Android性能优化四:卡顿监测方案及原理
文章目录
- 1.卡顿介绍及优化工具的选择
- 1.1背景介绍
- 1.2工具介绍
- 2.自动化卡顿检测方案原理
- 2.1自动化卡顿监测原理
- 2.2具体实现
- 2.3第三方自动检测库AndroidPerformanceMonitor和BlockCanary
- 3.ANR的分析与实战
- 3.1ANR的分类,也就是四大组件的ANR
- 3.2ANR执行流程
- 3.3ANR分析思路
- 4.卡顿单点问题检测方案
- 4.1IPC问题监测指标
- 4.2常规方案
- 4.3IPC问题检测技巧
- 4.4优雅方案
- 5.耗时盲区监控
1.卡顿介绍及优化工具的选择
1.1背景介绍
很多性能问题不易被发现,但是卡顿却很容易被直观感受,另外一方面,对开发者来说,卡顿的问题的排查和定位有一定的难度。因为卡死产生的原因是错综复杂的,比如代码问题,内存环境、绘制过程,IO操作等等情形都有可能导致卡顿,尤其是线上的卡顿问题,受限于用户具体的运行环境,在线下难以复现,所以最好是能记录卡顿产生时的环境。
1.2工具介绍
Profiler介绍
-
图形的形式展示执行的时间、调用栈等信息
-
信息全面、包含所有线程
-
运行时开销严重,应用整体变慢(可能带偏优化方向)
使用方式
- Debug.startMethodTracing();
- Debug.stopMethodTracing();
- 生成文件在sd卡:Android/data/packagename/files
Systrace介绍
结合Android内核的数据,生成Html报告
API18以上使用,推荐TraceCompat向下兼容
使用方式
-
TraceCompat.beginSection(“xxx”);// 手动埋点起始点
-
TraceCompat.endSection();// 手动埋点结束点
-
python systrace.py -b 32768 -t 5 -a packageName -o trace.html sched gfx view wm am app
优势:
-
轻量级,开销小
-
直观反映cpu利用率
-
根据问题给出建议(比如绘制慢或GC频繁)
Systrace具体使用不是本文重点,有兴趣的可参考: Android应用开发性能优化完全分析
StrictMode介绍
严苛模式,Android提供的一种运行时检测机制,可以用来帮助检测代码中一些不规范的问题,项目中有成千上万行代码,如果通过肉眼对代码进行review,这样不但效率低下,而且还容易遗漏问题。使用StrictMode之后,系统会自动检测出来主线程当中一些违例的情况,同时按照配置给出相应的反应。它主要用来检测两大问题,一个是线程策略,另一个是虚拟机策略,StrictMode方便强大,但是容易因为不被熟悉而忽视。
线程策略的检测内容主要包括一下几个方面
-
自定义的耗时调用,detectCustomSlowCalls()
-
磁盘读取写入操作,detectDiskReads
-
网络操作,detectNetwork
虚拟机策略检测内容主要包括以下几个方面
- Activity泄露,detectActivityLeaks()
- 未关闭的Closable对象泄漏,detectLeakedClosableObjects()
- Sqlite对象泄露,detectLeadedSqlLiteObjects
- 检测某个具体实例数量,setClassInstanceLimit()
StrictMode一般用于线下检测,可以在应用的Application、Activity或者其他应用组件的onCreate方法中加入检测代码
if (BuildConfig.DEBUG) {
//线程策略检测
StrictMode.setThreadPolicy(new StrictMode.ThreadPolicy.Builder()
.detectCustomSlowCalls() //API等级11,使用StrictMode.noteSlowCode
.detectDiskReads()
.detectDiskWrites()
.detectNetwork()// or .detectAll() for all detectable problems
.penaltyLog() //在Logcat 中打印违规异常信息
.build());
//虚拟机策略检测
StrictMode.setVmPolicy(new StrictMode.VmPolicy.Builder()
.detectLeakedSqlLiteObjects()
.setClassInstanceLimit(UserBean.class, 1)
.detectLeakedClosableObjects() //API等级11
.penaltyLog()
.build());
}
可以通过配置peanltyLog(),在Logcat 中打印违规异常信息,或者penaltyDialog(),通过Dialog的方式提示违规异常信息。
2.自动化卡顿检测方案原理
前面简单介绍了Profiler、Systrace系统工具,但是系统工具比较适合线下问题针对性分析,但是卡顿问题和实际使用的场景紧密结合,因此线上环境及测试环节需要自动化检测方案,来帮我们定位卡顿,更重要的是记录卡顿发生时的场景。
2.1自动化卡顿监测原理
它的原理基于Android的消息处理机制,一个线程无论有多少个Handler,都只有一个Looper,主线程中执行的任何代码,都会通过Looper.loop()分发执行,而Looper中有一个mLogging对象,它在每个message处理前后都会被调用,如果主线程发生了卡顿,一定是在dispatchMessage中执行了耗时操作,因此可以通过mLogging对dispatchMessage执行的时间进行监控。
public static void loop() {
...
for (;;) {
Message msg = queue.next(); // might block
if (msg == null) {
// No message indicates that the message queue is quitting.
return;
}
// This must be in a local variable, in case a UI event sets the logger
final Printer logging = me.mLogging;
if (logging != null) {
logging.println(">>>>> Dispatching to " + msg.target + " " +
msg.callback + ": " + msg.what);
}
try {
msg.target.dispatchMessage(msg);
if (observer != null) {
observer.messageDispatched(token, msg);
}
dispatchEnd = needEndTime ? SystemClock.uptimeMillis() : 0;
} catch (Exception exception) {
...
throw exception;
} finally {
...
}
...
if (logging != null) {
logging.println("<<<<< Finished to " + msg.target + " " + msg.callback);
}
}
}
2.2具体实现
- Looper.getMainLooper().setMessageLogging();
- 匹配>>>>>Dispatching,指定阈值时间,超过时间后执行任务(获取堆栈信息等)
- 匹配<<<<
2.3第三方自动检测库AndroidPerformanceMonitor和BlockCanary
- 非侵入式的性能监控组件,通知形式弹出卡顿信息
- https://github.com/seiginonakama/BlockCanaryEx
- https://github.com/markzhai/AndroidPerformanceMonitor
使用方式类比LeakCanary。
3.ANR的分析与实战
什么是ANR呢?如果应用程序有一段时间响应不够灵敏,系统会向用户显示一个Dialog对话框,这个对话框称作应用程序无响应(ANR:Application Not Responding)对话框。容易忽视的是这个对话框是由系统服务进程SystemServer的AMS弹出的,而且是在子线程弹出的。
3.1ANR的分类,也就是四大组件的ANR
KeyDispatchTimeout 点击或触摸事件5s内没有响应完成,也可以说是ActivityTimeout
BroadcastTimeout,前台10s,后台60s
ServiceTimeout,前台20s, 后台200s
ContentProviderTimeout
3.2ANR执行流程
- 发生ANR
- 进程接收异常终止信号,开始写入进程ANR信息(线程堆栈信息,CPU等使用情况)
- 弹出ANR提示框,关闭还是继续等待(不同的ROM表现不一,有的手机厂商没有提示框)
3.3ANR分析思路
常规方案:adb pull data/anr/traces.txt 存储路径,即通过adb命令导出anr信息文件,然后根据信息分析是由CPU、IO、锁冲突等哪些原因导致的。
ANR-Watchdog,线上ANR监控方案
- 非侵入式的ANR监控组件
- com.github.anrwatchdog:anrwatchdog:1.3.0
- https://github.com/SalomonBrys/ANR-WatchDog
这个库只有两个类,ANRError和ANRWatchdog。初始化就是通过new ANRWatchdog().start()即可。ANRWatchdog继承Thread,是一个线程类。主要看run方法即可:
public class ANRWatchDog extends Thread {
private volatile int _tick = 0;
//注释1
//更改-tick的值
private final Runnable _ticker = new Runnable() {
@Override public void run() {
_tick = (_tick + 1) % Integer.MAX_VALUE;
}
};
...
@Override
public void run() {
setName("|ANR-WatchDog|");
int lastTick;
int lastIgnored = -1;
while (!isInterrupted()) {
lastTick = _tick;
//注释2
//post更改更改-tick的值的Runnable到主线程执行
_uiHandler.post(_ticker);
try {
//注释3 sleep 一段时间_timeoutInterval= DEFAULT_ANR_TIMEOUT = 5000
Thread.sleep(_timeoutInterval);
}
catch (InterruptedException e) {
_interruptionListener.onInterrupted(e);
return ;
}
// If the main thread has not handled _ticker, it is blocked. ANR.
//注释4
// 如果更改-tick的值没有发生改变,即Runnable _ticker没有执行,表明主线程发生ANR了
if (_tick == lastTick) {
if (!_ignoreDebugger && Debug.isDebuggerConnected()) {
if (_tick != lastIgnored)
Log.w("ANRWatchdog", "An ANR was detected but ignored because the debugger is connected (you can prevent this with setIgnoreDebugger(true))");
lastIgnored = _tick;
continue ;
}
ANRError error;
if (_namePrefix != null)
error = ANRError.New(_namePrefix, _logThreadsWithoutStackTrace);
else
error = ANRError.NewMainOnly();
_anrListener.onAppNotResponding(error);
return;
}
}
}
}
ANR的原理也比较好理解,它主要有以下几个步骤:
ANRWatchdog线程类调用start方法,执行run方法,将注释1处更改-tick的值的Runnable _ticker通过post的方式,交给主线程执行。
然后sleep一段时间,默认是5s, 见注释2
判断tick的值是否发生了改变,即名为_ticker的Runnable是否执行,如果tick的值没有改变,代表Runnable没有执行,也就间接表明发生ANR了
可根据日志中的ANRError信息,进行分析定位
和前面的AndroidPerformanceMonitor的简单对比
AndroidPerformanceMonitor: 监控Message的执行,在执行前后加上时间戳,通过消息的执行之间来判定卡顿问题
ANR-WatchDog:sleep一段时间,看任务是否执行
毕竟每个message执行的时间相对较短,还不到ANR的级别,时间的粒度不同,也对应了卡顿和ANR不同,所以前者比较适合监控卡顿,后者适合ANR监控。
4.卡顿单点问题检测方案
自动化卡顿监测方案并不能够满足所有场景的要求,比如有很多的message要执行,但是每个message的执行时间都不到卡顿的阈值。那么此时自动化监测方案不能检测出卡顿,但此时用户却觉得卡顿。IPC是比较耗时的操作,但是一般没有引起足够的重视,经常在主线程中做IPC操作,以及频繁调用,虽然没有到达卡顿的阈值,但还是会影响体验,监控维度有IPC、IO、DB、View绘制等。下面以IPC举例进行简要说明。
4.1IPC问题监测指标
-
IPC调用类型(如PackageManager和TelephoneManager等)
-
调用耗时、次数
-
调用堆栈、发生线程
4.2常规方案
- IPC调用前后添加埋点
- 侵入性强,不优雅
- 维护成本大
4.3IPC问题检测技巧
通过adb 命令抓取相关信息生成文件,然后进行分析
adb shell am trace-ipc start
adb shell am trace-ipc stop --dump-file /data/local/tmp/ipc-trace.txt
adb pull /data/local /tmp/ipc-trace.txt
4.4优雅方案
提到埋点的优雅方案就难免ARTHook或者AspectJ,他们还是有区别的ARTHook可以Hook系统方法,而AspectJ(AOP方式),它的实现是会在编译成字节码.class文件的时候,在切面点插入添加相关代码,在运行时切面点代码执行时,也会执行添加的相关代码,达到监测的目的。但是它不能针对系统方法做这些操作。
IPC跨进程都是通过Binder调用,大致流程图如下
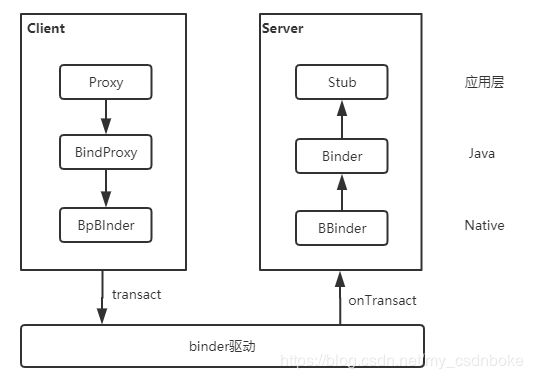
这些IPC如PackageManager和TelephoneManager等都会调用BindProxy,所以只需要Hook这个类的transact方法即可起到监听的效果,注意方法参数要与之相对应。
try {
DexposedBridge.findAndHookMethod(Class.forName("android.os.BinderProxy"), "transact",
int.class, Parcel.class, Parcel.class, int.class, new XC_MethodHook() {
@Override
protected void beforeHookedMethod(MethodHookParam param) throws Throwable {
LogUtils.i( "BinderProxy beforeHookedMethod " + param.thisObject.getClass().getSimpleName()
+ "\n" + Log.getStackTraceString(new Throwable()));
super.beforeHookedMethod(param);
}
});
} catch(ClassNotFoundException e){
e.printStackTrace();
}
5.耗时盲区监控
Activity生命周期间隔,或者onResume到Feed(首页列表第一条)展示的时间间隔,就是耗时监控的盲区,在统计过程容易被忽视。比如在生命周期方法onCreate中postMessage,很可能在Feed显示之前执行,假如这个message执行耗时1秒,那么Feed的展示就要延迟1秒。更多的情况是不知道这段时间主线程具体做了什么事情,一方面是添加代码的人多,另一方面各种第三方的SDK可能在这段时间有postMessage等操作,这是很普遍的,很难通过review代码排查的,再就是线上盲区就更无从排查了。
耗时盲区监控线下方案
TraceView
- 特别适合一段时间内的盲区监控
- 线程具体时间做了什么,一目了然
耗时盲区监控线上方案
思考分析
- 针对mLogging的监控,对主线程Looper来说,所有方法都是Msg,是系统回调的,没有Msg的具体堆栈信息,也就是说不知道Msg是谁抛出来的,只能监测大致的耗时范围,所以这个方案不够完美
- AOP切Handler的sendMessage方法?可以获取是谁(哪个Handler具体post的message),但是不清楚准确的执行时间点,所以想知道onResume到Feed(列表第一条展示),执行了哪些message,以及具体耗时,AOP方案也是不可以的。
具体方案:
- 使用统一的Handler:定制具体方法,因为发送消息,不管四send还是post的方式,最终都会调用sendMessageAtTime方法,而处理消息最终都会调用dispatchMessage方法。
- 定制gradle插件,编译期动态替换,项目中所有使用到的Handler的父类替换成定制的Handler。这样所有sendMessage和dispatchMessage都会经过定制方法的回调。
定制Handler如下:
public class SuperHandler extends Handler {
private long mStartTime = System.currentTimeMillis();
public SuperHandler() {
super(Looper.myLooper(), null);
}
public SuperHandler(Callback callback) {
super(Looper.myLooper(), callback);
}
public SuperHandler(Looper looper, Callback callback) {
super(looper, callback);
}
public SuperHandler(Looper looper) {
super(looper);
}
/**
* 注释1
* 定制的发送消息方法
*/
@Override
public boolean sendMessageAtTime(Message msg, long uptimeMillis) {
// 布尔值表示消息是否发送成功
boolean send = super.sendMessageAtTime(msg, uptimeMillis);
if (send) {// 发送成功
//将message对象和它的调用栈信息保存起来,后续就可以知道这个消息是由谁发送的
GetDetailHandlerHelper.getMsgDetail().put(msg, Log.getStackTraceString(new Throwable()).replace("java.lang.Throwable", ""));
}
return send;
}
/**
* 注释2
* 定制的处理消息方法
*/
@Override
public void dispatchMessage(Message msg) {
//添加开始时间戳
mStartTime = System.currentTimeMillis();
super.dispatchMessage(msg);
if (GetDetailHandlerHelper.getMsgDetail().containsKey(msg)
&& Looper.myLooper() == Looper.getMainLooper()) {
JSONObject jsonObject = new JSONObject();
try {
jsonObject.put("Msg_Cost", System.currentTimeMillis() - mStartTime);
jsonObject.put("MsgTrace", msg.getTarget() + " " + GetDetailHandlerHelper.getMsgDetail().get(msg));
LogUtils.i("MsgDetail " + jsonObject.toString());
GetDetailHandlerHelper.getMsgDetail().remove(msg);
} catch (Exception e) {
}
}
}
}
在注释1处方法,可以把要发送的msg和调用栈信息保存到GetDetailHandlerHelper类中的ConcurrentHashMap集合中,在注释2处方法,即处理消息的时候,先加上时间戳,消息处理完毕,将消息处理的耗时,以及message的调用栈信息打印出来,这样一来,就可以从日志中详细的看到message的耗时情况,以及调用栈信息(在什么地方,由谁发送和执行)了。
public class GetDetailHandlerHelper {
private static ConcurrentHashMap<Message, String> sMsgDetail = new ConcurrentHashMap<>();
public static ConcurrentHashMap<Message, String> getMsgDetail() {
return sMsgDetail;
}
}
监测到卡顿的地方,或者或者耗时较长的方法,就可以针对性的进行的调优了,具体优化可参考启动优化的相关要点,异步、延迟,根据任务的IO型或是CPU型针对性配置线程池等等。