jdk8 streamAPI 中Collector收集器Collectors.groupingBy分组难点精解
collector
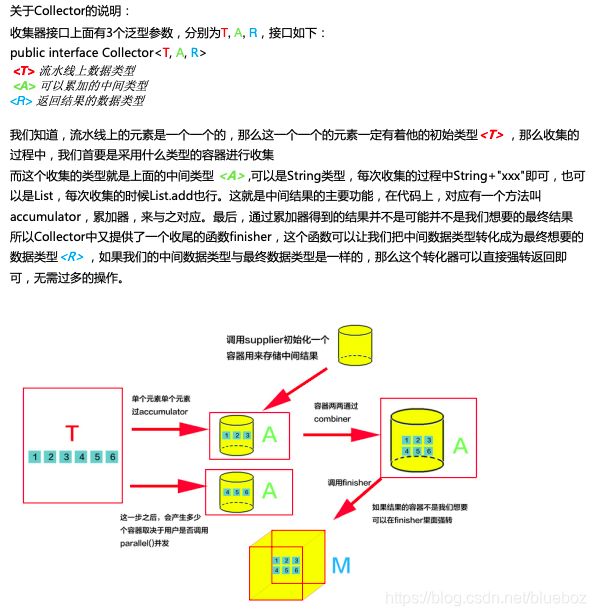
collector的简单场景,一般是在流处理完毕,想要收集对象的收尾工作。代码如下。
List<String> list = Stream.of("kimmy", "robin", "lisa", "lulu", "mike", "jimmy")
.collect(Collectors.toList());
这个收集器主要是把 流水线上的每一个小部件进行收集,并进行装箱。那么这个操作由
大名鼎鼎的Collector来操作。
精解
示例代码
List<String> list = Stream.of("kimmy", "robin", "lisa", "lulu", "mike", "jimmy")
.parallel().collect(new Collector<String, List<String>, List<String>>() {
@Override
public Supplier<List<String>> supplier() {
return ()->new ArrayList<String>();
}
@Override
public BiConsumer<List<String>, String> accumulator() {
return (list,item)->list.add(item);
}
@Override
public BinaryOperator<List<String>> combiner() {
return (list1,list2)->{list1.addAll(list2);return list1;};
}
@Override
public Function<List<String>, List<String>> finisher() {
return (list)->{return list;};
}
@Override
public Set<Characteristics> characteristics() {
return Set.of();
}
});
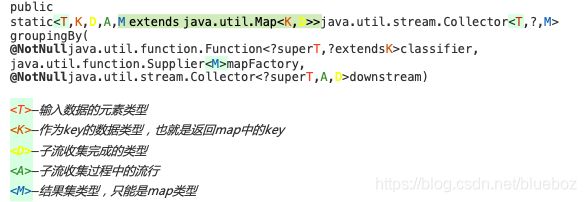
从最简单的层次看这些代码,supplier是容器的提供者,每一次需要临时容器的存储都是需要在这里构造容器的。accumulator是累加器,每一次,我们的流水线的数据将会通过该函数装入到supplier提供的容器,combiner,如果声明了parallel()并发操作,那么数据在一开始会被拆开成为n条流水线,那么每条流水线都会调用一次supplier产生一个临时容器,再通过accumulator装着每一条流水线的数据,最后,才到combiner登场,combiner在不是并发的情况下是无用的。最后是finisher,该函数主要是用做中间容器与最后返回结果集的整合的操作。
最后,你可能会发现笔者漏了一个方法没有讲,characteristics(),这个方法是返回一个Set集合,里面装的是枚举值,这个方法可见是用于收集器的一些其他的配置,首先就最简单的讲,如果返回的是如下,那么finisher函数将不再执行,程序将认为中间对象就是返回的结果对象,这要求泛型
![]()
必须保持一致。否则会发生错误。
@Override
public Set<Characteristics> characteristics() {
return Set.of(Characteristics.IDENTITY_FINISH);
}
另外的2个参数时相互一起配合使用的。官方的解释是accumulator会被并发的调用,但是实际测试还是需要parallel()配合使用,一般配置UNORDERED,使得流水线上的数据以乱序方式处理。
@Override
public Set<Characteristics> characteristics() {
return Set.of(Characteristics.CONCURRENT,Characteristics.UNORDERED);
}
那么返回的结果集当然也是乱序的了。
before:
“kimmy”, “robin”, “lisa”, “lulu”, “mike”, “jimmy”,“kimmy”, “robin”, “lisa”, “lulu”, “mike”, “jimmy”
After;
[robin, lisa, kimmy, robin, lisa, kimmy, jimmy, mike, lulu, jimmy, lulu, mike]
有的同学不知道parallel是什么,在这里我简单的描述一下:就是在stream 的时候,调用一下paralle方法。
Stream.of("kimmy", "robin", "lisa", "lulu", "mike", "jimmy","kimmy", "robin", "lisa", "lulu", "mike", "jimmy")
.parallel().collect(...))
注意
![]()
那么既然int 类型无法使用,就应该使用mapToObj转化成为字符串对象。
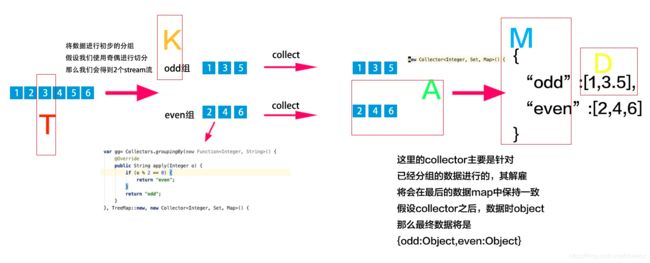
Collectors.groupingBy
假设我们有一个以数字1,10组成的流,需要将该流按照奇数偶数进行分组,那么此时就需要使用groupBy了,groupBy函数一共有2个处理步骤,分别为分组,收集,其中分组操作是不可忽略的,而收集操作是可以忽略的。
Map<String, List<Integer>> collect = IntStream.range(1, 10).mapToObj(it -> Integer.valueOf(it)).collect(Collectors.groupingBy(new Function<Integer, String>() {
@Override
public String apply(Integer integer) {
if (integer % 2 == 0) {
return "even";
} else {
return "odd";
}
}
}));
System.out.println(collect);
//返回的结果
//{even=[2, 4, 6, 8], odd=[1, 3, 5, 7, 9]}
如果希望在子流,即分组流在进行操作。可以在参数2,3进行定制
流程以及接口详细介绍