AQF量化金融分析师学习笔记——上篇完结
part上:思想部分
量化投资策略思想
量化择时
择时策略:期货市场CTA,股票市场看大盘
择时思想:因果系统,封闭系统
择时维度:社会经济指标,企业财务报表,市场波动率换手率,投资者情绪指标
均线模型:股价上穿MA5位后达到SD点位买入,跌破MA5卖出
在MA120以上,MA10上穿MA20做多;在MA120以下,MA10下穿MA20做空
另外还有KDJ,MACD等指标,见之前的操盘笔记博客
HANSI23:开盘一段时间内最高与最低价作上下轨,价格上下突破分别做多和做空,收盘平仓
多项式回归:就是把价格连成多项式,然后求导即可得到最新趋势
盈利回吐:设止盈价位,比买入价位高2.5%则卖出
动量策略:
策略思想:过去收益好的,认为将来收益也会好
看股价:创历史新高/新低,破了均线
对50只恒指成分股,不考虑指数成分变更回顾过去区间收益range(20,90,5)
计算不同的组合收益率sharpe ratio,求最大参数组合
反转策略:
均值回归:过去涨的好的会下跌,过去跌的多的会上涨,价格总围绕某一均值波动
基金结构套利
QDII-LOF基金套利(T+1):香港市场
QDII-LOF基金套利(T+2):跟踪海外市场
依赖长期对数据的追踪,可以提高统计套利精确性
纽交所上市的一个ETF,成分股是香港上市的25只成分股,两个不在同一时间点交易,潜在套利机会
宏观择时
选宏观经济变量(PM1,CPI,M1,M2增速差)
将这些变量作备选自变量,上证综指为因变量,进行逐项回归测试
宏观经济指标体系:
工业与固定资产投资:工业增加值,工业企业营收利润,固定资产投资,发电量
消费与价格指数:CPI,PPI,消费品零售总额,猪肉价格
货币政策与银行:现金投放量,M0M1M2,存贷款余额
利率与利差:债券利率,信用利差,期限利差,理财收益率
景气度:PMI,宏观景气指数,波罗的海指数,消费者信心指数,OECD指标
权益市场:估值PE/PB,股息率,股权风险溢价
海外市场:美债、美元指数,原油,汇率,新增非农就业人数
行业轮动
模式识别:涨跌排名相似性,轮动顺序相似性,决策树
板块联动:行业羊群效应,上下游驱动
截面分析:行业风格极值,大单资金监控
事件驱动:政策事件驱动,宏观事件驱动,行业事件驱动
相对价值策略:
最好的前20%积极做多,最差的后20%积极做空,年化10%
做多PE最低的,做空PE最高的,年化20%
年报公布后股息率高的做多,低的做空
做多低估值公司股票,做空高估值公司的股票
做多低负债/低财务费用公司股票,做空高负债/高财务费用公司股票
做空高商誉公司股票,如商誉/股东权益大于1倍的公司
国内喜欢做多CF,海外倾向股息率高的
可交换债:公开发行的波动率更符合实际,非公开发行波动率偏低
多空alpha策略
市场中性策略:由对冲规避市场风险,构成独立于大盘变动的股票组合
通过多因子模型选股确定多头股票组合,同时用空头股指期货等量对冲多头股票组合
(多头:+alpha+beta,空头:-bata,两者相加=+alpha)
多因子策略
投资因子超2000个,但赚钱的很少,必须储备足够多的因子才能在不同市场上用不同的因子,使得收益率稳定
必须考虑频繁集,频繁出现的策略才是有用的,比如金融危机因子不能用
基本面长期:分析师类,盈利类,估值类,成长类,运营类
技术面短期:盈利类,波动类,残差类,市场类
大类因子相关性矩阵:相关性高的因子之间只需选择一个(他们受同一隐藏因子影响)
有效因子:前20%做多,尾20%做空,两者收益显著
事件驱动型策略
CEO,CFO变更;业绩公布,股东大会召开,派息,拆股,回购,限售股解禁
定增,期权到期,税收优惠,停牌,指数成分股调整策略,大股东增持
商品CTA策略(commodity trading advisor)商品交易顾问
CTA产品:商品期货,金融期货,期权
趋势策略:通过大量指标排除市场噪音,判断当前市场趋势,决定跟踪或反转策略
套利策略:通过对基本面分析或者统计规律寻找不同合约间定价误差,偏离时做多做空,回归时平仓
套利策略类型:期现套利,跨期套利,跨市场套利,跨品种套利
套利策略优势:持仓时间短,设计初衷在接近无风险情况下寻找短时间市场错误定价机会,风险小,最大回撤幅度不大
海龟交易:上线:max(N天最高价);下线:min(N天最低价);中线:上线/2+下线/2
N值计算:(之前20天的N值或ATR+真实波幅)/20
真实波幅TrueRange=Max(High-Low,abs(High-PreClose),abs(PreClose-Low))
资金管理:买卖单位及首次建仓:Unit=1%*账户总资金Account/N
加仓:股价在上一次买入基础上上涨了0.5N,则加仓一个Unit
动态止损:当价格比最后一次买入价格下跌2%时,清仓
统计套利
可转债套利:可转债和国债、企业债一样,也有固定收益和票面利率,其最大区别在于可以转换成股票。股票的涨停板制度限制了资金的做多动能,但是可转债没有这个限制,反应快的股民看到正股涨停,就会去立马买进可转债,或者某只股票突发利好,就可以买进可转债。买的人越多,可转债涨得越多,套利空间也就越大。
AH股价差套利:某家公司在沪深和香港联合交易所皆上市,存在协整
跨期套利:某家公司在沪深和美国皆上市,存在协整,开市时间有差异
无风险套利策略
数据播报频率:上交所5秒/次,深交所3秒/次,股指期货有0.5秒/次,港股/期货实时
期现套利:在到期日股指期货价格和标的指数会收敛
期货无风险套利策略:当两个市场中同一期货比例不一致时,就一个做多一个做空按比例做持有至到期即可
套利风险:交易成本/手续费,冲击成本/保证金追加,等待成本/机会成本,成分股停牌
大数据及舆情分析
识别非机构化数据,微博,twitter上的博文做出投资决策,做情感分析
一致预期:用分析师的建议中,目标价位的中位数,来进行投资
机器学习量化策略
HMM,支持向量机,缺点是非线性关系无法将结果和参数进行联系
高频交易策略
不同交易所播报频率不一致,或者直接打信息传输时间差,例如A下了一笔单在8.7元下吃下100万股,但传过去交易所要1秒,B知道后马上吃下8.6元以下的单,再全部以8.7元放上去给A,每股就赚了0.1元,而B做完获取网络信息分析并吃单下单能在一秒来完成
期权交易策略
合成套利:合成股票多头=认购期权多头+认沽期权空头
part下:编程部分
#首先是自动下载B站视频的代码
import os
# 需要一个支持的工具包,如果没有,就自动安装
retu = os.popen('you-get').read() # 执行you-get命令,获取返回值
if not 'OPTION' in retu:
print('安装支持插件ing,请稍后 . . .')
os.system('pip install you-get') # 安装you-get工具
print('环境已OK!')
else:
print('环境已OK!')
savePath = r'F:\ProjectPython\hello_test2\download' # 根据你的物理环境自行设定,不存在的话会自行创建这么一个文件夹
# 如果savePath不存在,就新建这么一个目录
if not os.path.exists(savePath):
os.makedirs(savePath)
# 循环拼接搞网址,用的是bilibili的,它的网址比较单一化
# https://www.bilibili.com/video/av16378934?p=1
# 上面是它第一个教程的网址,多观察几个就发现,这些网址只有 p=n 只有这个n不同,所有的教程是1-18
downloadPath = r'https://www.bilibili.com/video/BV1ht4y1C7GA?p='
for page in range(1, 87):
url = downloadPath + str(page) # 这有点儿爬虫的意思,拼接url地址
cmd = 'you-get ' + url + ' -o ' + savePath # 拼接you-get命令
os.system(cmd)
'''
#然后是pytorch
LSTM函数的传入参数
1:input_size: 输入特征维数
2:hidden_size: 隐藏层状态的维数,即隐藏层节点的个数
3:num_layers: LSTM 堆叠的层数
4:bias: 隐层状态是否带bias,默认为true
5:batch_first: 输入输出的第一维是否为 batch_size,默认值 False。因为 Torch 中,人们习惯使用Torch中带有的dataset,dataloader向神经网络模型连续输入数据,这里面就有一个 batch_size 的参数,表示一次输入多少个数据。 在 LSTM 模型中,输入数据必须是一批数据,为了区分LSTM中的批量数据和dataloader中的批量数据是否相同意义,LSTM 模型就通过这个参数的设定来区分。 如果是相同意义的,就设置为True,如果不同意义的,设置为False。 torch.LSTM 中 batch_size 维度默认是放在第二维度,故此参数设置可以将 batch_size 放在第一维度。如:input 默认是(4,1,5),中间的 1 是 batch_size,指定batch_first=True后就是(1,4,5)。所以,如果你的输入数据是二维数据的话,就应该将 batch_first 设置为True;
6:dropout: 默认值0。是否在除最后一个 RNN 层外的其他 RNN 层后面加 dropout 层。输入值是 0-1 之间的小数,表示概率。0表示0概率dripout,即不dropout
7:bidirectional: 是否是双向 RNN,默认为:false
'''
#例一:LSTM模型的四种shape
import torch
rnn = torch.nn.LSTM(10, 20, 2)
input = torch.randn(5, 3, 10)
output, (hn, cn) = rnn(input,None)
print(input.shape,output.shape,hn.shape,cn.shape)
#torch.Size([5, 3, 10]) torch.Size([5, 3, 20]) torch.Size([2, 3, 20]) torch.Size([2, 3, 20])
print(input,'\n\n\n',output,'\n\n\n',hn,'\n\n\n',cn)
'''
一、模型参数(10, 20, 2) 输入维度是10,细胞维度与输出维度是20,LSTM层数是2
二、输入矩阵(5, 3, 10)输入数据由3个句子组成,每个句子长度是5个单词,每个单词的表征维度是10(对应上面第一行的10)
三、输出矩阵(5, 3, 20)前两个维度与输入矩阵是相同的,三个句子每句五个单词,最后20是输出维度
四、细胞值隐藏值矩阵(2, 3, 20)LSTM层数是2(对应第一行的2),每次调入3个序列(对应第二行的3),细胞维度与输出维度是20(对应第一行的20)
(注意模型参数中没有定序列长度以及每次扔多少个序列)
'''
#例二:线性回归只操作最后一维数据,前面的维度照搬
import torch
inp=torch.randn(20,60,1)
print(inp.shape)#torch.Size([20, 60, 1])
rnn=torch.nn.LSTM(1,60,1)
hidp,(hn,cn)=rnn(inp,None)
print(hidp.shape)#torch.Size([20, 60, 60])
reg=torch.nn.Linear(60,1)
outp=reg(hidp)
print(outp.shape)#torch.Size([20, 60, 1])
#例三:下标获取时若是单值就会降维
import torch
x=torch.randn(2,3,4)
print(x)
y=x[1:2]
print(y.shape)#torch.Size([1, 3, 4])
z=x[1]
print(z.shape)#torch.Size([3, 4])
print(y)
print(z)
#例四:代价函数的两个参数
import torch
import numpy as np
#loss_fn = torch.nn.MSELoss(reduce=False, size_average=False)#直接返回向量形式的 loss, 无视size_average
#loss_fn = torch.nn.MSELoss(reduce=False, size_average=True) #直接返回向量形式的 loss, 无视size_average
loss_fn = torch.nn.MSELoss(reduce=True, size_average=False) #返回标量,取总和 sum
#loss_fn = torch.nn.MSELoss(reduce=True, size_average=True) #返回标量,取平均 mean
#loss_fn = torch.nn.MSELoss() #默认两个True取平均 mean
#loss_fn = torch.nn.MSELoss(reduce=False) #直接返回向量形式的 loss
#loss_fn = torch.nn.MSELoss(reduction= 'mean') #取标平均 mean
#loss_fn = torch.nn.MSELoss(reduction= 'sum') #取向量总和 sum
#loss_fn = torch.nn.MSELoss(reduction= 'none') #直接返回向量形式的 loss
a = np.array([[1, 2], [3, 4]])
b = np.array([[2, 3], [4, 5]])
input = torch.autograd.Variable(torch.from_numpy(a))
target = torch.autograd.Variable(torch.from_numpy(b))
print(input,'\n', target)
loss = loss_fn(input.float(), target.float())
print(loss)
#接着是基础语法
#第一例
s='abc'
ss=list(s)
ss[0]='d'
print(ss)
s=ss[0]+ss[1]+ss[2]
print(s)
#第二例
import numpy
a=[[1,2,3],[4,5,6]]
b=numpy.array(a)
print(b)
c=b.tolist()
print(c)
#第三例
def even(x):return x%2
print(list(map(even,range(10))))
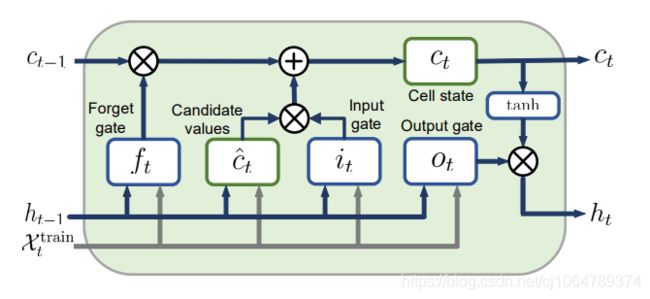
忘记门:H权重乘H+X权重乘X+偏置,再sigmod
细胞门:H权重乘H+X权重乘X+偏置,再tanh
输入门:H权重乘H+X权重乘X+偏置,再sigmod
输出门:H权重乘H+X权重乘X+偏置,再sigmod
细胞值:忘记门输出值乘上一轮细胞值+细胞门输出乘输入门输出值
隐藏值/输出值(若是多层LSTM则作为后面一层LSTM的X输入):细胞值进行tanh后乘输出门输出值