Java集合的深入学习
一、Java集合
List:有序可重复集合;
Set:无序不重复集合;
Map:键值对存储,key必须唯一,只有一个key可以为null,value可以有多个null,使用key来搜索value;
测试Map中key为null,而value不为null
@Test
public void test1() {
Map<String, String> map = new HashMap<>();
map.put(null, "kenewstar");
System.out.println(map.get(null));
}
结果如下图:

1.ArrayList与LinkedList
① 两者都是线程不安全的集合;
② 底层数据结构的不同,ArrayList使用Object[]数组存储,LinkedList使用双向链表存储,JDK1.6之前为循环链表,JDK1.7取消了循环链表;
③ 操作优劣,ArrayList使用数组存储,因此查询速度快,插入,删除速度慢,因为需要移动元素的位置,主要是指从指定位置插入删除速度,从末尾添加元素时间复杂度为O(1),LinkedList使用链表存储,因此添加,删除速度快,无需移动元素即可完成,而查询速度慢,每次查询某个元素都需要从头部节点或尾部节点开始遍历,直到查找到指定元素;
④ 内存空间占用比较,ArrayList使用数组存储,列表后面总是需要预留一部分空间,造成空间浪费,LinkedList的每个元素所占用的空间总是要比ArrayList每个元素的空间大,因为它需要存储前一个节点的位置和后一个节点的位置,从而占用了较多的空间;
2.ArrayList与Vector
ArrayList与Vector一样都是使用Object[]数组作为底层数据结构,但是ArrayList的方法不是同步的,因此是线程不安全的集合,而Vector的每个方法都是同步的,因此是线程安全的,但是当有多个线程同时访问Vector时,只能有一个线程访问它,其他线程只能等待它完成,因此非常耗时;
因此当操作不需要保证线程安全时使用ArrayList比较合适;
3.HashMap与Hashtable
① 线程安全,HashMap是线程不安全的,Hashtable是线程安全的,Hashtable的每个方法都被synchronized修饰,每个方法都是同步的,但是效率低下,因此HashMap是效率比较高,但是线程不安全,Hashtable目前已被淘汰,可使用ConcurrentHashMap替代它;
② HashMap可以有null键,但是在Hashtable不能有null做为键,否则会报NPE即NullPointException空指针异常;
③ 初始容量与扩容大小,创建时如果不指定容量大小,则会使用默认大小,Hashtable默认初始容量大小为11,扩容为2n+1,HashMap默认初始容量大小为16,扩容为2n,若给定初始容量大小Hashtable则直接使用给定的值,HashMap将其扩充为2的幂次方大小,也就是 HashMap 总是使用2的幂作为哈希表的大小;
④ 底层数据结构,JDK1.8之后HashMap中当链表的长度大于阈值(默认8),则将链表转化为红黑树,以减少搜索时间;
HashMap源码(JDK11):
中文注释是我自己加上去的
static final float DEFAULT_LOAD_FACTOR = 0.75f;
static final int TREEIFY_THRESHOLD = 8;
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // 默认初始容量: 16
static final int MAXIMUM_CAPACITY = 1 << 30; //最大容量大小
//initialCapacity:初始容量大小
//loadFactor:负载因子
public HashMap(int initialCapacity, float loadFactor) {
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal initial capacity: " +
initialCapacity);
//初始容量大于最大容量大小则使用最大容量
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
//负载因子不能为负,不能为非Number类型
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal load factor: " +
loadFactor);
//使用给定大小
this.loadFactor = loadFactor;
this.threshold = tableSizeFor(initialCapacity);
}
public HashMap(int initialCapacity) {
this(initialCapacity, DEFAULT_LOAD_FACTOR);
}
public HashMap() {
this.loadFactor = DEFAULT_LOAD_FACTOR; //默认负载因子:0.75
}
//保证HashMap总是使用2的幂作为哈希表的大小
static final int tableSizeFor(int cap) {
int n = -1 >>> Integer.numberOfLeadingZeros(cap - 1);
return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;
}
4.HashMap与HashSet

如上图中HashSet的源码中,HashSet底层是基于HashMap实现的,因此HashSet是无序的,不重复的,因为HashMap中的键不能重复,且Map中的元素没有顺序,因此HashSet的默认大小就是HashMap的默认大小为16,HashMap使用键计算HashCode,HashSet使用成员对象计算HashCode值,对于两个对象来说HashCode可能相同,因此使用equals()方法用来判断对象的相等;
5.HashSet检查重复
当HashSet添加元素时,HashSet会先计算元素的HashCode值是否在集合中已存在,若不存在,则直接加入,若HashCode值已存在,则使用equals方法判断HashCode相同的两个元素的值是否相等,如果值相等则元素加入失败,也就是不能有重复元素;
①如果两个对象相等,则HashCode一定相等
②两个对象相等,则equals方法返回为true
③如果两个对象的HashCode相等,对象不一定相等
6.HashMap底层实现
JDK1.8之前使用的是数组加链表结合在一起的链表散列,HashMap通过key的HashCode经过扰动函数处理过后得到Hash值,然后通过(n-1)&hash判断当前元素存放的位置(这里的n指的是数组的长度),如果当前位置存在元素,就判断该元素与添加的元素的hash值以及key是否相同,如果相同,直接覆盖,不相同就通过拉链法解决冲突。扰动函数指HashMap的hash方法,使用hash方法是为了防止实现比较差的hashCode()方法为了减少碰撞;
JDK1.8的HashMap的hash()源码:
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
拉链法,即将链表和数组结合,也就是创建一个链表数组,数组中的每一格就是一个链表,若遇到哈希冲突,则将冲突的值加到链表中即可;
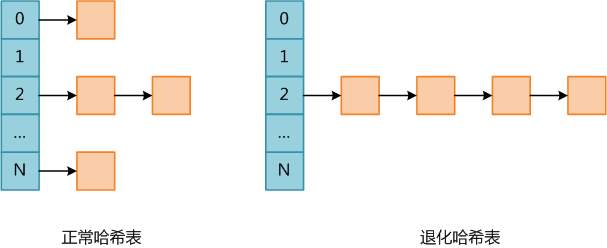
JDK1.8之后的哈希表
相比JDK1.8之前,JDK1.8之后在解决哈希冲突时有了较大的变化,当链表大于阈值(默认为8)时,将链表转化为红黑树,以减少搜索时间。
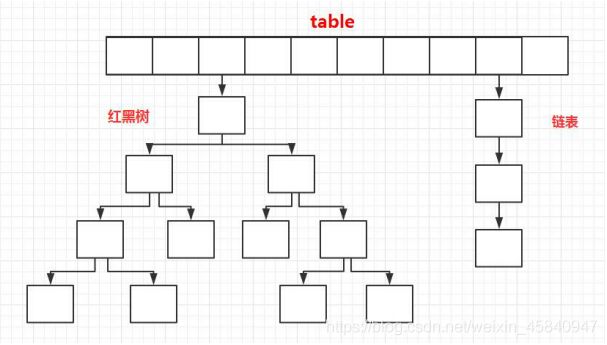
7.HashMap的长度
为了能让 HashMap 存取高效,尽量较少碰撞,也就是要尽量把数据分配均匀。我们上面也讲到了过了,Hash 值的范围值-2147483648到2147483647,前后加起来大概40亿的映射空间,只要哈希函数映射得比较均匀松散,一般应用是很难出现碰撞的。但问题是一个40亿长度的数组,内存是放不下的。所以这个散列值是不能直接拿来用的。用之前还要先做对数组的长度取模运算,得到的余数才能用来要存放的位置也就是对应的数组下标。这个数组下标的计算方法是“ (n - 1) & hash ”。(n代表数组长度)。这也就解释了 HashMap 的长度为什么是2的幂次方。
这个算法应该如何设计呢?
我们首先可能会想到采用%取余的操作来实现。但是,重点来了:“取余(%)操作中如果除数是2的幂次则等价于与其除数减一的与(&)操作(也就是说 hash%length==hash&(length-1)的前提是 length 是2的 n 次方;)。” 并且 采用二进制位操作 &,相对于%能够提高运算效率,这就解释了 HashMap 的长度为什么是2的幂次方。
因为 n 永远是2的次幂,所以 n-1 通过 二进制表示,永远都是尾端以连续1的形式表示(00001111,00000011)
当(n - 1) 和 hash 做与运算时,会保留hash中 后 x 位的 1,
例如 00001111 & 10000011 = 00000011
这样做有2个好处
① &运算速度快,至少比%取模运算块
② 能保证 索引值 肯定在 capacity 中,不会超出数组长度
③ (n - 1) & hash,当n为2次幂时,会满足一个公式:(n - 1) & hash = hash % n
8.ConcurrentHashMap与Hashtable
两者的区别在于实现线程安全的方式不一样;
①底层数据结构,JDK1.7的ConcurrentHashMap底层采用分段的数组+链表实现,JDK1.8采用的结构与HashMap的结构一样,数组+链表/红黑树,Hashtable和JDK1.8之前的HashMap底层数据结构类似都是采用数组+链表的形式,数组是HashMap的主体,链表则是为了解决哈希冲突而存在的;
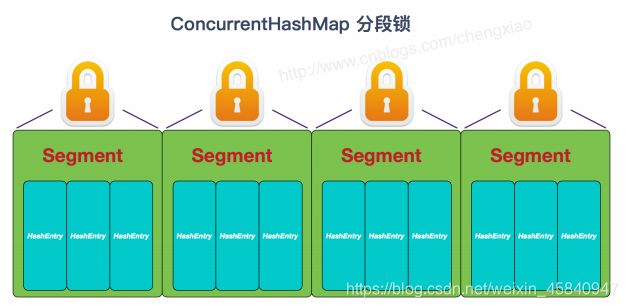
②线程安全的实现方式,JDK1.7时,ConcurrentHashMap使用了分段锁,对整个桶数组进行分段(Segment),每个锁只锁定容器中的一部分数据,即锁段,多线程访问容器里不同数据段的数据时,不会存在锁竞争,提高并发访问率;JDK1.8摒弃了Segment的概念,而是直接用Node数组+链表+红黑树来实现,并发控制使用synchronized和CAS来操作。
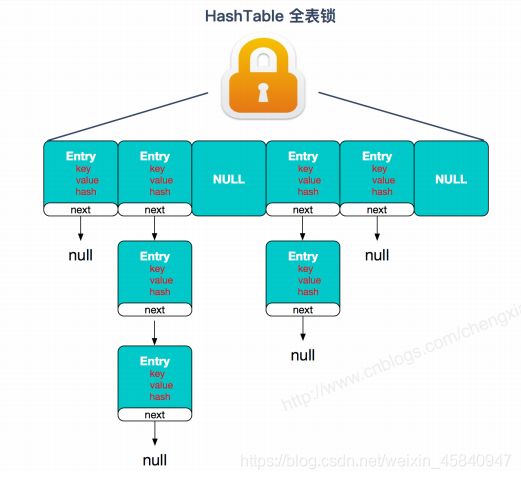
③Hashtable,使用synchronized来保证线程安全,效率非常低,当一个线程访问同步方法时,其他线程也访问同步方法,可能会进入阻塞或轮询状态,例如,另一个线程则不能使用put,get方法向集合中添加或者获取值;
Hashtable
JDK1.7的ConcurrentHashMap
JDK1.8的ConcurrentHashMap
TreeBin:红黑二叉树节点
Node:链表节点
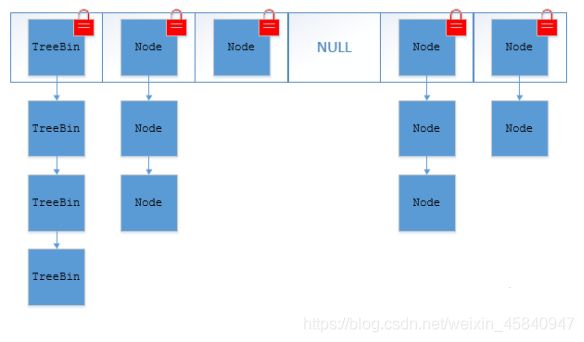
9.ConcurrentHashMap线程实现方式
JDK1.7
将数据分段存储,给每个段加一把锁,当一个线程占用锁访问其中一个段数据时,其他段的数据也能被其他线程访问。ConcurrentHashMap是由Segment数组结构和HashEntry数组结构组成,Segment实现了ReentrantLock,所以Segment是一种可重入锁;
一个ConcurrentHashMap里面包含一个Segment数组,Segment的结构和HashMap类似,是一种数组和链表结构,一个Segment包含一个HashEntry数组,每个HashEntry是一个链表结构的元素,每个Segment守护着一个HashEntry数组里的元素,当对HashEntry数组数据修改时,必须先获得对应的Segment的锁;
JDK1.8
ConcurrrentHashMap取消了分段锁,采用CAS+synchronized来保证并发安全。数据结构和HashMap类似,数组+链表/红黑树;JDK1.8在链表长度超过一定阈值(8)时,将链表转换成红黑树,时间复杂度由O(n)–>O(log(N)),synchronized只锁定当前链表或红黑树的首节点,只要hash不冲突,就不会产生并发;
10.总结
① List
ArrayList--------->Object数组实现
Vector------------ >Object数组实现
LinkedList-------->双向链表,JDK1.6之前为循环链表
② Set
HashSet(无序,唯一)—>基于HashMap实现
LinkedHashSet----------->基于HashSet,其内部是基于LinkedHashMap实现
TreeSet(有序,唯一)----->红黑树(自平衡的排序二叉树)
③ Map
HashMap
JDK1.7---->由数组+链表组成;
JDK1.8---->阈值大于8s时,链表转变成红黑树,减少搜索时间
LinkedHashMap
继承自HashMap,在HashMap 基础上,增加一条双向链表
Hashtable----->数组+链表
TreeMap-------->红黑树(自平衡的排序二叉树)
HashMap
JDK1.7---->由数组+链表组成;
JDK1.8---->阈值大于8s时,链表转变成红黑树,减少搜索时间
LinkedHashMap
继承自HashMap,在HashMap 基础上,增加一条双向链表
Hashtable----->数组+链表
TreeMap-------->红黑树(自平衡的排序二叉树)