利用Ajax提升网页渲染速度——以Highcharts为例
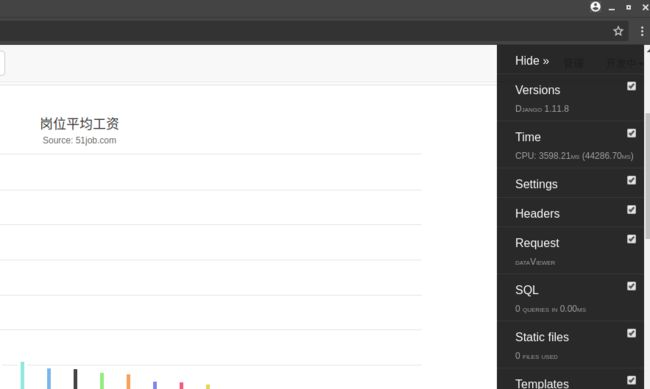
先来看看速度优化对比


AJAX = Asynchronous JavaScript and XML(异步的 JavaScript 和 XML)。
AJAX 不是新的编程语言,而是一种使用现有标准的新方法。
AJAX 最大的优点是在不重新加载整个页面的情况下,可以与服务器交换数据并更新部分网页内容。
AJAX 不需要任何浏览器插件,但需要用户允许JavaScript在浏览器上执行。
在项目一开始时, 为了呈现数据的工资趋势图, 把所有的关键词趋势数据一次性处理后发送至前端, 造成DOM数目过多, 导致网页渲染数据极慢, 到了无法忍受的1分多钟的时间.
后面使用Ajax的get方法, 只对于要下钻的关键词工资趋势获取对应数据, 最终把时间压到了20秒以内(由于整个页面还包含其他图表, 如果只有单个图表, 时间可以进一步缩短)
前端发送请求
下面的代码片就是添加了get方法后的highcharts片段. 这段代码的意思是用get函数发送请求, 请求的内容是{'keyword':String(e.point.name), 'city': '东莞'}, url是/get_trend_by_word/, 这里的url会交由Django后台的路由识别出对应函数进行处理. 处理后的返回数据保存在ret中. 函数体内部把返回的数据ret保存在series中供后面的图表渲染.
$.get('/get_trend_by_word/', {'keyword':String(e.point.name), 'city': '东莞'}, function(ret){
series = ret
});
Django响应请求
在Django的视图模块views.py中, 响应ajax请求, 处理完毕后发送回前端
def get_trend_by_word(request):
...
#把request中的变量值提取出来, 用于处理
keyword = request.GET['keyword']
city = request.GET['city']
...
return JsonResponse(salary_trend, safe=False)
参考资料
关于HighCharts的Ajax例子可以参考官方文档
点击查看
菜鸟教程
点击查看
还在修改中的项目, 欢迎吐槽(逃
https://github.com/FesonX/JobDataViewer
代码对比
下面这段是修改前的js代码片
var drilldown = {
series: [
{% for k, v in series1.items %}
{
type: 'line',
id: '{{ k }}',
name: '{{ k }}',
data: [
{% for i in v %}
{% for j in i %}
{% if forloop.first %} ['{{ j | date:"Y-m-d" }}', {% endif %}
{% if forloop.last %} {{ j }}], {% endif %}
{% endfor %}
{% endfor %}
]
},
{% endfor %}
]};
下面这段是修改后的js代码片
$(function (){
$('#trend').highcharts({
chart: {
type: 'column',
events:{
drillup: function(e) {
// 上钻回调事件
console.log(e.seriesOptions);
},
drilldown: function (e) {
// 重点在这一句
$.get('/get_trend_by_word/', {'keyword':String(e.point.name), 'city': '东莞'}, function(ret){
console.log(ret.Animals)
series = ret
console.log(series)
});
if (!e.seriesOptions) {
var chart = this,
drilldowns = {
type:'line',
},
series = drilldowns;
// Show the loading label
chart.showLoading('正在获取数据...');
setTimeout(function () {
chart.hideLoading();
chart.addSeriesAsDrilldown(e.point, series);
}, 1000);
}
}
}
},
...
});
});
下面这段是修改前的python代码片
def dataViewer(request):
...
# 使用一个循环将所有关键词的工资趋势一次性保存在一个字典里
trends_dict = {kd: get_salary_trend(job_info, kd, city)
for kd in top_keyword if (get_salary_trend(job_info, kd, city).empty) is False}
...
# 把该工资趋势所有数据一次性发送到前端渲染
context = {
'cities': items[:20],
'series': series.sort_values()[::-1][:25],
'keyword_dict': kd_salary,
'top_job_counts':job_count_rank.sort_values()[::-1][:25],
# 按索引排序
'trends_dict': Series(trends_dict).sort_index()[::-1][:25],
'city':city,
}
return render(request, 'data_viewer.html', context)
def get_salary_trend(job_info, keyword, city):
# 获取工资趋势
if(city != '全国' or city != '异地招聘'):
pattern = r'^(' + city + '|' + city + ')'
# items = JobField.objects(__raw__={'key_word':keyword, 'job_city': city})
items = JobField.objects(Q(key_word=keyword) & Q(job_city=city))
else:
# items = JobField.objects(__raw__={'key_word':keyword})
items = JobField.objects(key_word=keyword)
salary_trend_list = []
dates = items.distinct("create_time")
for day in dates:
item = items(__raw__={'create_time': day})
salary_avg = item.average('salary_avg')
salary_trend = [day, round(salary_avg, 2)]
salary_trend_list.append(salary_trend)
salary_trend = dict(salary_trend_list)
salary_trend = Series(salary_trend)
return salary_trend
下面这段是修改后的python代码片
# 根据网页请求的关键词, 把对应关键词的工资趋势数据保存下来, 发送到前端
def get_trend_by_word(request):
# use Ajax to reduce dom
keyword = request.GET['keyword']
city = request.GET['city']
keyword = str(keyword)
city = str(city)
# 获取工资趋势
if(city != '全国' or city != '异地招聘'):
pattern = r'^(' + city + '|' + city + ')'
items = JobField.objects(Q(key_word=keyword) & Q(job_city=city))
else:
items = JobField.objects(key_word=keyword)
salary_trend_list = []
dates = items.distinct("create_time")
for day in dates:
item = items(__raw__={'create_time': day})
salary_avg = item.average('salary_avg')
salary_trend = [str(day)[0:10], round(salary_avg, 2)]
salary_trend_list.append(salary_trend)
salary_trend_list = Series(salary_trend_list).sort_index()[::-1]
salary_trend = {'type': 'line', 'name': keyword, 'data':[i for i in salary_trend_list]}
return JsonResponse(salary_trend, safe=False)
欢迎关注我的腾讯云