sparkstreaming消费多个topic数据获取topic的信息
这个问题是最近一个朋友问我的,用sparkstreaming消费kafka的多个topic,怎么获取topic的信息,然后根据不同topic的数据做不同的逻辑处理.
其实这个问题非常简单,最容易想到的办法就是直接对Dstream的数据进行filter过滤操作,类似于下面的写法
val data = stream.map(_.value()).cache()
// a topic的数据
data.filter(_.contains("a"))
// b topic的数据
data.filter(_.contains("b"))
但是这种写法的前提是你需要提前知道数据的格式,然后根据两个topic里面数据的不同字段或者不同点去过滤数据然后再分别处理,如果提前不知道数据的类型该怎么办呢? 其实也非常简单,我们先来看下相关的源码.
def createDirectStream[K, V](
ssc: StreamingContext,
locationStrategy: LocationStrategy,
consumerStrategy: ConsumerStrategy[K, V]
): InputDStream[ConsumerRecord[K, V]] = {
val ppc = new DefaultPerPartitionConfig(ssc.sparkContext.getConf)
createDirectStream[K, V](ssc, locationStrategy, consumerStrategy, ppc)
}从kafka里面获取数据我们常用的是createDirectStream低阶API,也就是Direct方式,可以看到这个方法的返回值是一个InputDStream[ConsumerRecord[K, V]]类型的数据,InputDStream里面的泛型是ConsumerRecord类型的,我们主要来看下ConsumerRecord类里面都有什么信息
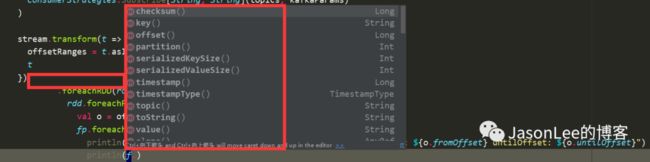
public class ConsumerRecord {
public static final long NO_TIMESTAMP = Record.NO_TIMESTAMP;
public static final int NULL_SIZE = -1;
public static final int NULL_CHECKSUM = -1;
private final String topic;
private final int partition;
private final long offset;
private final long timestamp;
private final TimestampType timestampType;
private final long checksum;
private final int serializedKeySize;
private final int serializedValueSize;
private final K key;
private final V value;
}
这个类的作用是从kafka接收的键/值对。这也包括一个主题名称和从中接收记录的分区号,它指向一个偏移量记录到Kafka分区中的记录,以及相应的ProducerRecord标记的时间戳 ,也就是说所有的信息都是在这里面封装的,比如key,value,topic,offset等信息都在里面,那就好办了,直接从这里面获取topic信息不就行了吗,其实所有的信息都在这里,只是很多人不知道,一上来就只获取了value的值,到下面foreach里在想获取别的信息已经拿不到了.
代码如下:
stream.map(m => (m.topic(),m.value()))这里一个map操作把topic和value转换成一个Tuple2,这样做的好处是过滤掉了其他不需要的信息,只保留有用的数据,然后就可以获取到topic的信息了,后面做什么样的处理就看自己的逻辑了,当然这里的数据类型可以定义为任何类型,只要包含有topic的信息即可,我这里只是为了演示.
完整的代码如下:
package spark
import org.apache.kafka.clients.consumer.ConsumerRecord
import org.apache.kafka.common.serialization.StringDeserializer
import org.apache.log4j.{Level, Logger}
import org.apache.spark.TaskContext
import org.apache.spark.sql.SparkSession
import org.apache.spark.streaming.dstream.InputDStream
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.streaming.kafka010._
object moreTopic {
private var stream: InputDStream[ConsumerRecord[String, String]] = null
private var offsetRanges: Array[OffsetRange] = null
def main(args: Array[String]): Unit = {
Logger.getLogger("org.apache.spark").setLevel(Level.ERROR)
Logger.getLogger("org.eclipse.jetty.server").setLevel(Level.ERROR)
Logger.getLogger("org.apache.kafka.clients.consumer").setLevel(Level.ERROR)
val spark = SparkSession
.builder()
.appName("Spark Jason")
.master("local[*]")
.getOrCreate()
val sc = spark.sparkContext
val scc = new StreamingContext(sc, Seconds(2))
val kafkaParams = Map[String, Object](
"auto.offset.reset" -> "latest",
"value.deserializer" -> classOf[StringDeserializer]
, "key.deserializer" -> classOf[StringDeserializer]
, "bootstrap.servers" -> "master:9092,storm1:9092,storm2:9092"
, "group.id" -> "jason_spark"
, "enable.auto.commit" -> (true: java.lang.Boolean)
)
val topics = Array("jason_flink-1", "jason_flink-2")
stream = KafkaUtils.createDirectStream[String, String](
scc,
LocationStrategies.PreferConsistent,
ConsumerStrategies.Subscribe[String, String](topics, kafkaParams)
)
stream.map(m => (m.topic(),m.value()))
stream.transform(t => {
offsetRanges = t.asInstanceOf[HasOffsetRanges].offsetRanges
t
}).map(m => (m.topic(),m.value()))
.foreachRDD(rdd => {
rdd.foreachPartition(fp => {
val o = offsetRanges(TaskContext.get.partitionId)
fp.foreach(f => {
println(s"topic: ${o.topic} partition: ${o.partition} fromOffset: ${o.fromOffset} untilOffset: ${o.untilOffset}")
println(f)
})
})
})
scc.start()
scc.awaitTermination()
}
}
为了更加清楚的看到打印的结果,我在代码里把日志级别改成了ERROR级别,运行程序打印的结果如下:
topic: jason_flink-1 partition: 0 fromOffset: 598 untilOffset: 599
(jason_flink-1,{"address":"北京市海淀区","money":100.5,"city":"beijing","name":"jason50","topic":"jason_flink-1","age":25,"ts":1591005156780})
topic: jason_flink-2 partition: 0 fromOffset: 570 untilOffset: 571
(jason_flink-2,{"address":"北京市海淀区","money":100.5,"city":"beijing","name":"jason49","topic":"jason_flink-2","age":26,"ts":1591005155779})
topic: jason_flink-2 partition: 2 fromOffset: 448 untilOffset: 449
(jason_flink-2,{"address":"北京市海淀区","money":100.5,"city":"beijing","name":"jason51","topic":"jason_flink-2","age":26,"ts":1591005157780})
可以看到打印的数据里面第一个元素就是topic的信息,如果你还想获取别的信息也可以通过这种方式获取.
有人可能会觉得多此一举,不加上面那段map转换的代码也可以获取到topic,确实是这样的,我把这行代码删了,到下面的foreach里可以获取到所有的信息.
但是本着不需要的数据提前过滤掉的原则,我习惯在上面加一行转换操作,只留下有用的信息.大家可以自己选择.
推荐阅读:
Flink1.10.0 SQL DDL 把计算结果写入kafka
JasonLee,公众号:JasonLee的博客Flink1.10.0 SQL DDL 把计算结果写入kafka
Flink 1.10.0 SQL DDL中如何定义watermark和计算列
JasonLee,公众号:JasonLee的博客Flink 1.10.0 SQL DDL中如何定义watermark和计算列
FlinkSQL使用DDL语句创建kafka源表
JasonLee,公众号:JasonLee的博客FlinkSQL使用DDL语句创建kafka源表
Flink 状态清除的演进之路
JasonLee,公众号:JasonLee的博客Flink 状态清除的演进之路
Flink动态写入kafka的多个topic
JasonLee,公众号:JasonLee的博客Flink动态写入kafka的多个topic
Flink源码分析: 窗口机制的执行流程
JasonLee,公众号:JasonLee的博客Flink源码分析: 窗口机制的执行流程
更多spark和flink的内容可以关注下面的公众号
