大话 KMP 算法
LeetCode上有一题,简单难度的,以下是原题
 这个题目应该刷LeetCode的同学大部分都刷到过,比较荒谬的是可以直接用 indexOf 方法实现,并且是最优的解法,看到评论以后一片哗然,大家扯到最多的是这道题就应该用KMP来做,如果用KMP做那这道题应该是困难级别的。所以看了这些评论以后,决定自己去摸索一下KMP的算法,以及大概其实现原理。
这个题目应该刷LeetCode的同学大部分都刷到过,比较荒谬的是可以直接用 indexOf 方法实现,并且是最优的解法,看到评论以后一片哗然,大家扯到最多的是这道题就应该用KMP来做,如果用KMP做那这道题应该是困难级别的。所以看了这些评论以后,决定自己去摸索一下KMP的算法,以及大概其实现原理。
网上找了很多关于解释KMP算法的,发现只有阮一峰老师的(字符串匹配的KMP算法)解释的比较通俗易懂,但是缺点是没有给出对应的代码,所以在编程方面还是比较晦涩的。
简单说下KMP算法,我们在找字符串的时候需要找到第一次出现此字符串的地方,没有则返回-1.
下面是KMP算法具体的代码实现 ,这边代码strStr方法是我自己写的,下面的初始化字典是参考的网上的
public class KMP {
public int strStr(String haystack,String needle){
int[] dp = kmpInt(needle);
int M = haystack.length();
int N = needle.length();
// i 表示当前的起始位置,j表示当前 needle的匹配位置, z表示匹配数
int z = 0;
// i的累加交给循环处理
loop:
for (int i=0;i <= M - N;i++){
for (int j=0;j 0 && needle.charAt(k) != needle.charAt(i)){
k = kmp[k-1];
}
if (needle.charAt(k) == needle.charAt(i)){
k++;
}
kmp[i] = k;
}
return kmp;
}
} 在strStr方法中,按照阮一峰老师的博客还是很好理解的, 完全维护了一个字典表,然后根据字典表来进行相对应的位移
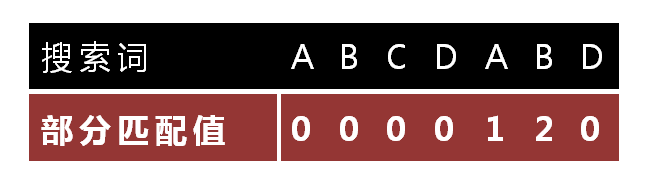
KMP真正难的地方在于怎么样构建上图这个字典树,而字典树里面最难的代码的就是这一段
while (k > 0 && needle.charAt(k) != needle.charAt(i)){
k = kmp[k-1];
}我理解了很久没有理解,然后把代码改成了下图,也同样构建了KMP的字典数组,达到了同样的效果。我来解释下下面这段代码:
while (k > 0 && needle.charAt(k) != needle.charAt(i)){
k--;
}首先,K只是我们维护的一个常数,因为我们要取字典树中的值,因为大小一定要大于0,由于我们的i是累加的,因此我们需要判断第K个字符和第I个字符是否相等,如果不相等的话,并不能直接判断当前的字典树位置对应的就是0,而是要往前找。但是如果第K个字符和第I个字符相等,那么他的最大匹配数一定是k++的。
如果上一个字符串的最大匹配数是0,在当前情况下,如果第一个字符和最后一个字符相等,那么此次的最大匹配数一定为1。
意思就是说如果 ABCDABD,如果ABCD的最大匹配数是0,因为I是5的时候,A=A,所以ABCDA的最大匹配数就一定是1,这个不懂的可以自己画图理解下。
举个栗子看一下,needle的字符串为”aabaaac“。
- 1的默认长度为0;
- "aa"的前缀为[a],后缀为[a],共有元素的长度为1;
- "aab"的前缀为[a,aa],后缀为[ab, b],共有元素的长度0;
- "aaba"的前缀为[a,aa,aab],后缀为[aba, ba, a],共有元素的长度为1;
- "aabaa"的前缀为[a, aa, aab, aaba],后缀为[abaa, baa, aa, a],共有元素为"aa",长度为2;
- "aabaaa"的前缀为[a, aa, aab, aaba, aabaa],后缀为[abaaa, baaa, aaa, aa, a],共有元素为"aa",长度为2;
- "aabaaac"的前缀为[a, aa, aab, aaba, aabaa, aabaaa],后缀为[abaaac, baaac, aaac, aac, ac, c],共有元素的长度为0。
我们是从i=1的时候开始算起,对应的就是aa,因为a == a 并且K初始化为0,所以kmp[1] = k++ = 1;
i = 2的时候,对应的就是aab,此时K是1,因为kmp[1] != kmp[2],所以需要K--,使K的指针前移,直到匹配到有一个字符等于K[i]或者K减到0,所以kmp[2] = 0;
i = 3的时候,对应的就是aaba,此时K是0,因为a == a,K还是等于0,所以kmp[3] = 1;
i = 4的时候,对应的就是aabaa,此时K是1,那么K[1] = a,K[4] = a,因此直接 k++,所以kmp[4] = 2;
i = 5的时候,问题就来了,当前对应的是aabaaa,此时的K是2,kmp[2] = b,而kmp[5] = a,b != a,当前KMP数组维护的指针是2,我们需要进行指针回退,匹配上一个字符是否等于最后一个字符,相当于我们回到了i=4的时候,不同的是,当前K-- = 1,而kmp[k] = a,kmp[i] = a,所以 needle,charAt(1) == needle.charAt(5) ,所以kmp[5] = 2;
i = 6的时候,对应的就是aabaaac,由于K的指针递减,发现没有一个字符可以和最后的最新字符进行匹配,所以kmp[6] = 0;
转化出来的字典数组即为 【0,1,0,1,2,2,0】,当字典转换出来理解以后,KMP的算法就基本理解了。
另外附一下我的代码改和没有改时候在LeetCode的区别
用
while (k > 0 && needle.charAt(k) != needle.charAt(i)){
k = kmp[k-1];
}
的时候: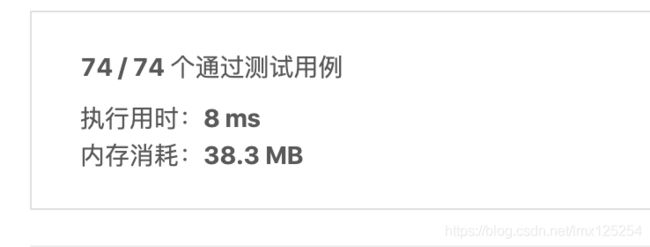
用
while (k > 0 && needle.charAt(k) != needle.charAt(i)){
k--;
}
的时候:
虽然我改版后执行用时增加了,但是我觉得比较方便我理解。。。
果然是头秃的劝退算法。。。摸索了好久才把自己讲通。
本身理解的也不是很深,有问题欢迎探讨。。。