Elasticsearch——Query DSL
- 概述
- 查询context与过滤context
- 查询上下文
- 过滤上下文
- 示例
- Match All Query
- Match All Query
- Match None Query
- 全文检索
- Full text queries
- Match Query匹配查询
- match
- Fuzziness
- zero terms query
- cutoff frequency
- match phrase
- Match Phrase Prefix Query
- multi match query
- best_fields
- most_fields
- phrase和phrase_prefix
- corss_fields
- Common Terms Query
- 问题
- 解决方法
- Match Query匹配查询
- 多词匹配
- 多字段搜索
- dis_max分离最大化查询
- dis_breker
- 设定匹配精度
- 如何使用bool匹配How match Uses bool
概述
Elasticsearch提供基于Json的查询功能,将DSL查询看做AST树的话,包含两种子句类型:
+ Leaf query clauses:叶子节点的查询子句,主要用于检索特定字段的特定值,例如match、term、range查询。这些子句可以嵌套自己。
+ Compound query clauses:复合子句,用于组合多个叶子查询子句,形成逻辑,例如bool或者dis_max查询,或者行为修改(例如constant_score查询)
查询子句在query上下文与filter上下文表现有所区别。
查询context与过滤context
查询上下文
查询上下文中的查询子句,用于计算文档与该查询的相似程度,同时计算_score用于衡量相似度。当查询子句放入query中时,此时该查询子句就处于查询上下文中。例如:
{
"query": {
"match" :{
"message": "test"
}
}
}过滤上下文
过滤上下文中的查询子句主要解决“这个文档是否符合这个查询子句”,其结果不是相似度,结果只有“是”或者“否”。过滤想下雨主要用于过滤数据,例如
+ 年龄是否大于18岁
+ 状态是否是正常
大量使用过滤上下文时,过滤查询会被ES自动缓存,加速性能。当查询子句放入“filter”参数中时,会被置于过滤环境中,例如bool查询中的filter或者must_not、constant_score中的filter参数以及聚集中的filter,都是过滤上下文环境。具体过滤如何缓存,会单独介绍。
示例
总结:将影响文档相似度计算的查询,放入query上下文中,将其他的查询放入filter的上下文中。

1. 查询参数,表示查询上下文
2. bool查询,其中两个match查询子句(3和4),位于查询上下文中,用于计算匹配程度
5. 过滤参数,表示过滤上下文
6. 过滤上下文中的term查询,用于过滤数据
7. 过滤上下文中的range擦好像,用于过滤数据
Match All Query
Match All Query
最简单的查询:匹配所有文档,对每个文档打分_score为1.0,相当于关系数据库中的select * from table
curl -XGET 'localhost:9200/_search?pretty' -d'
{
"query": {
"match_all": {}
}
}'如果对于某个查询条件,希望更改其计算_score的权重,可以使用boost参数:
curl -XGET 'localhost:9200/_search?pretty' -d'
{
"query": {
"match_all": { "boost" : 1.2 }
}
}'Match None Query
与全检索相反,可以使用match_none,不匹配任何文档
curl -XGET 'localhost:9200/_search?pretty' -d'
{
"query": {
"match_none": {}
}
}'全文检索
全文搜索两个最重要的方面是:
相关(relevance):相关是将查询到相关的文档结果进行排名的一种能力,这种相关度可以是根据TF/IDF、地理位置相似性(geolocation)、模糊相似,或者其他的一些算法得出。
分析(analysis):将一个文本块转换为唯一的、规范化的token的过程,目的是为了(a)创建反向索引以及(b)查询反向索引。
当我们提到相关与分析的时候,我们已经身处查询上下文之中,而不是过滤。
Full text queries
高层级的全文检索,通常会对文本的整体内容进行分析查询。在检索前会使用每个字段的analyzer对查询字段进行分词。
+ 如果我们用它来查询 时间(date) 或 整数(integer),他们会将查询字符串用分别当作 时间 和 整数。
+ 如果查询一个准确的(未分析过的 not_analyzed)字符串字段,它会将整个查询字符串当成一个术语。
+ 但是如果要查询一个全文字段(分析过的 analyzed),它会讲查询字符串传入到一个合适的分析器,然后生成一个供查询的术语列表。
一旦查询组成了一个术语列表,它会对每个术语逐一执行低层次的查询,然后将结果合并,为每个文档生成一个最终的相关性分数。
注意:
当我们想要准确查询一个未分析过(not_analyzed)的字段之前,需要仔细想想,我们到底是想要一个查询还是一个过滤。
单术语查询通常可以用是非问题表示,所以更适合用过滤来表达,而且这样子可以有效利用过滤的缓存。
下面对全文本查询进行详细介绍:
Match Query匹配查询
match查询接受文本、数值、时间类型的数据,对其进行分析,构建查询。简单示例:
curl -XGET 'localhost:9200/_search?pretty' -d'
{
"query": {
"match" : {
"message" : "this is a test"
}
}
}'
其中message是字段名称,可以根据情况替换。上面的查询会先对this is a test进行分词,对每个term进行匹配并合并结果。
match
match是布尔类型的查询,通过对提供的文本进行analyze,构建一个boolean的查询。
operator:其操作符operator可以设定为and或者or,用于控制查询结构的构建。
minimum_should_match:当存在多个should可选时,可以通过minimum_should_match来设定最少匹配的should条件个数。
analyzer:可以控制文本分析器
lenient:默认为false,当设定为true时,可以忽略类型不匹配导致的异常
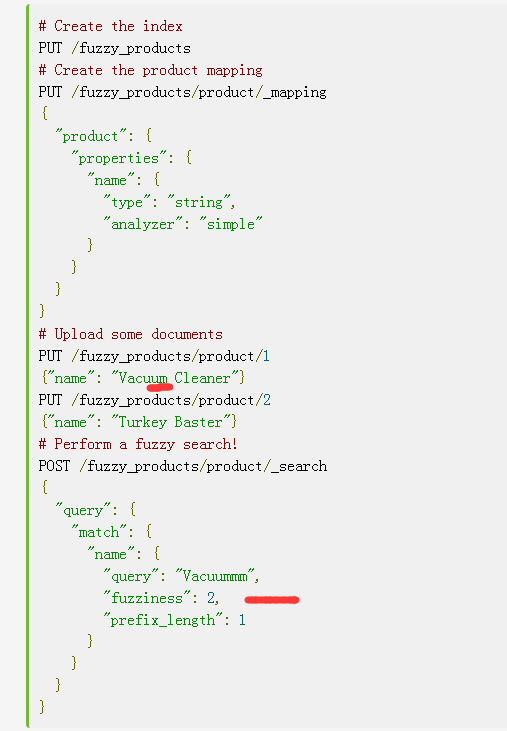
Fuzziness
fuziness可以开启模糊匹配功能。通过设定模糊参数,修改匹配时可以容忍的差距,该值最后在0-2之间,值越大,则计算时间越长。例如下面的例子中,名称多了一个a,通过模糊匹配也能查找出来:
参考:
https://www.elastic.co/blog/found-fuzzy-search
zero terms query
cutoff frequency
指定文档频率
match phrase
短语匹配,通过对查询字符串进行分词,并记录token的位置关系,然后对待查询的字段进行过滤查询分析。
例如:下面例子会查询包含this is a test短语,且顺序与其一致的文档。
curl -XGET 'localhost:9200/_search?pretty' -d'
{
"query": {
"match_phrase" : {
"message" : "this is a test"
}
}
}'
对于查询字符串的分析器,可以手动置顶:
curl -XGET 'localhost:9200/_search?pretty' -d'
{
"query": {
"match_phrase" : {
"message" : {
"query" : "this is a test",
"analyzer" : "my_analyzer"
}
}
}
}'
有时不希望对顺序要求过于严格,可以通过设定slop,指定可以移动查询字符串的token的次数,最终使其顺序一致。如果slop足够大,其检索与忽略顺序一致。例如

文档内容为:quick brown fox
检索字符串为:fox quick
移动步骤:
将quick从pos2移动到pos1
将fox从pos1移动到pos2
将fox从pos2移动到pos3
Match Phrase Prefix Query
与match_phrase类似,但最后一个token作为前缀进行匹配,其最长的匹配长度由max_expansions设定:
curl -XGET 'localhost:9200/_search?pretty' -d'
{
"query": {
"match_phrase_prefix" : {
"message" : {
"query" : "quick brown f",
"max_expansions" : 10
}
}
}
}'
multi match query
允许对多个字段进行同时检索:
curl -XGET 'localhost:9200/_search?pretty' -d'
{
"query": {
"multi_match" : {
"query": "this is a test",
"fields": [ "subject", "message" ]
}
}
}'
可以对各字段分配不同权重,例如下面例子中,subject的权重是message的三倍:
curl -XGET 'localhost:9200/_search?pretty' -d'
{
"query": {
"multi_match" : {
"query" : "this is a test",
"fields" : [ "subject^3", "message" ]
}
}
}'
multi match查询包括以下几种类型:
best_fields
将每个match查询封入dis_max中,这样可以保证精确匹配得分更高
curl -XGET 'localhost:9200/_search?pretty' -d'
{
"query": {
"multi_match" : {
"query": "brown fox",
"type": "best_fields",
"fields": [ "subject", "message" ],
"tie_breaker": 0.3
}
}
}'
与下面等价:
curl -XGET 'localhost:9200/_search?pretty' -d'
{
"query": {
"dis_max": {
"queries": [
{ "match": { "subject": "brown fox" }},
{ "match": { "message": "brown fox" }}
],
"tie_breaker": 0.3
}
}
}'
tie_breaker:只有在use_dis_max参数设为true时才会使用这个参数。它指定低分数项和最高分数项之间的平衡。该参数指定了除了最高得分的子查询外,其他查询得分所占的权重。
most_fields
对每个字段都进行搜索匹配并计算,匹配文档越多,分数越高
curl -XGET 'localhost:9200/_search?pretty' -d'
{
"query": {
"multi_match" : {
"query": "quick brown fox",
"type": "most_fields",
"fields": [ "title", "title.original", "title.shingles" ]
}
}
}'
与下面的一致:
curl -XGET 'localhost:9200/_search?pretty' -d'
{
"query": {
"bool": {
"should": [
{ "match": { "title": "quick brown fox" }},
{ "match": { "title.original": "quick brown fox" }},
{ "match": { "title.shingles": "quick brown fox" }}
]
}
}
}'
将所有match子句的得分相加并除以match的个数
phrase和phrase_prefix
相当于将每个match子句用match_phrase_prefix封装:
curl -XGET 'localhost:9200/_search?pretty' -d'
{
"query": {
"multi_match" : {
"query": "quick brown f",
"type": "phrase_prefix",
"fields": [ "subject", "message" ]
}
}
}'
与下面语句功能一致:
curl -XGET 'localhost:9200/_search?pretty' -d'
{
"query": {
"dis_max": {
"queries": [
{ "match_phrase_prefix": { "subject": "quick brown f" }},
{ "match_phrase_prefix": { "message": "quick brown f" }}
]
}
}
}'
corss_fields
将所有字段作为一个big-fields,进行检索
Common Terms Query
问题
当查询多个字段时,每个token会使用一个term查询,但某些token十分常见,并不应该影响文档的的得分,例如the、a等词,将其作为stopword可以减少term查询个数。但直接移除这些词汇,我们会损失一些精度,比如我们无法区分 happy和not happy。
解决方法:
common terms查询会分两步进行查询
查询重要性高的文档(分布在较少的文档中),并计算score
在第一步查询结果的文档中,查询相关性低的token,并计算socre
可以通过cutoff_frequency控制频率(值大于1为绝对频率,小于1为相对频率)
下面例子中,对频率大于0.1%的token视为common term,
例如下面示例,对低频token使用and操作:
curl -XGET 'localhost:9200/_search?pretty' -d'
{
"query": {
"common": {
"body": {
"query": "nelly the elephant as a cartoon",
"cutoff_frequency": 0.001,
"low_freq_operator": "and"
}
}
}
}'
上面查询近似得等同下面的查询:
curl -XGET 'localhost:9200/_search?pretty' -d'
{
"query": {
"bool": {
"must": [
{ "term": { "body": "nelly"}},
{ "term": { "body": "elephant"}},
{ "term": { "body": "cartoon"}}
],
"should": [
{ "term": { "body": "the"}},
{ "term": { "body": "as"}},
{ "term": { "body": "a"}}
]
}
}
}'
可以分别对高频和低频token进行限制:
curl -XGET 'localhost:9200/_search?pretty' -d'
{
"query": {
"common": {
"body": {
"query": "nelly the elephant not as a cartoon",
"cutoff_frequency": 0.001,
"minimum_should_match": {
"low_freq" : 2,
"high_freq" : 3
}
}
}
}
}'
多词匹配
其中match是一个boolean查询,会对匹配字段进行analyze,操作符默认是or,可以根据情况设定为or或and。例如为了同时匹配三个term,则设定为and:
curl -XGET 'localhost:9200/_search?pretty' -d'
{
"query": {
"match" : {
"message" : "this is a test",
"operator": "and"
}
}
}'
多字段搜索
索引测试的文档:
PUT /my_index/my_type/1
{
"title": "Quick brown rabbits",
"body": "Brown rabbits are commonly seen."
}
PUT /my_index/my_type/2
{
"title": "Keeping pets healthy",
"body": "My quick brown fox eats rabbits on a regular basis."
}
多字段查询:
若多个字段进行查询,默认查询按照下面规则进行排序:
{
"query": {
"bool": {
"should": [
{ "match": { "title": "Brown fox" }},
{ "match": { "body": "Brown fox" }}
]
}
}
}
它会执行 should 语句中的两个查询
将两个查询的分数相加
与总匹配语句的数目相乘
并除以总语句的数目(这里为:2)
普通的多字段查询,文档1两个字段都包含brown,所以两个match都符合,其匹配度高于文档2;
但我们发现文档2对于borwn fox的匹配度更高,如果我们想要提高最佳匹配的文档的匹配度,可以使用dis_max:
dis_max分离最大化查询
{
"query": {
"dis_max": {
"queries": [
{ "match": { "title": "Quick pets" }},
{ "match": { "body": "Quick pets" }}
]
}
}
}
dis_breker
设定匹配精度
curl -XGET 'localhost:9200/_search?pretty' -d'
{
"query": {
"match" : {
"message" : "this is a test",
"minimum_should_match": "75%"
}
}
}'
通常设定最小的匹配百分比,来控制匹配term的个数,例如上面的例子中有三个term,75%会被修正为66.6%,即最少匹配2个term。
但该值可以为负数,负数的意义有些特殊。
例如有4个term的匹配,当匹配度为-25%与75%,其意义是一样的,都是最少匹配三个,但处理5个term时,-25%表示至少匹配四个,而75%表示至少匹配三个term。
如何使用bool匹配(How match Uses bool)
目前为止,可能已经知道如何对多个词进行查询,我们需要做的只是要把多个语句放入bool查询中,因为默认的操作符是 or,每个 term 查询都会被当作 should 语句进行处理,所以至少有一个语句需要匹配,下面的两个查询是等价的:
{
"match": { "title": "brown fox"}
}与
{
"
bool": {
"should": [
{ "term": { "title": "brown" }},
{ "term": { "title": "fox" }}
]
}
}如果使用 and 操作符,那么下面两个语句也是等价的:
{
"
match": {
"title": {
"query": "brown fox",
"operator": "and"
}
}
} 与
{
"
bool": {
"must": [
{ "term": { "title": "brown" }},
{ "term": { "title": "fox" }}
]
}
}如果按照下面这样给定参数 minimum_should_match,那么下面两个查询也是等价的:
{
"
match": {
"title": {
"query": "quick brown fox",
"minimum_should_match": "75%"
}
}
}与
{
"
bool": {
"should": [
{ "term": { "title": "brown" }},
{ "term": { "title": "fox" }},
{ "term": { "title": "quick" }}
],
"minimum_should_match": 2
}
} 当然,我们通常将这些查询以 match 查询来表示,但是如果了解match内部的工作原理,我们就能对查询过程按照我们的需要进行控制,有些时候单个match查询无法满足需求,比如我们要为一些查询条件分配更多的权重。在下一部分中,我们会介绍这个例子。