目录
- 一 项目背景和项目分析目标
- 1.1 项目背景
- 1.2 项目分析目标
- 1.3 项目分析思路
- 二 使用方法和相关代码
- 2.1 使用方法
- 2.2 数据结构
- 2.3 相关代码
- 2.3.1 爬取微信公众号(存入MongoDB)
- 2.3.2 拿到的文章链接
- 2.3.3 图形展示
- 三 分析角度
- 3.1 从时间分析:
- 3.2 从关键词分析:
- 3.3 从文章分类分析:
- 3.4 从文章内容分析:
- 3.5 从网站分析:
- 四 对应策略
我们的竞争对手在看向哪里---对勺海公众号的挖掘与细分
一 项目背景和项目分析目标
1.1 项目背景
勺海是一家数据分析公司,现暂时观察到的有北京勺海和深圳勺海两家公司,其中深圳勺海并不从事与三桶油合作的相关项目,侧重点是软硬件,互联网方面. 北京勺海和我公司部分业务冲突,比如神秘顾客行业.我们不得不重视这件事情. 通过细节了解对方公司动向,能够在迷茫中给人一点提示和建议.
1.2 项目分析目标
- 勺海的公众号是瞄向哪个群体的?
- 是否与我们现阶段的业务造成影响?
- 能否确定他们的下一个方向大概是哪里?
- 我们应当如何应对这种威胁?
1.3 项目分析思路
本项目着力于爬取勺海的微信公众号,根据推送时间,文章标题,文章内容,相关网站进行分析,最终提出相关建议.
- 明确分析目的---通过微信公众号这一细节发现勺海的战略目标并提出相关策略建议
- 数据收集---爬取勺海微信公众号的相关内容,数据结构在2.2处标明,使用工具是python的requests,xpath,selenium,pymongo等模块,并且把数据存储到MongoDB中.
- 数据处理---从MongoDB中读取数据并且进行数据清洗,空值和异常值刨除,拿到清洗后的原始数据.
- 数据分析---通过细分分析(不同角度),广义的对比分析(分析网站,不限于同比环比等),进行分析.
- 数据展示---通过pyecharts模块展示生成的数据,并且把相关图片放到报告中.
- 数据报告---生成最终的报告.
二 使用方法和相关代码
2.1 使用方法
代码:
python相关:
requests,selenium,xpath.
数据库:
MongoDB:存储相关信息
其他:
百度AI开放平台的api:用于文章分类.
echarts:展示数据.
2.2 数据结构
{
'_id':'ObjectId',
'title':'xxxx',
'content_url':'文章链接',
'cover':'封面',
'datetime':'xxx',
}2.3 相关代码
2.3.1 爬取微信公众号(存入MongoDB)
# # # 勺海公众号目录
# # m_url = 'https://mp.weixin.qq.com/mp/profile_ext?action=home&__biz=MjM5MTY3MjIxNA==&scene=124'
# 爬取微信公众号并且放到MongoDB里面
# 需要修改的参数
'''
uin
key
Cookie
User-Agent
'''
import requests
import json
import time
from pymongo import MongoClient
url = 'https://mp.weixin.qq.com/mp/profile_ext'
# Mongo配置
conn = MongoClient('127.0.0.1', 27017)
db = conn.wx #连接wx数据库,没有则自动创建
mongo_wx = db.article #使用article集合,没有则自动创建
def get_wx_article(index=0, count=10):
offset = (index + 1) * count
params = {
'action': 'getmsg',
'__biz': 'MjM5MTY3MjIxNA==',
'f': 'json',
'offset': offset,
'count': 10,
'is_ok': 1,
'scene': '',
'uin': 777,
'key': 777,
'pass_ticket': '',
'wxtoken': '',
'appmsg_token': '1021_CJykttHiBi95yOiXF0ng2w0Mnol0sU1X8kAcHQ~~',
'x5': 0
}
headers = {
'Cookie': 'RK=2cQY6O/pSU; ptcz=893bc880c1675d92ad3d1aefd62555c4c372d39b00dd9ddb18f0c8edeacdce2c; pgv_pvid=8386041760; gr_user_id=a69ffd00-b039-4d9d-a148-73e2de181c35; '
'grwng_uid=b94c04db-fb58-4a48-8da3-cdf239fd9ff3; pgv_pvi=6928166912; tvfe_boss_uuid=6cabcbaf997804b3; o_cookie=810395333; pac_uid=1_810395333; '
'eas_sid=w1b5d6X4H259O3T9b012W5U8e1; uin=o0810395333; ptisp=cnc; rewardsn=; wxtokenkey=777; '
'skey=@vATOrb2kn; pgv_info=ssid=s1342811293; wxuin=1830578711; devicetype=Windows7; version=62060833; '
'lang=zh_CN; pass_ticket=A1ooUCr21gSquzom9vu6btcgJbkuAtiIpwdBx/tZ/REG/Yi7JXT5+pAJya2pKXrJ; wap_sid2=CJfU8egGElw5aTlsTjVUT1JKQzZ1WDZVYVZOdUNsMEFvczlZbWpBSWVIU'
'F93RzBHRjRydXlmVFpXOFVKYXBVdFhGSXduSWdoWnRxZVROSFYySno1Mk01OFlMQUpUUDBEQUFBfjCP/MPqBTgNQAE=',
'Host': 'mp.weixin.qq.com',
'Referer': 'https://mp.weixin.qq.com/mp/profile_ext?action=home&__biz=MjM5MTY3MjIxNA==',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3719.400 QQBrowser/10.5.3715.400'
}
response = requests.get(url=url, params=params, headers=headers)
resp_json = response.json()
# print(resp_json)
if resp_json.get('errmsg') == 'ok':
resp_json = response.json()
# 是否还有分页数据, 用于判断return的值
can_msg_continue = resp_json['can_msg_continue']
# 当前分页文章数
msg_count = resp_json['msg_count']
general_msg_list = json.loads(resp_json['general_msg_list'])
list = general_msg_list.get('list')
# print(list, "**************")
for i in list:
app_msg_ext_info = i['app_msg_ext_info']
# 标题
title = app_msg_ext_info['title']
# 摘要(有则执行,没则不要)
digest = app_msg_ext_info['digest']
# 文章地址
content_url = app_msg_ext_info['content_url']
# 封面图
cover = app_msg_ext_info['cover']
# 发布时间
datetime = i['comm_msg_info']['datetime']
datetime = time.strftime("%Y-%m-%d %H:%M:%S", time.localtime(datetime))
mongo_wx.insert({
'title': title,
'content_url': content_url,
'cover': cover,
'datetime': datetime
})
if can_msg_continue == 1:
return True
return False
else:
print('获取文章异常...')
return False
if __name__ == '__main__':
index = 0
while 1:
print(f'开始抓取公众号第{index + 1} 页文章.')
flag = get_wx_article(index=index)
# 防止和谐,暂停8秒
time.sleep(8)
index += 1
if not flag:
print('公众号文章已全部抓取完毕,退出程序.')
break
print(f'..........准备抓取公众号第{index + 1} 页文章.')2.3.2 拿到的文章链接
# 调用百度AI进行文章分类
# import collections # 词频统计库
# import os
# import time
#
# import numpy as np # numpy数据处理库
# import jieba # 结巴分词
# import requests
# import wordcloud # 词云展示库
# from PIL import Image # 图像处理库
# import matplotlib.pyplot as plt # 图像展示库
# from lxml import etree
from aip import AipNlp
from pymongo import MongoClient
""" 你的 APPID AK SK """
APP_ID = 'xxx'
API_KEY = 'xxx'
SECRET_KEY = 'xxx'
client = AipNlp(APP_ID, API_KEY, SECRET_KEY)
# Mongo配置
from selenium import webdriver
conn = MongoClient('127.0.0.1', 27017)
db = conn.wx # 连接wx数据库,没有则自动创建
mongo_article = db.article # 使用article集合,没有则自动创建
FILE_PATH = 'shaohai'
params = {
'__biz': 'MjM5MTY3MjIxNA==',
'amp;mid': '2657778963',
'amp;idx': '1',
'amp;sn': 'f2e5833c1ff036487f966aefa7453ed8',
'amp;chksm': 'bd2f2fea8a58a6fceec8ff03cf44901f560e3bf5d3012e4cb5bcf82ea91f78d0425c0f9195c1',
'amp;scene': '27'
}
get_data = mongo_article.find()
title_ele_list = ['用户', '中国', '数据', '产品''研究', '体验', '消费者', '报告', '消费', '设计']
lst = []
dic = {}
count = 0
for data in get_data:
for title_ele in title_ele_list:
if title_ele in data.get('title'):
count += 1
if count % 25 == 0:
lst.append(dic)
print(dic)
dic = {}
son_url = data.get('content_url')
# print(son_url)
# 经过半天尝试,发现微信反爬机制非常顽强,似乎是认证电脑的,总之,我因为no session没办法继续爬取文章了
title = data.get('title')
content = title * 5
""" 调用文章分类 """
item = client.topic(title, content).get('item')
if item:
kinds = item['lv1_tag_list'][0].get('tag')
if dic.get(kinds):
dic[kinds] += 1
else:
dic[kinds] = 1
break
print(lst)
# {'科技': 176, '社会': 46, '娱乐': 7, '时尚': 26, '健康养生': 14, '时事': 20, '文化': 5, '体育': 41, '家居': 33,'教育': 7 , '财经': 28, '汽车': 13, '历史': 12, '情感': 7, '军事': 7}
# headers = {
# 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3',
# 'Accept-Encoding': 'gzip, deflate, br',
# 'Accept-Language': 'zh-CN,zh;q=0.9',
# 'Cache-Control': 'no-cache',
# 'Connection': 'keep-alive',
# 'Cookie': 'pgv_pvi=9564880896; RK=BdQY6O/pTW; ptcz=a81334855602b86ab4e3f674e6a21eb72fad39108bff3d025746b03038993e79; rewardsn=; wxtokenkey=777',
# 'Host': 'mp.weixin.qq.com',
# 'Pragma': 'no-cache',
# 'Sec-Fetch-Mode': 'navigate',
# 'Sec-Fetch-Site': 'none',
# 'Sec-Fetch-User': '?1',
# 'Upgrade-Insecure-Requests': '1',
# 'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.87 Safari/537.36'
# }
# text = requests.post(url=son_url, headers=headers, params=params).json()
# print(text)
# break
# bro = webdriver.Chrome(executable_path='chromedriver.exe')
# bro.get(son_url)
# tree = etree.HTML(bro.page_source)
# print(bro.page_source)
# title = tree.xpath('//*[@id="activity-name"]/text()')[0].replace(' ','').strip('\n').replace('|',':')
# print(title,str(title))
# file_path = os.path.join(FILE_PATH, title)+'.txt'
# print(file_path)
# 写名字的时候不要用管道符
# with open(file_path,'w',encoding='utf8') as f:
# f.write(title+'\n')
# digest = tree.xpath('//*[@id="js_content"]/section[4]/section/section/section[1]/section/section/p/text()')
# if digest == []:
# digest = tree.xpath('//*[@id="js_content"]/section/section[4]/section/section/section[1]/section/section/p/text()')
# f.write(digest[0])
# section_list = tree.xpath('//*[@id="js_content"]/section[5]/section/section/section')
#
# for section in section_list:
# content = section.xpath('.//span/text()')
# if content:
# for i in content:
# print(i)
# f.write(i)
# # print(content)
#
# time.sleep(3)
# bro.close()
# # print(text)
# break
# 总共有500多篇
# http://mp.weixin.qq.com/s?__biz=MjM5MTY3MjIxNA==&mid=2657779153&idx=1&sn=f48669ede69430c941ce4654e9efe9b0&chksm=bd2f2f288a58a63e5694f795e8a2f57cf9f0d2e193c4d2866e4cc05c8db3673ab89e668feab2&scene=27#wechat_redirect
# http://mp.weixin.qq.com/s?__biz=MjM5MTY3MjIxNA==&mid=2657779140&idx=1&sn=b41c63d20f256991beca880fe84e0d15&chksm=bd2f2f3d8a58a62b9010eefdc9ee552407efe341e1798c60f323c49cc857d5eac3075ae21254&scene=27#wechat_redirect
# http://mp.weixin.qq.com/s?__biz=MjM5MTY3MjIxNA==&mid=2657779123&idx=1&sn=f1920b6c267ac65a2a357576d3145fff&chksm=bd2f2f4a8a58a65c7e59f1ece9dbd31b3d66a81003e875df841a5e8a19ae0addff85fb55aba3&scene=27#wechat_redirect
# http://mp.weixin.qq.com/s?__biz=MjM5MTY3MjIxNA==&mid=2657779107&idx=1&sn=00c951e2d95d10e75c6647c444515420&chksm=bd2f2f5a8a58a64cb58ffb5d22ec920101fd07e5edd5720d09ad5fad8a114aa384c9b27fa51b&scene=27#wechat_redirect由于500多篇链接过多,只放几个.
2.3.3 图形展示
柱状图
# {'科技': 176, '社会': 46, '娱乐': 7, '时尚': 26, '健康养生': 14, '时事': 20, '文化': 5, '体育': 41, '家居': 33,'教育': 7 , '财经': 28, '汽车': 13, '历史': 12, '情感': 7, '军事': 7}
from pyecharts import Bar
# from pyecharts import Scatter
columns = ['科技', '社会', '娱乐', '时尚', '健康养生', '时事', '文化', '体育', '家居','教育', '财经', '汽车', '历史', '情感', '军事']
count = [176,46,7,26,14,20,5,41,33,7,28,13,12,7,7]
bar = Bar('柱状图','文章分类')
bar.add('文章数量',columns,count,mark_line=["average"],mark_point=["max","min"])
bar.render()
# columns = ["Jan", "Feb", "har", "Apr", "may", "Jun", "Jul", "Aug", "sep", "oct", "Nov", "Dec"]
# data1 = [2.0, 4.9, 7.0, 23.2, 25.6, 76.7, 135.6, 162.2, 32.6, 20.8, 6.4, 3.3]
# bar = Bar("柱状图", "一年的降水量与蒸发量")
# bar.add("降水量", columns, data1, mark_line = ["average"], mark_point = ["max", "min"])
# bar.render()散点图(更新了pyecharts的版本导致操作有所不同)
from pymongo import MongoClient
conn = MongoClient('127.0.0.1', 27017)
db = conn.wx # 连接wx数据库,没有则自动创建
mongo_article = db.article # 使用article集合,没有则自动创建
date_list = []
time_list = []
for data in mongo_article.find():
datetime = data['datetime'].split(' ')
date_list.append(datetime[0])
print(datetime[1], type(datetime[1]))
# 由于字符串的大小无法体现在y轴上,此处取比率.
h, m, s = datetime[1].split(':')
ratio = (int(h) * 3600 + int(m) * 60 + int(s)) / (24 * 3600)
time_list.append(ratio)
date_list = date_list[::-1]
time_list = time_list[::-1]
print(date_list)
print(time_list)
# 折线图
# from pyecharts import Line
#
#
# line = Line("折线图","文章发布时间")
# # //is_label_show是设置上方数据是否显示
# line.add("文章发布时间", [str(i) for i in date_list],time_list, is_label_show=True)
# line.render()
from pyecharts import options as opts
from pyecharts.charts import Scatter
def scatter_base() -> Scatter:
c = (
Scatter()
.add_xaxis([str(i) for i in date_list])
.add_yaxis("文章发布时间", time_list)
.set_global_opts(title_opts=opts.TitleOpts(title="Scatter-文章发布日期与时间"))
)
return c
scatter_base().render()三 分析角度
3.1 从时间分析:
日期和时间的关系基本如下: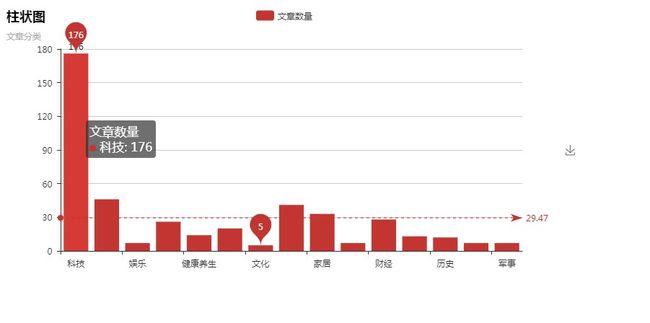
该公众号大概2013年底开始运营,前期文章发放时间并不明确,且经常在晚上发放文章,在一个大范围分布,但是到了2015年左右主键重视公众号运营,发放文章的时间多为12点(0.5左右)和6点到7点左右(0.7到0.8之间). 并且时间趋于固定,而且2013年和2015年时间间隔较大,因此前期的数据仅起参考作用. 后期稳定的原因很可能是确定了公众号的发展方向,且把公众号运营提上线程,这时候的数据对于分析对方公司的战略会有一定的帮助.
3.2 从关键词分析:
下图是通过对勺海的1500篇左右的微信公众号的抓取得出的一幅词云
其中,该企业热衷于写关于用户,体验,消费者的文章,说明企业更愿意从客户的角度出发,考虑更多事情.
另外一些标签是中国,企业,时代,新趋势这样的字眼,说明这个公众号更愿意站在更高的平台上.
还有一些则是产品,研究,数据,经济,营销,分析等. 这里似乎是为了标榜自己是一家数据驱动的企业,这是比较值得肯定的.
除了上面的一些标签,很难看到跑题的,基本都是围绕提升企业效益的主题进行的,或者就是未来的前景,而勺海现在更多是基于过去和现在的数据为客户提供复盘和总结,且考虑到企业不可能全盘把自己的发展方向放手给第三方企业,那么是不是可以认为勺海的战略重心会逐渐移向战略咨询企业转移呢? 这对于我司来说是有一定影响的. 我公司的实力不如勺海,如果它选择放弃了较为吃力的神秘顾客行业,进军战略咨询,那么我们是应当选择继续坚持当下的情况还是也随之转进?
3.3 从文章分类分析:
我们得到了下列数据:
{'科技': 176, '社会': 46, '娱乐': 7, '时尚': 26, '健康养生': 14, '时事': 20, '文化': 5, '体育': 41, '家居':
33,'教育': 7 , '财经': 28, '汽车': 13, '历史': 12, '情感': 7, '军事': 7}
.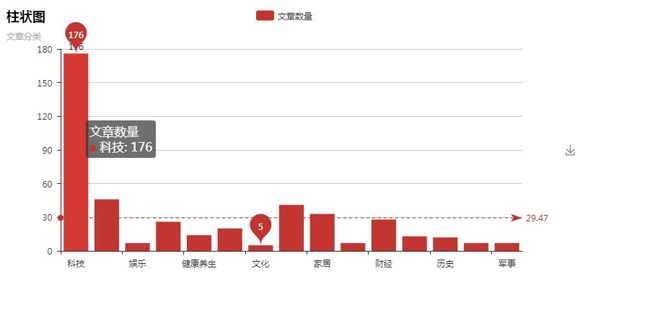
明显,该公司侧重科技方面. 公众号整体给人的感觉也是如此,基本符合数据驱动企业的定义.
很有可能该公众号的主体就会围绕着科技进行文章发放.
然而,尽管该公众号以科技为主体,但是值得深思的是,为什么现在风头正盛的5G和AI的文章却这么少?5G一篇没有,AI的话只有3篇. 是勺海在囤积力量准备一举爆发?还是勺海自身没有这方面的实力呢?
可能是该公司行为谨慎,不愿意借助自己不熟悉的一些东西.但这未尝不是其他公司的契机. 现在的人工智能相关技术一般都掌握在大厂手里,我们完全可以调用他们的api进行使用. 能够应用在神秘顾客项目中的恐怕也就是人脸识别,语音识别和词性分析了,现在的识别率达不到那么高,但至少能辅助工作,这都是后话了,在建议那里会详细说明的.
3.4 从文章内容分析:
符合我们关键字的有将近500篇,我们对其抽样仔细研究.
我们选取下列文章进行研究:
- 为什么你的用户洞察会失灵?---讲述了AARRR分析方法,普及知识型.
- 迪士尼乐园的游客数据挖掘 | 利润丰厚,风平浪静---生活小故事.
- 4个用户召回策略与案例,教你如何挽回流失用户(含RFM分析)---干货型
- 读懂用户,从移情图开始---干货型
- 消费者研究报告 | 10后小孩已开始影响家庭旅行决策---普及知识型.
这里面不乏其他一些好的文章,我仅是抽取了上述5篇文章.
从这里完全可以看出这家公司的野望,先通过普及知识类型的,可以吸引一批对数据分析感兴趣的大学生和初入数据分析行业的菜鸟,达到吸引潜在生力军的目的;然后;最后通过一些有意思的小故事和经济管理案例,维持粉丝.
同样是有神秘顾客业务的,勺海不会在每一篇文章下面都贴一个招集神秘顾客的二维码,这似乎显示出了一个细节:勺海不是特别在意神秘顾客这块业务,或者说他们的常备力量已经足够应对业务需求了.
如果是前者,对于其他神秘顾客相关行业的公司来说是利好消息,这很可能意味着勺海业务的变化;后者的话也至少意味着勺海暂时不会扩大业务.
3.5 从网站分析:
为什么要提网站呢?因为网站上展示的文章基本都来源于微信公众号.
网站作为一个企业的脸面,是企业面向客户的第一个交流点,上面基本上都放置的是微信公众号的内容,这是否意味着微信公众号的思路其实也就是网站的思想?也就是想要展示给客户的呢?
勺海身为一家专业的数据分析公司,单从公司网站看,其志不小. 和普通的网站相比(包括我公司),勺海试图成为一家数据应用平台.
勺海的官网可以分为三部分:
- 第一部分是head_title,分别是勺海的logo,勺海的介绍,项目解决方案案例和联系方式. 勺海的介绍主要是针对想要了解勺海的客户和潜在的员工. 项目解决方案更多的是说一个勺海执行方案的流程,让客户大体心里有数.
- 第二部分可以算是一个置顶标题栏. 其中左侧是解决方案,也就是跳到第一部分那个解决方案那里,右侧一般是微信公众号的置顶文章.
- 第三部分是其他文章.左侧是关于数据类的热门文章,右侧是勺海自创或者转载其他人的文章,并不是闭门造车.其他文章分为勺海观点,研究方法,大数据,消费者洞察,营销与零售,铲平创新和行业趋势.
仔细研究一番勺海的官网,发现网站和微信公众号的思想几乎保持一致,那就是:
把勺海打造成一个数据分析爱好者,数据分析师和客户,同行都能用上的一个数据平台.
这是很恐怖的,这意味着勺海已经脱离了一家公司的视界,而是妄图定义整个行业.幸好不是每一家企业都叫麦肯锡,勺海作为一家国内企业,还没成长到行业的天花板.
而且对于勺海来说,网站做的有一些弊端:
自己合作过的企业,真实案例没有进行过展示. 也就是说,勺海强化了自己作为一个平台的概念,弱化了作为一家企业的概念,这从某种角度来说也算是一件好事吧.
四 对应策略
根据上述分析,我们基本可以得出以下结论:
- 勺海现在不以神秘顾客业务为核心,现在对于勺海来说,神秘顾客业务应该属于现金牛,而且是一只日益衰弱的现金牛,下一步可能会落位瘦狗区域从而进行清算,或者维持.
- 勺海想要把公司打造为数据展示和应用平台,并且在致力于如此. 也就是说,勺海可能想做数据界的"IBM",但实际上,限于IT巨头们和传统工业对数据的有力把持,勺海最多可以做出一个曾经做过领域的"数据分析服务平台".
- 勺海没有借助AI"造势"的打算.尽管借助所谓的"大数据"造势(实际上大数据一般来说都是TB乃至PB级别的),但勺海的微信公众号和官网上都很少放出关于AI的消息,更不用说利用它造势了.
对应策略:
- 明确我司发展方向,是以业务为核心进而打通相关业务,还是也准备打造成一个"数据分析平台". 如果是前者,对于抢夺业务方面我们能相对以前稍微好些. 但考虑到神秘顾客的招聘情况,培训情况和执行形势,恐怕是不容乐观,我们必须要做好艰苦奋战地准备,这个时候,人是最重要的,不管未来切换到什么业务,充分的人手是执行业务必不可失的."存人失地,人地皆得". 如果是后者,我们要做好和勺海硬碰硬的打算,勺海的市场调研业务相比我司而言规模巨大,而且深圳的公司主要是为了做平台而建立的,这是一个巨大的挑战.
- 对于大数据和AI领域,我司要研究一番. 为了业务来往方便,说起来也比较高大上.现在可应用的百度AI开放平台的api接口有语音识别(可应用于神秘顾客采集的声音转换),图像识别(可用于车流量获取),人脸识别(用于神秘顾客采集声音的对应人物),自然语言处理(可用于语音识别转化而来的文本分析). 由于百度AI开放平台是免费的,可以用作测试上.而且也并不是非要使用不可,而是为了"造势",声称我们现在可用这项技术而已.至于具体怎么执行还是要看具体情况的,实际上能够把AI技术应用于实际的恐怕也只有几家巨头了,很多都是跟风,实际应用到底如何还有待商榷.