基于投影学习的负采样改进型上位词关系提取 (翻译学习使用)
原标题:Negative Sampling Improves Hypernymy ExtractionBased on Projection Learning
原作者们(感谢国际友人):Dmitry Ustalov†, Nikolay Arefyev§, Chris Biemann‡, and Alexander Panchenko
致谢!
源论文下载查看
以下翻译依据google翻译,百度翻译,bing 翻译以及鄙人仅有的四级水平综合而成,不通顺之处,建议看会小电影就好了。
附件:Ruiji Fu(付瑞吉)baseline 模型的论文
本论文的github 代码托管:github代码
建议:看完baseline 模型论文,再看本文的优化模型
基于投影学习的负采样改进型上位词关系提取
摘要:我们提出了一种新的提取方法。基于单词嵌入和投影技术的上位学习单词提取算法。相反以分类为基础的方法,基于投影的方法不需要上下位关系候选项(根据词向量计算出来)。而很自然地使用正面和负面的监督关系抽取样本,对上位词预测中负样本的影响至今没有研究。在本文中,相比较于现今最好的模型效果(傅等人(2014)关于三种不同语言的数据集实验)我们确实证明了负样本用于正则化的模型性能显著提高。
1,引言
上位词在很多自然语言处理任务中很有用,从分类的构建到查询扩展和问题回答。自动从文本中提取上位词已经成为人工构建高质量资源的一个活跃的研究领域,因为WordNet不适用于许多域-语言对。hypernymy(上位词,下同) 模式提取方法的缺点是它们的稀疏性。依赖于词对分类嵌入方法的目的是解决这个缺点, 但他们需要候选上位对。我们探索一种不需要候选对的 hypernymy 提取方法。相反, 该方法在词嵌入的基础上执行上下位词的预测。
本文的贡献是一种新的方法基于投影的 hypernymy 提取学习.即 我们提出了一个改进al. (2014) 提出的模型的版本,使用正反两面训练实例强制执行不对称投影.所提出的模型是通用的,可以直接用于其他关系正向和负两种提取任务。最后, 我们是首先成功应用投影学习在形态丰富的 hypernymy 提取语言.我们的具体实验做法和预先训练好的模型可在网上获得.
2,相关工作
hypernymy 提取的路径方法依靠上下位的句子发生在特殊的上下文, 例如,"奔驰和奥迪等汽车"赫斯特 (1992)建议使用手工制作的词法-句法模式从这种环境中提取上位。雪等 al. (2004) 介绍了一种学习方法基于自动模式上下位对。进一步例子路径方法包括 (Tjong 金桑和霍夫曼, 2009) 和 (纳维格利和 Velardi,2010). 路径的内在局限性导致稀疏问题的方法是义和上位必须发生在同一句话。
基于分布向量的方法, 如使用 word2vec 工具箱 (Mikolov et al., 2013b) 生成的算法, 目的是克服这一稀疏问题, 因为它们不需要在一个句子中同时出现上下位词。这种方法以单个词的表示作为输入来预测它们之间的关系。
到目前为止, 依赖于词向量表示的两个方法应运而生。
基于词对分类的方法采用有序对字嵌入 (候选义-上位对) 作为输入, 输出二进制标签, 表示单词之间存在 hypernymy 关系。通常, 二进制分类器在输入词嵌入向量的串联或减法上进行训练。这些方法的进一步例子包括 (Vylomova et al., 2016)。
HypeNET (Shwartz et al., 2016) 是一种混合方法, 也是基于分类器, 但除了两个字嵌入到第三矢量使用。它表示使用 LSTM 模型 (Hochreiter 和 Schmidhuber, 1997) 编码的路径语法信息。它们的结果显著优于以前基于路径的方法。
分类方法的固有局限性是它们需要候选词对的列表。这些都是在评估数据集中给出的,如BLESS数据集, 一个全语料库的关系分类将需要分类所有可能的单词对, 这是计算昂贵的大词汇量。此外, 利维等 al. (2015) 发现了这种方法的词汇记忆倾向, 阻碍了模型的泛化。
基于投影学习的方法: 以一个本位词向量作为输入, 在上位词向量的拓扑附近输出一个词向量。将其扩展到词汇表中, 每个单词只有一个这样的投影。Mikolov et al. (2013a) 用于双语词汇翻译的投影学习。Vulic 和 Korhonen (2016) 前´ sented 系统地研究了四类学习双语嵌入的方法, 包括基于投影学习的语言。
傅 et al. (2014) 首次应用投影学习上位提取。他们的方法是学习一个本位词的仿射向量转换成一个上位的词向量。采用随机梯度下降的方法对模型进行训练。利用 k-均值聚类算法将训练关系划分为若干组。一个变革为每个小组学会, 可能解释关系的投射取决于子空间的可能性。这种最先进的方法是我们实验的基线。
纳亚克 (2015) 根据分类-阳离子和投影方法对离散的上位提取物进行了评价 (但在不同的数据集上, 因此这些方法不能直接比较)。本实验提出的最佳基于体系结构是 fourlayered 前馈神经网络。没有使用关系聚类。作者在模型中采用了负样本, 在损失函数中加入了正则化项。然而, 从词汇表中抽取出的负面例子却阻碍了表现。相比之下, 我们的方法使用手动创建的同义词和下位作为负样得到了显著的改进。
山根等人。(2016)介绍了福氏等人的模型的一些改进。(2014)。他们的模型通过在训练中动态添加新的集群共同学习预测和聚类。它们还通过正则化项在损失函数中自动生成负实例。相反,纳亚克(2015),阴性样品的选择不是随机的,但最近的邻居之间的预测关系。他们的方法比较有利(福等人,2014),但负面样本的贡献没有研究。关键的区别我们的方法从(山根et al.,2016)是(1)使用明确的而不是自动产生的负样本,(2)通过执行重新投影投影矩阵的不对称。而我们的实验则是基于福氏等人的模型。(2014)、我们的正则化可以直截了当地集成到山根等人的模型中。(2016)。
3,通过正规投影学习 Hypernymy 提取
3.1 baseline 方法
在我们的实验中, 我们使用傅 et 的模型al. (2014) 作为基线。在这种方法中,投影矩阵Φ得到类似于线性回归问题, 即对于给定行词向量 x 和 y 相应地代表本位词(下位词)和上位词, 矩阵Φ适合于正样本对 P 的训练集:
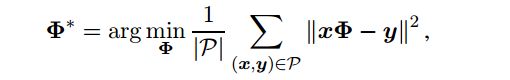
公式 |P |是培训实例的数量和 ||xΦ − y||一对行向量 xΦ和 y 之间的距离。在原方法中, 使用 L2 距离。为了提高性能, k 投影矩阵Φ是
学习一个为每个集群的关系在训练集中。一个示例由本位词-上位偏移表示。使用 k-均值算法 (MacQueen, 1967) 进行聚类。
3.2 语言制约
使用分布词向量生成的近邻往往包含同义词、上位、下位词和其他相关词的混合 (Wandmacher, 2005;Heylen et al., 2008;十月, 2011)。为了明确提供与
模型不受欢迎的关系的例子, 我们提出了两个改进的基线模型的版本:
1,不对称正规化, 使用反向关系为负的例子, 和2,邻居正规化使用的关系其他类型作为阴性例子。
为此, 我们在损失函数中添加一个正则化项:
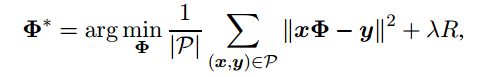
λ是控制正则化项R的重要性的常数。
非对称正则化。作为上位关系是非对称关系,我们的第一种方法强制执行投影矩阵的非对称性。应用对预测相同的转化关系
向量XΦ不应该提供矢量相似(·)的初始义词向量X。注意,正则化只需要正样本P:
向量XΦ不应该提供矢量相似(·)的初始义词向量X。注意,正则化只需要正样本P:
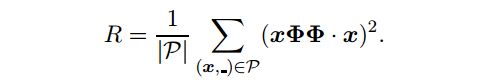
邻居正规化。这种方法依赖于负抽样, 通过显式提供义 x 的语义相关单词 z 的例子, 该示例对矩阵进行惩罚, 以生成类似于它们的向量:
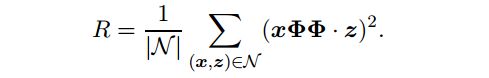
请注意, 此 regularizer 需要负样本 N。在我们的实验中, 我们使用下位的同义词作为 N, 但其他类型的关系也可以使用, 如反义词或下位词等。某些单词在
训练集中可能没有同义词。在这种情况下, 我们用 x 代替 z, 优雅地减少到以前的变化。否则, 在每个训练的时代, 我们抽样一个给定的词的随机同义词。
无需重新投影正则化。除了上述的两种正则化,依靠下义词向量投影(xΦΦ)(本人不知道啥是xΦΦ,感觉是上位词聚类的结果),我们还测试了两种正则化重新投影,记为xΦ。在这个变化的邻居化定义如下:

在我们的情况下, 这 regularizer 惩罚的相关性预测的上位 xΦ到同义词 z。无投影的非对称 regularizer 是以类似的方式定义的。
3.3 模型的训练学会被考虑的模型的参量我们使用了Adma方法 (Kingma 和 Ba, 2014) 与使用默认参数meta-parameters 在 TensorFlow 框架 上(阿巴迪 et al., 2016). 我们跑了700训练迭代次数,批次大小1024进行模型训练。我们使用正态分布 N (0, 0.1) 初始化每个投影矩阵的元素。
4,实验结果
为了评估模型的质量, 我们采用了 al. (2013) 提出的 hit@l 措施, 该方法最初用于图像标注。对于在测试集 P 中由义 x 和上位 y 组成的每个包容对 (x、y), 我们为投影的上位 xΦ∗计算最近的邻居。如果金上位 y 出现在最近邻 NNl (xΦ∗) 的计算列表中, 则该配对被视为匹配。为了获得质量分数, 我们平均在测试集 P 中的匹配项:

其中 1 (·) 是指示器函数。也考虑正确的答复的等级, 我们计算区域在曲线测量之下作为区域在 L−1梯形之下:
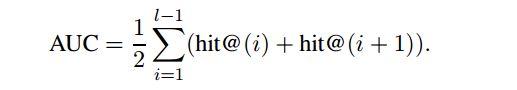
4.2 实验 1: 俄语
数据说明:在这个实验中, 我们使用的词嵌入作为一部分的俄语分布词库 (十月 et al., 2016b) 其训练在129亿块俄国书片段。嵌入词向量训练了使用n-skip模型 (Mikolov et al., 2013b) 与500维度和上下文窗口设置为10词大小。
我们实验中使用的数据集由两个来源组成。我们使用 Wikokit 工具箱 (Krizhanovsky 和斯米尔诺夫, 2013) 从 Wiktionary3 中提取同义词和上位。为了丰富数据集的词法覆盖率, 我们使用 PatternSim 工具箱 (十月 et al., 2012) 从同一个语料库中提取了来自同一语料的额外上位. 4 过滤噪声提取, 我们只使用关系提取超过100次。正如 al. (2015) 所建议的, 我们将训练和测试集分开, 这样每个包含一个不同的词汇, 以避免过拟合。这将导致 25 067 训练、8 192 验证和 8 310 测试示例。验证和测试集包含上位从维基词典, 而培训集是由上位和同义词来自两个来源。
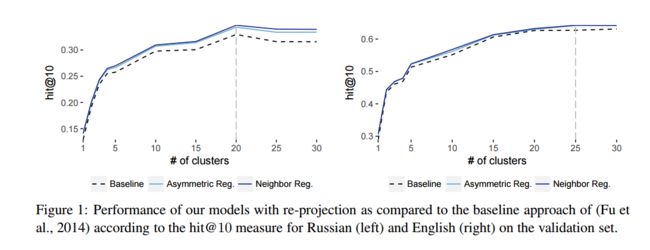
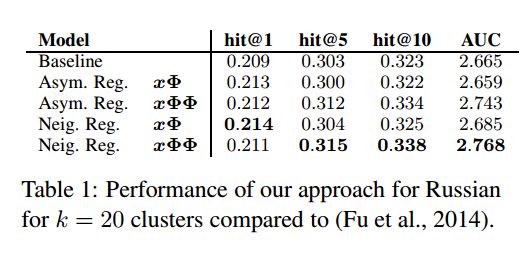
讨论结果。图 1 (左侧) 显示了验证集上三投影学习设置的性能: 基线方法、非对称正则化方法和相邻的正规化方法。两种正则化策略都能在不同簇大小的 non-regularized 基线 (Fu et al., 2014) 上得到一致的改进。该方法达到了 k = 20 簇的最佳性能。表1提供了此设置的性能指标的详细比较。我们的方法基于规范化使用同义词作为负样品胜过基础模型 (所有区别在基线和我们的模型之间是重要的关于 t 测试)。根据所有的指标, 但 hit@1 的结果可与 xΦ, 投影 (xΦΦ) 改善的结果。
4.3 实验 2: 英语
我们对两个数据集进行了评估。评估数据集。在这项评估中, 单词嵌入词向量由维基百科, ukWaC (Ferraresi et al., 2008), Gigaword (格拉夫, 2003), 和新闻语料库从莱比锡集合 (Goldhahn et al., 2012) 组成的63亿token 文本集合。我们使用的 skipgram 模型的上下文窗口大小为8令牌和300维向量。
我们使用EVALution数据集 (Santus et al., 2015) 来训练和测试模型, 它由 1 449 上位和520同义词组成, 其中上位分为944训练、65验证和440测试对。同样地, 在第一个实验中, 我们用赫氏模式提取了额外的训练上位, 但与俄语相比, 他们并没有显著改善结果, 所以我们把它们留给了英语。这种差异的一个原因可能是更复杂的俄语形态学系统, 其中每个词有更多的形态学变体相比, 英语。因此, 俄语需要额外的训练样本 (俄语嵌入在 non-lemmatized 语料库上进行训练)。组合数据集。为了在配置中显示我们的方法的健壮性, 此数据集有更多的训练实例、不同的嵌入以及同义词和 co-hyponyms 作为负样本。我们使用上位, 同义词和 cohyponyms 从四常用的数据集: 评估, 祝福 (菜和伦奇, 2011), ROOT09 (死 et al., 2016) 和 K 和 H + N (Necsulescu et al., 2015)。获得的 14 528 关系被分成 9 959 训练、1 631 验证和 1 625 测试上位;1 313 同义词和 cohyponyms 作为阴性样品使用。我们使用的标准300维嵌入训练的1000亿令牌谷歌新闻语料库 (Mikolov et al., 2013b)
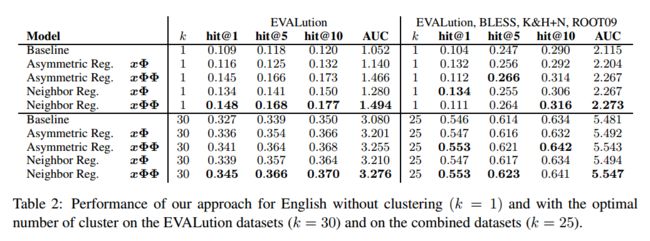
结果讨论。图 1 (右) 显示, 与俄语相似, 两种正则化策略导致了对 non-regularized 基线的一致改进。表2给出了两个英文数据集的详细结果。与第一个实验相似, 我们的方法在不同的配置中持续地改进结果。随着我们改变簇的数量, 嵌入的类型, 训练数据的大小和用于负采样的关系类型, 使用我们的方法的结果要优于基线。与 re-projected 版本 (xΦΦ) 相比, 无投影 (xΦ) 的 regularizers 在大多数配置中获得较低的结果。总体而言, 与非对称正则化相比, 邻域正规化的结果略好。我们把这归因于一些同义词 z 是接近原始的义 x, 而其他可能是遥远的事实。因此, 相邻正则化能够在训练过程中得到更稳健的模型。这也是为什么两个 regularizers 的性能相似的原因: 不对称正规化使 re-projected 向量不属于本义词的语义邻域。这正是邻居正规化达到的。那邻居经常化要求明确消极例子。
5,结论
本研究提出了一种基于分布词向量投影的 hypernymy 关系提取新模型。该模型包含了由其他类型的关系 (如同义词和 co-hyponyms下位词) 表示的显式负训练实例的信息, 并强制执行投影操作的不对称性。我们在英语和俄语 hypernymy 上位词预测任务的背景下进行的实验表明, 在没有负抽样的情况下, 所提出的方法在最先进的模型上有了显著的改进。
致谢:
我们感谢德意志 Forschungsgemeinschaft (DFG) 基金会在 "联合 T" 项目下的支持, 凯撒 Akademischer Austauschdienst (DAAD), 俄罗斯基础研究基金会 (RFBR) 在16-37-00354 摩尔 a 项目下, 以及俄罗斯人文基础项目 16-04-12019 "RussNet 和纱线词表一体化"。我们还感谢微软提供的计算资源在微软 Azure 研究奖。最后, 我们感谢本杰明 Milde, 安德烈库图佐夫, 安德鲁 Krizhanovsky 和马丁 Riedl 有关这项研究的讨论和建议。