小白的大数据入门路——Hive学习笔记
文章目录
- 一、Hive基本概念
- 1.1、什么是Hive
- 1.2、Hive的优缺点
- 1.3、Hive架构原理
- 1.4、Hive对比数据库
- 二、Hive安装
- 2.1、安装包准备
- 2.2、相关配置和启动
- 2.3、本地文件导入Hive
- 2.3.1、Linux本地文件导入
- 2.3.2、HDFS文件导入
- 2.4、安装MySQL
- 2.5、Hive的JDBC访问(了解)
- 2.6、Hive常用交互命令
- 2.7、Hive常见属性配置
- 2.7.1、常用配置参数
- 2.7.2、修改配置的方式
- 三、Hive数据类型
- 3.1、基本数据类型
- 3.2、集合数据类型
- 3.3、数据类型转换
- 3.4、集合数据类型实操
- 四、DDL数据定义
- 4.1、数据库相关操作
- 4.2、表相关操作
- 4.2.1、创建表
- 4.2.2、管理表(内部表)和外部表
- 4.2.3、分区表
- 4.2.3.a、分区表操作
- 4.2.5、修改表
- 五、DML数据操作
- 5.1、数据导入
- 5.1.1、使用Load向表中装载数据
- 5.1.2、使用 Insert手动插入数据
- 5.1.3、As Select创建表并直接加载数据
- 5.1.4、建表使用Location直接加载数据
- 5.1.5、使用Import导入数据
- 5.2、数据导出
- 5.2.1、Insert导出
- 5.2.2、非常规数据导出
- 5.2.3、使用Export数据导出,使用Import数据导入(了解)
- 5.3、清空表数据(Truncate)
- 六、查询
- 6.1、基本查询
- 6.2、Where语句
- 6.3、分组(GroupBy)
- 6.4、连接Join
- 6.5、排序
- 6.5.1、全局排序Order By
- 6.5.2、区内排序Sort By
- 6.5.3、数据分区Distribute By
- 6.5.4、ClusterBy
- 6.6、分桶及抽样查询
- 6.6.1、分桶表及数据存储
- 6.6.2、分桶的抽样查询
- 6.7、其他查询常用函数
- 空字段赋值
- 时间类
- case when then&if
- 行转列(拼接多列数据)
- 列转行(单列数据拆分)
- 窗口函数
- 1、了解和认识窗口函数over()
- 2、了解over()函数参数选择
- 3、over()外常用函数
- 4、排行Rank
- 七、函数
- 7.1、系统内置函数
- 7.2、自定义函数
- 7.2.1、自定义UDF函数具体步骤
- 7.2.2、自定义UDF
- 7.2.3、自定义UDTF函数具体步骤
- 7.2.4、自定义UDTF函数
- 八、压缩和存储
- 8.1、数据压缩
- 8.2、文件存储
- 8.2.1、行存储和列存储
- 8.2.2、存储数据格式
- 九、调优
- 9.1、Fetch抓取
- 9.2、本地模式
- 9.3、表的优化
- 9.3.1、大小表Join
- 9.3.2、大表Join
- 9.3.3、MapJoin
- 9.3.4、Group By
- 9.3.5、去重统计Count(distinct())
- 9.3.6、笛卡尔积
- 9.3.7、行过滤,列过滤
- 9.3.8、动态分区
- 9.4、MR优化
- 9.5、其他调优
- 9.4、MR优化
- 9.5、其他调优
一、Hive基本概念
1.1、什么是Hive
Hive:最早由Facebook开源用于解决海量结构化日志的数据统计
Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射成为一张表,并提供类SQL的查询功能
本质:就是将HQL(Hive Query Language)转化为MapReduce程序
简单原理图:

其实整个过程还是要依托Hadoop的组件来完成的。比如MapReduce的运行需要Yarn来进行资源调度管理,计算的数据和结果还是存放在HDFS上,所以现在就很好理解为什么说Hive是Hadoop的数据仓库工具了。
总结:
- Hive的处理数据是存放在HDFS上的
- Hive分析数据底层的默认实现是MapReduce(可以修改)
- 执行程序(底层是MapReduce)是运行在Yarn上的
1.2、Hive的优缺点
优点
- 操作接口采用类SQL的语法,简单容易上手
- 避免了写MapReduce程序,降低了学习成本
- Hive由于采用MR进行数据分析计算,所以执行延迟较高,适用于对实时性要求不高的场景
- Hive善于处理大数据,不适合处理小文件,其实是MR的优势和不足
- Hive支持用户自定义函数,用户可以根据自己的业务需要来定制自己的函数
缺点
- Hive的HQL表达能力有限,主要表现在:
- 对于迭代式算法无法表达(迭代式算法:对计算结果进行迭代处理)
- 数据挖掘方面不擅长(数据挖掘本质就是通过使用迭代式算法)
- Hive的效率较低
- Hive自动生成的MapReduce程序,通常情况下不够智能化(自动生成的没有全手写的来得智能)
- Hive的调优比较困难,粒度较粗(因为是使用MapReduce模板,所以即时调优也不能精确到MapReduce的方法中)
1.3、Hive架构原理
简易架构图

先不看HDFS和MapReduce。整个Hive组成核心就是解析器、编译器、优化器、执行器以及元数据存储
- CLI、JDBC、Driver都是Hive对外开放的用户操作接口
- 元数据MateData:存放Hive通过映射HDFS中文件生成表的一些数据,包括表名、所属数据库、字段属性、字段名以及表数据的路径等。默认存储在自带的derby数据库中,但是推荐使用MySQL进行存储元数据
- 解析器:主要是检查SQL的语法以及数据合法性的检查
- 编译器:将解析通过的SQL,结合MapReduce的模板翻译成对应的MapReduce程序。
- 优化器:对要执行的程序进行简单的优化处理
- 执行器:提交执行MR
1.4、Hive对比数据库
由于Hive采用的类SQL查询语言,以及表、数据类型、数据库等都和数据库比较相似,所以很容易误以为Hive也是一款数据库软件,其实Hive只是针对Hadoop的一个数据仓库的工具,和数据库相比区别还是比较大的。
查询语言
Hive:HQL(Hive Query Language),MySQL:SQL(Structured Query Language)两者虽然语法大致相同,但是前者针对大数据环境,还提供了一些特殊的功能语法。
数据的存储位置
Hive是建立在Hadoop之上的,所以Hive的数据都是存放在HDFS上的。而数据库则是将数据存放在块设备或者本地文件系统中。
数据更新
Hive是针对数据仓库设计的,而数据仓库中的内容都是多读少写的,所以Hive对数据的操作基本都是查询,不建议对已有的数据进行改写,而数据库则是面向与用户交互对数据进行存放的,所以数据库对数据的更新就包括增删改查。
索引
MySQL中使用数据存储引擎InnoDB是支持索引的,在数据库中建立索引主要是优化SQL的查询速度。而Hive中是不支持创建索引的,即时有索引在海量数据的场景下优化的幅度也不明显。
执行
Hive的本质是将HQL转化为MR程序运行,而数据库一般都有自己的执行引擎。
执行延时
由于Hive是采用MR进行数据分析计算,所以MR慢的特性就提高了Hive的执行延时。而SQL的执行效率相比较来说在数据量瓶颈之前要快得多。
可扩展性
得益于Hadoop的优良扩展性,Hive的扩展性也相应提升,而反观数据库扩展性却不那么理想。
数据规模
Hive能处理的数据都是大规模的数据,而数据库的性能瓶颈的原因2000万条数据是单台数据库所能接收的最大数据量。
二、Hive安装
Hive官网、官方文档、中文手册、下载地址
2.1、安装包准备
-
Hive 1.2.x(可以尝试新版本2.3.x)
-
MySQL的相关安装文件

-
到虚拟机上解压Hive:(初始目录结构)
2.2、相关配置和启动
-
首先确保Hadoop的环境配置没有问题
-
hive的conf目录中
hive-env.sh.template文件修改export HADOOP_HOME=/opt/module/hadoop-2.7.7 export HIVE_CONF_DIR=/opt/module/hive-2.3.7/conf -
启动Hadoop(NN、DN、RM、NM)
-
使用
bin/hive启动hive即可
启动后目录中多了
derby.log、metastore_db文件,是和元数据存储相关的文件。 -
执行一些简单命令:
show databases;
create table xxx(xx)创建一张表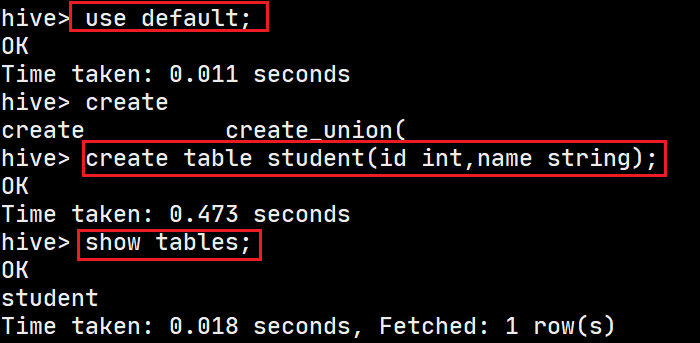
insert插入数据
我们做一次数据插入,他居然启动了一个MapReduce Job!!
并且还在HDFS中创建了一些文件目录:
/user/hive/warehouse/000000_0,下载这个文件查看,里面放着就是我们插入的数据

select查询数据
count(*)统计数据数
只要是设计数据的变动和计算的都会启动MapReduce进行处理。
2.3、本地文件导入Hive
要知道Hive是应用于大数据场景下的,手动录入数据显然是不可能的,Hive提供了从文件导入数据到Hive的功能。
2.3.1、Linux本地文件导入
-
在Linux文件系统中创建一个stu.txt文件(/opt/module/data/stu.txt)
2 lisi 3 wangwu 4 sonliu字段之间以/t分隔
-
在Hive中使用命令从本地导入
load data local inpath ‘/opt/module/data/stu.txt’ into table student;
注意:从Linux本地导入数据要在load data后加上 local !!
-
导入数据后,却意外发现导入的数据无法被正常读取到
这是正常情况,总不能说随便来个数据像导入就导入吧!**必须保证数据的格式和已有的数据文件格式一致!!**我们在创建表的时候,并没有规定数据之间以
\t分割,而默认是<0x01>
很明显两个文件的数据格式就不一样!
-
重新建表规定数据格式
create table stu(id int, name string) row format delimited fields terminated by '\t';规定字段之间使用\t作为分隔符。
-
再次导入数据进新表

-
发现HDFS中对应表的数据文件中出现了stu.txt文件

既然就是将文件移动到了HDFS中对应的文件夹里面,那么我们使用hdfs命令手动put文件到这个文件夹中行不行呢?
-
手动put文件到HDFS测试
-
准备文件(/opt/module/data/stu2.txt)
5 xiaoming 6 xiaohong 7 xiaoqiang -
HDFS命令上传文件到/user/hive/warehouse/stu

-
hive查询

没有毛病!
初步判断本地导入数据,就是将本地的数据拷贝到了HDFS上的数据目录下
-
2.3.2、HDFS文件导入
刚才测试的是从Linux文件系统导入数据,现在我们直接在HDFS上导入数据。
-
准备数据导入到HDFS(hdfs:///stu3.txt)
8 aaa 9 bbb 10 ccc
-
Hive导入数据
load data inpath ‘/stu3.txt’ into table stu; -
查询结果

-
但是蹊跷的事情发生了:原数据文件在HDFS中不见了


不出意外数据还是在Hive的表数据目录中
难道真的是发生了数据迁移?
要知道这种移动的效果只是在HDFS这个可视化界面上产生,在Linux的Hadoop中数据的位置并没有发生变化,我们之前说的Hadoop的数据内容与元数据是分离的元数据放在NameNode中,也就是说想要达到视觉上的数据移动,只需要修改NameNode中stu3.txt文件的元数据(中的路径)即可。

真实的数据其实一直都在这里没有动。只是修改其元数据中的路径属性。
2.4、安装MySQL
为什么安装MySQL呢?
默认使用derby存储元数据,但是存在缺陷:只允许同时一个客户端窗口连接,开多窗口的连接hive时报错,无法连接:
![]()
所以改用MySQL来存储元数据。
MySQL的安装步骤参考:MySQL学习笔记
仅仅安装配置MySQL还不够,还需要一个MySQL的连接驱动,稍后会将其解压文件中的驱动jar包加入到Hive的lib目录下
![]()
修改Hive的配置文件(hive-site.xml(首次新建))
配置参考博客
hive-site.xml
<configuration>
<property>
<name>javax.jdo.option.ConnectionURLname>
<value>jdbc:mysql://hadoop102:3306/metastore?createDatabaseIfNotExist=truevalue>
property>
<property>
<name>javax.jdo.option.ConnectionDriverNamename>
<value>com.mysql.cj.jdbc.Drivervalue>
<description>Driver class name for a JDBC metastoredescription>
property>
<property>
<name>javax.jdo.option.ConnectionUserNamename>
<value>rootvalue>
<description>Username to use against metastore databasedescription>
property>
<property>
<name>javax.jdo.option.ConnectionPasswordname>
<value>hivevalue>
<description>password to use against metastore databasedescription>
property>
configuration>
在hive-default.xml中默认使用的连接驱动是derby

重启测试
配置完成后,重启hive,此时会发现之前的所有数据没有了,表示元数据已经成功迁移到了MySQL上!

此时再回到Hive中,尝试多窗口启动hive也不会报错了!!
来看看Hive存放再MySQL中的元数据

里面空空如也,也就很好解释为什么我们的Hive中没有数据了。
2.5、Hive的JDBC访问(了解)
有助于我们后期学习第三方框架,来替换默认的MapReduce
先向Hive中添加一些数据。
hive> select * from aaa;
OK
1
2
3
4
5
6
7
Time taken: 0.03 seconds, Fetched: 7 row(s)
-
启动hiveserver2服务
bin/hiveserver2(这是一个阻塞进程,当我们连接上进行操作时会输出相应的提示信息) -
启动beeline
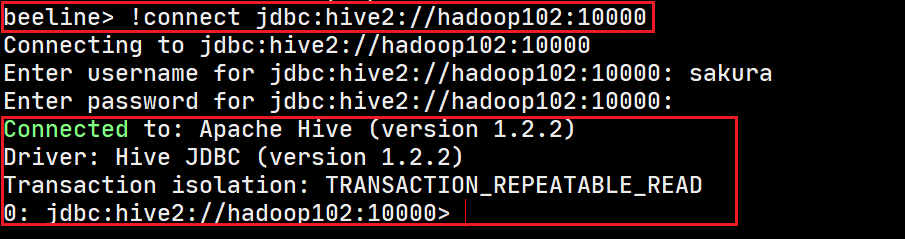
bin/beeline -
连接hiveserver2
beeline>
!connect jdbc:hive2://hadoop102:10000输入用户名:sakura,密码:没有不输入
-
连接成功
一边执行,hiveserver2的阻塞进程也在不停的输出命令的执行情况:

2.6、Hive常用交互命令
当前我们使用Hive存在一些局限,Hive的命令行都是在hive的命令行去完成,可是我们处理数据一般在凌晨使用脚本去自动完成,那能不能不进入hive在Linux命令行中就完成Hive的命令执行呢?
Hive给出了两种方案:执行命令行中的查询语句、执行文件中的查询语句

从命令行读取HQL执行

虽然说是有点慢,但是不必进入Hive再去执行查询了。
从文件读取HQL执行
在文件中先写好要执行的查询语句,使用-f选项加上文件路径执行即可

有了以上两种方法,就可以方便我们使用定时任务和脚本来自动完成一些事情。以上的两个命令都可以使用>将结果追加写入到文件中。
其他命令
-
在Hive客户端中操作HDFS
dfs -ls /xx/xx(dfs -xx)hive> dfs -ls /; Found 2 items drwx-wx-wx - sakura supergroup 0 2020-07-08 17:33 /tmp drwxr-xr-x - sakura supergroup 0 2020-07-08 23:11 /user hive> dfs -ls /user; Found 2 items drwxr-xr-x - sakura supergroup 0 2020-07-08 17:31 /user/hive drwx------ - sakura supergroup 0 2020-07-08 23:11 /user/sakura -
在Hive客户端操作本地文件系统
!ls /xx/xx(!mkdir等)hive> !ls .; bin conf derby.log examples hcatalog lib LICENSE metastore_db NOTICE README.txt RELEASE_NOTES.txt scripts -
查看你hive的历史执行命令
在当前用户的家目录中有一个
.hivehistory隐藏文件可以查看[sakura@hadoop102 ~]$ cat .hivehistory show databases; show database; show tables;
2.7、Hive常见属性配置
2.7.1、常用配置参数
以下配置均可以在hive-default.xml.template中找到,但是需要在hive-site.xml中进行修改!
Default数据库表数据的存放路径(默认:hdfs://hadoop102:9000/user/hive/warehouse)
<property>
<name>hive.metastore.warehouse.dirname>
<value>/user/hive/warehousevalue>
<description>location of default database for the warehousedescription>
property>
Hive命令行显示当前所在库、查询输出表头(默认都是关闭(false))
<property>
<name>hive.cli.print.current.dbname>
<value>truevalue>
<description>Whether to include the current database in the Hive prompt.description>
property>
<property>
<name>hive.cli.print.headername>
<value>truevalue>
<description>Whether to print the names of the columns in query output.description>
property>
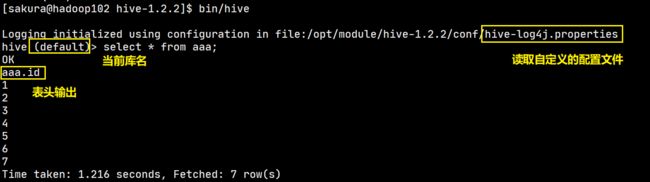
日志文件的输出位置
-
首先将conf目录下的hive-log4j.properties.template改为
hive-log4j.properties -
默认配置
hive.log.dir=${java.io.tmpdir}/${user.name} hive.log.file=hive.log默认是在
/tmp/sakura(用户名)目录下,文件名是hive.log
并且日志文件是按天滚动的。
-
修改配置
将日志文件位置改到
/opt/module/hive-1.2.2/logs/
以上配置完成,重启hive查看变化。
2.7.2、修改配置的方式
注意:所有用户自定义的配置都会覆盖原有的默认配置,并且Hive会读取Hadoop的配置,所以Hive上对Hadoop的参数配置也会覆盖原有的Hadoop配置。
Hive命令行查看,修改参数
set
只有set,不赋值就是查看
hive (default)> set hadoop.tmp.dir;
hadoop.tmp.dir=/opt/module/hadoop-2.7.7/data/tmp
hive (default)> set mapred.reduce.tasks;
mapred.reduce.tasks=-1
set赋值只是临时修改,仅在本客户端有效
hive (default)> set mapred.reduce.tasks=10;
hive (default)> set mapred.reduce.tasks;
mapred.reduce.tasks=10
Linux命令行修改(启动时配置)
--hiveconf property=value
[sakura@hadoop102 hive-1.2.2]$ bin/hive --hiveconf mapred.reduce.tasks=2
Logging initialized using configuration in file:/opt/module/hive-1.2.2/conf/hive-log4j.properties
hive (default)> set mapred.reduce.tasks;
mapred.reduce.tasks=2
同样这种也是临时修改,仅本次启动有效
配置文件覆盖
创建的hive-site.xml中配置信息会覆盖Hive原有的hive-default.xml中的对应配置!!
修改hive-default.xml.template是毫无意义的!!
三、Hive数据类型
3.1、基本数据类型
| Hive数据类型 | Java数据类型 | 长度 |
|---|---|---|
| tinyint | byte | 1个字节有符号整数 |
| smallint | short | 2个字节有符号整数 |
| int | int | 4个字节有符号整数 |
| bigint | long | 8个字节有符号整数 |
| boolean | boolean | 布尔类型,true or false |
| float | float | 单精度浮点数 |
| double | double | 双精度浮点数 |
| string | String | 字符串类型,使用双引号或单引号表示,可以指定字符集 |
| timestamp | 时间戳 | |
| binary | 字节数组 |
Hive的数据类型是大小写不敏感的,string类型相当于MySQL的varchar,是不可变的,不能指定存储长度,最多可以存储2G的字符数。
3.2、集合数据类型
| 数据类型 | 描述 | 语法示例 |
|---|---|---|
| struct | 结构体类型,类似于C语言中的结构体 | structName.fieldNmae |
| map | 集合Map类型,以KV形式存放数据 | mapName[‘keyName’] |
| array | 数组类型,按顺序存储数据 | arrayName[index] |
3.3、数据类型转换
和Java一样,Hive中的数据类型也支持隐式转换和显示转换,总体来说转换规则可以总结为:
表示范围小的的数据类型可以向表示范围大的数据类型转换
- tinyint、smallint可以转换为int,反之则不行。(不过可以使用cast()进行强转)
- int、float、string在数值正确的情况下可以转换为double
- boolean类型不支持数据转换
在hive客户端可以使用select cast(xx as xx)来尝试做数据类型转换
hive (default)> select cast('1' as int);
OK
_c0
1
Time taken: 0.189 seconds, Fetched: 1 row(s)
hive (default)> select cast('1.23' as double);
OK
_c0
1.23
3.4、集合数据类型实操
上面介绍了集合数据类型,那么我们如何在表中进行使用呢?
数据格式化问题
在Java开发中使用JSON传递数据,JSON对于数据格式要求严格,只有符合数据格式的数据才能被正确解析。这里也是相同的道理,要想Hive能从文件中正确解析出数据存储要做好两件事情:
- 规定好表数据格式
- 按照规定好的格式编写数据
建表并规定数据格式
create table student(
name string,
friends array<string>,
score map<string,int>,
address struct<street:string, city:string>
)
--数据格式规定--
row format delimited
fields terminated by ',' --字段使用 ',' 分隔--
collection items terminated by '_' --集合元素之间使用 '_' 分隔--
map keys terminated by ':' --map中kv之间使用 ':' 分隔--
lines terminated by '\n'; --行数据以 '\n' 分隔--
规定好了表中数据的格式后,就要按照要求写数据了。
按规定对数据格式化
我们先来看看对应的数据的JSON表达
{
"name": "sakura",
"friends": ["zhangsan","lisi"],
"score": [
"math": 78,
"computer": 80,
"english": 71
],
"address": {
"street": "danyangdadao",
"city": "yichang"
}
}
按照我们规定的格式对数据进行格式化后:
sakura,zhangsan_lisi,math:78_computer:80_english:71,danyangdadao_yichang
将格式化的数据写到文件中,在hive中从文件中加载数据测试:
hive (default)> select * from student;
OK
student.name student.friends student.score student.address
sakura ["zhangsan","lisi"] {"math":78,"computer":80,"english":71} {"street":"danyangdadao","city":"yichang"}
问题来了,数据插入成功了,我要怎么取出对应的这些集合中的数据呢?
集合数据查询
-
array数据查询
arrayName[index]hive (default)> select friends[0],friends[1] from student; OK _c0 _c1 zhangsan lisi直接使用数组名和下标就能取到数据。
-
map数据查询
mapName[keyName]hive (default)> select score['math'],score['english'] from student; OK _c0 _c1 78 71使用map名加上key就能取到对应的value值。
-
struct取值
structName.fieldNamehive (default)> select address.city,address.street from student; OK city street yichang danyangdadao
四、DDL数据定义
DDL(Data Definition Language):数据定义语言,主要用于操作数据库基本对象(数据库、表等)
4.1、数据库相关操作
创建数据库
在Hive中有一个初始的数据库:default,数据默认存放目录是/user/hive/warehouse。
创建数据库的基本命令:create databases dbName
为了安全起见一般使用create databases if not exists dbName
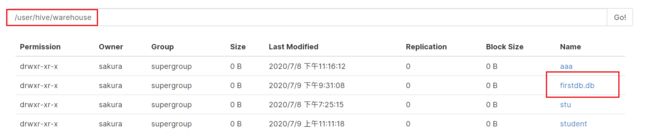
hive (default)> create database if not exists firstdb;
OK
默认情况下,创建的数据库目录放在/user/hive/warehouse目录下,以 数据库名.db 命名,MySQL中的存放的元数据也记录了这个路径
在这个库下创建的所有表数据都放在这个目录下。
Q:可不可以修改数据库目录的位置呢?
在之前的命令的基础上使用.. location ‘path’即可指定数据库的数据文件存放路径
hive (default)> create database if not exists seconddb location '/hivedb/seconddb';
OK
元数据中也会记录下这个路径:

查询数据库
-
显示所有数据库
show databases;(不用多说吧)hive (default)> show databases; OK database_name # 这个是表头 default firstdb seconddb也可以进行模糊查询显示哦!(通配符和mysql不同)
hive (default)> show databases like '*db'; OK database_name firstdb seconddb -
显示数据库的详细信息
desc database dbName;hive (default)> desc database firstdb; OK db_name comment location owner_name owner_type parameters firstdb hdfs://hadoop102:9000/user/hive/warehouse/firstdb.db sakura USER hive (default)> desc database default; OK db_name comment location owner_name owner_type parameters default Default Hive database hdfs://hadoop102:9000/user/hive/warehouse public ROLE其实这些东西就是MySQL中DBS表中存放个各个数据库的元数据

-
显示数据库其他扩展信息
desc database extended dbName在没有设置额外信息的时候,这条命令的输出和前者是一样的。在修改数据库中会使用这条命令。
修改数据库
这里所说的修改其实并不是对数据库的元数据进行修改,(比如数据存放位置、所有者、数据库名等这些都是不支持修改的),这里的修改是指对数据库的扩展信息(DBPROPERTIES)增改键值对。也就查询数据库详细信息中的parameters字段。
Q:那么什么是数据库扩展信息呢?
**A:**简单来说就是除了数据库的元数据之外,人为添加的一些数据库信息(例如:创建时间等)。
现在来增加创建一条扩展信息:alter database dbName set dbproperties('key'='value')
hive (default)> alter database firstdb set dbproperties('createtime'='2020/07/09');
OK
在MySQL的DATABASE_PARAMS表中就会存下这条扩展信息并记录这是属于哪个数据库的。

现在我们再使用desc database extended dbName就可以看到这条扩展信息了:
hive (default)> desc database extended firstdb;
OK
db_name comment location owner_name owner_type parameters
firstdb hdfs://hadoop102:9000/user/hive/warehouse/firstdb.db sakura USER {createtime=2020/07/09}
删除数据库(危!)
删除空数据库:drop database dbName;,保险起见加上if exists
hive (default)> drop database if exists seconddb;
Moved: 'hdfs://hadoop102:9000/hivedb/seconddb' to trash at: hdfs://hadoop102:9000/user/sakura/.Trash/Current
OK
删除数据库的同时还移除了数据库数据目录(好贴心)
如果删除尚存数据的数据库使用drop是无法删除的:
hive (firstdb)> drop database if exists firstdb;
FAILED: Execution Error, return code 1 from org.apache.hadoop.hive.ql.exec.DDLTask. InvalidOperationException(message:Database firstdb is not empty. One or more tables exist.)
# 提示数据库不为空,存在一个或多个表
两种办法:
- 先删除所有表,然后删库。(太慢了,删库跑路要快!开玩笑)
- 使用
drop database dbName cascade;(霸王硬上弓,强制删除)
hive (firstdb)> drop database firstdb cascade;
Moved: 'hdfs://hadoop102:9000/user/hive/warehouse/firstdb.db/aaa' to trash at: hdfs://hadoop102:9000/user/sakura/.Trash/Current
Moved: 'hdfs://hadoop102:9000/user/hive/warehouse/firstdb.db' to trash at: hdfs://hadoop102:9000/user/sakura/.Trash/Current
OK
4.2、表相关操作
4.2.1、创建表
建表语法(重要!)
CREATE [EXTERNAL] TABLE [IF NOT EXISTS] table_name(
col_name data_type [COMMENT 'col_comment'],
..
)[COMMENT 'table_comment']
[PARTITIONED BY (col_name data_type [COMMENT 'col_comment'],..)] --分区相关--
[CLUSTERED BY (col1_name, col2_name,..)
[SORTED BY (col_name [ASC|DESC],..)] INTO num_buckets BUCKETS] --分桶、排序相关--
[ROW FORMAT row_format] --数据文件表数据格式规定--
[STORED AS file_format] --表数据导入文件格式规定--
[LOCATION hdfs_path] --表数据存储路径--
以上大写字母均为关键字,[]为可选项。
Hive提供了查看表完整创建语句的命令:show create table table_name;
hive (default)> show create table student;
OK
createtab_stmt
CREATE TABLE `student`(
`name` string,
`friends` array<string>,
`score` map<string,int>,
`address` struct<street:string,city:string>)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
COLLECTION ITEMS TERMINATED BY '_'
MAP KEYS TERMINATED BY ':'
LINES TERMINATED BY '\n'
STORED AS INPUTFORMAT
'org.apache.hadoop.mapred.TextInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
LOCATION
'hdfs://hadoop102:9000/user/hive/warehouse/student'
TBLPROPERTIES (
'COLUMN_STATS_ACCURATE'='true',
'numFiles'='1',
'totalSize'='73',
'transient_lastDdlTime'='1594264278')
默认表的数据是放在数据库文件目录下的,在建表的时候可以使用location进行指定。
在建表的时候可以使用like来复制某一张表的结构,而不复制数据。
4.2.2、管理表(内部表)和外部表
Q:管理表和外部表之间有什么区别?
**A:**我们在建表语法中有一个关键词EXTERNAL,加上这个关键词创建的表就是外部表,反之则为管理表。其实很容易理解:表其实就是用来管理显示数据的,一张表的数据又分为表实际数据(存储在HDFS)和表信息元数据(存在MySQL)。
管理表(内部表)认为实际数据和元数据都由我一手管理,在删除表的时候元数据和实际数据一并删除!(也就是平时我们删表的时候,存放在MySQL中的元数据和HDFS上的数据文件统统删除)
外部表则认为只是管理一张表的元数据,真实数据不由我掌控,我删表的时候把自己的元数据删干净就行!(这种情况下,MySQL中表的元数据会被删除,但是元数据指向的真实数据目录并没有删除)
实践测试(删除外部表)
-
创建外部表
hive (default)> create external table test (id int); OK -
导入数据后,我们到HDFS上查看表的数据文件

MySQL中表的元数据

可以看到外部表相对于管理表来说还是存在一些区别的!
-
尝试删除外部表
hive (default)> drop table test; OK hive (default)> show tables; OK tab_name aaa student # 正常删除元数据删除成功:

真实数据被保留:

这就很有意思了,那恢复(重建)test表,还能不能正常读到数据呢?
-
重建表,试图恢复
hive (default)> create external table test (id int); # 重建表 OK hive (default)> select * from test; OK test.id 1 2 3 4 5 6OHHHHHHHHHHHHH!!居然可以!!
还记得我们最开始说Hive的框架原理部分的时候就着重强调了元数据和真实数据之间的关系,通过元数据的信息来锁定真实数据!
所以,元数据和真实数据的先后顺序没有要求,只要两者之间能够形成映射就能正常获取到数据。
Q:管理表和外部表能不能相互转化呢?如何转?
A:
在我们查看元数据的时候,管理表和外部表的两个区别:
- TBL_TYPE(TBLS表):
- 管理表:MANAGED_TABLE
- 外部表:EXTERNAL_TABLE
- EXTERNAL(TABLE_PARAMS表):
- 管理表:无
- 外部表:TRUE
TBLS表和DBS表一样是基本元数据是不能修改的!!
TABLE_PARAMS和DATABASE_PARAMS表一样,是扩展信息表,可以修改!
使用命令将EXTERNAL置为false就可以将外部表改为管理表。
Hive命令行,提供了查看表详细信息的命令
desc table_name:查看表字段信息desc formatted table_name:查看表完整信息

使用alter table table_name set tblproperties('key'='value')修改表扩展信息
hive (default)> alter table test set tblproperties('EXTERNAL'='FALSE');
OK

!!扩展信息里面的KEY、VALUE保证与原数据大小写一致!(‘external’=‘true’是无效的哦)
Q:管理表和外部表哪个好?分别用于什么场景?
**A:**从数据安全角度来说,无疑是外部表安全性更高。
管理表一般只适合用于做临时表。
存放业务数据的表或多部门共享的表还是推荐使用外部表,毕竟数据地安全性更高。
4.2.3、分区表
Q1:为什么出现分区?
**A1:**由于Hive本身对数据是无法创建索引的,所以每次查询数据在没有对数据进行处理的情况下,都要对全数据扫描!小点的数据还好,一旦海量的数据全扫描效率就非常之低,所以考虑对数据分区,将数据定位到某个区,那样每次扫描就只需要扫描某个区即可。
Q2:分区是什么概念?文件中如何实现?
**A2:**在普通情况下,所有的数据文件都会放在表数据目录下(混在一起),而进行分区时需要指定一个分区字段(这个分区字段是独立于表中字段的),使用这个字段以及字段值创建一个二级目录(…/table_name/partitoncol=value),在插入的数据的适合要指定分区字段的值,通过对应的值将数据放入到对应的分区目录中。
Q3:分区表如何创建?
**A3:**建表的适合加上partitioned by (col_name data_type)
create table employee(id int,name string)
partitioned by (department string)
row format delimited
fields terminated by '\t';
现在往里面塞数据使用之前的方法是不行哒!
hive (default)> load data local inpath '/opt/module/data/emp01.txt' into table employee;
FAILED: SemanticException [Error 10062]: Need to specify partition columns because the destination table is partitioned
现在插入数据告诉我们需要指定分区,因为表是分区表。
所以现在插入数据的正确操作是:load data local inpath '/opt/module/data/emp01.txt' into table employee partition(department='dev');
或者你也可以使用HDFS直接put数据到对应的分区里面也可以,前提保证数据可被解析。
遇到一个小插曲:惊奇的发现我的MySQL元数据库中没有PARTIONS表!!!出大问题,这直接导致我在插入分区数据的时候反复报错:
Failed with exception MetaException(message:For direct MetaStore DB connections, we don't support retries at the client level.) FAILED: Execution Error, return code 1 from org.apache.hadoop.hive.ql.exec.MoveTask虽然数据文件在分区目录中,但是怎么都查不出来数据,这就是因为分区信息没有被存储到元数据中。(其实不是没有存,而是没有地方存)就是因为PARTIONS表没有。
首先我用了
MSCK REPAIR TABLE table_name修复分区,告诉我patition不在元数据中。后来我去看了下日志文件,其中有一条日志信息Table 'metastore.PARTITIONS' doesn't exist去查了以下相关信息,给出的答案是:
MySQL数据库和MySQL连接驱动的问题。我用的MySQL版本是5.7.26,但是用的驱动是8.0.19,官方给出的解释是8.0+的驱动是可以兼容5.0+版本的MySQL,也就是说可以正常使用的。但是Hive不认啊,哎无奈换成5.1.48的驱动jar包,删除之前的metastore。把配置文件中连接驱动改成com.mysql.jdbc.Driver。
然后重启Hive,Partitions表回来了!!~~
到这里问题还不算完全解决,在每次启动都会有一堆提示,关于SSL的,如下(自行翻译):
Fri Jul 10 20:23:27 CST 2020 WARN: Establishing SSL connection without server's identity verification is not recommended. According to MySQL 5.5.45+, 5.6.26+ and 5.7.6+ requirements SSL connection must be established by default if explicit option isn't set. For compliance with existing applications not using SSL the verifyServerCertificate property is set to 'false'. You need either to explicitly disable SSL by setting useSSL=false, or set useSSL=true and provide truststore for server certificate verification.所以再修改一波连接URL:加上
&useSSL=false,在XML中用&代替&
插入分区数据成功后,我们看三个地方:HDFS文件、Hive数据、MySQL中元数据
HDFS文件:

分区目录:
Hive中查询数据:
hive (default)> select * from employee where department='dev';
OK
employee.id employee.name employee.department
1 zhangsan dev
2 liming dev
3 wanglei dev
4 laowang dev
最后那个department字段 ,是分区所用得字段但是查询的时候也会带上,我们想要缩小我们的搜索范围,在查询中使用where指定对应的分区就好了。
MySQL中元数据:
-
先看困扰了我很久的partitions表(关联一个SDS表)

-
其他几个和分区相关的表:(几张表相互关联)

4.2.3.a、分区表操作
增加分区
alter table table_name add patition(key=value) [partition(key=value) ..]
hive (default)> alter table employee add partition(department='financial') partition(department='person');
增加多个分区的时候,分区之间以空格间隔

元数据和HDFS文件都会产生相应的变化。
删除分区
alter table table_name drop partition(key='value')[,patition(key-value),..]
hive (default)> alter table employee drop partition(department='financial'),partition(department='person');
Dropped the partition department=financial
Dropped the partition department=person
OK
注意:当删除多个分区的时候不是使用空格隔开了!!分区之间使用,隔开。
查看分区数量、分区表结构信息
查看分区数量:show partitions table_name
hive (default)> show partitions employee;
OK
partition
department=dev
department=prod
查看分区表结构信息:desc formatted table_name

二级(多级)分区创建
道理和一级分区是相同的,只是对分区再分区。创建分区表的时候写上两个字段就可以了,分区字段的顺序决定了谁是一级目录谁是二级目录!,此时插入数据后就要同时填上两个分区字段的信息。
关于加入分区数据的问题
一共有三种方式可以引入分区数据。
-
方法一:使用分区修复命令
msck repait table table_name之前我们试过创建好分区直接往里面put数据,这样是可以的!现在我们来个更狠的,直接put一个分区目录。
[sakura@hadoop102 data]$ hadoop fs -mkdir /user/hive/warehouse/employee/department=other [sakura@hadoop102 data]$ hadoop fs -put ./emp01.txt /user/hive/warehouse/employee/department=other虽说HDFS中有数据了,但是MySQL里面没有对应的分区元数据,所以现在可以肯定的说这个分区是无效的,是查不出数据的:
hive (default)> show partitions employee; OK partition department=dev department=prod使用修复命令修复分区:
hive (default)> msck repair table employee; OK Partitions not in metastore: employee:department=other # 提醒分区不在元数据中 Repair: Added partition to metastore employee:department=other # 修复日志:增加分区再查数据:
hive (default)> show partitions employee; OK partition department=dev department=other department=prodOK,好起来了。
-
方法二:先加数据再加分区
刚才的修复日志给了我们灵感,修复就是增加了一个分区。因为真实数据已经在那了,就差元数据了,我们给这个分区创建一下元数据不就行了么。
-
方法三:使用load方式,增加数据的同时自动创建分区。
4.2.5、修改表
可以使用相应的命令来修改表名、表字段名、表字段类型,以及对表的字段增删替换。
重命名:
alter table old_table_name rename to new_table_name
hive (default)> alter table stu rename to staff;
OK
hive (default)> show tables;
OK
tab_name
employee
staff
列修改(增、改、替换)
-
增加列ADD:
alter table table_name add columns (col_name data_type,..)hive (default)> alter table staff add columns (sex tinyint, age int); OK Time taken: 0.244 seconds hive (default)> select * from staff; OK staff.id staff.name staff.sex staff.age 2 lisi NULL NULL 3 wangwu NULL NULL 4 songliu NULL NULL hive (default)> desc staff; OK col_name data_type comment id int name string sex tinyint age int -
修改字段CHANGE:
alter table table_name change [column] old_col_name new_col_name data_typehive (default)> alter table staff change sex tel string; OK hive (default)> desc staff; OK col_name data_type comment id int name string tel string age int -
字段替换REPLACE:
alter table table_name replace columns (col_name data_type [COMMENT],..)这个替换是对当前表的所有字段进行一次替换!
hive (default)> alter table staff replace columns (name string,birth string,addr string); OK hive (default)> desc staff; OK col_name data_type comment name string birth string addr string
以上所有的修改只涉及到表结构及元数据的修改,表中真实数据不会发生变化,显示为NULL只是因为数据无法转化为对应的类型。
删除表:
drop table table_name
五、DML数据操作
5.1、数据导入
5.1.1、使用Load向表中装载数据
完整语法
load data [local] inpath 'file_path' [overwrite] into table table_name [partition(..)];
- local(可选):表示从Linux本地文件系统导入数据
- overwrite(可选):表示覆盖原有的所有数据
- partition(可选):分区相关的数值
5.1.2、使用 Insert手动插入数据
除了原始的手敲数据,还可以直接把查询结果作为数据插入到表中。
-
复制一张employee表
hive (default)> create table aaa like employee; OK -
测试基本的数据插入
hive (default)> insert into table aaa partition(department='clean') values(8,'laoba'); hive (default)> select * from aaa; OK aaa.id aaa.name aaa.department 8 laoba clean -
根据查询结果插入
hive (default)> insert overwrite table aaa partition(department='clean') > select id,name > from employee > where department='dev'; hive (default)> select * from aaa; OK aaa.id aaa.name aaa.department 1 zhangsan clean 2 liming clean 3 wanglei clean 4 laowang clean好奇的人已经发现问题了,老八呢?insert同样支持使用overwrite覆盖写入,不过与load语法有一点不同,不需要into。
这一张表查询可以,多张表当然也行!在一个语句中不停使用insert就可以实现多张表查询结果的插入。
5.1.3、As Select创建表并直接加载数据
这个和创建表时候使用的like功能很想,区别在于使用As Select直接连搬带抄直接把数据也拿了过来。
hive (default)> create table if not exists bbb
> as select id,name from aaa;
hive (default)> select * from bbb; # 数据完整地拿过来
OK
bbb.id bbb.name
1 zhangsan
2 liming
3 wanglei
4 laowang
1 zhangsan
2 liming
3 wanglei
4 laowang
hive (default)> desc bbb; # 结构也是一模一样
OK
col_name data_type comment
id int
name string
5.1.4、建表使用Location直接加载数据
这种导入数据的方式原理很简单,就是利用HDFS上已有的数据再加上对应的元数据,就可以通过表来读取和管理这些数据。说白了它们就是差一个表,差一些元数据。
在建表的语句中使用location指向这个已有的数据目录就可以了。
5.1.5、使用Import导入数据
这个import和load data不同,不是随随便便一个文件你就可以拿来Import的,首先被Import的文件是经过export导出的才行,下一节学习数据导出时再来进行实操演示。
5.2、数据导出
5.2.1、Insert导出
在导入数据的时候我们使用Load data inpath命令,可以选择从本地或者HDFS上导入,这里Insert数据导出也同样支持本地和远程。
完整命令:insert [overwrite] [local] directory 'path' [row format ..] select * from table_name;
导出到本地local
直接导出数据(无数据格式)
hive (default)> insert overwrite local directory '/opt/module/data/employee_insert' select * from employee;
# 无数据格式导出到Linux文件系统
导出以后的数据是一个打包的目录,0000_0文件中就是导出的数据
[sakura@hadoop102 employee_insert]$ cat 000000_0
1zhangsandev
2limingdev
# ... 杂乱无章
想要二次利用数据就有必要在导出的时候确定导出的数据格式
hive (default)> insert overwrite local directory '/opt/module/data/employee_insert'
> row format delimited
> fields terminated by '\t'
> select * from employee;
使用了覆盖(overwrite导出),使用row_format规定导出数据的格式
[sakura@hadoop102 employee_insert]$ cat 000000_0
1 zhangsan dev
2 liming dev
3 wanglei dev
4 laowang dev
导出数据到HDFS
和load data一样去掉local即可,其他操作与本地导出一模一样

5.2.2、非常规数据导出
-
使用hdfs命令直接到表数据目录中get数据文件
HDFS命令中get命令将文件下载到本地
-
使用Hive的交互式命令
在学习交互式命令的时候使用
-e选项参数在Linux命令行中执行Hive命令,使用>将执行结果输出到文件中[sakura@hadoop102 data]bin/hive -e 'select * from staff;' > ./staff_data
5.2.3、使用Export数据导出,使用Import数据导入(了解)
基础命令
导出:export table table_name [partition] to 'hdfs_path'
导入:import table table_name [partiton] from 'hdfs_path'
数据导出
hive (default)> export table staff to '/staff_data';
HDFS数据层级目录
[sakura@hadoop102 data]$ hadoop fs -ls -R /staff_data
-rwxr-xr-x 3 sakura supergroup 1324 2020-07-13 21:08 /staff_data/_metadata
drwxr-xr-x - sakura supergroup 0 2020-07-13 21:08 /staff_data/data
-rwxr-xr-x 3 sakura supergroup 26 2020-07-13 21:08 /staff_data/data/stu.txt
==一个元数据文件、一个真实数据目录。==就是因为export导出的数据有元数据所以才能使用import,否则其他的数据是不能使用import导入的。
数据导入
hive (default)> import table staff from '/staff_data';
FAILED: SemanticException [Error 10119]: Table exists and contains data files
遇到问题:使用Import导入数据,表必须为未创建的表或者新表(没有插入过数据的表)
hive (default)> import table emp from '/staff_data';
hive会通过元数据信息自动创建表、匹配字段。
5.3、清空表数据(Truncate)
注意:truncate只能删除管理表的数据,不可以清空外部表
例如:现有一个外部表emp;
hive (default)> truncate table emp;
FAILED: SemanticException [Error 10146]: Cannot truncate non-managed table emp.
# 提示不能对非管理表使用truncate
管理表清空
hive (default)> truncate table staff;
OK
hive (default)> select * from staff;
OK
staff.id staff.name
可以想而知,对应表的HDFS数据目录下的数据文件肯定是被删除了

六、查询
6.1、基本查询
Hive的基本查询语法和MySQL几乎没什么区别。
全列查询和筛选列查询
# 全列查询
hive (default)> select * from emp;
OK
emp.id emp.name
2 lisi
3 wangwu
4 songliu
# 筛选列查询
hive (default)> select name from emp;
OK
name
lisi
wangwu
songliu
列别名、表别名
直接在列名(或表名)后加as然后加别名。也可以直接省略不写
# 列别名
hive (default)> select id staff_id
> from emp;
OK
staff_id
2
3
4
# 表别名
hive (default)> select a.id
> from emp a;
OK
a.id
2
3
4
常用查询函数
count()统计行数max()、min()最大最小值sum()数据总和avg()均值
Limit语句
hive (default)> select * from employee limit 4;
OK
employee.id employee.name employee.department
1 zhangsan dev
2 liming dev
3 wanglei dev
4 laowang dev
**这个里面limit好像只有一个参数!?**没有limit m,n;这种用法
6.2、Where语句
常用的比较运算符
-
=等值判断 -
<=>,等价运算符,真值表(仅当两值相等、或均为NULL时输出为true,任意一方为null,或者值不相等为false)hive (default)> select 'a' <=> null; OK _c0 false hive (default)> select null <=> null; OK _c0 true -
!=<>不等于 -
>=><=<大小比较 -
A [NOT] between B and C,范围(闭区间)条件 -
A is [NOT] null,空值判断 -
A in (B,C,..),集合判断 -
A [NOT] like 'regex_str',简单的SQL正则匹配通配符与MySQL一致:
%,_;前者为任意数量的字符,后者为匹配一个字符。 -
A RLIKE B, A REGEXP B,复杂正则表达式匹配,使用JDK中的正则表达式接口实现。
逻辑运算符
AND,逻辑并OR,逻辑或NOT,逻辑否
6.3、分组(GroupBy)
通常GroupBy和聚合函数一起使用,使用Having对分组数据做二次筛选。
与Where不同,Having只作用于分组后的数据,过滤掉不符合条件的分组。
==注意!!==这里同样有一个和MySQL一样的机制:ONLY_FULL_GROUP_BY,简单说就是select中的字段必须全部出现在groupby中。详情见MySQL高级部分groupby。
6.4、连接Join
左(外)连接、右(外)连接、内连接这些都和MySQL一样。
Hive和MySQL的连接查询区别有两点:
- Hive不支持非等值连接,仅能使用等值连接。
- Hive支持满外连接(Full outer join),而MySQL只能通过对join的条件进行处理以达到满连接的效果。
join的连接条件不支持使用or!
笛卡尔积
产生笛卡尔积的清况:
- 省略了连接条件
- 连接条件无效
- 所有表的所有行互相连接
使用笛卡尔积,通常数据量增长比较大,所以一般全局关闭使用笛卡尔积,使用时开启,避免不必要计算资源占用。
6.5、排序
6.5.1、全局排序Order By
全局排序在MapReduce过程中实现只有一个Reduce。
排序规则:
- DESC:降序
- ASC:升序(默认)
在OrderBy中可以使用列别名,也支持多列排序。
6.5.2、区内排序Sort By
往往我们的业务需求,是对分区数据进行排序,保证区内的数据是有序的,并不要求所有数据全局排序。区内排序就要用到Sort By,使用Sort By的前提是 MR处理数据是进行分区处理的,要想数据分区就设置Reduce的数量>1(回顾Hadoop之MapReduce)
在没有设置Reduce的数量的时候(默认-1),使用sort by和order by的运行结果是一样的。
表数据:
staff.id staff.name staff.age staff.sal staff.deptno
1 xiaowang 25 5900.0 2
2 zhaolaosi 31 7800.0 2
3 wanglaowu 34 6000.0 3
4 songxiaoqi 23 5200.0 2
5 lixiaodan 27 13000.0 1
6 zhaozong29 29 50000.0 1
7 xiaoxiaoli 20 4000.0 2
8 linxiaohong 22 6000.0 3
9 lishasha 24 6450.0 3
10 zhangfeng 31 8000.0 4
11 chendaniu 29 7000.0 3
12 liuerdao 27 6310.0 4
没有设置Reduce数量时,OrderBy和SortBy效果相同
OrderBy:
hive (default)> select name,sal,deptno
> from staff
> order by sal;
name sal deptno
xiaoxiaoli 4000.0 2
songxiaoqi 5200.0 2
xiaowang 5900.0 2
linxiaohong 6000.0 3
wanglaowu 6000.0 3
liuerdao 6310.0 4
lishasha 6450.0 3
chendaniu 7000.0 3
zhaolaosi 7800.0 2
zhangfeng 8000.0 4
lixiaodan 13000.0 1
zhaozong29 50000.0 1
SortBy:
hive (default)> select name,sal,deptno
> from staff
> sort by sal;
name sal deptno
xiaoxiaoli 4000.0 2
songxiaoqi 5200.0 2
xiaowang 5900.0 2
linxiaohong 6000.0 3
wanglaowu 6000.0 3
liuerdao 6310.0 4
lishasha 6450.0 3
chendaniu 7000.0 3
zhaolaosi 7800.0 2
zhangfeng 8000.0 4
lixiaodan 13000.0 1
zhaozong29 50000.0 1
设置Reduce数量为3(分区)后
设置单个Job的Reduce数量
hive (default)> set mapreduce.job.reduces;
mapreduce.job.reduces=-1
hive (default)> set mapreduce.job.reduces=3;
hive (default)> set mapreduce.job.reduces;
mapreduce.job.reduces=3
设置后,对OrderBy没有任何影响
SortBy测试:
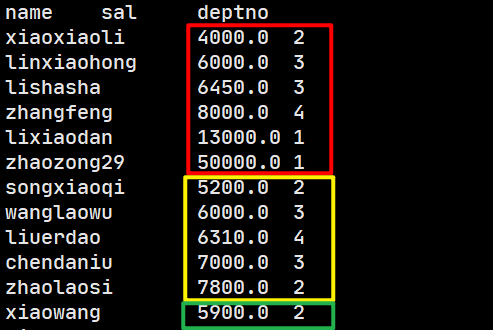
这个输出可以看出明显的三个分区但是规律不可寻,我们尝试将结果输出到文件系统中试试看。
hive (default)> insert overwrite local directory '/opt/module/data/staff_orderby'
> row format delimited fields terminated by '\t'
> select name,sal,deptno
> from staff
> sort by sal;
#-------------------------------
[sakura@hadoop102 data]$ cd staff_orderby/
[sakura@hadoop102 staff_orderby]$ ll
-rw-r--r--. 1 sakura sakura 119 7月 14 10:22 000000_0
-rw-r--r--. 1 sakura sakura 95 7月 14 10:22 000001_0
-rw-r--r--. 1 sakura sakura 18 7月 14 10:22 000002_0
# 果然三个分区就有三个输出文件
[sakura@hadoop102 staff_orderby]$ cat 000000_0
xiaoxiaoli 4000.0 2
linxiaohong 6000.0 3
lishasha 6450.0 3
zhangfeng 8000.0 4
lixiaodan 13000.0 1
zhaozong29 50000.0 1
[sakura@hadoop102 staff_orderby]$ cat 000001_0
songxiaoqi 5200.0 2
wanglaowu 6000.0 3
liuerdao 6310.0 4
chendaniu 7000.0 3
zhaolaosi 7800.0 2
[sakura@hadoop102 staff_orderby]$ cat 000002_0
xiaowang 5900.0 2
# 三个文件中内容和我们划出的三个分区是一样的
问题1:我们并没有指定按什么分区,那这些数据是如何进行分区的呢?自动使用hash分区吗?
问题2:sortby 和 orderby的区别
这些都可以在官方文档中找到结果:
Hive supports SORT BY which sorts the data per reducer. The difference between “order by” and “sort by” is that the former guarantees total order in the output while the latter only guarantees ordering of the rows within a reducer. If there are more than one reducer, “sort by” may give partially ordered final results.
Note: It may be confusing as to the difference between SORT BY alone of a single column and CLUSTER BY. The difference is that CLUSTER BY partitions by the field and SORT BY if there are multiple reducers partitions randomly in order to distribute data (and load) uniformly across the reducers.
Basically, the data in each reducer will be sorted according to the order that the user specified.
译文:
Hive支持SORT BY,可对每个reducer的数据进行排序。 “ order by”和“ sort by”之间的区别在于,前者保证输出中的总顺序,而后者仅保证reducer中行的排序。 如果存在多个reducer,则“sort by”可能会给出部分排序的最终结果。
注意:关于单个列的单独SORT BY与CLUSTER BY之间的区别可能会造成混淆。 区别在于,如果有多个reducer分区,则CLUSTER BY按字段划分,而SORT BY则是随机划分,以便在reducer上均匀地分布数据(和负载)。
基本上,每个reducer中的数据将根据用户指定的顺序进行排序。
回答问题1:==SORT BY是随机划分,以便在reducer上均匀地分布数据(和负载)。==在没有明确如何划分数据的时候,SortBy是随机划分,以确保数据的均匀分配。(防止数据倾斜问题)
回答问题2:“ order by”和“ sort by”之间的区别在于,前者保证输出中的总顺序,而后者仅保证reducer中行的排序。 如果存在多个reducer,则“sort by”可能会给出部分排序的最终结果。
中间有提到Cluster By马上就会提到!在此之前我们先学习Distribute By,用于数据分区通常和sortby一起使用。
6.5.3、数据分区Distribute By
在SortBy中我们没有指定按什么对数据分区,程序随机划分保证数据的均匀。而这里DistributeBy就相当于MapReduce中的Partitoner,经过了分区的数据再使用SortBy就可以保证分区内是有序的,且输出的文件中内容也是按照DistributeBy来划分的,
!重要使用了DistributeBy的时候,当可分区数量大于Reduce的数量时,并不保证每个分区中分区字段都一样,一般使用hashcode%NumReducer来确定在哪个分区
DistributeBy单独使用
hive (default)> select name,sal,deptno
> from staff
> distribute by deptno;
name sal deptno
#---------------------------3%3=0
chendaniu 7000.0 3
lishasha 6450.0 3
linxiaohong 6000.0 3
wanglaowu 6000.0 3
#---------------------------4%3=1%3=1
liuerdao 6310.0 4
zhangfeng 8000.0 4
zhaozong29 50000.0 1
lixiaodan 13000.0 1
#---------------------------2%3=2
xiaoxiaoli 4000.0 2
songxiaoqi 5200.0 2
zhaolaosi 7800.0 2
xiaowang 5900.0 2
我们将其输出到文件中来看一下是不是和我们预期的相同:
hive (default)> insert overwrite local directory '/opt/module/data/distributeby_staff'
> row format
> row format delimited
> fields terminated by '\t'
> select name,sal,deptno
> from staff
> distribute by deptno;
# 没毛病啊铁汁
[sakura@hadoop102 distributeby_staff]$ cat 000000_0
chendaniu 7000.0 3
lishasha 6450.0 3
linxiaohong 6000.0 3
wanglaowu 6000.0 3
[sakura@hadoop102 distributeby_staff]$ cat 000001_0
liuerdao 6310.0 4
zhangfeng 8000.0 4
zhaozong29 50000.0 1
lixiaodan 13000.0 1
[sakura@hadoop102 distributeby_staff]$ cat 000002_0
xiaoxiaoli 4000.0 2
songxiaoqi 5200.0 2
zhaolaosi 7800.0 2
xiaowang 5900.0 2
结合OrderBy使用
hive (default)> insert overwrite local directory '/opt/module/data/dist_sort_staff'
> row format delimited
> fields terminated by '\t'
> select name,sal,deptno
> from staff
> distribute by deptno
> sort by sal;
[sakura@hadoop102 dist_sort_staff]$ cat 000000_0
linxiaohong 6000.0 3
wanglaowu 6000.0 3
lishasha 6450.0 3
chendaniu 7000.0 3
[sakura@hadoop102 dist_sort_staff]$ cat 000001_0
liuerdao 6310.0 4
zhangfeng 8000.0 4
lixiaodan 13000.0 1
zhaozong29 50000.0 1
[sakura@hadoop102 dist_sort_staff]$ cat 000002_0
xiaoxiaoli 4000.0 2
songxiaoqi 5200.0 2
xiaowang 5900.0 2
zhaolaosi 7800.0 2
6.5.4、ClusterBy
下面我们学习一下ClusterBy,其实它只适用于分区排序中的特殊情况:
DistributeBy和OrderBy的字段是同一个字段时,可以直接使用Cluster By代替。
发问:对一个字段都分区了,每个分区中分区字段不应该都是一样的吗?那再对字段排序不是毫无意义吗?
再回头看看在DistributeBy中标注的那句话,当理论分区数量大于实际的Reducer数量的时候,是会出现分区中分区字段不同的情况的(参考上个例子)!所以这种操作还是有意义的。
实操:
hive (default)> insert overwrite local directory '/opt/module/data/cluster_staff'
> row format delimited
> fields terminated by '\t'
> select name,sal,deptno
> from staff
> cluster by deptno;
# 结果自行理会
[sakura@hadoop102 cluster_staff]$ cat 000000_0
chendaniu 7000.0 3
lishasha 6450.0 3
linxiaohong 6000.0 3
wanglaowu 6000.0 3
[sakura@hadoop102 cluster_staff]$ cat 000001_0
zhaozong29 50000.0 1
lixiaodan 13000.0 1
liuerdao 6310.0 4
zhangfeng 8000.0 4
[sakura@hadoop102 cluster_staff]$ cat 000002_0
xiaoxiaoli 4000.0 2
songxiaoqi 5200.0 2
zhaolaosi 7800.0 2
xiaowang 5900.0 2
6.6、分桶及抽样查询
6.6.1、分桶表及数据存储
==分桶表:建表时指定字段进行分桶,按照分桶的规则将每条数据细分到每个桶中,每一个桶在HDFS文件系统中表现为一个文件。==其行为类似与MapReduce中Map端的数据分区。
联系上面的分区DistributeBy
如果数据的分区规则是稳定的,使用了分桶以后,后续的数据插入都会判断分桶字段然后放入对应的桶中,并且查询的时候无需使用DistributeBy来指定划分,MR程序可以根据桶的个数自行选择Reducer的个数!
对比分区表
- 划分规则上,
在分区表中,分区依据的字段是独立于数据的,是我们额外增加的一个字段用于分区,并不能对数据的某一个列完成划分。
分桶表中,分桶的字段是数据中的,按照特定的列进行划分。 - 存储上,
分区表每一个分区在HDFS上对应一个目录
分桶表每一桶在HDFS上对应一个数据文件
分桶表创建(参考4.2.1中建表语法)
hive (default)> create table stu(id int,name string)
> clustered by (id)
> into 3 buckets
> row format delimited
> fields terminated by '\t';
# 数据按照id分桶,数据分到3个桶中。
问题:怎么向分桶表插入数据呢?
直接Load data?(很显然是不可以的,Load操作底层就是使用Hadoop的put,这样不经过计算显然是不行的,听说Hive3.X可以直接使用Load?)
所以往分桶表中插入数据必定要经过一次MR,那就联想到了Insert导入数据。
在此之前检查两个参数:
hive.enforce.bucketing(分桶支持,默认false,需改为true)mapreduce.job.reduces(Ruducer数量,默认-1,表示MR自动分配)
hive (default)> set hive.enforce.bucketing=true;
hive (default)> set mapreduce.job.reduces=-1;
设置这俩参数后,分桶才能有效,MR程序根据桶数量决定Reduce数量。
导入数据过程:
-
创建一个普通表,除了没有分桶其他和分桶表一模一样
-
先把数据导入到普通表中
# 初始数据 stu_tmp.id stu_tmp.name 2 lisi 3 wangwu 4 songliu 5 xiaoming 6 xiaohong 7 xiaoqiang 8 aaa 9 bbb 10 ccc 11 kongxiaoliu 12 abaaba 13 lvbuwei 14 liubei 15 guanyu -
使用Insert将普通表中的数据导入到分桶表
hive (default)> insert into table stu > select * from stu_tmp; -
查看HDFS文件看是否分桶成功:

[sakura@hadoop102 data]$ hadoop fs -cat /user/hive/warehouse/stu/000000_0 6 xiaohong 12 abaaba 3 wangwu 9 bbb 15 guanyu [sakura@hadoop102 data]$ hadoop fs -cat /user/hive/warehouse/stu/000001_0 4 songliu 13 lvbuwei 10 ccc 7 xiaoqiang [sakura@hadoop102 data]$ hadoop fs -cat /user/hive/warehouse/stu/000002_0 8 aaa 14 liubei 11 kongxiaoliu 5 xiaoming 2 lisi这分桶的规则不用多说肯定也是 hashcode % bucketNum
6.6.2、分桶的抽样查询
分桶抽样查询语句
select * from table_name tablesample (bucket x out of y);
参数解读以及抽样规则
x:从第x个桶开始抽取数据(桶编号从1开始)
y:必须为桶数量的倍数或者因子,通过y的值来确定抽取的数据比例。公式:抽取(桶数量÷y)个bucket数据。
规则:
-
当需要从多个bucket中抽取数据的时候,抽取的桶编号之间间隔y! (x,x+y,x+2y,x+3y,…)
-
根据规则一演算,x是不能大于y的。
若x>y,按照规则一的规律,最后抽的桶编号i=x+[(桶数量/y)-1]*y=>i=x+桶数量-y,
因为x>y所以最后抽的桶编号i是一定大于桶的数量的,所以是不合乎规范的!!
如果命令行中使用出现了x>y,直接报错:FAILED: SemanticException [Error 10061]: Numerator should not be bigger than denominator in sample clause for table stu
实际演示
hive (default)> select * from stu tablesample (bucket 2 out of 3); #从二号桶开始抽一桶数据,即二号桶的所有数据
OK
stu.id stu.name
4 songliu
13 lvbuwei
10 ccc
7 xiaoqiang
select * from stu tablesample (bucket 1 out of 6); # 从一号桶开始,随机抽出1/2桶的数据,即一号桶的1/2数据
OK
stu.id stu.name
6 xiaohong
12 abaaba
6.7、其他查询常用函数
空字段赋值
NVL(col_name,value|col)
在查询的时候,那些烦人的NULL,看着有点碍眼,使用这个函数,可以用固定值或者指定列的值来替换NULL。
函数功能描述:当查询结果中col_name列的值为null时,使用value(或者指定列col的值)替换null;
# 例如现在有这样一组数据
id name age
a1 zhsa 20
a2 lisi null
a3 liuliu 19
a4 xiaowu 22
a5 liuyu null
select name,nvl(age,0) from person;
# 查询结果就是
name age
zhsa 20
lisi 0
liuliu 19
xiaowu 22
liuyu 0
时间类
-
时间格式化:
date_format(date_str|col,'format_str')hive (default)> select date_format('2020-7-14','yyyy/MM/dd HH:mm:ss'); OK _c0 2020/07/14 00:00:00 hive (default)> select date_format('2020/7/14','yyyy/MM/dd HH:mm:ss'); OK _c0 NULL # 以/分隔的时间格式,hive是不认的哦,其他时间相关的函数也是注意!第一个参数只认
yyyy-MM-dd(即以短横线分割的),不认/分割的
-
时间和天数加减:
date_add或者date_sub(记住其一就OK,因为天数参数是可以为负数的)hive (default)> select date_add('2020-07-14',5); OK _c0 2020-07-19 Time taken: 0.042 seconds, Fetched: 1 row(s) hive (default)> select date_add('2020-07-14',-5); OK _c0 2020-07-09注意时间格式!
-
日期天数间隔:
datediff()hive (default)> select datediff('2020-7-14','2020-1-13'); OK _c0 183 hive (default)> select datediff('2019-8-17','2020-7-14'); OK _c0 -332
下面这个函数与时间计算关系不大,但是可以解决时间格式的问题,时间类函数中不支持(yyyy/MM/dd)格式的时间数据,我们就可以将/替换为-
字符串替换函数:regexp_replace('str','target','replace');
hive (default)> select regexp_replace('2020/7/14','/','-');
OK
_c0
2020-7-14
# 嘿嘿,来个绕的
hive (default)> select regexp_replace(date_add(regexp_replace('2020/7/14','/','-'),19),'-','/');
OK
_c0
2020/08/02
case when then&if
当列的值是我们可控范围内的,并且我们希望对数据进行划分的时候,比如男女统计,年龄、工资范围统计等等,可以会使用到Case分支函数,或者if-else。
数据准备
staff.id staff.name staff.age staff.sal staff.deptno
1 xiaowang 25 5900.0 2
2 zhaolaosi 31 7800.0 2
3 wanglaowu 34 6000.0 3
4 songxiaoqi 23 5200.0 2
5 lixiaodan 27 13000.0 1
6 zhaozong29 29 50000.0 1
7 xiaoxiaoli 20 4000.0 2
8 linxiaohong 22 6000.0 3
9 lishasha 24 6450.0 3
10 zhangfeng 31 8000.0 4
11 chendaniu 29 7000.0 3
12 liuerdao 27 6310.0 4
case分支函数语法:case [col_name] when bool_exp|value then true_val else false_val end)
可以结合sum()做数量统计。
# 需求一:分别统计年龄在(<22,22~28,>28)的三个区间的人数,分别定位小白,菜鸟,老鸟
hive (default)> select
> sum(case when age<22 then 1 else 0 end) xiaobai,
> sum(case when age>=22 and age<=28 then 1 else 0 end) cainiao,
> sum(case when age>28 then 1 else 0 end) laoniao
> from staff;
xiaobai cainiao laoniao
1 6 5
# 需求二:统计各个部门的人数 1:研发部,2:人事部,3:财务部,4:产品部
select
sum(case deptno when 1 then 1 else 0 end) yanfabu,
sum(case deptno when 2 then 1 else 0 end) renshibu,
sum(case deptno when 3 then 1 else 0 end) caiwubu,
sum(case deptno when 4 then 1 else 0 end) chanpinbu
from staff;
yanfabu renshibu caiwubu chanpinbu
2 4 4 2
当分支只有两个时,可以使用if来替代。
if语法:if(bool_exp,true_val,false_val);
# 需求三:统计工资低于6000和高于6000的人数
select
sum(if(sal<=6000,1,0)) xinren,
sum(if(sal>6000,1,0)) laogou
from staff;
xinren laogou
5 7
case&if的分支取值(true_val,false_val),可以是固定写死的值,也可以是使用列
行转列(拼接多列数据)
通常遇到需要将两个列的数据进行拼接显示,离不开concat()函数,与concat功能一致的还有一个特殊的函数:concat_ws()。
concat() 使用,concat(col_name|str,..)可以拼接任意多个值
hive (default)> select concat('hello','!','world');
OK
_c0
hello!world
concat_ws()使用,在使用concat进行拼接的时候,有时候需要频繁使用固定的分隔符,使用concat_ws()可以定好分隔符,只管写数据,concat_ws(separator,value1,valu2,...)
hive (default)> select concat_ws('-','this','is','concat_ws','usage');
OK
_c0
this-is-concat_ws-usage
但是很遗憾,concat_ws只对string类型或者array
再介绍一个函数,可以将查询结果中某一列的所有值,收集成为set或者list!!collect_set()/collect_list()
list和set的区别主要是:set是去重的。两者合理选择使用即可。
hive (default)> select collect_set(age) from staff;
[25,31,34,23,27,29,20,22,24]
collect_set,collect_list都是聚合函数!所以一般使用离不开groupby~
实操案例
# 案例数据
stu.name stu.sex stu.hobby
liming man basketball
wanghong woman tennis
liumeng woman basketball
zhangli man ping-pong
wanglei man basketball
likun woman tennis
zhaoqiang man basketball
# 需求分析
要求统计每种运动的男女分别的喜好人名,例如:
sports_sex member
basketball,man liming|wanglei|zhaoqiang
basketball,woman liumeng
ping-pong,mam zhangli
tennis,woman wanghong|likun
# 解题思路
1. 首先把sex、hobby使用concat()连接成字段sport_sex字段
2. 按照sport_sex字段分组,使用collect_set(),然后用concat_ws()进行姓名拼接。
# 代码
select
t1.sport_sex,
concat_ws('|',collect_set(t1.name))
from
(
select
concat(sport,',',sex) sport_sex,
name
from
stu_sports
) t1
group by t1.sport_sex;
# 计算结果
basketball,man liming|wanglei|zhaoqiang
basketball,woman liumeng
ping-pong,man zhangli
tennis,woman wanghong|likun
列转行(单列数据拆分)
在行转列中,我们使用collect_set()和concat()将列中的多行数据转为一个列的单行数据。
在列转行中,操作恰恰相反:我们要将一个列的单行数据进行拆分形成多行数据。类似的需求:电影类别的拆分。
explode():可以将集合中元素拆分成多个单项。
还有一个与之配合使用的语法:lateral view(侧视图,侧写),主要是用其将explode()生成的数据转化为一个视图暂存,然后方便和原数据进行关联。
案例实测
# 案例数据
**movie.name** **movie.genres**
Extreme Measures (1996) Drama|Thriller
Upside Down (2012) Drama|Romance|Sci-Fi
Liability, The (2012) Action|Thriller
Angst (1983) Drama|Horror
Stand Up Guys (2012) Comedy|Crime
Side Effects (2013) Crime|Drama|Mystery|Thriller
Identity Thief (2013) Comedy|Crime
ABCs of Death, The (2012) Horror
Glimmer Man, The (1996) Action|Thriller
# 需求描述
将每部电影和其每个分类流派单独形成一行记录,方便后续统计。
# 目标结果
**movie.name** **movie.genres**
Extreme Measures (1996) Drama
Extreme Measures (1996) Thriller
.. ..
# 解题思路
1. 对genres使用explode()
2. 使用lateral view暂存explode()结果,然后与关联数据(电影名)做笛卡尔积
# 实现过程
- 建表(genres一定要定为集合类型,否则是无法使用explode())
```sql
create table movies(name string,genres array)
row format delimited
fields terminated by '\t'
collection items terminated by '|';
```
- 加载数据(案例数据需要进行加工)
Extreme Measures (1996) ["Drama","Thriller"]
Upside Down (2012) ["Drama","Romance","Sci-Fi"]
Liability, The (2012) ["Action","Thriller"]
Angst (1983) ["Drama","Horror"]
Stand Up Guys (2012) ["Comedy","Crime"]
Side Effects (2013) ["Crime","Drama","Mystery","Thriller"]
Identity Thief (2013) ["Comedy","Crime"]
ABCs of Death, The (2012) ["Horror"]
Glimmer Man, The (1996) ["Action","Thriller"]
- SQL代码测试
测试使用`explode()`
> `select explode(genres) from movies;`
结果(部分):
col
Drama
Thriller
Drama
Romance
Sci-Fi
..
- 尝试直接使用explode(),不使用lateral view
> `select name,explode(genres) from movies;`
报错:UDTF's are not supported outside the SELECT clause, nor nested in expressions
原因:当使用UDTF函数(例如explode())的时候,hive只允许对拆分字段进行访问,而name并不是。
- 测试结合使用lateral view
```sql
select
name,
movie_genre
from
movies lateral view explode(genres) table_tmp as movie_genre;
```
结果(部分):
Extreme Measures (1996) Drama
Extreme Measures (1996) Thriller
Upside Down (2012) Drama
Upside Down (2012) Romance
Upside Down (2012) Sci-Fi
上述案例中使用的lateral view相当于把explode()的结果用一张临时的表存了起来,并重命名列,然后于原数据中的name进行关联。巧妙解决了此前的报错问题。
窗口函数
1、了解和认识窗口函数over()
over:指定分析函数工作的数据窗口大小,窗口大小随着行变化而变化。
我们先不介绍太多,测试对比一下慢慢理解。
测试数据准备:
**name** **orderdate** **cost**
jack 2017-01-01 10
tony 2017-01-02 15
jack 2017-02-03 23
tony 2017-01-04 29
jack 2017-01-05 46
jack 2017-04-06 42
tony 2017-01-07 50
jack 2017-01-08 55
mart 2017-04-08 62
mart 2017-04-09 68
neil 2017-05-10 12
mart 2017-04-11 75
neil 2017-06-12 80
mart 2017-04-13 94
create table marketorder(name string,orderdate string,cost int)
row format delimited
fields terminated by '\t';
需求:统计2017年4月消费的人数以及人名。
目标输出:
jakc 2
mart 2
# 表示一共两人,jack mart
解题思路全过程:
-
统计总数肯定离不开count(),随之就会联想到分组(GroupBy)
-
对orderdate分组肯定不太现实,只能统计出每个人的订单的数量,其实问题出在GroupBy的一个特殊机制,select中的所有字段都必须出现在GroupBy的字段中!。
这个需求的描述中就暗示着GroupBy中必定有name这个字段,所以即便我们按照orderdate的月份分组并筛选出来的4月订单也会被name分为两个组。# SQL select name, count(*) from marketorder group by substring(orderdate,1,7), name having substring(orderdate,1,7)='2017-04'; # groupby结果 > 分组一 jack 2017-04 > 分组二 mart 2017-04 mart 2017-04 mart 2017-04 mart 2017-04 # 结果 jack 1 mart 4 -
转移阵地,就只对name分组,然后在where中对月份筛选,其实和上面这种没什么区别,只要是对name分了组,想统计总数(相当于统计分组数量)就基本很难完成
# SQL select name, count(*) from marketorder where substring(orderdate,1,7)='2017-04' group by name; # 结果 jack 1 mart 4 -
发现结果还是这个样,原因就是groupby对name分组以后,虽然显示的是jack,mart其实是代表两个组,那么执行count(*)就是针对于每个组来统计。那两个组的记录在步骤2中列出,所以得到1,4的结果并不意外。
# SQL select name from marketorder where substring(orderdate,1,7)='2017-04' group by name; # 结果 jack mart -
理想的实现过程:把步骤4的结果单独拎出来再做一次count呢?
目前我们我们通过子查询嵌套还是只能统计出总数量,而不能显示名字,如果要显示名字,外层SQL也要用GroupBy,结果就又不一样了。# SQL 1 select count(*) from ( select name from marketorder where substring(orderdate,1,7)='2017-04' group by name ) t1; # 结果 2 # SQL 2 select t1.name, count(*) from ( select name from marketorder where substring(orderdate,1,7)='2017-04' group by name ) t1 group by t1.name; # 结果 jack 1 mart 1 -
无论怎样使用现有的知识还不足以用很简单的办法解决这个问题。
但是思路已经确定:将按照名字分组的结果再做一次单独的count。窗口函数中的over()也许可以帮上忙。
窗口函数over()可以做到:对数据重新开一个窗口进行分析计算。
那么这个窗口是什么概念呢?目前我简单地将其认为是对当前的数据进行提取,形成一个新的临时数据集供我们单独使用。例如:
# 步骤四SQL查询结果 jack mart > 虽然这两行数据在那个SQL中只是代表着两个分组,每个分组中又有若干数据。但是在使用窗口函数over()的时候,我就只当它是两行数据提取出来就是普普通通的两行记录,然后再使用count(),结果为2; -
窗口函数over()测试使用
# SQL select name, count(*) over() from marketorder where substring(orderdate,1,7)='2017-04' group by name; # 结果 name count_window_0 mart 2 jack 2- over():无参表示窗口大小对应所有数据行。
- over()在聚合函数count(*)之后: 表示对分组后的结果数据重新开辟窗口然后使用count(*);
over()练习案例:输出订单明细,并统计订单总金额。
# 你以为的SQL
select
*,
sum(cost)
from
marketorder;
# 结果
要求使用groupby,so 没这么简单。
# 实际上的SQL
select
*,
sum(cost) over()
from
marketorder;
# 结果(部分)
marketorder.name marketorder.orderdate marketorder.cost sum_window_0
mart 2017-04-13 94 661
neil 2017-06-12 80 661
mart 2017-04-11 75 661
..
上述案例都涉及一个问题就是:SQL中只要用到聚合函数就一定要用到group by 吗?
回答:不一定,要分情况而定
1、当聚集函数和非聚集函数出现在一起时,需要将非聚集函数进行group by
2、当只做聚集函数查询时候,就不需要进行分组了。上述情况中,select字段中既有使用了聚合函数的列,又有未使用聚合函数的列,此时对于未使用聚合函数的列要进行groupby
除此以外再了解一下SQL的执行顺序
from -> join on -> where -> group by -> having -> select -> order by -> limit
2、了解over()函数参数选择
在over()函数的入门了解阶段,我们提到当over函数的参数为空时,默认开启的窗口大小是所有数据行。也就是是我们可以通过参数调制窗口大小,然聚合函数对部分区域的数据有效。
可怕的需求来咯:
-
基础版:按照日期顺序统计当前收益金额。(cost累加)
# 期望输出 jack 2017-01-01 10 tony 2017-01-02 25 tony 2017-01-04 54 jack 2017-01-05 100 ... # 遇到麻烦了.. > 使用之前的over(),然后使用聚集函数sum(),只能统计出来总数。 # 正确的解题思路 > 将订单按照日期排序,然后逐渐放大窗口大小,从1条,2条,直到所有。完美契合需求。 # 怎么控制窗口大小顺序变大呢?代码呈上=> select *, sum(cost) over(order by orderdate) from marketorder; # 结果 name orderdate cost sum_window_0 jack 2017-01-01 10 10 tony 2017-01-02 15 25 tony 2017-01-04 29 54 jack 2017-01-05 46 100 tony 2017-01-07 50 150 jack 2017-01-08 55 205 ..根据代码来看,很清楚我们就是在over的参数上做文章。
order by并没有写在select查询语句中,而是搬到了over()函数的参数中。告诉开窗函数按着日期的顺序依次放大窗口,每一个窗口执行一次sum,就得到了结果。
-
进阶版:在基础版的基础上改为统计每个人的消费累加。(按人名分组,每组累加cost)
# 解题思路 > 窗口按照name分组开放,每个分组内按照日期逐渐放大窗口 # 怎么进行窗口分组开放?代码呈上=> select *, sum(cost) over(distribute by name sort by orderdate) from marketorder; # 结果(部分) jack 2017-01-01 10 10 jack 2017-01-05 46 56 jack 2017-01-08 55 111 jack 2017-02-03 23 134 jack 2017-04-06 42 176 .. # 小分析 `distribute by`和`sort by`是重点!在6.5中介绍两者的功能分别是:数据分区、区内排序。 也可以使用partition by和order by结合使用替换。
除了常用的distribute by、sort by、partition by、order by。
还有可以使用使用rows [betweem .. and ..],两处可填以下数值
- current row:代表当前行
- n perceding:往前n行数据
- n following:往后n行数据
- unbounded:起止位置
- unbounded preceding:表示从数据的起点
- unbounded following:表示到数据的终点
3、over()外常用函数
lag(col,n,default_val):当前数据往前第n条记录中col列的数值
lead(col,n,default_val):当前数据往后第n条记录中col列的数值
以上两个函数需要用over()进行辅助使用。可以在为每条记录开辟窗口的时候跨行访问到数据并加以利用。
使用场景:在每一条消费记录上增加一列,显示用户上一次消费的日期。
# 解题思路
> 先按照name分组,每组按照orderdate顺序开放窗口,每次为一条记录开辟窗口时,获取前一行数据的orderdate列并加到查询结果列中。
# 使用lag()完成需求
select
*,
lag(orderdate,1,'1970-01-01') over(distribute by name sort by orderdate)
from
marketorder;
# 结果(部分)
name orderdate cost lasttime
jack 2017-01-01 10 1970-01-01
jack 2017-01-05 46 2017-01-01
jack 2017-01-08 55 2017-01-05
jack 2017-02-03 23 2017-01-08
jack 2017-04-06 42 2017-02-03
...
lead的用法与之相同,好好理会其中的执行过程吧。
ntile(n):对有序的数据分为n个组,并保证分组中的数据均匀。每条记录都有对应的分组号(从1开始)
测试一下:
select
name,
orderdate,
cost,
ntile(5) over(order by orderdate)
from
marketorder;
# 结果(部分)
name orderdate cost ntile_window_0
jack 2017-01-01 10 1
tony 2017-01-02 15 1
tony 2017-01-04 29 1
jack 2017-01-05 46 2
tony 2017-01-07 50 2
jack 2017-01-08 55 2
...
需求:按照日期顺序筛选出前10%的订单
# 需求的难点,以及为什么使用ntile
> 此需求是站在总体数据集的角度来看,并不是说固定的条数,而一个比例数,那么在现实场景中我们无从得知总记录数,也就难以判断前10%是多少条数据。
可是使用ntile(10),先将平均数据分组成10份,取出分组号为1的分组即为前10%。
# 上代码
- 错误示范
select
name,
orderdate,
cost,
ntile(10) over(order by orderdate) ntile_10
from
marketorder
where
ntile_10=1;
> 错误解释:基本错误!!在SQL的执行过程中where要先于select,所以where里面不能使用列别名,同理这里ntile(10)也是在select中才执行。
- 正确示范
select
name,
orderdate,
cost
from
(
select
name,
orderdate,
cost,
ntile(10) over(order by orderdate) ntile_10
from
marketorder
) t1
where
t1.ntile_10=1;
# 结果
name orderdate cost
jack 2017-01-01 10
tony 2017-01-02 15
4、排行Rank
常用的三种排行函数:
RANK():排序字段相同时,重复但总数不变化(计数器不影响)。DENSE_RANK():排序字段相同时,重复但是总数减少(计数器停滞)。ROW_NUMBER():排序字段相同时,按照顺序计数排行。
案例:给学生多科成绩,按照学科分类排名。
# 案例数据
**name** **subject** **score**
xiaohong math 98
xiaoming english 71
xiaolimi computer 86
xiaoqiang math 81
xiaoming computer 93
xiaoqiang english 81
xiaohong computer 93
xiaoming math 88
xiaolimi english 95
xiaohong english 95
xiaoqiang computer 90
xiaolimi math 87
# 建表
create table score(name string,subject string,score int)
row format delimited
fields terminated by '\t';
# 案例需求的代码=>
select
name,
subject,
score,
rank() over(partition by subject order by score DESC) rank,
dense_rank() over(partition by subject order by score DESC) dense_rank,
row_number() over(partition by subject order by score DESC) row_number
from
score;
# 运行结果(部分)
name subject score rank dense_rank row_number
xiaohong computer 93 1 1 1
xiaoming computer 93 1 1 2
xiaoqiang computer 90 3 2 3
xiaolimi computer 86 4 3 4
三者之间的区别通过结果就可以看得一清二楚。
七、函数
7.1、系统内置函数
-
查看系统自带函数
show functions; -
查看某个函数的用法
desc funtion function_name; -
详细查看用法(带示例)
desc function extended function_name;
7.2、自定义函数
在真实的业务场景中,系统内置的函数不足以满足我们的某些特殊需求,即使可以实现也要经过一套复杂的流程。那么这时可以考虑自定义函数。(UDF:User-Defined-Function)
三类用户自定义函数
- UDF(User-Defined-Function):一进一出
- UDAF(User-Defined Aggregation-Function):聚集函数,多进一出
- UDTF(User-Defined Table-Genertating Function):一进多出,例如
lateral view explore()
7.2.1、自定义UDF函数具体步骤
-
继承 org.apache.hadoop.hive.ql.UDF类
-
实现evaluate()方法;evaluate()支持重载。
-
Hive命令行窗口添加创建函数
-
添加jar包:
add jar jar_path -
创建function
create [temporary] function [dbname.]function_name as 'class_name';
-
-
Hive命令窗口删除函数
drop [temporary] function [if exists] [dbname.]function_name;
自定义的函数类必须要有返回值!!返回类型不可为void!!可以返回null
7.2.2、自定义UDF
-
创建maven工程并导入依赖
<dependency> <groupId>org.apache.hivegroupId> <artifactId>hive-execartifactId> <version>1.2.2version> dependency>可能遇到某些依赖aliyun仓库中找不到,将maven的镜像换成官方仓库即可。
-
创建自定义函数类并继承UDF,实现evaluate()方法,参数和返回值自定
package com.sakura.hive; import org.apache.hadoop.hive.ql.exec.UDF; public class MultiplyFive extends UDF { public int evaluate(int input) { return input * 5; } } -
maven打包,将jar包上传到Linux上。(为了方便管理,我们将其加入到/opt/module/data目录中,位置自定只是在后续创建函数需要使用jar包的路径。也可以直接放到hive的lib目录中,无需每次创建函数的时候都add jar包)
-
添加jar包,创建函数
# 添加jar包 add jar /opt/module/data/hive-1.0.jar # 创建函数 create function multiplyfive as 'com.sakura.MultiplyFive'; -
测试函数
hive (default)> select multiplyfive(13); OK _c0 65在当前库创建的函数只能在当前库中使用,不可以跨库使用
-
删除函数
drop function if exists multiplyfive;
7.2.3、自定义UDTF函数具体步骤
步骤相对于UDF要复杂,但是也有固定的套路。
- 继承GenericUDTF类(抽象类)
- 重写
initialize,process,close方法,后两者是强制要求重写。各自作用在实现中细说。 - 打包上传,创建函数。
7.2.4、自定义UDTF函数
initialize():StructObjectInspector
抽象类GenericUDTF并没有强制要求重写此方法,为何要手动添加重写?

怎么写?
参考已有实现类:GenericUDTFJSONTuple中的initialize()方法,在return语句上做文章
return ObjectInspectorFactory.getStandardStructObjectInspector(fieldNames, fieldOIs);
从类最后部分的写法中可以知道fieldNames和fieldOIs是两个List,并且两者具有一定的关联关系,并且和字段(列)息息相关。

我们所写的是UDTF(即一进多出),即对一行的某列数据进行解析得到多个数据。在使用exploded()的时候,解析出来的数据都是在一列中。
而我们自定义UDTF的时候发现的fieldNames居然是一个List,那么说明我们可以选择将数据解析成多个列多个行的数据。
==fieldOIs其实就是对应fieldNames中每个字段的类型验证。==只不过这里的类型并不是Java中的数据类型。这些数据类型都要通过PrimitiveObjectInspectorFactory类来获取。
例如:PrimitiveObjectInspectorFactory.javaStringObjectInspector就相当于Java中的String类,也最常用。
process():void
Hive中使用此函数的时候,针对每一行数据调用一个process()。即每解析一行数据就要调用一次。负责主要的功能逻辑。
参数是通过函数调用时的参数传入的。所以是一个Object[];
功能实现由业务而定不必多说。
关键在于处理后的数据的输出!在初始化的时候我们就定下了我们输出数据的字段名和类型校验。那么我们输出数据也要按照规则使用List存放数据。最后使用forward()将list写出。每调用一次forward就写出一行数据,想要多列写出只需要在写出的list中多放数据即可,但是要于初始化中字段数量一致!!
close()
资源关闭和释放等操作。
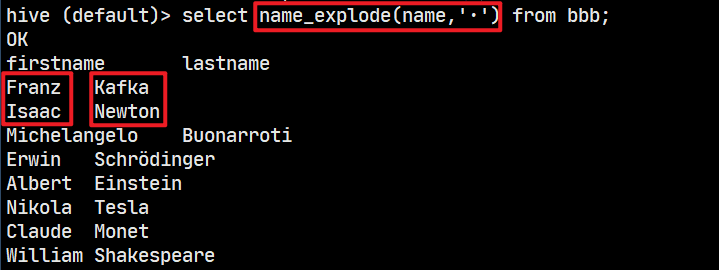
实操案例:名字切分
# 示例数据
Franz·Kafka
Isaac·Newton
Michelangelo·Buonarroti
Erwin·Schrödinger
Albert·Einstein
Nikola·Tesla
Claude·Monet
William·Shakespeare
# 要求将名字拆分为firstName和lastName分开显示
NameExplode类
public class NameExplode extends GenericUDTF {
private List<Object> outputData = new ArrayList<>();
@Override
public StructObjectInspector initialize(StructObjectInspector argOIs) throws UDFArgumentException {
List<String> fieldNames = new ArrayList<>();
fieldNames.add("firstName");
fieldNames.add("lastName");
List<ObjectInspector> fieldOIs = new ArrayList<>();
fieldOIs.add(PrimitiveObjectInspectorFactory.javaStringObjectInspector);
fieldOIs.add(PrimitiveObjectInspectorFactory.javaStringObjectInspector);
return ObjectInspectorFactory.getStandardStructObjectInspector(fieldNames, fieldOIs);
}
@Override
public void process(Object[] args) throws HiveException {
String fullName = args[0].toString();
String separator = args[1].toString();
String[] splitName = fullName.split(separator);
outputData.clear();
for (String split : splitName) {
outputData.add(split);
}
forward(outputData);
}
@Override
public void close() throws HiveException {
}
}
打包测试
八、压缩和存储
8.1、数据压缩
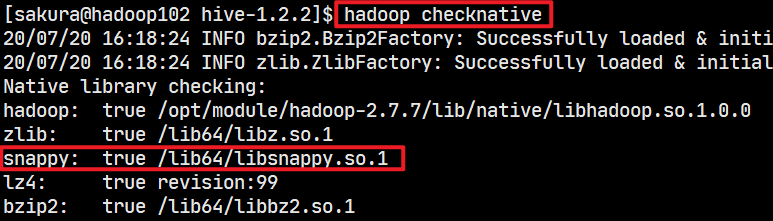
一般要求编译Hadoop,也可以将编译过的Hadoop的native中的文件直接拷贝一份就可以。然后重启Hadoop,使用hadoop checknative来看压缩支持的情况,我的Hadoop之前编译过,莫名奇妙就支持了snappy压缩。
相关的参数的设置(Hive命令行设置,临时生效)
set hive.exec.compress.output=true:开启Hive最终输出数据的压缩功能。set mapreduce.output.fileoutputformat.compress=true:开启mapreduce最终输出数据压缩set mapreduce.output.fileoutputformat.compress.codec=org.apache.hadoop.io.compress.SnappyCodec:设置mapreduce输出数据压缩编码器为Snappy。set mapreduce.output.fileoutputformat.compress.type=BLOCK:设置压缩方式为块压缩(BLOCK),默认为行压缩(RECORD)
测试压缩输出
使用insert导出查询结果:
insert overwrite local directory '/opt/module/data/masters' select * from bbb;
得到snappy压缩文件:

8.2、文件存储
Hive支持的存储数据格式
- TEXTFILE (文本文件)
- SEQUENCEFILE(序列化文件)
- ORC(使用最多)
- PARQUET(Spark中默认使用)
建表时使用stored as xxx指定数据文件的存储格式
8.2.1、行存储和列存储
此处说的行存储和列存储,在文件中都是行模式写入,只是写入的顺序有所不同。
**行存储:**表中数据存入文件时,是==以数据记录的顺序存储的。==一条记录紧接着一条记录。
**列存储:**存数据时,按照列的顺序存储,一列(字段)所有数据紧放在一起,存完后然后存下一个列的所有数据。
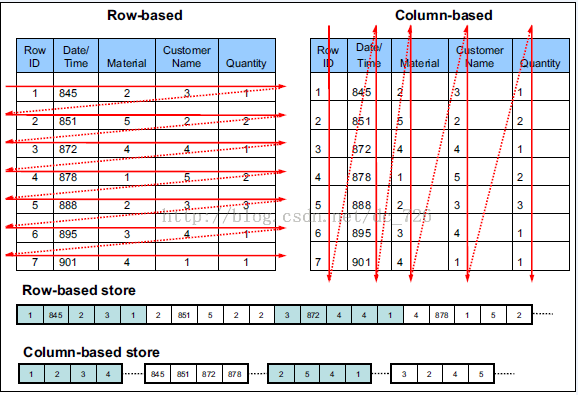
各自的使用场景:
-
行存储
当查询的字段很多,且不稳定时 或者 按条件筛选查询时,使用行存储更加高效,由于同一行记录的数据都在“附近”,取数据的速度要比使用列存储快。
-
列存储
当查询的字段较少,且稳定时,使用列存储可以快速取到本列所有的数据,效率更高。
TEXTFILE和SEQUENCEFILE 采用行存储
ORC和PARQUET 采用列存储
8.2.2、存储数据格式
TextFile格式
默认的格式,数据不做压缩,磁盘开销较大,数据解析开销大
ORC(Optimized Row Columnar)格式
参考阅读博客:https://www.cnblogs.com/ITtangtang/p/7677912.html
ORC具有以下一些优势:
- ORC是列式存储,有多种文件压缩方式,并且有着很高的压缩比。(ORC > Parqute)
- 文件是可切分(Split)的。因此,在Hive中使用ORC作为表的文件存储格式,不仅节省HDFS存储资源,查询任务的输入数据量减少,使用的MapTask也就减少了。
- 提供了多种索引,row group index、bloom filter index。
- ORC可以支持复杂的数据结构(比如Map等)
文件结构示意图:
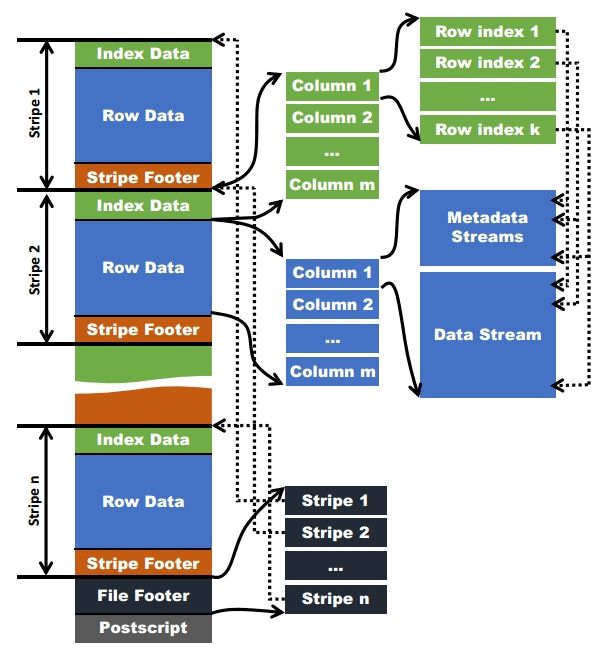
ORC文件中通常由多个stripe组成,默认每1W条数据创建一个索引(IndexData),列数据存放在RowData中,然后加上stripe的相关元数据构成一个stripe。并不是我们想象中的一个列完全存放完再存放下一个列,这样的做法在检索数据时效率低下。而使用stripe分块(行组)存储单独建立索引,检索数据要更快。
ORC存储格式自带了压缩,采用Zlib压缩,所以ORC的压缩比比较出色!
在建表语句中stored by orc 后接tblproperties("orc.compress"="xxx")来修改ORC存储时压缩方式。例如:SNAPPY,NONE…
Parquet格式(扩展学习)
参考阅读博客:https://blog.csdn.net/yu616568/article/details/50993491
与ORC一样同为列存储,在存储Parquet数据的时候会按照Block大小设置行组的大小,由于一般情况下每一个Mapper任务处理数据的最小单位是一个Block,这样可以把每一个行组由一个Mapper任务处理,增大任务执行并行度。

九、调优
9.1、Fetch抓取
简单说就是Hive中对某些特定的查询情况(例如:select * …)是不使用MR计算的,这样可以大大提高查询的速度。
使用Select *,Hive可以直接去数据文件中抓取数据输出到控制台就行了,无须使用MapReduce任务。
在旧版本中,有一项参数需要设置才能达到这种效果。当前版本(1.2.2)默认已选择最优配置。
hive.fetch.task.conversion,在hive-default.xml.template中可以查看当前配置为more即最优的配置,可选的配置有none,minimal(旧版本默认)
<property>
<name>hive.fetch.task.conversionname>
<value>morevalue>
<description>
Expects one of [none, minimal, more].
Some select queries can be converted to single FETCH task minimizing latency.
Currently the query should be single sourced not having any subquery and should not have
any aggregations or distincts (which incurs RS), lateral views and joins.
0. none : disable hive.fetch.task.conversion
1. minimal : SELECT STAR, FILTER on partition columns, LIMIT only
2. more : SELECT, FILTER, LIMIT only (support TABLESAMPLE and virtual columns)
description>
property>
-
使用
none时,所有的查询语句都要走MR任务。 -
使用
minimal时,select *,对分区(partition)字段筛选,litmit查询不使用MR。 -
使用
more时,所有的普通select(不涉及函数计算),以及普通where字段筛选,limit查询,不使用MR。-- 设置为more时,以下查询都不会使用MR select * from aaa; select name,age from aaa where id=3; select name,age+2 from aaa where id<4; select name from aaa limit 4;
9.2、本地模式
在做案例练习时,使用set hive.exec.mode.local.auto=true;临时开启本地模式,将MR任务提交给本地Hadoop而不是集群的Yarn上执行,速度要快很多。但是并不是开启了本地模式就一定会走本地的Hadoop哦,还需要满足以下两个条件:
-
输入的数据量要小于
hive.exec.mode.local.auto.inputbytes.max(默认是134217728=128M) -
输入的文件数量要小于
hive.exec.mode.local.auto.input.files.max(默认是4)# 当Hadoop中表文件数量大于4时: Cannot run job locally: Number of Input Files (= 5) is larger than hive.exec.mode.local.auto.input.files.max(= 4)
以上两个参数均可以自行调整。
9.3、表的优化
9.3.1、大小表Join
在查询中,使用Join查询的时候会对表进行扫描,但是无意义反复多次的扫描又是浪费时间和消耗资源的,在MapReduce学习中MapJoin将小表缓存到了内存中,以加快扫描筛选的速度。通常小表在左,大表在右。==Hive在新版中已经默认对此进行优化,不需要再关心表的位置。==所以现在大小表即使交换位置也不会有很多差距。
9.3.2、大表Join
空值、数据过滤
在大表之间的Join过程中,每多一条无意义的数据就会多一次无意义的全表扫描。所以为了减少这种无谓的扫描,我们可以在Join之前就对表先进行过滤。将空值、不符合条件的值过滤掉,减小数据集提高查询效率。
空Key替换
在查询过程中也不可以盲目将空key直接过滤,可能其他数据对查询还有作用,但是如果不加以处理,一旦空key的数量很大时,这些所有的空key记录就会分配到同一个Reducer中去处理,这样就导致数据倾斜,在企业业务开发中是致命的!
所以在==遇到空Key要合理替换为可均匀分布的key(例如使用随机数),让这些空key记录在计算处理时,尽量摊分到各个Reducer上以避免数据倾斜的问题。==对空key的替换会使整个MapReduce的时间变长,但是为了稳定性是值得的。
9.3.3、MapJoin
相关参数:
hive.auto.convert.join=true,默认开启MapJoinhive.mapjoin.smalltable.filesize=25000000(25M),大小表的阈值,以文件大小25M为分界点
开启MapJoin后,在Map阶段对小表进缓存,大表扫描,避免进入Reduce阶段处理,容易发生数据倾斜。
9.3.4、Group By
默认情况下MR程序中,Map阶段输出数据中相同的Key都会汇总到一个Reducer中去处理,然而一旦某个(些)key的数量较大的时候,就会发生Reduce端的数据倾斜。
Hadoop中我们可以让Map阶段进行一次局部汇总(Combine),然后再将汇总后结果给Reduce处理。
所以,并不是所有的聚合操作都要放到Reduce中完成,也可以提前在Map中进行部分聚集,以减轻Reduce的压力。
开启Map端聚合的参数设置
-
hive.map.aggr=true:是否开启Map端聚合,默认开启(true) -
hive,groupby.mapaggr,checkinterval=100000:每次聚合的数据数 -
hive.groupby.skewindata=true:当数据产生倾斜的时候采用负载均衡(默认关闭false)当此参数配置为true时,当一个Reduce处理的数据量很大产生了数据倾斜的时候,执行查询会有两个MR任务。
第一个MR任务中Map阶段Mapper均匀读取分片数据,随机进行分区,随机分区中的数据由Reduce进行一次汇总,此时数据以及经历了一遍简单的汇总。由于第一次是随机分区并没有按照GroupBy的key值进行分区,所以就会出现相同的key在第一次MR中在不同的Reduce中处理。
第二个MR任务,利用已经汇总处理过的数据再按照GroupBy Key进行分区, 经过多次聚合后,数据量大大减小,数据倾斜的可能性也就随之降低。注意:只能对单个字段聚合。不支持多个字段的GroupBy
9.3.5、去重统计Count(distinct())
使用Count(distinct)去重统计列中值的数量。使用GroupBy也能达到相同效果。
count(distinct())存在的问题
一旦统计的列的数据量巨大,在启动MR任务时,Reduce要处理的数据巨大,就有可能导致MR任务久久不能完成,甚至直接失败。这样的情况在开发过程中十分危险。
但是正常情况下这种做法相对于使用GroupBy执行效率更高
使用GroupBy
使用GroupBy实现,还需要在外层套上一层count()查询,也就相应多一个Job,但是比较安全,在大数据量的情况下,这种时间的付出是值得的。
9.3.6、笛卡尔积
在前面Join中讲到了笛卡尔积产生的情况,一般是将其关闭,因为一旦出现意外查询中出现了笛卡尔积,数据量增长快,得到的数据量巨大。且计算笛卡尔会占用大量的计算资源。
9.3.7、行过滤,列过滤
**行过滤:**查询中做到提前进行数据过滤,精简数据集,减小查询时扫描表的无效扫描。
**列过滤:**查询中尽量写明要查询的字段,少使用select *,即使是要查询全列,也尽量写列名!;
9.3.8、动态分区
在使用普通静态分区的时候,分区字段由我们单独创建一个分区字段,并且在插入数据的时候,我们要指定数据的分区字段值,也就是说所有的数据分到哪个区有我们插入数据时自行决定。
动态分区恰好相反,使用动态分区的时候,我们指定数据中的一个列作为分区字段,这个列的数据种类(即可选值的数量)决定了最终分区的数量。并且在插入数据的时候,默认检查对应字段的值来决定数据归属到哪个分区中。
动态分区的相关参数
-
hive.exec.dynamic.partition=true:开启动态分区的功能(默认开启true) -
hive.exec.dynamic.parition.mode=nonstrict:设置为非严格模式(nonstrict),默认是严格模式(strict)即插入数据时要显式指明分区字段的值。 -
hive.exec.max.dynamic.partitions=1000:所有MR节点一共可创建的分区数量(默认1000) -
hive.exec.max.dynamic.partition.pernode=100:每个MR节点可创建的分区数量(默认100)一旦实际分区的数量超过总分区数量的限制,则会产生问题,注意设置。
-
hive.error.on.empty.partition=false:产生空分区时是否抛出异常(默认不开启false)
具体操作注意
创建表时,分区的字段不必写在基本字段列表中,直接使用partitioned by (col_name)即可。此后插入数据就会自动检测分区。下面来实操演示一下:
建表:
create table dynamic_partition(name string,age int)
partitioned by (grade string)
row format delimited
fields terminated by '\t';
-- 检查设置开启动态分区和非严格模式
hive (default)> set hive.exec.dynamic.partition;
hive.exec.dynamic.partition=true
hive (default)> set hive.exec.dynamic.partition.mode;
hive.exec.dynamic.partition.mode=strict
hive (default)> set hive.exec.dynamic.partition.mode=nonstrict;

这里有个注意点:分区字段默认在最后一列,所以之后插入数据的时候注意数据的顺序哦!
插入数据
此时使用insert或者load data都还是会要求指定分区,insert直接使用partition(grade)就可以啦!!load data无法从文本文件中提取分区列,所以不能使用load data…,下面分别演示使用insert导入数据。
insert导入数据
-- 普通表
create table stu_tmp(name string,age int,grade string)
row format delimited
fields terminated by '\t';
zhangsan 19 freshman
xiaoqiang 20 sophomore
liming 18 freshman
wanglei 22 junior
zhangli 22 senior
songyu 21 junior
chenkang 21 sophomore
liuyun 23 senior
-- 导入数据到动态分区表
insert overwrite table dynamic_partition partition(grade)
select * from stu_tmp;

上面的过程有一个很重要的注意点!就是关于插入数据的字段顺序。
虽然写了partition(grade),这只能说明分区的字段名叫grade,但是并不会去select的结果中找到grade列来创建分区,而是以动态分区表的字段顺序为标准。默认分区字段在最后,但是如果你插入的数据集最后一个列即使不是分区字段,它也会认为这一列数据就是用来分区的,就会出现这种情况
insert overwrite table dynamic_partition partition(grade)
select grade,age,name from dynamic_partition;
/*
插入数据集最后一个字段是name,但是hive并不知道,只好硬生用name也做了分区:
Loading partition {grade=liming}
Loading partition {grade=chenkang}
Loading partition {grade=liuyun}
Loading partition {grade=xiaoqiang}
Loading partition {grade=zhangli}
*/
所以导入数据的时候千万莫要搞错了字段的顺序。
除此以外insert into也是可以插入数据的,但是效率较低:
insert into table dynamic_partition partition(grade) values('zhangqiang',19,'freshman');
9.4、MR优化
可以参考Hadoop-MapReduce学习笔记中MR调优的内容。
Map端调优
- 合理调整Map的数量
- 结合数据集设置合适的分区大小(参考MapReduce学习文件中分区大小设置)
- 其他相关的调优参数设置
Reduce调整
-
Reduce数量的设置
Reduce的数量受多个情况的控制,优先级依次为
- 查询语句中使用了
distinct、order by:强制使用一个Reduce - 手动参数设置:
set mapreduce.job.reduces = n mapreduce.job.reduces默认值:-1表示按任务自动设置,自动配置涉及以下参数- 每个Reduce处理的数据量
hive.exec.reducers.bytes.per.reducer=256000000默认256M - 每个Job的最大Reduce数量
hive.exec.reducers.max=1009默认1009 - 自动计算reduce个数:
min(reducers最大值, job的总数据输入量/每个reducer处理的数据量)
- 每个Reduce处理的数据量
- 查询语句中使用了
-
其他资源调优参数
9.5、其他调优
并行执行
有时候HIve执行一次查询的时候,提交的任务分为多个阶段,有可能这些阶段在数据上并不相互依赖,可以开启并行模式让各个阶段并行执行,以缩短整个的任务的完成实际。但是每个阶段的MR任务中只能顺序执行
- 开启并行模式:
set hive.exec.parallel=true - 设置最大并行数量:
set hive.exec.parallel.thread.number=n默认值为8。
并行模式只有在资源比较空闲的时候开启才能有比较明显的速度优势,当资源紧张的时候,即使开启了并行模式也没法并行执行。
严格模式
这里的严格模式和动态分区的严格模式是两个范围。此处的严格模式是全局的严格模式hive.mapred.mode,默认是非严格模式nonstrict
<property>
<name>hive.mapred.modename>
<value>nonstrictvalue>
<description>
The mode in which the Hive operations are being performed.
In strict mode, some risky queries are not allowed to run. They include:
Cartesian Product.
No partition being picked up for a query.
Comparing bigints and strings.
Comparing bigints and doubles.
Orderby without limit.
description>
property>
开发场景下,我们通常将其设置为严格模式(strict),严格模式下以下操作是不允许的:
- 笛卡尔积
- 查询分区表时不指定分区
- 比较bigints和string数据、比较bigints和double数据
- 使用OrderBy时不使用limit
JVM重用、推测执行(参考MapReduce学习笔记)
适当情况下开启JVM重用和推测执行能够提高任务的执行效率。但是并不是只要开启了就一定能提高性能!
性能分析语句
explain
使用explain对SQL进行执行过程性能分析,我们能够详细看到任务执行过程中做了哪些事情。
创建的分区数量(默认100)
一旦实际分区的数量超过总分区数量的限制,则会产生问题,注意设置。
hive.error.on.empty.partition=false:产生空分区时是否抛出异常(默认不开启false)
具体操作注意
创建表时,分区的字段不必写在基本字段列表中,直接使用partitioned by (col_name)即可。此后插入数据就会自动检测分区。下面来实操演示一下:
建表:
create table dynamic_partition(name string,age int)
partitioned by (grade string)
row format delimited
fields terminated by '\t';
-- 检查设置开启动态分区和非严格模式
hive (default)> set hive.exec.dynamic.partition;
hive.exec.dynamic.partition=true
hive (default)> set hive.exec.dynamic.partition.mode;
hive.exec.dynamic.partition.mode=strict
hive (default)> set hive.exec.dynamic.partition.mode=nonstrict;
[外链图片转存中…(img-7ZA9NnfR-1596510182171)]
这里有个注意点:分区字段默认在最后一列,所以之后插入数据的时候注意数据的顺序哦!
插入数据
此时使用insert或者load data都还是会要求指定分区,insert直接使用partition(grade)就可以啦!!load data无法从文本文件中提取分区列,所以不能使用load data…,下面分别演示使用insert导入数据。
insert导入数据
-- 普通表
create table stu_tmp(name string,age int,grade string)
row format delimited
fields terminated by '\t';
zhangsan 19 freshman
xiaoqiang 20 sophomore
liming 18 freshman
wanglei 22 junior
zhangli 22 senior
songyu 21 junior
chenkang 21 sophomore
liuyun 23 senior
-- 导入数据到动态分区表
insert overwrite table dynamic_partition partition(grade)
select * from stu_tmp;
[外链图片转存中…(img-PgIAcN6L-1596510182171)]
上面的过程有一个很重要的注意点!就是关于插入数据的字段顺序。
虽然写了partition(grade),这只能说明分区的字段名叫grade,但是并不会去select的结果中找到grade列来创建分区,而是以动态分区表的字段顺序为标准。默认分区字段在最后,但是如果你插入的数据集最后一个列即使不是分区字段,它也会认为这一列数据就是用来分区的,就会出现这种情况
insert overwrite table dynamic_partition partition(grade)
select grade,age,name from dynamic_partition;
/*
插入数据集最后一个字段是name,但是hive并不知道,只好硬生用name也做了分区:
Loading partition {grade=liming}
Loading partition {grade=chenkang}
Loading partition {grade=liuyun}
Loading partition {grade=xiaoqiang}
Loading partition {grade=zhangli}
*/
所以导入数据的时候千万莫要搞错了字段的顺序。
除此以外insert into也是可以插入数据的,但是效率较低:
insert into table dynamic_partition partition(grade) values('zhangqiang',19,'freshman');
9.4、MR优化
可以参考Hadoop-MapReduce学习笔记中MR调优的内容。
Map端调优
- 合理调整Map的数量
- 结合数据集设置合适的分区大小(参考MapReduce学习文件中分区大小设置)
- 其他相关的调优参数设置
Reduce调整
-
Reduce数量的设置
Reduce的数量受多个情况的控制,优先级依次为
- 查询语句中使用了
distinct、order by:强制使用一个Reduce - 手动参数设置:
set mapreduce.job.reduces = n mapreduce.job.reduces默认值:-1表示按任务自动设置,自动配置涉及以下参数- 每个Reduce处理的数据量
hive.exec.reducers.bytes.per.reducer=256000000默认256M - 每个Job的最大Reduce数量
hive.exec.reducers.max=1009默认1009 - 自动计算reduce个数:
min(reducers最大值, job的总数据输入量/每个reducer处理的数据量)
- 每个Reduce处理的数据量
- 查询语句中使用了
-
其他资源调优参数
9.5、其他调优
并行执行
有时候HIve执行一次查询的时候,提交的任务分为多个阶段,有可能这些阶段在数据上并不相互依赖,可以开启并行模式让各个阶段并行执行,以缩短整个的任务的完成实际。但是每个阶段的MR任务中只能顺序执行
- 开启并行模式:
set hive.exec.parallel=true - 设置最大并行数量:
set hive.exec.parallel.thread.number=n默认值为8。
并行模式只有在资源比较空闲的时候开启才能有比较明显的速度优势,当资源紧张的时候,即使开启了并行模式也没法并行执行。
严格模式
这里的严格模式和动态分区的严格模式是两个范围。此处的严格模式是全局的严格模式hive.mapred.mode,默认是非严格模式nonstrict
<property>
<name>hive.mapred.modename>
<value>nonstrictvalue>
<description>
The mode in which the Hive operations are being performed.
In strict mode, some risky queries are not allowed to run. They include:
Cartesian Product.
No partition being picked up for a query.
Comparing bigints and strings.
Comparing bigints and doubles.
Orderby without limit.
description>
property>
开发场景下,我们通常将其设置为严格模式(strict),严格模式下以下操作是不允许的:
- 笛卡尔积
- 查询分区表时不指定分区
- 比较bigints和string数据、比较bigints和double数据
- 使用OrderBy时不使用limit
JVM重用、推测执行(参考MapReduce学习笔记)
适当情况下开启JVM重用和推测执行能够提高任务的执行效率。但是并不是只要开启了就一定能提高性能!
性能分析语句
explain
使用explain对SQL进行执行过程性能分析,我们能够详细看到任务执行过程中做了哪些事情。