---|---|
| FLST_LEN | 4 | 存储链表的长度 |
| FLST_FIRST | 6 | 指向链表的第一个节点 |
| FLST_LAST | 6 | 指向链表的最后一个节点 |
FLST_NODE:
| Macro | bytes | Desc |
|---|---|---|
| FLST_PREV | 6 | 指向当前节点的前一个节点 |
| FLST_NEXT | 6 | 指向当前节点的下一个节点 |
如上所述,文件链表中使用6个字节来作为节点指针,指针的内容包括:
| Macro | bytes | Desc |
|---|---|---|
| FIL_ADDR_PAGE | 4 | Page No |
| FIL_ADDR_BYTE | 2 | Page内的偏移量 |
该链表结构是InnoDB表空间内管理所有page的基础结构,下图先感受下,具体的内容可以继续往下阅读。
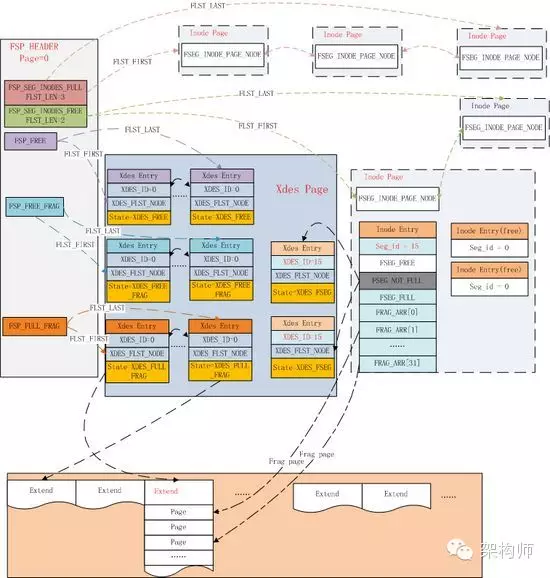
文件链表管理的相关代码参阅:include/fut0lst.ic, fut/fut0lst.cc
FSP_HDR PAGE
数据文件的第一个Page类型为FIL_PAGE_TYPE_FSP_HDR,在创建一个新的表空间时进行初始化(fsp_header_init),该page同时用于跟踪随后的256个Extent(约256MB文件大小)的空间管理,所以每隔256MB就要创建一个类似的数据页,类型为FIL_PAGE_TYPE_XDES ,XDES Page除了文件头部外,其他都和FSP_HDR页具有相同的数据结构,可以称之为Extent描述页,每个Extent占用40个字节,一个XDES Page最多描述256个Extent。
FSP_HDR页的头部使用FSP_HEADER_SIZE个字节来记录文件的相关信息,具体的包括:


在文件头使用FLAG(对应上述FSP_SPACE_FLAGS)描述了创建表时的如下关键信息:

除了上述描述信息外,其他部分的数据结构和XDES PAGE(FIL_PAGE_TYPE_XDES)都是相同的,使用连续数组的方式,每个XDES PAGE最多存储256个XDES Entry,每个Entry占用40个字节,描述64个Page(即一个Extent)。格式如下:
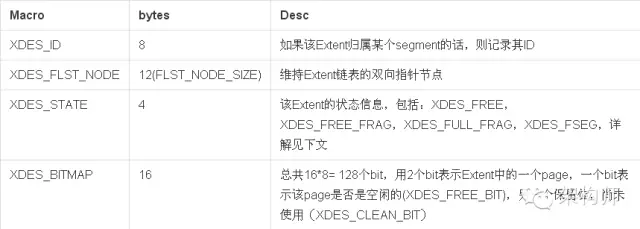 XDES_STATE表示该Extent的四种不同状态:
XDES_STATE表示该Extent的四种不同状态:

通过XDES_STATE信息,我们只需要一个FLIST_NODE节点就可以维护每个Extent的信息,是处于全局表空间的链表上,还是某个btree segment的链表上。
IBUF BITMAP PAGE
第2个page类型为FIL_PAGE_IBUF_BITMAP,主要用于跟踪随后的每个page的change buffer信息,使用4个bit来描述每个page的change buffer信息。

由于bitmap page的空间有限,同样每隔256个Extent Page之后,也会在XDES PAGE之后创建一个ibuf bitmap page。
关于change buffer,这里我们不展开讨论,感兴趣的可以阅读之前的这篇月报:
MySQL · 引擎特性 · Innodb change buffer介绍
INODE PAGE
数据文件的第3个page的类型为FIL_PAGE_INODE,用于管理数据文件中的segement,每个索引占用2个segment,分别用于管理叶子节点和非叶子节点。每个inode页可以存储FSP_SEG_INODES_PER_PAGE(默认为85)个记录。

每个Inode Entry的结构如下表所示:
文件维护
从上文我们可以看到,InnoDB通过Inode Entry来管理每个Segment占用的数据页,每个segment可以看做一个文件页维护单元。Inode Entry所在的inode page有可能存放满,因此又通过头Page维护了Inode Page链表。
在ibd的第一个Page中还维护了表空间内Extent的FREE、FREE_FRAG、FULL_FRAG三个Extent链表;而每个Inode Entry也维护了对应的FREE、NOT_FULL、FULL三个Extent链表。这些链表之间存在着转换关系,以高效的利用数据文件空间。
当创建一个新的索引时,实际上构建一个新的btree(btr_create),先为非叶子节点Segment分配一个inode entry,再创建root page,并将该segment的位置记录到root page中,然后再分配leaf segment的Inode entry,并记录到root page中。
当删除某个索引后,该索引占用的空间需要能被重新利用起来。
创建Segment
首先每个Segment需要从ibd文件中预留一定的空间(fsp_reserve_free_extents),通常是2个Extent。但如果是新创建的表空间,且当前的文件小于1个Extent时,则只分配2个Page。
当文件空间不足时,需要对文件进行扩展(fsp_try_extend_data_file)。文件的扩展遵循一定的规则:如果当前小于1个Extent,则扩展到1个Extent满;当表空间小于32MB时,每次扩展一个Extent;大于32MB时,每次扩展4个Extent(fsp_get_pages_to_extend_ibd)。
在预留空间后,读取文件头Page并加锁(fsp_get_space_header),然后开始为其分配Inode Entry(fsp_alloc_seg_inode)。 首先需要找到一个合适的inode page。
我们知道Inode Page的空间有限,为了管理Inode Page,在文件头存储了两个Inode Page链表,一个链接已经用满的inode page,一个链接尚未用满的inode page。如果当前Inode Page的空间使用完了,就需要再分配一个inode page,并加入到FSP_SEG_INODES_FREE链表上(fsp_alloc_seg_inode_page)。对于独立表空间,通常一个inode page就足够了。
当拿到目标inode page后,从该Page中找到一个空闲(fsp_seg_inode_page_find_free)未使用的slot(空闲表示其不归属任何segment,即FSEG_ID置为0)
一旦该inode page中的记录用满了,就从FSP_SEG_INODES_FREE链表上转移到FSP_SEG_INODES_FULL链表。
获得inode entry后,递增头page的FSP_SEG_ID,作为当前segment的seg id写入到inode entry中。随后进行一些列的初始化。
在完成inode entry的提取后,就将该inode entry所在inode page的位置及页内偏移量存储到其他某个page内(对于btree就是记录在根节点内,占用10个字节,包含space id, page no, offset)。
Btree的根节点实际上是在创建non-leaf segment时分配的,root page被分配到该segment的frag array的第一个数组元素中。
Segment分配入口函数: fseg_create_general
分配数据页
随着btree数据的增长,我们需要为btree的segment分配新的page。前面我们已经讲过,segment是一个独立的page管理单元,我们需要将从全局获得的数据空间纳入到segment的管理中。
Step 1: 空间扩展
当判定插入索引的操作可能引起分裂时,会进行悲观插入(btr_cur_pessimistic_insert),在做实际的分裂操作之前,会先对文件进行扩展,并尝试预留(tree_height / 16 + 3)个Extent,大多数情况下都是3个Extent。
这里有个意外场景:如果当前文件还不超过一个Extent,并且请求的page数小于1/2个Extent时,则如果指定page数,保证有2个可用的空闲Page,或者分配指定的page,而不是以Extent为单位进行分配。
注意这里只是保证有足够的文件空间,避免在btree操作时进行文件Extent。如果在这一步扩展了ibd文件(fsp_try_extend_data_file),新的数据页并未初始化,也未加入到任何的链表中。
在判定是否有足够的空闲Extent时,本身ibd预留的空闲空间也要纳入考虑,对于普通用户表空间是2个Extent + file_size * 1%。 这些新扩展的page此时并未进行初始化,也未加入到,在头page的FSP_FREE_LIMIT记录的page no标识了这类未初始化页的范围。
Step 2:为segment分配page
随后进入索引分裂阶段(btr_page_split_and_insert),新page分配的上层调用栈:
在传递的参数中,有个hint page no,通常是当前需要分裂的page no的前一个(direction = FSP_DOWN)或者后一个page no(direction = FSP_UP),其目的是将逻辑上相邻的节点在物理上也尽量相邻。
在Step 1我们已经保证了物理空间有足够的数据页,只是还没进行初始化。将page分配到当前segment的流程如下(fseg_alloc_free_page_low):
-
计算当前segment使用的和占用的page数
-
使用的page数存储包括FSEG_NOT_FULL链表上使用的page数(存储在inode entry的FSEG_NOT_FULL_N_USED中) + 已用满segment的FSEG_FULL链表上page数 + 占用的frag array page数量
-
占用的page数包括FSEG_FREE、FSEG_NOT_FULL 、FSEG_FULL三个链表上的Extent + 占用的frag array page数量。
-
-
根据hint page获取对应的xdes entry (
xdes_get_descriptor_with_space_hdr) -
当满足如下条件时该hint page可以直接拿走使用:
-
Extent状态为XDES_FSEG,表示属于一个segment
-
hint page所在的Extent已被分配给当前segment(检查xdes entry的XDES_ID)
-
hint page对应的bit设置为free,表示尚未被占用
-
返回hint page
-
-
当满足条件:1. xdes entry当前是空闲状态(XDES_FREE);2.该segment中已使用的page数大于其占用的page数的7/8 (FSEG_FILLFACTOR);3. 当前segment已经使用了超过32个frag page,即表示其inode中的frag array可能已经用满。
-
从表空间分配hint page所在的Extent (
fsp_alloc_free_extent),将其从FSP_FREE链表上移除 -
设置该Extent的状态为XDES_FSEG,写入seg id,并加入到当前segment的FSEG_FREE链表中。
-
返回hint page
-
-
当如下条件时:1. direction != FSP_NO_DIR,对于Btree分裂,要么FSP_UP,要么FSP_DOWN;2.已使用的空间小于已占用空间的7/8; 3.当前segment已经使用了超过32个frag page
-
尝试从segment获取一个Extent(
fseg_alloc_free_extent),如果该segment的FSEG_FREE链表为空,则需要从表空间分配(fsp_alloc_free_extent)一个Extent,并加入到当前segment的FSEG_FREE链表上 -
direction为FSP_DOWN时,**返回该Extent最后一个page**,为FSP_UP时**返回该Extent的第一个Page**
-
-
xdes entry属于当前segment且未被用满,从其中取一个**空闲page并返回**
-
如果该segment占用的page数大于实用的page数,说明该segment还有空闲的page,则依次先看FSEG_NOT_FULL链表上是否有未满的Extent,如果没有,再看FSEG_FREE链表上是否有完全空闲的Extent。从其中取一个**空闲Page并返回**
-
当前已经实用的Page数小于32个page时,则分配独立的page(
fsp_alloc_free_page)并加入到该inode的frag array page数组中,然后**返回该block** -
当上述情况都不满足时,直接分配一个Extent(
fseg_alloc_free_extent),并从**其中取一个page返回**。
上述流程看起来比较复杂,但可以总结为:
1. 对于一个新的segment,总是优先填满32个frag page数组,之后才会为其分配完整的Extent,可以利用碎片页,并避免小表占用太多空间。
2. 尽量获得hint page;
3. 如果segment上未使用的page太多,则尽量利用segment上的page。
上文提到两处从表空间为segment分配数据页,一个是分配单独的数据页,一个是分配整个Extent
表空间单独数据页的分配调用函数fsp_alloc_free_page:
-
如果hint page所在的Extent在链表XDES_FREE_FRAG上,可以直接使用;否则从根据头page的FSP_FREE_FRAG链表查看是否有可用的Extent;
-
未能从上述找到一个可用Extent,直接分配一个Extent,并加入到FSP_FREE_FRAG链表中。
-
从获得的Extent中找到描述为空闲(XDES_FREE_BIT)的page。
-
分配该page (
fsp_alloc_from_free_frag)-
设置page对应的bitmap的XDES_FREE_BIT为false,表示被占用
-
递增头page的FSP_FRAG_N_USED字段
-
如果该Extent被用满了,就将其从FSP_FREE_FRAG移除,并加入到FSP_FULL_FRAG链表中。同时对头Page的FSP_FRAG_N_USED递减1个Extent(FSP_FRAG_N_USED只存储未满的Extent使用的page数量)。
-
对Page内容进行初始化(
fsp_page_create)
-
表空间Extent的分配函数fsp_alloc_free_extent:
-
通常先通过头page看FSP_FREE链表上是否有空闲的Extent,如果没有的话,则将新的Extent(例如上述step 1对文件做扩展产生的新page,从FSP_FREE_LIMIT算起)加入到FSP_FREE链表上(
fsp_fill_free_list):-
一次最多加4个Extent(
FSP_FREE_ADD) -
如果涉及到xdes page,还需要对xdes page进行初始化;
-
如果Extent中存在类似xdes page这样的系统管理页,这个Extent被加入到FSP_FREE_FRAG链表中而不是FSP_FREE链表。
-
取链表上第一个Extent为当前使用。
-
-
将获得的Extent从FSP_FREE移除,并返回对应的xdes entry(
xdes_lst_get_descriptor)
回收Page
数据页的回收分为两种,一种是整个Extent的回收,一种是碎片页的回收。在删除索引页或者drop索引时都会发生。
当某个数据页上的数据被删光时,我们需要从其所在segmeng上删除该page(btr_page_free -->fseg_free_page --> fseg_free_page_low),回收的流程也比较简单:
-
首先如果是该segment的frag array中的page,将对应的slot设置为FIL_NULL, 并返还给表空间(
fsp_free_page):-
page在xdes entry中的状态置为空闲
-
如果page所在Extent处于FSP_FULL_FRAG链表,则转移到FSP_FREE_FRAG中
-
如果Extent中的page完全被释放掉了,则释放该Extent(
fsp_free_extent),将其转移到FSP_FREE链表 -
从函数**返回**
-
-
如果page所处于的Extent当前在该segment的FSEG_FULL链表上,则转移到FSEG_NOT_FULL链表
-
设置Page在xdes entry的bitmap对应的XDES_FREE_BIT为true
-
如果此时该Extent上的page全部被释放了,将其从FSEG_NOT_FULL链表上移除,并加入到表空间的FSP_FREE链表上(而非Segment的FSEG_FREE链表)。
释放Segment
当我们删除索引或者表时,需要删除btree(btr_free_if_exists),先删除除了root节点外的其他部分(btr_free_but_not_root),再删除root节点(btr_free_root)
由于数据操作都需要记录redo,为了避免产生非常大的redo log,leaf segment通过反复调用函数fseg_free_step来释放其占用的数据页:
-
首先找到leaf segment对应的Inode entry(
fseg_inode_try_get) -
然后依次查找inode entry中的FSEG_FULL、或者FSEG_NOT_FULL、或者FSEG_FREE链表,找到一个Extent,注意着里的链表元组所指向的位置实际上是描述该Extent的Xdes Entry所在的位置。因此可以快速定位到对应的Xdes Page及Page内偏移量(
xdes_lst_get_descriptor) -
现在我们可以将这个Extent安全的释放了(
fseg_free_extent,见后文) -
当反复调用fseg_free_step将所有的Extent都释放后,segment还会最多占用32个碎片页,也需要依次释放掉(
fseg_free_page_low) -
最后,当该inode所占用的page全部释放时,释放inode entry:
-
如果该inode所在的inode page中当前被用满,则由于我们即将释放一个slot,需要从FSP_SEG_INODES_FULL转移到FSP_SEG_INODES_FREE(更新第一个page)
-
将该inode entry的SEG_ID清除为0,表示未使用
-
如果该inode page上全部inode entry都释放了,就从FSP_SEG_INODES_FREE移除,并删除该page。
-
non-leaf segment的回收和leaf segment的回收基本类似,但要注意btree的根节点存储在该segment的frag arrary的第一个元组中,该Page暂时不可以释放(fseg_free_step_not_header)
btree的root page在完成上述步骤后再释放,此时才能彻底释放non-leaf segment
索引页
ibd文件中真正构建起用户数据的结构是BTREE,在你创建一个表时,已经基于显式或隐式定义的主键构建了一个btree,其叶子节点上记录了行的全部列数据(加上事务id列及回滚段指针列);如果你在表上创建了二级索引,其叶子节点存储了键值加上聚集索引键值。本小节我们探讨下组成索引的物理存储页结构,这里默认讨论的是非压缩页,我们在下一小节介绍压缩页的内容。
每个btree使用两个Segment来管理数据页,一个管理叶子节点,一个管理非叶子节点,每个segment在inode page中存在一个记录项,在btree的root page中记录了两个segment信息。
当我们需要打开一张表时,需要从ibdata的数据词典表中load元数据信息,其中SYS_INDEXES系统表中记录了表,索引,及索引根页对应的page no(DICT_FLD__SYS_INDEXES__PAGE_NO),进而找到btree根page,就可以对整个用户数据btree进行操作。
索引最基本的页类型为FIL_PAGE_INDEX。可以划分为下面几个部分。
Page Header
首先不管任何类型的数据页都有38个字节来描述头信息(FIL_PAGE_DATA, or PAGE_HEADER),包含如下信息:

Index Header
紧随FIL_PAGE_DATA之后的是索引信息,这部分信息是索引页独有的。

![]()
Segment Info
随后20个字节描述段信息,仅在Btree的root Page中被设置,其他Page都是未使用的。

10个字节的inode信息包括:
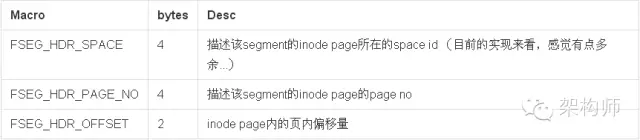
通过上述信息,我们可以找到对应segment在inode page中的描述项,进而可以操作整个segment。
系统记录
之后是两个系统记录,分别用于描述该page上的极小值和极大值,这里存在两种存储方式,分别对应旧的InnoDB文件系统,及新的文件系统(compact page)

Compact的系统记录存储方式为:
两种格式的主要差异在于不同行存储模式下,单个记录的描述信息不同。在实际创建page时,系统记录的值已经初始化好了,对于老的格式(REDUNDANT),对应代码里的infimum_supremum_redundant,对于新的格式(compact),对应infimum_supremum_compact。infimum记录的固定heap no为0,supremum记录的固定Heap no 为1。page上最小的用户记录前节点总是指向infimum,page上最大的记录后节点总是指向supremum记录。
具体参考索引页创建函数:page_create_low
用户记录
在系统记录之后就是真正的用户记录了,heap no 从2(PAGE_HEAP_NO_USER_LOW)开始算起。注意Heap no仅代表物理存储顺序,不代表键值顺序。
根据不同的类型,用户记录可以是非叶子节点的Node指针信息,也可以是只包含有效数据的叶子节点记录。而不同的行格式存储的行记录也不同,例如在早期版本中使用的redundant格式会被现在的compact格式使用更多的字节数来描述记录,例如描述记录的一些列信息,在使用compact格式时,可以改为直接从数据词典获取。因为redundant属于渐渐被抛弃的格式,本文的讨论中我们默认使用Compact格式。在文件rem/rem0rec.cc的头部注释描述了记录的物理结构。
每个记录都存在rec header,描述如下(参阅文件include/rem0rec.ic)

在记录头信息之后的数据视具体情况有所不同:
-
对于聚集索引记录,数据包含了事务id,回滚段指针;
-
对于二级索引记录,数据包含了二级索引键值以及聚集索引键值。如果二级索引键和聚集索引有重合,则只保留一份重合的,例如pk (col1, col2),sec key(col2, col3),在二级索引记录中就只包含(col2, col3, col1);
-
对于非叶子节点页的记录,聚集索引上包含了其子节点的最小记录键值及对应的page no;二级索引上有所不同,除了二级索引键值外,还包含了聚集索引键值,再加上page no三部分构成。
Free space
这里指的是一块完整的未被使用的空间,范围在页内最后一个用户记录和Page directory之间。通常如果空间足够时,直接从这里分配记录空间。当判定空闲空间不足时,会做一次Page内的重整理,以对碎片空间进行合并。
Page directory
为了加快页内的数据查找,会按照记录的顺序,每隔4~8个数量(PAGE_DIR_SLOT_MIN_N_OWNED ~ PAGE_DIR_SLOT_MAX_N_OWNED)的用户记录,就分配一个slot (每个slot占用2个字节,PAGE_DIR_SLOT_SIZE),存储记录的页内偏移量,可以理解为在页内构建的一个很小的索引(sparse index)来辅助二分查找。
Page Directory的slot分配是从Page末尾(倒数第八个字节开始)开始逆序分配的。在查询记录时。先根据page directory 确定记录所在的范围,然后在据此进行线性查询。
增加slot的函数参阅 page_dir_add_slot
页内记录二分查找的函数参阅 page_cur_search_with_match_bytes
FIL Trailer
在每个文件页的末尾保留了8个字节(FIL_PAGE_DATA_END or FIL_PAGE_END_LSN_OLD_CHKSUM),其中4个字节用于存储page checksum,这个值需要和page头部记录的checksum相匹配,否则认为page损坏(buf_page_is_corrupted)
压缩索引页
InnoDB当前存在两种形式的压缩页,一种是Transparent Page Compression,还有一种是传统的压缩方式,下文分别进行阐述。
Transparent Page Compression
这是MySQL5.7新加的一种数据压缩方式,其原理是利用内核Punch hole特性,对于一个16kb的数据页,在写文件之前,除了Page头之外,其他部分进行压缩,压缩后留白的地方使用punch hole进行 “打洞”,在磁盘上表现为不占用空间 (但会产生大量的磁盘碎片)。 这种方式相比传统的压缩方式具有更好的压缩比,实现逻辑也更加简单。
对于这种压缩方式引入了新的类型FIL_PAGE_COMPRESSED,在存储格式上略有不同,主要表现在从FIL_PAGE_FILE_FLUSH_LSN开始的8个字节被用作记录压缩信息:

打洞后的page其实际存储空间需要是磁盘的block size的整数倍。
这里我们不展开阐述,具体参阅我之前写的这篇文章:MySQL · 社区动态 · InnoDB Page Compression
原文:https://yq.aliyun.com/articles/5586