Java泛型学习笔记
目录
- 1. 泛型的作用
- 2. 泛型类
- 3. 泛型接口
- 4. 泛型方法
- 5. 泛型擦除
- 5.1 擦除是什么?
- 5.2 擦除的代价
- 5.3 边界处的动作
- 6. 边界
- 7. 通配符
- 7.1 协变
- 7.2 逆变
- 7.3 无界通配符
- 参考
1. 泛型的作用
Java 中的泛型是在 Java 1.5以后引入的。它主要有两个作用:
-
泛型通过使用参数化类型的概念,使代码可以应用于多种类型,可以理解“泛型”这个术语的意思是:“适用于许多许多的类型”,这其实就是提高了代码的可重用性。
下面通过代码说明一下:
这是PointInt.java类,它存放两个int类型的变量:x,y。public class PointInt { private int x; private int y; public PointInt(int x, int y) { this.x = x; this.y = y; } public int getX() { return x; } public void setX(int x) { this.x = x; } public int getY() { return y; } public void setY(int y) { this.y = y; } }这里是
PointFloat.java类,它存放了两个float类型的变量:x,y。public class PointFloat { private float x; private float y; public PointFloat(float x, float y) { this.x = x; this.y = y; } public float getX() { return x; } public void setX(float x) { this.x = x; } public float getY() { return y; } public void setY(float y) { this.y = y; } }可以看到,上面的两个类,除了变量类型一个是
int,一个是float之外,没有任何区别了。那么,我们可能会考虑使用一个参数形式的类型,代表可能传入的类型,如int,float等,也就是说,在使用这一种参数形式的类型时,我们可以传入int,float,这种参数形式的类型就可以接收int,float等。事实上,这是可行的,这就是参数化类型的概念。需要特别说明的是,方法中的形式参数的输入是值,而泛型的类型参数需要输入的是类型。代码如下:
public class Point<T> { private T x; private T y; public Point(T x, T y) { this.x = x; this.y = y; } public T getX() { return x; } public void setX(T x) { this.x = x; } public T getY() { return y; } public void setY(T y) { this.y = y; } }下边是测试代码:
public class Test { public static void main(String[] args) { Point<Integer> integerPoint = new Point<>(1, 2); System.out.println("x = " + integerPoint.getX() + ", y = " + integerPoint.getY()); Point<Float> floatPoint = new Point<>(1f, 2f); System.out.println("x = " + floatPoint.getX() + ", y = " + floatPoint.getY()); } } /* 打印結果: x = 1, y = 2 x = 1.0, y = 2.0 */在上面的例子中,在类名
Point之后,跟着一个尖括号(<>),尖括号里面的T就是类型参数(Type parameter)(也称为类型变量),这样我们就定义了一个泛型类。这里需要注意的一点是,传入
T的具体类型,不能是int或float,而应该是Integer和Float。这是因为 Java 泛型的一个局限性:基本类型无法作为类型参数。可以看到,新的
Point.java类完全可以替代原来的PointInt.java和PointFloat.java两个类,这样我们使用一份代码,同时适用于int和float两种类型。 -
泛型通过在使用时指定实际的类型能够把运行期可能出现的类型转换异常,提前到编译期处理(这是因为编译器会执行额外的类型检查),起到了提前预防代码错误的作用;也避免了强制类型转换。
这里我们通过ArrayList这个容器类的使用来说明:public class ArrayListNonGenericTest { public static void main(String[] args) { // 这是一个存放 String 数据的集合 ArrayList nonGenericStringList = new ArrayList(); nonGenericStringList.add("hello"); nonGenericStringList.add("hi"); // 一个无心的程序员却存入了 int 类型,但是编译器没有任何提示 nonGenericStringList.add(1); // 另外一个程序员,看到这个 nonGenericStringList,知道这是一个 // 存放 String 数据的集合,就想看看这里面都有哪些元素。 for (int i = 0; i < nonGenericStringList.size(); i++) { String e = (String) nonGenericStringList.get(i); System.out.println("e = " + e); } } } /* 打印结果: e = hello e = hi Exception in thread "main" java.lang.ClassCastException: java.base/java.lang.Integer cannot be cast to java.base/java.lang.String at com.java.advanced.features.generics.intro.ArrayListNonGenericTest.main(ArrayListNonGenericTest.java:17) */可以看到由于在大家认为是存放
String类型的集合中,存入了int类型,而在遍历时取出元素时,需要强转成String类型时,发生了把int类型去转换成String类型的类型转换异常。这种错误通过使用泛型,是可以避免的。代码如下:public class ArrayListGenericTest { public static void main(String[] args) { // 这是一个存放 String 数据的集合 ArrayList<String> genericStringList = new ArrayList(); genericStringList.add("hello"); genericStringList.add("hi"); // 一个无心的程序员意图存入了 int 类型,但是编译器会报错: // add (java.lang.String) in ArrayList cannot be applied to (int) // 这就起到了提前预防的作用 // genericStringList.add(1); // 另外一个程序员,看到这个 nonGenericStringList,知道这是一个 // 存放 String 数据的集合,就想看看这里面都有哪些元素。 for (int i = 0; i < genericStringList.size(); i++) { // 取出元素时,无需再做强转 // String e = (String) genericStringList.get(i); String e = genericStringList.get(i); System.out.println("e = " + e); } } } /* 打印结果: e = hello e = hi */上面的代码有两点需要注意:第一,我们在定义集合时,就指定了这是一个存放
String的集合,这样在存入意外的int类型时,编译器就马上提示出类型不匹配的错误;第二,在从集合中取出它持有的元素时,自动地就是正确的类型,即String类型,而无需再去手动做强转的操作了。
2. 泛型类
我们通过一个 Holder.java 的泛型类来说明一下:
class Food { }
class Fruit extends Food {}
class Apple extends Fruit {}
class Rice extends Food {}
public class Holder<T> {
private T a;
public Holder(T a) {
this.a = a;
}
public T get() {
return a;
}
public void set(T a) {
this.a = a;
}
public static void main(String[] args) {
Holder<Fruit> fruitHolder = new Holder<>(new Fruit());
fruitHolder.set(new Fruit());
fruitHolder.set(new Apple());
// 编译报错:需要的是 Fruit 类型,但是传入的是 Food 类型
// fruitHolder.set(new Food());
// 编译报错:需要的是 Fruit 类型,但是传入的是 Rice 类型
// fruitHolder.set(new Rice());
}
}
上面的例子中一些类的继承关系如下图:
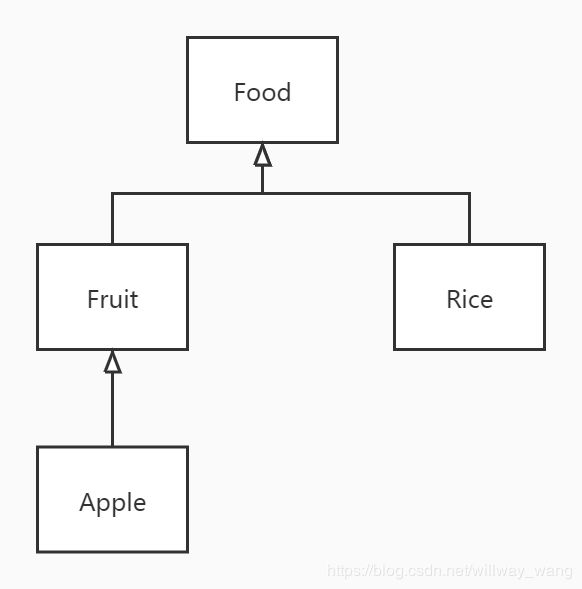
定义一个泛型类,就需要把类型参数,用尖括号括起来,放在类名的后面。可以看代码,这里我们是把类型参数 T,用尖括号<>括起来放在了类名 Holder 后面。
在使用泛型类时,使用实际的类型替换参数类型。在这里,我们使用 Fruit 这个实际的类型替换了参数类型 T。那么,在构造方法中我们可以传入哪些对象呢?我们只能传入实际的类型(或其子类)。具体到我们的例子,我们可以传入 Fruit 对象,还有 Fruit 的子类 Apple 对象(为什么还可以传入子类对象呢?这是因为多态与泛型不冲突)。
正如我们使用函数时的参数列表可以有多个一样,泛型类的类型参数也可以有多个,并且仍然是使用逗号隔开。这里我们举一个二元的元组的例子:
public class TwoTuple<A, B> {
public final A first;
public final B second;
public TwoTuple(A first, B second) {
this.first = first;
this.second = second;
}
@Override
public String toString() {
return "(" +
"first=" + first +
", second=" + second +
')';
}
}
当然,对于三元元组,四元元组等,只需要添加更多的类型参数就可以了。
可能不少人对于类型参数的命名有点疑问,是不是只能用大写字母啊?有没有什么规范啊?
实际上,只要符合变量命名规范,都是合法的,也不限于单个字母。但是,这里面为了提高可读性,有一些约定的命名:
- E,代表 Element,集合中的元素,常见在集合类中,举例:
List,ArrayList; - K, V 代表 Key-Value 键值对,Map 中的键值对,举例:
Map; - T,代表 Type,类型;
- N,代表 Number,数字。
我们可以从源码里面看一下,大神们都是怎么用命名泛型变量的:
- Android 中处理异步任务的
AsyncTask类:public abstract class AsyncTask<Params, Progress, Result> - Retrofit2 中的
HttpServiceMethod类:abstract class HttpServiceMethod<ResponseT, ReturnT> extends ServiceMethod<ReturnT> - Android 中的
Pair类,用于表示一个 2 维元组:public class Pair<F, S> - RxJava2 中的
SingleOperator类:public interface SingleOperator<Downstream, Upstream>
从这些源码中的泛型变量的命名中,可以得到结论:对于泛型类型参数的命名并非只能是单个的大写字母,只要表达的含义清楚明白就行。
3. 泛型接口
我们通过一个生成器接口来说明:
public interface Generator<T> {
T next();
}
可以看到,接口使用泛型与类使用泛型没有什么区别。
在实现泛型接口时,有两种实现方式:
这里我们还是通过实现 Generator 接口来进行说明
-
泛型类的方式
class A { private static int count; private final int i = count++; @Override public String toString() { return "A " + i; } } class B { private static int count; private final int i = count++; @Override public String toString() { return "B " + i; } } public class GenericGeneratorImpl<T> implements Generator<T> { // 变量 type 是一个 Class 引用,它指向某个 Class 对象,比如 int.class, String.class 等 private Class<T> type; public GenericGeneratorImpl(Class<T> type) { this.type = type; } @Override public T next() { try { // 注意如果 type 没有默认的构造器,那么此处调用它的 newInstance() 方法,会抛出异常。 return type.newInstance(); } catch (Exception e) { throw new RuntimeException(e); } } // 这是一个泛型方法 public static <T> Generator<T> create(Class<T> type) { return new GenericGeneratorImpl<>(type); } public static void main(String[] args) { Generator<A> generator = GenericGeneratorImpl.create(A.class); for (int i = 0; i < 5; i++) { System.out.println(generator.next()); } Generator<B> bGenerator = GenericGeneratorImpl.create(B.class); for (int i = 0; i < 3; i++) { System.out.println(bGenerator.next()); } } } /* 打印结果: A 0 A 1 A 2 A 3 A 4 B 0 B 1 B 2 */上面的例子中,使用
GenericGeneratorImpl泛型类实现了泛型接口Generator。在实例化GenericGeneratorImpl时,我们分别传递了类型实参为A和B。 -
非泛型类的方式
public class NonGenericGeneratorImpl implements Generator<Integer> { private Random random = new Random(32); @Override public Integer next() { return random.nextInt(100); } public static void main(String[] args) { NonGenericGeneratorImpl nonGenericGenerator = new NonGenericGeneratorImpl(); for (int i = 0; i < 5; i++) { System.out.println(nonGenericGenerator.next()); } } } /* 打印结果: 77 31 85 41 39 */
那么,泛型类的方式和非泛型类的方式有什么区别呢?或者在实际开发中该如何选用呢?
区别:泛型类的方式在创建类的实例时,必须需要指定实际的类型;而非泛型类的方式在创建类的实例时,和普通的类是一样的;
选择:泛型类的方式可以让调用者(也可以说是客户)来决定传入哪种实际的类型,而非泛型的方式则相当于是直接写死了,不给客户留有选择的余地。
4. 泛型方法
在类中包含的参数化方法,就是泛型方法。需要注意的是,泛型方法的标志是这个方法拥有自己定义的泛型参数。是不是泛型方法,与它所在的类是泛型类,还是非泛型类,没有任何关系。
public class GenericMethods {
public <T> void f(T x) {
System.out.println(x.getClass().getName());
}
public static void main(String[] args) {
GenericMethods genericMethods = new GenericMethods();
genericMethods.f("Hello");
genericMethods.f(1);
genericMethods.f(true);
// 显式的类型说明,那么括号里只能传入声明的类型
genericMethods.<Double>f(1.0D);
}
}
定义泛型方法,就需要将泛型参数列表,即上面例子中的
从上面的例子可以看出:
泛型方法能够使得方法独立于类而产生变化,也就是说,泛型方法使用什么实际的类型与它所在的类没有任何关系。
使用泛型方法时,可以不必指定参数类型,因为编译器会推断出具体的类型,这就是类型参数推断(type argument inference)。而使用泛型类,则必须在创建对象的时候指定类型参数的值。这是一个区别的地方。
为什么说泛型方法能够使得方法独立于类而产生变化?这里通过在泛型类中定义的泛型方法来说明一下:
public class GenericClassGenericMethod<T> {
private T x;
public GenericClassGenericMethod(T x) {
this.x = x;
}
// 这是个普通方法,只不是使用了泛型参数而已
public T e(T t) {
return t;
}
// 这是个泛型方法,因为它自己定义了泛型参数列表 和 GenericClassGenericMethod 后面的 没有任何关系
// 但是泛型方法定义的泛型参数和所在类的泛型参数用一样的字母,是不好的写法。
public <T> T f(T t) {
return t;
}
// 这是个泛型方法,它自己定义了泛型参数列表下面举一个泛型方法与可变参数列表结合的例子:
public class GenericMethodVarargs {
public static <T> List<T> toList(T... args) {
List<T> result = new ArrayList<>();
for (T item : args) {
result.add(item);
}
return result;
}
public static void main(String[] args) {
System.out.println(GenericMethodVarargs.toList(1, 2, 3, 4));
System.out.println(GenericMethodVarargs.toList("a", "b", "c", "d", "e"));
// 在这里,可以体会显式的类型说明的作用
// 本来,我们是传入一个都是 String 类型元素的可变参数列表,但是有一个不和谐的 int 类型:88,也被传入了,但是编译器没有提示出问题。
System.out.println(GenericMethodVarargs.toList("h", "e", "l", "l", "o", 88));
// 如果采用显式的类型说明,编译器就会给出出错的提示: 期望的是 String 类型元素的可变参数列表,但是实际上里面包含了 int 类型。
// System.out.println(GenericMethodVarargs.toList("h", "e", "l", "l", "o", 88));
}
}
/*
打印结果:
[1, 2, 3, 4]
[a, b, c, d, e]
[h, e, l, l, o, 88]
*/
5. 泛型擦除
5.1 擦除是什么?
通过下面的代码来进行演示:
public class ErasedTypeEquivalence {
public static void main(String[] args) {
Class c1 = new ArrayList<String>().getClass();
Class c2 = new ArrayList<Integer>().getClass();
System.out.println("c1 = " + c1);
System.out.println("c2 = " + c2);
System.out.println("c1 == c2: " + (c1 == c2));
}
}
/*
打印结果:
c1 = class java.util.ArrayList
c2 = class java.util.ArrayList
c1 == c2: true
*/
ArrayList 是存放 String 类型的集合,ArrayList 是存放 Integer 类型的集合。我们不能把一个 String 放入 ArrayList 中,同样地,我们也不能把一个 Integer 放入 ArrayList 中。
因此,我们有理由认为 ArrayList 和 ArrayList 是不同的类型。但是,程序的输出结果却表明它们是相同的类型。
查看一下对应的 ErasedTypeEquivalence.class 文件,可以看到尖括号不见了:
//
// Source code recreated from a .class file by IntelliJ IDEA
// (powered by Fernflower decompiler)
//
package com.java.advanced.features.generics.genericerase;
import java.util.ArrayList;
public class ErasedTypeEquivalence {
public ErasedTypeEquivalence() {
}
public static void main(String[] var0) {
Class var1 = (new ArrayList()).getClass();
Class var2 = (new ArrayList()).getClass();
System.out.println("c1 = " + var1);
System.out.println("c2 = " + var2);
System.out.println("c1 == c2: " + (var1 == var2));
}
}
这是什么原因呢?
先留着这个问题,我们再看一个例子:
class Pair<First, Second> {
}
public class MissingInformation {
public static void main(String[] args) {
List<String> list = new ArrayList<>();
Map<String, Integer> map = new HashMap<>();
Pair<Integer, Integer> pair = new Pair<>();
System.out.println(Arrays.toString(list.getClass().getTypeParameters()));
System.out.println(Arrays.toString(map.getClass().getTypeParameters()));
System.out.println(Arrays.toString(pair.getClass().getTypeParameters()));
}
}
/*
打印结果:
[E]
[K, V]
[First, Second]
*/
Class.getTypeParameters() 的作用是返回一个 TypeVariable 数组,表示由泛型声明所声明的类型参数。TypeVariable 是一个接口,它的实现类是 TypeVariableImpl。打印出的信息是通过 TypeVariable 的 String getName(); 方法获取的。而 getName() 方法仅仅是返回用作参数占位符的标识符。其实,我们想要获取的是替换了类型参数的实际类型,如String,Integer。
这又是什么原因呢?
这都是因为 Java 泛型使用擦除来实现,而擦除的作用就是当我们在使用泛型时,任何具体的类型信息都会被擦除,我们只能知道我们在使用一个对象。
回到 ErasedTypeEquivalence.java 的例子中,List 和 List 在运行时实际上是相同的类型,因为它们都被会被擦除成它们的“原生”类型,即 List。
到这里,或许有人会想:擦除了又能怎么样呢?或者这是 Java 的设计者们的精巧设计呢?这应该不会有什么影响吧?
我们还是通过一个例子来说明,看 EraseBadEffect.java :
// 这是画笔类
class Paint {
void draw() {
System.out.println("Paint.draw() called");
}
}
// 这是画家类,它是一个泛型类
class Painter<T> {
private T t;
public Painter(T t) {
this.t = t;
}
// 画家开始工作
public void work() {
// 这里打算调用 Paint 类的 draw() 方法
// 但实际上,编译器已经提示:Cannot resolve method 'draw()'
t.draw();
}
}
public class EraseBadEffect {
public static void main(String[] args) {
Paint paint = new Paint();
Painter<Paint> painter = new Painter<>(paint);
painter.work();
}
}
正是因为擦除,Java 编译器没有办法将 work() 方法必须能够在 t上调用 draw() 这一需求映射到 Paint 拥有 draw() 方法这一事实上。
好了,我们已经看到擦除导致的问题,那么怎么解决呢?
这里需要初步引入边界的概念,通过给定泛型类的边界,这样就通知了编译器只能接受遵循这个边界的类型。
// 这是画笔类
class Paint {
void draw() {
System.out.println("Paint.draw() called");
}
}
// 这是画家类,它是一个泛型类
class Painter<T extends Paint> {
private T t;
public Painter(T t) {
this.t = t;
}
// 画家开始工作
public void work() {
// 这里打算调用 Paint 类的 draw() 方法
t.draw();
}
}
public class EraseBadEffectFixed {
public static void main(String[] args) {
Paint paint = new Paint();
Painter<Paint> painter = new Painter<>(paint);
painter.work();
}
}
/*
打印结果:
Paint.draw() called
*/
可以看到,有了边界后,代码就可以正常编译运行了。
边界T 必须具有类型 Paint 或者从 Paint 导出(或者说派生)的类型。这里重用了 extends 关键字。
泛型类型参数将擦除到它的第一个边界(它可能会有多个边界)。编译器会把类型参数替换为它的擦除。
为了验证上面的话,这里我们用 javap -c Painter 反编译这个类对应的 class 文件,看一下:
Compiled from "EraseBadEffectFixed.java"
class com.java.advanced.features.generics.genericerase.fix.Painter {
public com.java.advanced.features.generics.genericerase.fix.Painter(T);
Code:
0: aload_0
1: invokespecial #1 // Method java/lang/Object."":()V
4: aload_0
5: aload_1
6: putfield #2 // Field t:Lcom/java/advanced/features/generics/genericerase/fix/Paint;
9: return
public void work();
Code:
0: aload_0
1: getfield #2 // Field t:Lcom/java/advanced/features/generics/genericerase/fix/Paint;
4: invokevirtual #3 // Method com/java/advanced/features/generics/genericerase/fix/Paint.draw:()V
7: return
}
可以看到,编译器确实把类型参数替换为了它的擦除。
既然擦除会带来一些问题,那么 Java 为什么还要采用擦除呢?
《Java 编程思想》中有很好的描述,等于说明了擦除的前世今生:
擦除是 Java 的泛型实现中的一种折中,泛型并不是 Java 1.0 开始就有的组成部分。如果在 Java 1.0 就有泛型的话,那么泛型将使用具体化,使类型参数保持为第一类实体,这样我们就能够在类型参数上执行基于类型的语言操作和反射操作。事实上, Java 1.5 才引入泛型,所以 Java 基于擦除实现了泛型:泛型类型被当作第二类类型来处理,即不能在某些重要的上下文环境中使用的类型。泛型类型只有在静态类型检查期间才出现,在此之后,程序中的所有泛型类型都会被擦除,替换为它们的非泛型上界。
擦除使得 Java 泛型能够支持向后兼容性,以及支持迁移兼容性。
擦除主要的正当理由是从非泛化代码到泛化代码的转变过程,以及在不破坏现有类库的情况下,将泛型融入 Java 语言。
5.2 擦除的代价
泛型不能显式地引用在运行时类型的操作里,如转型,instanceof 操作和 new 表达式。
package com.java.advanced.features.generics.genericerase.cost;
public class EraseCost<T> {
private final int SIZE = 10;
public void f(Object arg) {
// if (arg instanceof T) {} // 在 T 处编译报错:Class or array expected
// T value = new T(); // 在第二个 T 处编译报错:Type parameter 'T' cannot be instantiated directly
// T[] array = new T[SIZE]; // 在第二个 T 处编译报错:Type parameter 'T' cannot be instantiated directly
T t = (T) arg; // 警告:Unchecked cast
}
}
运行时类型查询只适用于原始类型
这一点在 5.1 中已有例子说明。
不能创建泛型类型的数组,只可以声明一个泛型类型的数组引用
package com.java.advanced.features.generics.genericerase.cost;
class Generic<T> {}
public class ArrayOfGenericReference {
static Generic<Integer>[] gia; // 这样是 ok 的
// static Generic[] array = new Generic[10]; // 编译报错:Generic array creation
}
5.3 边界处的动作
边界:对象进入和离开方法的地点。这些正是编译器在编译器执行类型检查和插入转型代码的地点。
这里我们通过一个简单的非泛型容器类和泛型容器类作为对比来说明上述的概念。
SimpleHolder.java 是一个非泛型容器类:
public class SimpleHolder {
private Object obj;
public Object get() {
return obj;
}
public void set(Object obj) {
this.obj = obj;
}
public static void main(String[] args) {
SimpleHolder holder = new SimpleHolder();
holder.set("Hello");
String str = (String) holder.get();
}
}
通过 javap -c SimpleHolder 反编译对应的 .class 文件,
Compiled from "SimpleHolder.java"
public class com.java.advanced.features.generics.genericerase.bound.SimpleHolder {
public com.java.advanced.features.generics.genericerase.bound.SimpleHolder();
Code:
0: aload_0
1: invokespecial #1 // Method java/lang/Object."":()V
4: return
public java.lang.Object get();
Code:
0: aload_0
1: getfield #2 // Field obj:Ljava/lang/Object;
4: areturn
public void set(java.lang.Object);
Code:
0: aload_0
1: aload_1
2: putfield #2 // Field obj:Ljava/lang/Object;
5: return
public static void main(java.lang.String[]);
Code:
0: new #3 // class com/java/advanced/features/generics/genericerase/bound/SimpleHolder
3: dup
4: invokespecial #4 // Method "":()V
7: astore_1
8: aload_1
9: ldc #5 // String Hello
11: invokevirtual #6 // Method set:(Ljava/lang/Object;)V
14: aload_1
15: invokevirtual #7 // Method get:()Ljava/lang/Object;
18: checkcast #8 // class java/lang/String
21: astore_2
22: return
}
可以看到 set() 方法直接存储值,get() 方法被调用时会直接返回值,在 18:位置可以看到在调用 get() 的时候进行了 checkcast (转型)。
再看一下泛型容器类:GenericHolder.java:
public class GenericHolder<T> {
private T obj;
public T get() {
return obj;
}
public void set(T obj) {
this.obj = obj;
}
public static void main(String[] args) {
GenericHolder<String> holder = new GenericHolder<>();
holder.set("Hello");
String str = holder.get();
}
}
同样地,查看对应的反编译代码:
Compiled from "GenericHolder.java"
public class com.java.advanced.features.generics.genericerase.bound.GenericHolder {
public com.java.advanced.features.generics.genericerase.bound.GenericHolder();
Code:
0: aload_0
1: invokespecial #1 // Method java/lang/Object."":()V
4: return
public T get();
Code:
0: aload_0
1: getfield #2 // Field obj:Ljava/lang/Object;
4: areturn
public void set(T);
Code:
0: aload_0
1: aload_1
2: putfield #2 // Field obj:Ljava/lang/Object;
5: return
public static void main(java.lang.String[]);
Code:
0: new #3 // class com/java/advanced/features/generics/genericerase/bound/GenericHolder
3: dup
4: invokespecial #4 // Method "":()V
7: astore_1
8: aload_1
9: ldc #5 // String Hello
11: invokevirtual #6 // Method set:(Ljava/lang/Object;)V
14: aload_1
15: invokevirtual #7 // Method get:()Ljava/lang/Object;
18: checkcast #8 // class java/lang/String
21: astore_2
22: return
}
可以看到,对进入 set() 的类型没有进行检查,因为这是由编译器完成的;我们看一下 18:的位置,在获取 get() 方法的值之后仍然要转型。
这与之前的 SimpleHolder.java 的区别是:这里的转型是由编译器自动插入的,而SimpleHolder 中的转型是手写的。
6. 边界
边界就是在泛型的参数类型上设置限制条件。这样可以强制规定泛型可以应用的类型,更重要的是可以按照自己的边界类型来调用方法。
对于无界泛型参数而言,只能调用属于 Object 类的方法;如果把泛型参数限制为某个类型的子集,就可调用这些类型子集的方法。
为了执行这种限制,Java 泛型重用了 extends 关键字。
语法是这样的:
Bound可以类,也可以是接口;InterfaceBound1,InterfaceBound2,…,InterfaceBoundn它们代表多个接口边界,多个边界使用&进行连接,顺序先后不会造成错误;
下面是一个演示例子:
interface Flyable {
void fly();
}
class FlyPower<T extends Flyable> {
T item;
FlyPower(T item) {
this.item = item;
}
void showFly() {
item.fly();
}
}
class Person {
String name;
int age;
}
class FlyPowerPerson<T extends Person & Flyable> {
T item;
FlyPowerPerson(T item) {
this.item = item;
}
void showFly() {
item.fly();
}
String getName() {
return item.name;
}
int getAge() {
return item.age;
}
}
interface SuperHearing {
void hearSubtleNoises();
}
interface SuperSmell {
void trackBySmell();
}
interface SuperVision {
void seeThroughWalls();
}
class SuperPowerPerson<T extends Person & Flyable & SuperHearing & SuperSmell & SuperVision> {
T item;
SuperPowerPerson(T item) {
this.item = item;
}
void showFly() {
item.fly();
}
String getName() {
return item.name;
}
int getAge() {
return item.age;
}
void showSuperSmell() {
item.trackBySmell();
}
void showSuperHearing() {
item.hearSubtleNoises();
}
void showSuperVision() {
item.seeThroughWalls();
}
}
class SuperMan extends Person implements Flyable, SuperVision, SuperHearing, SuperSmell {
@Override
public void fly() {
System.out.println("fly");
}
@Override
public void hearSubtleNoises() {
System.out.println("hearSubtleNoises");
}
@Override
public void trackBySmell() {
System.out.println("trackBySmell");
}
@Override
public void seeThroughWalls() {
System.out.println("seeThroughWalls");
}
}
public class BoundsDemo {
public static void main(String[] args) {
SuperMan superMan = new SuperMan();
superMan.name = "SuperMan";
superMan.age = 18;
SuperPowerPerson<SuperMan> superPowerPerson =
new SuperPowerPerson<>(superMan);
System.out.println(superPowerPerson.getAge());
System.out.println(superPowerPerson.getName());
superPowerPerson.showFly();
superPowerPerson.showSuperHearing();
superPowerPerson.showSuperSmell();
superPowerPerson.showSuperVision();
}
}
/*
打印结果:
18
SuperMan
fly
hearSubtleNoises
trackBySmell
seeThroughWalls
*/
7. 通配符
我们从数组的协变性作为引入点。
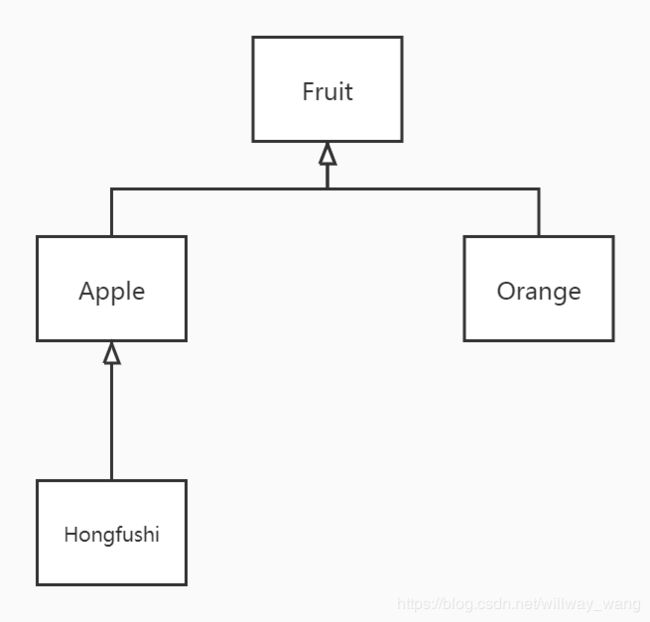
首先,看一下下面这个类的继承结构图,因为本部分我们会多次用到这个类的继承结构。
package com.java.advanced.features.generics.genericerase.wildcard;
public class CovariantArrays {
public static void main(String[] args) {
Fruit[] fruits = new Apple[10];
fruits[0] = new Apple();
fruits[1] = new Hongfushi();
try {
fruits[0] = new Fruit();
} catch (Exception e) {
System.out.println(e);
}
try {
fruits[0] = new Orange();
} catch (Exception e) {
System.out.println(e);
}
}
}
/*
打印结果:
java.lang.ArrayStoreException: com.java.advanced.features.generics.genericerase.wildcard.Fruit
java.lang.ArrayStoreException: com.java.advanced.features.generics.genericerase.wildcard.Orange
*/
知识点补充:什么是协变,逆变,不变?
逆变与协变用来描述类型转换后的继承关系。
定义 A,B 两个类型,A 是由 B 派生出来的子类(A ≤ B),f(·) 表示类型转换,如new List();
f(⋅) 是逆变(contravariant)的,当 A ≤ B 时有 f(B) ≤ f(A) 成立;
f(⋅) 是协变(covariant)的,当 A ≤ B 时有 f(A) ≤ f(B) 成立;
f(⋅) 是不变(invariant)的,当 A ≤ B 时上述两个式子均不成立,即 f(A) 与 f(B) 相互之间没有继承关系。
从 CovariantArrays 里的 Fruit[] fruits = new Apple[10]; 来看,代入上述的概念中:
f(A) = A[],令 A 为 Apple,B 为 Fruit,则有 Apple[] 可以赋值给 Fruit[],即 f(A) ≤ f(B) 成立,所以可以知道数组是协变的。
那么,如果我们用泛型容器来代替数组时,会是什么情况呢?
package com.java.advanced.features.generics.genericerase.wildcard;
import java.util.ArrayList;
public class NonConvariantGenerics {
public static void main(String[] args) {
// 编译错误:
// Incompatible types.
// Required:
// ArrayList fruitList = new ArrayList();
// 编译错误:
// Incompatible types.
// Required:
// ArrayList appleList = new ArrayList();
}
}
可以看到,令 f(A) = ArrayList(A),A为 Apple,B 为 Fruit,当 A ≤ B 时,f(A) ≤ f(B) 不成立,f(B) ≤ f(A) 也不成立。所以,泛型是不变的。
对于 ArrayList 编译报错的理解:不能把一个涉及 Apple 的泛型赋值给一个涉及 Fruit 的泛型。Apple 的 ArrayList 可以持有 Apple 及其 Apple 的子类对象,而 Fruit 的 ArrayList 可以持有 Fruit 及其 Fruit 的子类对象。Apple 的 ArrayList 和 Fruit 的 ArrayList 是两种不同的类型。
那么,有没有可能在这两种类型之间建立某种类型的向上转型关系呢?有的,这就是协变。
7.1 协变
协变是通配符所允许的。
package com.java.advanced.features.generics.genericerase.wildcard;
import java.util.ArrayList;
public class GenericsAndCovariance {
public static void main(String[] args) {
ArrayList<? extends Fruit> fruitList = new ArrayList<Apple>();
// 修改操作
// ===增加===
// 不允许添加任何类型的对象
// fruitList.add(new Apple());
// fruitList.add(new Fruit());
// fruitList.add(new Orange());
// fruitList.add(new Object());
// 可以添加 null,但是没有意义
fruitList.add(null);
// ===改变===
// 不允许改变任何类型的对象
// fruitList.set(0, new Apple());
// ===删除===
fruitList.remove(new Apple());
fruitList.remove(new Fruit());
// 获取操作
Fruit fruit = fruitList.get(0);
}
}
我们来看一下 ArrayList fruitList = new ArrayList 为什么是正确的:
令 f(A) = ArrayList(A),A 为 Apple,B 这时为 Fruit,A ≤ B ,而f(A) ≤ f(B)。因此,我们得出结论,通配符允许泛型支持协变。
但是,上面的例子中,我们看到向 fruitList 中添加非 null 的元素都是不成功的,连添加 Apple 对象都不可以,这是为什么?? extends Fruit 表示的是从 Fruit 继承的(包括 Fruit 本身)的某个未指定的具体类型,可以是 Fruit,Apple,Orange,Hongfushi。而现在给它一个确定的 Apple 对象,但是连它自己都不知道具体是哪个类型,编译器无法验证类型的安全性,所以无法添加。

但是,Fruit fruit = fruitList.get(0); 这是安全的,这是因为多态,Fruit 作为父类,总可以指向它的子类对象。
总结一下:使用 的变量只能取其中的值,不可以修改。
这是一个使用泛型协变的例子:
package com.java.advanced.features.generics.genericerase.wildcard;
import java.util.ArrayList;
import java.util.List;
public class GenericsAndCovarianceUseCase {
public static void main(String[] args) {
List<Apple> appleList = new ArrayList<>();
appleList.add(new Apple());
appleList.add(new Apple());
appleList.add(new Apple());
traverseFruitList(appleList);
List<Orange> orangeList = new ArrayList<>();
orangeList.add(new Orange());
orangeList.add(new Orange());
traverseFruitList(orangeList);
}
public static void traverseFruitList(List<? extends Fruit> fruitList) {
for (Fruit fruit : fruitList) {
System.out.println(fruit);
}
}
}
7.2 逆变
package com.java.advanced.features.generics.genericerase.wildcard;
import java.util.ArrayList;
public class GenericAndContravariance {
public static void main(String[] args) {
ArrayList<? super Apple> apples = new ArrayList<Fruit>();
// 存
apples.add(new Apple());
apples.add(new Hongfushi());
// 编译错误
// apples.add(new Fruit());
// 取
Object object = apples.get(0);
}
}
我们来看一下,ArrayList apples = new ArrayList 为什么是逆变的?
令f(A) = ArrayList(A),A 为 Apple,B 为 Fruit,A ≤ B,有 f(B) ≤ f(A)。所以通配符允许泛型逆变。
ArrayList 表示是 Apple 的某种基类型的 ArrayList,也就是说,可能是 ArrayList,也可能是 ArrayList,还可能是 ArrayList。因此,我们向 apples 里面添加 Apple 或者 Apple 的子类型对象一定是安全的,而向 apples 里面添加 Fruit 对象或者 Object 对象,就不能保证是安全的。
获取值的时候,会返回一个 Object 类型的值,而不能获取实际的类型参数代表的类型。
总结一下:使用 的变量只能存放值,不可以获取。
下面举一个使用泛型逆变的例子:
package com.java.advanced.features.generics.genericerase.wildcard;
import java.util.ArrayList;
import java.util.List;
public class GenericAndContravarianceUseCase {
public static void main(String[] args) {
List<Fruit> fruitList = new ArrayList<>();
collectApple(fruitList, new Apple());
System.out.println(fruitList);
List<Apple> appleList = new ArrayList<>();
collectApple(appleList, new Apple());
collectApple(appleList, new Hongfushi());
System.out.println(appleList);
}
public static <T> void collectApple(List<? super T> list, T item) {
list.add(item);
}
}
7.3 无界通配符
List 表示“具有某种特定类型的非原生 List,只是不知道那种类型是什么”。
参考
- Java 的泛型擦除和运行时泛型信息获取
- 夯实JAVA基本之一 —— 泛型详解(1):基本使用
- 夯实JAVA基本之一——泛型详解(2):高级进阶
- 【Java】泛型学习笔记
- JAVA中的协变与逆变