python爬虫学习笔记
文章目录
- 第一章 网络请求
- 1、`urllib`库
- 1.01、`urlopen`函数:
- 1.02、`urlretrieve`函数:
- 1.03、`urlencode`函数:
- 1.04、`parse_qs`函数:
- 1.05、`urlparse`和`urlsplit`:
- 1.06、`request.Request`类:
- 1.07、proxyHandler处理器(代理设置)
- 1.08、什么是`cookie`:
- 1.09、使用`cookielib`库和`HTTPCookieProcessor`模拟登录:
- 1.10、`http.cookiejar`模块:
- 1.11、保存`cookie`到本地:
- 1.12、从本地加载`cookie`:
- 2、`requests`库
- 2.01、安装和文档地址:
- 2.02、发送`GET`请求:
- 2.03、发送`POST`请求:
- 2.04、使用代理:
- 2.05、`cookie`:
- 2.06、`session`:
- 2.07、处理不信任的`SSL`证书:
- 第二章 数据提取
- 1、XPath语法和lxml库
- 1.01、什么是XPath?
- 1.02、XPath工具
- 1.03、XPath语法:
- 1.04、lxml的基本使用:
- 1.05、在lxml中使用XPath语法:
- 2、`BeautifulSoup4`库
- 2.01、安装和文档:
- 2.02、几大解析工具对比:
- 2.03、四个常用的对象:
- 2.03-1、Tag
- 2.03-2、NavigableString:
- 2.03-3、BeautifulSoup:
- 2.03-4、Comment:
- 2.04、搜索文档树
- 2.04-1、find和find_all方法:
- 2.04-2、select方法:
- 2.04-3、find_all的使用:
- 2.04-4、find和find_all的区别:
- 2.04-5、find和find_all的过滤条件:
- 2.04-6、获取标签的属性:
- 2.04-7、string、strings、stripped_strings属性和get_text方法:
- 2.05、遍历文档树
- 2.05-1、contents和children:
- 2.05-2、strings和stripped_strings
- 3、正则表达式和re模块
- 3.02、正则表达式常用的匹配规则:
- 3.03、转义字符和原生字符串
- 3.04、正则表达式函数:
- 3.04-1、`re.compile()`函数
- 3.04-2、用于匹配的函数:
- 3.04-3、分组:
- 3.04-4、match():
- 3.04-5、search():
- 3.04-6、findall():
- 3.04-7、检索替换re.sub():
- 3.04-8、检索替换re.subn()
- 3.04-9、re.split()
- 第三章 数据储存
- 1、json文件处理:
- 1.01、什么是json:
- 1.02、JSON支持数据格式:
- 1.03、字典和列表转JSON:
- 1.04、将json数据直接`dump`到文件中:
- 1.05、将一个json字符串load成python对象:
- 1.06、直接从文件中读取json:
- 2、csv文件处理:
- 2.01、读取csv文件:
- 2.02、写入数据到csv文件:
- 3、MySQL操作
- 3.01、数据库连接:
- 3.02、插入数据:
- 3.03、查找数据:
- 3.04、删除数据:
- 3.05、更新数据:
- 4、`MongoDB`数据库操作:
- 4.01、`MongoDB`概念介绍:
- 4.03、`MongoDB`基本操作命令:
- 4.04、`Python`操作`MongoDB`:
- 4.04-1、安装`pymongo`:
- 4.04-2、连接`MongoDB`:
- 4.04-3、数据类型:
- 4.04-4、操作`MongoDB`:
- 第四章 爬虫进阶
- 1、多线程爬虫
- 1.01、多线程介绍:
- 1.02、threading模块介绍:
- 1.03、查看线程数量:
- 1.04、查看当前线程的名字:
- 1.05、继承自`threading.Thread`类:
- 1.06、多线程共享全局变量的问题:
- 1.07、锁机制:
- 1.08、Lock版本的生产者与消费者模式:
- 1.09、Condition版的生产者与消费者模式:
- 1.10、`Queue`线程安全队列:
- 1.11、使用生产者与消费者模式多线程下载表情包
- 1.12、GIL全局解释器锁:
- 2、动态网页数据抓取
- 2.01、什么是`AJAX`:
- 2.02、获取`Ajax`数据的方式:
- 2.03、`Selenium+chromedriver`获取动态数据:
- 2.04、安装`Selenium`和`chromedriver`:
- 2.05、快速入门:
- 2.06、selenium常用操作:
- 2.06-1、关闭页面:
- 2.06-2、定位元素:
- 2.06-3、操作表单元素:
- 2.07、鼠标行为链:
- 2.08、`Cookie`操作:
- 2.09、页面等待:
- 2.10、切换页面:
- 2.11、设置代理IP:
- 2.12、`WebElement`元素:
- 3、图形验证码识别技术:
- 3.01、`Tesseract`:
- 3.02、设置环境变量:
- 3.03、在命令行中使用`tesseract`识别图像:
- 3.04、在代码中使用`tesseract`是被图像:
- 3.05、用`pytesseract`识别图形验证码实现自动登陆拉勾网:
- 1、`Scrapy`框架介绍:
- 1.01、`Scrapy`架构图:
- 1.02、Scrapy框架模块功能:
- 2、`Scrapy`快速入门
- 2.01、安装和文档:
- 2.02、快速入门:
- 2.02-1、创建项目:
- 2.03、使用`Scrapy`框架爬取糗事百科段子:
- 2.03-1、使用命令创建一个爬虫:
- 2.03-2、爬虫代码解析:
- 2.03-3、修改`settings.py`代码:
- 2.03-4、完成的代码:
- 2.03-5、运行`scrapy`项目:
- 2.04、爬虫中的注意事项:
- 2.05、json数据保存
- 3、CrawlSpider
- 3.02、`LinkExtractors`链接提取器:
- 3.03、Rule规则类:
- 3.04、微信小程序社区CrawlSpider案例
- 3.05、CrawlSpider注意要点:
- 4、Scrapy Shell
- 4.01、打开Scrapy Shell:
- 5、Request和Response对象
- 5.01、Request对象:
- 5.02、Response对象:
- 5.03、发送POST请求:
- 5.04、模拟登录
- 6、下载文件和图片
- 6.01、为什么选择`scrapy`内置的下载文件的方法:
- 6.02、下载文件的`Files Pipeline`:
- 6.03、下载图片的`Images Pipeline`:
- 7、Dowloader Middlewares(下载器中间件)
- 7.01、`process_request(self,request,spider)`:
- 7.02、`process_response(self,request,response,spider)`:
- 7.03、随机请求头中间件:
- 7.04、IP代理池中间件
- 8、`Scrapy`中的`MySQL`异步存储:
- 第六章Scrapy-Redis分布式爬虫
- 1、Redis数据库介绍:
- 1.02、`redis`使用场景:
- 1.03、`redis`和`memcached`比较:
- 1.04、`redis`在`ubuntu`系统中的安装与启动
- 1.05、对`redis`的操作
- 1.05-1、使用`redis-cli`对`redis`进行操作
- 1.05-2、`Python`操作`redis`
- 2、Scrapy-Redis分布式爬虫组件:
- 2.01、分布式爬虫的优点:
- 2.02、分布式爬虫必须要解决的问题:
- 2.03、安装:
- 2.04、Scrapy-Redis架构:
- 2.05、`ubuntu`爬虫服务器部署:
- 2.06、编写Scrapy-Redis分布式爬虫:
第一章 网络请求
1、urllib库
urllib库是python库中最基本的网络请求库。可模拟浏览器的行为,向指定的服务器发送一个请求,并可以保存服务器返回的数据。
1.01、urlopen函数:
在python的urllib库中,所有和网络请求相关的方法,都被集成到urllib.request模块下面了。先看以下urllib函数的基本使用:
from urllib import request
resp = request.urlopen('http://www.baidu.com')
print(resp.read())
实际上,使用浏览器访问百度,右键查看源代码。你会发现,和我们打印出来的数据是一样的。也就是说,上面的三行代码就已经帮我们把百度的首页全部代码爬下来了。一个基本的url请求对应的python代码非常简单。
以下对urlopen函数进行详细讲解:
url:请求的url。data:请求的data,如果设置了这个值,那么将变成post请求。- 返回值:返回值是一个
http.client.HTTPResponse对象,这个对象是一个类文件句柄对象。有read(size)、readline、readlines以及getcode等方法。
1.02、urlretrieve函数:
这个函数可以方便的将网页上的文件保存到本地(例如下载图片等网络文件等)。以下代码可以非常方便的将百度的首页下载到本地:
from urllib import request
request.urlretrieve('http://www.baidu.com','baidu.html')
1.03、urlencode函数:
用浏览器发送请求的时候,如果url中包含了中文或其它特殊字符,那么浏览器会自动给我们进行编码。而如果我们使用代码发送请求的,那么就必须手动进行编码,这时候就应该使用urlencode函数来实现。urlencode可以把字典数据转换为url编码的数据。示例如下:
from urllib import parse
data = {'name':'爬虫基础','greet':'hello wprld','age':100}
qs = parse.urlencode(data)
print(qs)
1.04、parse_qs函数:
可以将经过编码的url参数进行解码(和urlencode相反)。示例代码如下:
from urllib import parse
qs = 'name=%E5%86%AF%E5%AE%9A%E5%A5%8E&age=23'
result2 = parse.parse_qs(result)
print(result2)
1.05、urlparse和urlsplit:
有时候拿到一个url,想要对这个url中的各个组成部分进行分割,那么这时候就可以使用urlparse或者是urlsplit来进行分割。示例如下:
from urllib import parse
# hello是urlparams中的params属性!在urlsplit中,归属于path属性。
url = "http://www.baidu.com/s;hello?wd=fdk"
result = parse.urlparse(url)
# re = parse.urlsplit(url)
print('scheme:',result.scheme)
print('netloc:',result.netloc)
print('path:',result.path)
print('params:',result.params)
print('query:',result.query)
print('fragment:',result.fragment) # 锚点
两者的区别:
urlparse比urlsplit多了一个params属性。url = "http://www.baidu.com/s;hello?wd=fdk",urlparse的params属性值是hello。url中的params也用的比较少。
1.06、request.Request类:
如果想要在请求的时候增加一些请求头,那么就必须使用request.Request类来实现。比如要增加一个User-Agent,示例代码如下:
from urllib import request
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36'
}
req = request.Request('http://www.baidu.com/',headers=headers)
resp = request.urlopen(req)
print(resp)
1.07、proxyHandler处理器(代理设置)
很多网址都会检测一段时间内某个ip的访问次数(通过流量统计,系统日志等),如果访问次数多的不像正常人,它会禁止这个IP的访问。所以我们可以设置一些代理服务器,每隔一段时间换一个代理IP,就算IP禁止,依然可以换个IP继续爬取。通过**这个**可以获取本机的一些信息。
urllib中通过ProxyHandler来设置使用代理服务器,下main代码说明如何使用自定义opener来使用代理:
from urilib import request
# 这个是码云使用代理的
# resp = request.urlopen('http://httpbin.org/get')
# print(resp.read().decode('utf-8'))
# 这个是使用代理的
handler = request.ProxyHandler({'http':'119.254.94.91:54958'})
opener = request.build_opener(handler)
req = request.Request('http://httpbin.org/ip')
resp = opener.open(req)
print(resp)
常用的代理有:
-
西刺免费代理IP:点击进入
-
快代理:快代理的免费代理IP
1.08、什么是cookie:
在网站中,http请求是无状态的。也就是说即使第一次和服务器连接后并且登录成功后,第二次请求服务器依然不能知道当前请求是哪个用户。cookie的出现是为了解决这个问题,第一次登录后服务器返回一些数据(cookie)给浏览器,然后浏览器保存在本地,当该用户发送第二次请求的时候,就会自动把上次请求存储的cookie数据自动的携带给服务器,服务器通过浏览器携带的数据就能判断当前用户是哪一个了。cookie存储的数据量有限,不同的浏览器有不同的存储大小,但一般不超过4KB。因此使用cookie只能存储一些小量的数据。
cookie的格式:
set-Cookie: NAME=VALUE;Expires/Max-age=DATE;Path=PATH;Domain=DOMAIN_NAME;SECURE
参数意义:
- NAME:cookie的名字。
- VALUE:cookie的值。
- Expires:cookie的过期时间。
- Path:cookie作业的路径。
- Domain:cookie作业的域名。
- SECURE:是否只在https协议下起作用。
1.09、使用cookielib库和HTTPCookieProcessor模拟登录:
Cookie是指网站服务器为了辨别用户身份和进行Session跟踪,而存储在浏览器上的文本文件,Cookie可以保持登录信息到用户下次与服务器的会话。
在一些网站中,要访问某个页面需要先登录,也就是说要有cookie信息。如果我们想要用代码的方式进行访问,就必须要有正确的cookie信息才能访问。解决方案有两种,第一种是使用浏览器访问,然后cookie信息复制下来,放到headers中。示例代码如下:
from urllib import request
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36'
'Cookie':'浏览器中的cookie信息。'
}
url = 'http://www.renren.com/880151247/profile'
req = request.Request(url,headers=headers)
resp = request.urlopen(req)
with open('renren.html','w') as fp:
fp.write(resp.read().decode('utf-8'))
但是每次在访问需要cookie的页面都要从浏览器中复制cookie比较麻烦。在pyhton处理Cookie,一般是通过http.cookiejar模块和urllib模块的HTTPCookieProcessor处理器类一起使用。http.cookiejar模块主要作用是提供用于存储cookie的对象。而HTTPCookieProcessor处理器主要作用是处理这些cookie对象,并构建handler对象。
1.10、http.cookiejar模块:
该模块主要的类有CookieJar、FileCookieJar、MozillaCookieJar、LWPCookieJar。这四个类的作用分别是:
CookieJar:管理HTTP cookie值、存储HTTP请求生成的cookie、向传出的HTTP请求添加cookie的对象。整个cookie都存储在内存中,对CookieJar实例进行垃圾回收后cookie也将丢失。FileCookieJar(filename,delayload=None,policy=None):从CookieJar派生而来,用来创建FileCookieJar实例,检索cookie信息并将cookie存储到文件中。filename是存储cookie的文件名。delayload为True时支持延时访问文件,即只有在需要时才读取文件或在文件中存储数据。MozillaCookieJar(filename,delayload=None,policy=None):从FileCookieJar派生而来,创建与Mozilla浏览器cookies.txt兼容的FileCookieJar实例。LWPCookieJar(filename,delayload=None,policy=None):从FileCookieJar派生而来,创建与libwww-per标准的Set-Cookie3文件格式兼容的FileCookieJar实例。
利用http.cookiejar和request.HTTPCookieProcessor登录人人网。示例代码如下:
from urllib import request,parse
from http.cookiejar import CookieJar
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36'
}
def get_opener():
# 1. 登录
# 1.1 创建一个CookieJar对象
cookiejar = CookieJar()
# 1.2 使用cookiejar创建一个HTTPCookieProcess对象
handler = request.HTTPCookieProcessor(cookiejar)
# 1.3 使用上一步骤创建的handler创建一个opener
opener = request.build_opener(handler)
return opener
def login_renren(opener):
# 1.4 使用opener发送登录的请求(人人网的邮箱和密码)
data = {
'emial':'人人的邮箱',
'password':'密码'
}
login_url = 'http://www.renren.com/PLogin.do'
req = request.Request(login_url,data=parse.urlencode(data).encode('utf-8'),headers=headers)
opener.open(req)
def visit_profile(opener):
# 2 访问个人主页
dapeng_url = 'http://www.renren.com/880151247/profile'
# 获取个人主页的时候,不要新建opener
# 使用上一个登录的opener,因为上一个opener在登录的时候包含了cookie信息
req = request.Request(dapeng_url,headers=headers)
resp = opener.open(req)
with open('renren.html','w',encoding='utf-8') as fp:
fp.write(resp.read().decode('utf-8'))
if __name__ == '__main__':
opener = get_opener()
login_renren(opener)
visit_profile(opener)
1.11、保存cookie到本地:
保存cookie到本地,可以使用cookiejar的save方法,并且需要指定一个文件名:
from urllib import request
from http.cookiejar import MozillaCookieJar
cookiejar = MozillaCookieJar('cookies.txt')
handler = request.HTTPCookieProcessor(cookiejar)
opener = request.build_opener(handler)
resp = request.Request('http://httpbin.org/cookies/set?course=abc')
opener.open(resp)
cookiejar.save(ignore_discard=True)
注解:
ignore_discard的意思是:即使cookies将被丢弃也将它保存下来。
ignore_expires的意思是:如果cookies已经过期也将它保存并且文件已存在时将覆盖。
1.12、从本地加载cookie:
从本地加载cookie,需要使用cookiejar的load方法,并且也需要指定文件名:
from urllib import request
from http.cookiejar import MozillaCookieJar
cookiejar = MozillaCookieJar('cookies.txt')
cookiejar.load(ignore_discard=True)
for cookie in cookiejar:
print(cookie)
2、requests库
虽然python的标准库中urllib已经包含了很多平时使用的功能,但他的API使用起来感觉不太好,而Requests宣传是“HTTP for Humans”,说明使用更简洁方便。
2.01、安装和文档地址:
利用pip进行安装:pip install requests
中文文档:http://docs.python-requests.org/zh_CN/latest/index.html
2.02、发送GET请求:
-
最简单的发送
get请求就是通过requests.get来调用:response = requests.get('http://www.baidu.com') -
添加
headers和查询参数:如果想添加
headers,可以传入headers参数来增加请求头中的headers信息。如果要将参数放入url中传递,可以利用params参数。示例代码如下:import requests headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36'} data = {'wd':'中国'} url = 'https://www.baidu.com/s' response = requests.get(url,params=data,headers=headers) # 查看响应内容,Unicode格式 print(response.text) # 查看响应内容,字节流格式,可以使用decode进行编码 print(response.content) # 查看完整的url地址 print(response.url) # 查看响应头部字符编码 print(response.encoding) # 查看响应的状态码 print(response.status_code)
2.03、发送POST请求:
-
最基本的
POST请求可以使用post方法:response = requests.get('https://www.baidu.com/s',data=data) -
传入
data数据:这时候就不要在使用
urlencode进行编码了,直接传入一个字典进去就可以了。如果返回的数据是json类型的,可以按照字典的操作来进行提取数据。示例代码如下:import requests headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36', 'Referer': 'https://www.lagou.com/jobs/list_python%E7%88%AC%E8%99%AB?city=%E5%85%A8%E5%9B%BD&cl=false&fromSearch=true&labelWords=&suginput=' } data = {'first': 'true', 'pn': '1', 'kd': 'python爬虫'} url = 'https://www.lagou.com/jobs/positionAjax.json?needAddtionalResult=false' response = requests.post(url, data=data, headers=headers) json_str = response.json() result = json_str['content']['positionResult']['result'] for i in result: # 输出公司名 print(i['companyShortName']) # 输出城市名 print(i['city']) print('*' * 20)
2.04、使用代理:
使用requests添加代理非常简单,只要在请求的方法中(比如get或post)传递proxies参数就可以了。示例代码如下:
import requests
url = 'http://httpbin.org/ip'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36'
}
proxy = {
'http': '118.190.95.35:9001'
}
resp = requests.get(url,headers=headers,proxies=proxy)
print(resp.text)
2.05、cookie:
如果在一个响应的包含了cookie,那么可以利用cookie属性拿到这个返回的cookie值:
import requests
resp = requests.get('http://www.baidu.com')
print(resp.cookies)
# 获取cookie的详细信息
print(resp.cookies.get_dict())
2.06、session:
之前使用urllib库,是可以使用opener发送多个请求,多个请求之间是可以共享cookie的。那么如果要使用requests也要达到共享的cookie的目的,那么可以使用requests库提供的session对象。注意,这个session不是web开发中的session,这里只是一个会话对象而已。还是以登录人人网为例。示例代码如下:
import requests
url = 'http://renren.com/PLogin.do'
data = {'email':'人人邮箱账号','password':'密码'}
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36'
}
# 登录
session = requests.Session()
session.post(url,headers=headers,data=data)
# 访问大鹏个人中心
resp = session.get('http://www.renren.com/880151247/profile')
print(resp.text)
2.07、处理不信任的SSL证书:
对于那些已经被信任的SSL证书的网站,比如http://www.baidu.com/,那么使用requests直接就可以正常的返回响应。如果SSL证书不被信任,那么在请求网站的时候需要添加一个参数verify=False。示例代码如下:
resp = requests.get('http://www.12306.cn/mormhweb/',verify=False)
print(resp.content.decode('utf-8'))
第二章 数据提取
1、XPath语法和lxml库
1.01、什么是XPath?
xpath(XML Path Language)是一门在XML和HTML文档中查找信息的语言,可用来在XML和HTML文档中对元素和属性进行遍历。
1.02、XPath工具
Chrome插件XPath Helper。Firefox插件XPath Checker。
1.03、XPath语法:
选取节点:
XPath使用路径表达式来选取XML文档中的节点或者节点集。这些路径表达式和我们在常规的电脑文件系统中看到的表达式非常相似。
| 表达式 | 描述 | 示例 | 结果 |
|---|---|---|---|
| nodename | 选取此节点的所有子节点 | bookstore | 选取bookstore下所有的子节点 |
| / | 如果是在最前面,代表从根节点选取。否则选择某节点下的某个节点 | /bookstore | 选取根元素下所有的bookstore节点 |
| // | 从全局节点中选取节点,随便在哪个位置 | //book | 从全局节点中找到所有的book节点 |
| @ | 选取某个节点的属性 | //book[@price] | 选取所有book节点的price属性 |
谓语:
谓语用来查找某个特定节点或者包含某个指定的值的节点,被嵌套在方括号中。
在下面的表格中,我们列出了带有谓语的一些路径表达式,以及表达式的结果:
| 路径表达式 | 描述 |
|---|---|
| /bookstore/book[1] | 选取bookstore下的第一个子元素(下标是从1开始的。) |
| /bookstore/book[last()] | 选取bookstore下的倒数第二个book元素 |
| /bookstore/book[position()❤️] | 选取bookstore下前面两个子元素 |
| //book[@price] | 选取拥有price属性的book元素 |
| //book[@price=10] | 选取所有属性price等于10的book元素 |
| //book[contains(@class,‘fl’)] | 当节点拥有多个class时,可使用模糊匹配。 |
通配符:
*表示通配符。
| 通配符 | 描述 | 示例 | 结果 |
|---|---|---|---|
* |
匹配任意节点 | /bookstore/* | 选取bookstore下所有的 |
| @* | 匹配节点中的任何属性 | //book[@*] | 选取所有带有属性的book元素 |
选取多个路径:
通过在路径表达式中使用|运算符,可以选取若干个路径。
示例如下:
# 选取所有book元素以及book元素下所有的title元素
//bookstore/book | //book/title
运算符:
| 运算符 | 描述 | 实例 | 返回值 |
|---|---|---|---|
| | | 计算两个节点集 | //book | //cd | 返回所有拥有book和cd元素的节点元素 |
| + | 加法 | 6+4 | 10 |
| - | 减法 | 6-4 | 2 |
| * | 乘法 | 6*4 | 24 |
| div | 除法 | 8 div 4 | 2 |
| = | 等于 | price=9.80 | 如果price=9.80,则返回true。否则返回false。 |
| != | 不等于 | price!=9.80 | 如果price不等于9.80,则返回true。否则返回false。 |
| < | 小于 | price<9.80 | 如果真,则返回true,否则返回false |
| <= | 小于或等于 | price<=9.80 | 如果真,则返回true,否则返回false |
| > | 大于 | price>9.80 | 如果真,则返回true,否则返回false |
| >= | 大于或等于 | price>=9.80 | 如果真,则返回true,否则返回false |
| or | 或 | price=9.80 or price=9.70 | 如果真,则返回true,否则返回false |
| and | 与 | price=9.80 and price=9.70 | 如果真,则返回true,否则返回false |
| mod | 计算除法的余数 | 5 mod 2 | 1 |
lxml是一个HTML/XML的解析器,主要的功能是如何解析和提取HTML/XML数据。
lxml和正则一样,也是用C实现的,是一款高性能的Python HTML/XML解析器,我们可以利用之前学习的XPath语法,来快速定位特定元素以及节点信息。
lxml python官方文档:https://lxml.de/index.html
需要安装C语言库,可使用pip install lxml。
1.04、lxml的基本使用:
我们可以利用他来解析HTML代码,并且在解析HTML代码的时候,如果HTML代码不规范,他会自动的进行补全。示例代码如下:
从字符串中读取HTML代码:
# 使用 lxml的etree库
from lxml import etree
text = '''
你好
'''
html = etree.HTML(text)
print(etree.tostring(html,encoding='utf-8').decode('utf-8'))
从文件中读取HTML代码:
假设存在一个hello.html文件。利用etree.parse方法,这个方法默认的解析器是XML解析,不会像etree.HTML类一样进行代码补充。示例代码如下:
from lxml import etree
# 有的网站的代码并不规范,直接parse解析会失败,这时需要修改解析器
parser = etree.HTMLParser(encoding='utf-8')
html = etree.parse('hello.html',parser=parser)
print(etree.tostring(html,encoding='utf-8').decode('utf-8'))
print(result)
注意: etree.parse默认的是XML的解析器,有的不规则的网页会解析失败,这时修改parse的解析器。parser = etree.HTMLParser(encoding='utf-8'),然后把parser传入etree.parse()即可。
1.05、在lxml中使用XPath语法:
-
获取所有li标签:
from lxml import etree
html = etree.parse('hello.html')
result = html.xpath('//li')
# 打印- 标签的元素集合
print(result)
-
获取所有li元素下的所有class属性的值:
from lxml import etree
html = etree.parse('hello.html')
result = html.xpath('//li/@class')
print(result)
-
获取li标签下href为www.baidu.com的a标签:
from lxml import etree
html = etree.parse('hello.html')
result = html.xpath('//li/a[@href="www.baidu.com"]')
print(result)
-
获取li标签下href为www.baidu.com的a标签的文本信息,使用text()获取文本信息:
from lxml import etree
html = etree.parse('hello.html')
result = html.xpath('//li/a[@href="www.baidu.com"]/text()')
print(result)
注意事项:
-
使用xpath语法,应该使用Element.xpath方法。来执行xpath的选择。
result = html.xpath('//li')
xpath返回的永远是一个列表。
-
获取文本,是通过xpath中的text()函数。示例代码如下:
html.xpath('//li/a[1]/text()')
-
在某个标签下,再执行xpath函数,获取这个标 签下的子孙元素,那么应该在斜杠之前加一个.,代表是在当前元素下获取。
address = tr.xpath('./td[4]/text()')
2、BeautifulSoup4库
和lxml一样,BeautifulSoup也是一个HTML/XML的解析器,主要的功能也是如何解析和提取HTML/XML数据。
lxml指挥局部遍历,而BeautifulSoup是基于HTML DOM的,会载入整个文档,解析整个DOM树,因此时间和内存开销都会大很多,所以性能低于lxml。
BeautifulSoup用来解析HTML比较简单,api非常人性化,支持CSS选择器、python标准库中的HTML解析器,也支持lxml的XML解析器。
2.01、安装和文档:
- 安装:
pip install bs4
- 中文文档:https://beautifulsoup.readthedocs.io/zh_CN/v4.4.0
2.02、几大解析工具对比:
解析工具
解析速度
使用难度
BeautifulSoup
最慢
最简单
lxml
快
简单
正则
最快
最难
2.03、四个常用的对象:
Beautiful Soup将复杂HTML文档转换成一个复杂的树形结构,每个节点都是python对象,所有对象都可以归纳为4种:
Tag:BeautifulSou中所有的标签都是Tag类型,并且BeautifulSou的对象其实本质上也是一个Tag类型。所以其实一些方法比如:find、find_all并不是BeautifulSou的,而是Tag的。NavigatableString:继承自python中的str,用起来和str一样。BeautifulSouP:继承自Tag。用来生成BeautifulSou树的。对于一些查找方法,比如:find、select这些,其实还是Tag的。Comment:继承自NavigableString。
2.03-1、Tag
通俗点讲就是HTML中的一个个的标签
soup = BeautifulSoup(html,'lxml')
table = soup.find('table')
print(type(table))
我们可以利用soup加标签名轻松的获取这些标签的内容,这些对象的类型是bs4.element.Tag。但是注意,他查找的是在所有内容中的第一个符合条件的要求的标签。如果要查询所有的标签,后面会进行介绍。
Tag有两个重要的属性,分别为name和attrs。
print(soup.name)
# [document] # soup对象本身比较特殊,他的name即为[document]
print(soup.head.name)
# head #对于其他内部标签,输出的值为标签本身的名称。
print(soup.p.attrs)
#{'class':['title'],'name':'dromouse'}
#在这里,我们把p标签的所有属性打印输出,得到的类型是个字典
print(soup.p['class']) #soup.p.get('class)
# ['title'] #还可以利用get方法,传入属性的名称,二者等价。
soup.p['class'] = "newClass"
print(soup.p) #还可以对这些属性和内容进行修改
2.03-2、NavigableString:
如果拿到标签后,还想获取标签中的内容。那么可以通过tag.string获取标签中的文字。
print(soup.p.string)
# The Document's story
print(type(soup.p.string))
# thon
2.03-3、BeautifulSoup:
BeautifulSoup对象表示的是一个文档的全部内容,大部分时候,可以把它当作Tag对象,它支持遍历文档树和搜索文档树中描述的大部分方法。
因为BeautifulSoup对象并不是真正的HTML和XML的Tag,所以它没有name和attribute属性,但有时查看它的name属性是很方便的。所以BeautifulSoup对象包含了一个值为'[document]'的特殊属性.name。
soup.name
# '[document]'
2.03-4、Comment:
Tag、NavigableString、BeautifulSoup几乎覆盖了html和xml中所有的内容,但是还有一些特殊对象,容易让人担心内容是文档的注释部分:
markup = ""
soup = BeautifulSoup(markup)
comment = soup.b.string
print(type(comment))
#
Comment对象是一个特殊类型的NavigableString对象。
2.04、搜索文档树
2.04-1、find和find_all方法:
搜索文档书,一般用的比较多的方法就是两个方法,一个是find,一个是find_all。find方法是找到第一个满足条件的标签后立即返回,只返回一个元素。find_all方法是把所以满足条件的表签都返回。
实例演示:
-
获取所有tr标签
trs = soup.find_all('tr')
for tr in trs:
print(tr)
-
获取第二个tr标签
tr = soup.find_all('tr',limit=2)[1]
-
获取所有class等于even的tr标签
trs = soup.find_all('tr',attrs={'class':'even'})
for tr in trs:
print(tr)
-
将所有id等于test,class也等于test的a标签提取出来。
aList = soup.find_all('a',id='test',class='test')
# 也可以使用attrs属性选择
for a in aList:
print(a)
-
获取所有a标签的href属性
aList = soup.find_all('a')
for a in aList:
# 1.通过下标操作的方式
print(a['href'])
# 2.通过attrs属性的方式
print(a.attrs['href'])
-
获取所有职位信息(纯文本)
- string提取单个文本信息,
- strings提取标签下所有文本信息,
- stripped_strings提取标签下所有非空的文本信息。
trs = soup.find_all('tr')[1:]
zhiwei = {}
for tr in trs:
# tds = tr.find_all('td')
# title = tds[0].string
# city = tds[1].string
# zhiwei['title'] = title
# zhiwei['city'] = city
infos = list(tr.stripped_strings)
zhiwei['title'] = infos[0]
zhiwei['city'] = infos[1]
print(zhiwei)
2.04-2、select方法:
使用以上方法可以方便的找出元素,但有时候使用css选择器的方法可以更加方便。使用css选择器的语法,应该使用select方法。一下列出几种常用的css选择器方法:
-
通过标签名查找:
print(soup.select('a'))
-
通过类名查找:
通过类名查找,则应该在类名前面加一个.。比如查找class=sister的标签。
tg = soup.select('.sister')
-
通过id查找:
通过id查找,一个在id名字前面加#号。
print(soup.select('#idname'))
-
组合查找:
组合查找即和写class文件时,标签名与类名、id名进行组合原理一样,例如查找p标签中,id等于link1的内容,二者需要用空格分开:
print(soup.select('p #link1'))
直接子标签查找,这使用>分隔:
print(soup.select('head>title'))
-
通过属性查找:
查找时还可以加入属性元素,属性需要用中括号括起来,注意属性和标签属于同一节点,所以中间不能加空格,否则会无法匹配到。
print(soup.select('a[href="http://example.com/elsie"]'))
-
获取内容
以上select方法返回的结果都是列表,可以遍历的形式输出,然后用get_text()方法获取内容。
soup = BeautifulSoup(html,'lxml')
print(type(soup.select('title')))
print(soup.select('title')[0].get_text())
for title in soup.select('title'):
print(title.get_text())
2.04-3、find_all的使用:
- 在提取多个标签的时候,第一个参数是标签的名字。然后图个在提取标签的时候想要使用标签属性进行过滤,你们可以在这个方法中通过关键字参数的形式,将属性名以及对应的值传进去。或者是使用
attrs属性,将所有的属性以及对于的值房子啊一个字典中传给attrs属性。
- 有时候,在提取标签的时候,不想提取那么多,那么可以使用
limit参数。进行限制。
2.04-4、find和find_all的区别:
- find:只返回满足条件的第一个标签
- find_all:返回满足条件的所有标签。是个列表。
2.04-5、find和find_all的过滤条件:
- 关键字参数:将属性的名字作为关键字参数的名字,以及属性的值作为关键字参数的值进行过滤。
- attrs参数:将属性条件放到一个字典中,传给attrs参数。
2.04-6、获取标签的属性:
# 1.通过下标操作的方式
print(a['href'])
# 2.通过attrs属性的方式
print(a.attrs['href'])
2.04-7、string、strings、stripped_strings属性和get_text方法:
- string:获取某个标签下的非标签字符串。返回的是个字符串。如果这个标签下有多行字符,那么就获取不到了。
- strings:获取某个标签下的子孙非标签字符串。返回的是个生成器
- stripped_strings:获取某个标签下的子孙非标签字符串,去掉空白字符。返回的是个生成器。
- get_text:获取某个标签下的子孙非标签字符串,不是以列表的形式返回。只是普通字符串。
2.05、遍历文档树
2.05-1、contents和children:
返回某个标签下的直接子元素。其中也包括字符串。他们的区别是:contents返回的是一个列表,children返回的是一个迭代器。
soup = BeautifulSoup(html,'lxml')
head_tag = soup.head
# 返回所有的子节点的列表
print(head_tag.contents)
# 返回所有的子节点的迭代器
for child in head_tag.children:
print(child)
2.05-2、strings和stripped_strings
如果tag中包含多个字符串,可以使用.strings来循环获取:
for string in soup.strings:
print(string)
3、正则表达式和re模块
什么是正则表达式(通俗理解):按照一定的规则,从某个字符串中匹配出想要的数据。这个规则就是正则表达式。
###3.01、正则表达式符号:
-
[]:
- 用来指定字符集:[asdfghjkl],[a-zA-Z]
- 元字符在字符集中不起作用:[akn$]
- 不急匹配不在区间范围内的字符:[ ^io],匹配除io之外的任意字符。
-
^:
- 匹配行首。除非设置MULTILINE标志,它只是匹配字符串的开始。在MULTILINE模式里,它也可以直接匹配字符串中的每个换行。
-
$:
- 匹配行尾,行尾被定义为要么是字符串尾,要么是一个换行字符后面的任何位置。
-
\:
-
反斜杠后面可以加不同的字符以表示不同的特殊意义。
-
也可以用于取消所有的元字符,即当转义字符。
符号
含义
.
匹配除’\n’之外的任何单个字符,如果要匹配包括’\n’在内的任何字符,使用‘[.\n]’
\d
匹配任何十进制数,相当于类[0-9]
\D
匹配任何非数字字符;相当于类[ ^0-9]
\s
匹配任何空白字符,相当于类[\t\n\r\f\v]
\S
匹配任何非空白字符,相当于类[ ^\t\n\r\f\v]
\w
匹配任何字母数字字符,相当于类[a-zA-Z0-9_]
\W
匹配任何非字母数字字符,相当于类[ ^a-zA-Z0-9_]
-
重复:
- 正则表达式第一个功能是能够匹配不定长的字符集,另一个功能就是可以指定正则表达式的一部分的重复次数。在{ }捏填写重复次数
-
*:
- 指定前一个字符可以别匹配零次或更多次,而不是只有一次。匹配引擎会试着重复尽可能多的次数(不超过整数界定范围,20亿)
- a[bcd]*b----‘abcbd’。
-
+:
- 表示匹配一次或更多次。
- 和*的区别,*匹配零次或更多次,所有可以根本就不出现,而’+’则要求至少出现一次
-
?:
- 加在重复的后面,做最小匹配,即非贪婪模式。
- 匹配一次或零次,你可以认为它用于标识某事物是可选的
-
{m,n}:
- 其中m和n是十进制整数,该限定符的意思是至少有m个重复,至多到n个重复。
- 忽略m会认为下边界是0,而忽略n的结果将是上边界无穷大(实际是20亿)
- {0,}等同于‘’,{1,}等同于‘+’,而{0,1}则与‘?’相同。如果可以的话,最好使用‘’,‘+’或‘?’。
-
()分组:
- 利用
()来进行多种正则的选择。匹配时优先返回分组的值。
-
|:
- 匹配多个表达式或字符串。
3.02、正则表达式常用的匹配规则:
-
匹配某个字符串:
text = 'hello'
ret = re.march('he',text)
print(ret.group())
>>he
以上便可以在hello中,匹配出he。
3.03、转义字符和原生字符串
在正则表达式中,有些字符串是有特殊意义的字符。因此如果想要匹配这些字符,那么就必须使用反斜杠进行转义。比如$代表的是以…结尾,如果想要匹配$,那么就必须使用\$。
text = 'apple price is \$99,orange is $88'
ret = re.search('\$(\d+)',text)
print(ret.group())
>>$99
原生字符串:
在正则表达式中,\是专门用来转义的。在python中\也是用来转义的。因此如果想要在普通字符串中匹配出\,那么要给出4个\。
text = 'apple \c'
ret = re.search('\\\\c',text)
print(ret.group())
因此要使用原生字符串就可以解决这个问题:
text = 'apple \c'
ret = re.search(r'\\c',text)
print(ret.group())
3.04、正则表达式函数:
3.04-1、re.compile()函数
compile函数用于编译正则表达式,生成一个正则表达式( Pattern )对象,供 match() 和 search() 这两个函数使用。
语法格式为:re.compile(pattern[, flags])
-
pattern:一个字符串形式的正则,字符串前加r,反斜杠就不会被当作转义字符。
-
flags:可选,表示匹配模式,比如忽略大小写,多行模式等,具体参数如下:
符号
含义
re.I
忽略大小写
re.L
表示特殊字符集\w, \W, \b, \B, \s, \S 依赖于当前环境
re.M
多行模式
re.S
即为.并且包括换行符在内的任意字符(单纯的.不包括换行符)
re.U
表示特殊字符集 \w, \W, \b, \B, \d, \D, \s, \S 依赖于 Unicode 字符属性数据库
re.X
为了增加可读性,忽略空格和 # 后面的注释
3.04-2、用于匹配的函数:
方法/属性
作用
match()
在字符串刚开始的位置匹配,如果想要匹配换行符,传入一个flags=re.DOTALL就可以了。
search()
扫描字符串,找到这个RE匹配的位置
findall()
找到RE匹配的所有子串,并把它们作为一个列表返回
finditer()
找到RE匹配的所有子串,并把它们作为一个迭代器返回
如果没有匹配到,match()和search()将返回None,如果成功,返回一个‘MatchObject’实例 。
MatchObject实例方法(即匹配成功后使用的方法):
方法/属性
作用
group()
返回被RE匹配的字符串。
start()
返回匹配开始的位置。
end()
返回匹配结束的位置
span()
返回一个元组包含匹配(开始,结束)
3.04-3、分组:
在正则表达式中,可以对过滤到的字符串进行分组。分组使用()。
group:和group(0)是等价的,返回的是整个满足条件的字符串。groups:返回的是里面的子组。索引从1开始。group(1):返回的是第一个子组,可以传入多个。
实例如下:
text = 'apple price is $99,orange price is $10'
ret = re.search(r'.*(\$\d+).*(\$\d+)',text)
print(ret.group())
print(ret.group(0))
print(ret.group(1))
print(ret.group(2))
print(ret.groups())
3.04-4、match():
从开始的位置进行匹配。如果开始的位置没有匹配到,直接报错。
text = 'hello'
ret = re.match('h',text)
print(ret.group())
>>h
如果第一个字母不是h,那么就会失败。
text = 'ahello'
ret = re.match('h',text)
print(ret.group())
>>AttributeError:'NoneType' object has no attribute 'group'
如果想要匹配换行的数据,那么就要传入一个flag=re.DOTALL,就可以匹配换行符了。
text = 'abc\nabc'
ret = re.match('abc.+abc',text,re.DOTALL)
print(ret.group())
3.04-5、search():
在字符串中找满足条件的字符。如果找到了,就返回。只会返回第一个满足条件的。
text = 'apple price is $99,orange price is $88'
ret = re.search('\d+',text)
print(ret.group())
>>99
3.04-6、findall():
找出满足条件的,返回的是一个列表。
text = 'apple price is $99,orange price is $88'
ret = re.search('\d+',text)
print(ret.group())
>>['99','88']
3.04-7、检索替换re.sub():
re模块提供了re.sub()用于替换字符串中的匹配项。
语法:re.sub(pattern,repl,string,count=0,flags=0)
参数:
- pattern:正则中的模式字符串。
- repl:替换的字符串,也可为一个函数。
- string:要被查找替换的原始字符串。
- count:模式匹配后替换的最大次数,默认为0,表示替换所有的匹配。
3.04-8、检索替换re.subn()
返回结果比re.sub()多了一个替换次数。
3.04-9、re.split()
split 方法按照能够匹配的子串将字符串分割后返回列表,它的使用形式如下:
re.split(pattern, string[, maxsplit=0, flags=0])
-
pattern:匹配的正则表达式
-
string:要匹配的字符串
-
maxsplit:分割次数,maxsplit=1分割一次,默认为0,不限次数。
import re
s = '123+456-789*111'
re.split(r'[\+\-\*]',s)
>['123','456','789','111']
第三章 数据储存
1、json文件处理:
1.01、什么是json:
JSON(JavaScript Object Notation,JS对象标记)是一种轻量级的数据交换格式。它基于ECMAScript(w3c制定的js规范)的一个子集,采用完全独立于编程语言的文本格式来存储和表示数据。简洁欸和清晰的层次结构使得JSON成为理想的数据交换语言。易于人阅读和编写,同时也易于机器解析和生成,并有效地提升网络传输效率。
1.02、JSON支持数据格式:
- 对象(字典)。使用花括号。
- 列表(数组)。使用方括号。
- 整型、浮点型。
- 字符串类型(字符串必须要用双引号,不能用单引号)。
多个数据之间使用逗号分开。
注意:json本质上就是一个字符串。
1.03、字典和列表转JSON:
import json
books = [
{
'title':'钢铁是怎么炼成的',
'price':9.8
},
{
'title':'红楼梦',
'price':10.5
}
]
json_str = json.dumps(books,ensure_ascii=False)
print(json_str)
因为json在dump的时候,只能存放ASCII的字符,因此会将中文进行转义,这时候我们可以使用ensure_ascii=False关闭这个特性。
在python中。只有基本数据类型才能转换成JSON格式的字符串。也即:int、float、str、list、dict、tuple。
1.04、将json数据直接dump到文件中:
dump和dumps的区别就是:dump是直接到文件中,dumps是转换成json字符串。
json模块中除了dumps函数,还有一个dump函数,这个函数可以传入一个文件指针,直接将字符串dump到文件中。
import json
books = [
{
'title':'钢铁是怎么炼成的',
'price':9.8
},
{
'title':'红楼梦',
'price':10.5
}
]
with open('book.json','w',encoding='utf-8')as fp:
json.dump(books,fp,ensure_ascii=False)
1.05、将一个json字符串load成python对象:
json_str = '[{"title":"钢铁是怎么炼成的","price":9.8},{"title":"红楼梦","price":10.5}]'
books = json.loads(json_str,encoding='utf-8')
print(type(books))
print(books)
1.06、直接从文件中读取json:
import json
with open('a.json',encoding='utf-8')as fp:
json_str = json.load(fp)
print(json_str)
2、csv文件处理:
2.01、读取csv文件:
import csv
with open('stock.csv','r')as fp:
reader = csv.reader(fp)
titles = next(reader)
# 跳过标题行
for x in reader:
print(x)
这样操作,以后获取数据的时候,就要通过下标来获取数据,如果想要在获取数据的时候通过标题来获取。那么可以使用DictReader。
import csv
with open('stock.csv','r')as fp:
reader = csv.DictReader(fp)
for x in reader:
print(x['username'])
2.02、写入数据到csv文件:
写入数据到csv文件,需要创建一个writer对象,主要用到两个方法。一个是writerow,这个是写入一行。一个是writerows,这个是写入多行。
import csv
headers = ['name','age','classroom']
values = [
('fdk1',22,'111'),
('fdk2',23,'222'),
('fdk3',24,'333')
]
with open('test.csv','w',newline='')as fp:
writer = csv.writer(fp)
writer.writerow(headers)
writer.writerows(values)
也可以使用字典的方式把数据写入进去。这时候就需要使用DictWriter了。
import csv
headers = ['name','age','classroom']
values = [
{'name':'fdk1','age':22,'classroom':'111'},
{'name':'fdk2','age':23,'classroom':'222'},
]
with open('test.csv','w',newline='')as fp:
writer = csv.DictWriter(fp,headers)
# 写入表头数据的时候,需要调用writeheader方法。
writer.writeheader()
writer.writerow({'name':'fdk1','age':22,'classroom':'111'})
writer.writerows(values)
3、MySQL操作
3.01、数据库连接:
数据库连接之前。首先先确认以下工作完成,这里我们以一个pymysql_test数据库为例。
import pymysql
db = pymysql.connect(
host='127.0.0.1',
user='root',
password='root',
database='pymysql_test',
port=3306
)
cursor = db.cursor()
cursor.execute('select 1')
data = cursor.fetchone()
print(data)
db.close()
3.02、插入数据:
import pymysql
db = pymysql.connect(
host='127.0.0.1',
user='root',
password='root',
database='pymysql_test',
port=3306
)
cursor = db.cursor()
sql="""
insert into user(id,username,gender,age,password)values(null,'abc',1,18,'111111);
"""
cursor.execute(sql)
db.commit()
db.close()
如果在数据还不能保证的情况下,可以使用以下方式来插入数据:
sql = """
insert into user(id,username,gender,age,password)
values(null,%s,%s,%s,%s);
"""
cursor.execute(sql,('spider',1,20,'222222'))
3.03、查找数据:
使用pymysql查询数据。可以使用fetch*方法。
fetchone():这个方法每次只获取一条数据。fetchall():这个方法接收全部的返回结果。fetchmany(size):可以获取指定数量的数据。
result = cursor.fetchone()
# result = cursor.fetchall()
# result = cursor.fetchmany(3) 获取3条
3.04、删除数据:
cursor.db.cursor()
sql="""
delete drom user where id=1
"""
cursor.execute(sql)
db.commit()
db.close()
3.05、更新数据:
sql="""
update user set username='aaa' where id=1
"""
cursor.execute(sql)
db.commit()
db.close()
4、MongoDB数据库操作:
MongoDB是一个基于分布式文件存储的NoSQL数据库。在处理海量数据的时候会比MySQL更有优势。爬虫如果上一个量级,可能就会比较推荐使用MongoDB,当然没有上量的数据也完全可以使用MongoDB来存储数据。因此学会使用MongoDB也是爬虫开发工程师必须掌握的一个技能。
4.01、MongoDB概念介绍:
SQL术语/概念MongoDB术语/概念解释/说明
databasedatabase数据库
tablecollection数据库表/集合
rowdocument数据记录行/文档
columnfield数据字段/域
indexindex索引
joinsjoins表连接,MongoDB不支持
primary keyprimary key主键,MongoDB自动将_id字段设置为主键
###4.02、MongoDB三元素:
三元素:数据库、集合、文档。
-
文档(document):就是关系型数据库中的一行。文档是一个对象,由键值对构成,是json的扩展形式。
{'name':'abc','age':18}
-
集合(collection):就是关系型数据库中的表。可以存储多个文档,结构可以不固定。如可以存储如下文档在一个集合中。
{'name':'abc','age':18}
{'name':'xxx','gender':'1'}
{'title':'yyy','price':20.9}
4.03、MongoDB基本操作命令:
db:查看当前的数据库。show dbs:查看所有的数据库。use 数据库名:切换数据库。如果数据库不存在,则创建一个。(创建完成后需要插入数据库才算创建成功)db.dropDatabase():删除当前指向的数据库。db.集合名.insert(value):添加数据到指定集合中。db.集合名.find():从指定的集合中查找数据。
更多命令:http://www.runoob.com/mongodb/mongodb-tutorial.html
4.04、Python操作MongoDB:
4.04-1、安装pymongo:
要用python操作mongodb,必须下载一个驱动程序,这个驱动程序就是pymongo:
pip install pymongo
4.04-2、连接MongoDB:
import pymongo
#获取连接的对象
client = pymongo.MongoClient('127.0.0.1',port=27017)
#获取数据库
db = client.test
#获取集合(表)
collection = db.qa
#插入一条数据到集合中
collection.insert_one({
'username':'abc',
'password':'111111'
})
4.04-3、数据类型:
类型
说明
Object ID
文档ID
String
字符串,最常用,必须是有效的UTF-8
Boolean
存储一个布尔值,true或false
Integer
整数可以是32位或64位,取决于服务器
Double
存储浮点型
Arrays
数组或列表,多个值存储到一个键
Object
用于嵌入式的文档,即一个值为一个文档
Null
存储Null值
Timestamp
时间戳,表示从1970-1-1到现在的总秒数
Date
存储当前日期或事件的UNIX时间格式
4.04-4、操作MongoDB:
操作MongoDB的主要方法如下:
-
insert_one:加入一条文档数据到集合中。
collection.insert_one({
'username':'abc',
'password':'111111'
})
-
insert_many:加入多条文档到集合中。
collection.insert_many([
{
'username':'abc',
'password':'111111'
},
{
'username':'aaa',
'password':'123123'
},
])
-
find_one:查找一条文档对象。
result = collection.find_one()
print(result)
#或者是指定条件
result = collection.find_one({'username':'aaa'})
print(result)
-
update_one:更新一条文档对象。
#前面是条件,后面字典是要设置的东西。
collection.update_one({'username':'abc'},{'$set':{'username':'aaa'}})
-
update_many:更新多条文档对象。
collection.update_many({'username':'abc'},{'$set':{'username':'aaa'}})
-
delete_one:删除一条文档对象。
collection.delete_one({'username':'abc'})
-
delete_many:删除多条文档对象。
#删除符合条件的所有数据
collection.delete_many({'username':'abc'})
第四章 爬虫进阶
1、多线程爬虫
有些时候,比如下载图片,因为下载图片是一个耗时的操作。如果采用之前那种同步的方式下载。那效率肯定会特别慢。这时候我们就可以考虑使用多线程的方式来下载图片。
1.01、多线程介绍:
多线程是为了同步完成多项任务,通过通过资源使用效率提高系统的效率。线程是在同一时间需要完成多项任务的时候实现的。最简单的比喻多线程就像火车的每一节车厢,而进程就是火车。车厢离开火车无法跑动,同理火车也可以有多节车厢。多线程的出现就是为了提高效率。同时它的出现也带来了一些问题。
1.02、threading模块介绍:
threading模块是python中专门提供用来做多线程编程的模块。threading模块中最常用的类是Thread。以下是个简单的多线程例子:
import threading
import time
def coding():
for x in range(3):
print('%s正在写代码'%x)
time.sleep(1)
def drawing():
for x in range(3):
print('%s正在画图'%x)
time.sleep(1)
def single_thread():
coding()
drawing()
def multi_thread():
t1 = threading.Thread(target=coding)
t2 = threading.Thread(target=drawing)
t1.start()
t2.start()
if __name__ == '__main__':
multi_thread()
1.03、查看线程数量:
使用threading.enumerate()函数可以看到当前线程的数量。
1.04、查看当前线程的名字:
使用threading.current_thread()可以看到当前线程的信息。
1.05、继承自threading.Thread类:
为了让代码更好的封装。可以使用threading模块下的Thread类,继承自这个类,然后实现run方法,线程就会自动运行run方法中的代码。
import threading
import time
class CodingThread(threading.Thread):
def run(self):
for x in range(3):
print('%s正在写代码' %threading.current_thread())
time.sleep(1)
class DrawingThread(threading.Thread):
def run(self):
for x in range(3):
print('%s正在写画图' %threading.current_thread())
time.sleep(1)
def multi_thread():
t1 = CodingThread()
t2 = DrawingThread()
t1.start()
t2.start()
if __name__ == '__main__':
multi_thread()
1.06、多线程共享全局变量的问题:
多线程都是在同一个进程中运行的。因此在进程中的全局变量所有线程都是可共享的。这就造成了一个问题,就是因为线程执行的顺序是无序的。有可能会造成数据的错误。比如以下代码:
import threading
tickets = 0
def get_ticket():
global tickets
for x in range(1000000):
tickets += 1
print('tickets:%d' %tickets)
def main():
for x in range(2):
t = threading.Thread(target=get_ticket)
t.start()
if __name__ == '__main__':
main()
因为多线程运行的不确定性。因此最后的结果可能是随机的。
1.07、锁机制:
为了解决以上使用共全局共享全局变量的问题。threading提供了一个Lock类,这个类可以在某个线程访问某个变量的时候加锁,其他线程此时就不能进来,知道当前线程处理完后,把锁释放了,其他线程才能进来处理。示例如下:
import threading
tickets = 0
gLock = threading.Lock()
def get_ticket():
global tickets
#上锁
gLock.acquire()
for x in range(1000000):
tickets += 1
#释放锁
gLock.release()
print('tickets:%d' %tickets)
def main():
for x in range(2):
t = threading.Thread(target=get_ticket)
t.start()
if __name__ == '__main__':
main()
1.08、Lock版本的生产者与消费者模式:
生产者和消费者模式是多线程开发中常见的一种模式。生产者的线程专门用来生产一些数据,然后存放到一个中间的变量中。消费者再从这个中间的变量中取出数据进行消费。但是因为要使用中间变量,中间变量经常是一些全局变量,因此需要使用锁来保证数据的完整性。以下是使用threading.Lock锁实现的“生产者与消费者模式”的例子:
import threading, time
import random
gMoney = 1000
gLock = threading.Lock()
# 记录生产者生产的次数,达到10次就不生产了
gTimes = 0
class Producer(threading.Thread):
def run(self):
global gMoney
global gTimes
while True:
money = random.randint(100, 1000)
gLock.acquire()
if gTimes >= 10:
gLock.release()
break
gMoney += money
print('%s生产了%d元,现在总额为%d' % (threading.current_thread(), money, gMoney))
gTimes += 1
gLock.release()
time.sleep(0.5)
class Consumer(threading.Thread):
def run(self):
global gMoney
while True:
money = random.randint(100, 1000)
gLock.acquire()
if gMoney >= money:
gMoney -= money
print('%s消费了%s元钱,剩余%s元。' % (threading.current_thread(), money, gMoney))
else:
# 如果钱不够了,有可能是已经超过了次数,这时候就判断一下
if gTimes >= 10:
gLock.release()
break
print('%s消费了%s元钱,剩余%s元钱,不足!' % (threading.current_thread(), money, gMoney))
gLock.release()
time.sleep(0.5)
def main():
for i in range(5):
Consumer(name='消费者线程%d' % i).start()
for i in range(3):
Producer(name='生产者线程%d' % i).start()
if __name__ == '__main__':
main()
1.09、Condition版的生产者与消费者模式:
Lock版本的生产者与消费者模式可以正常的运行。但是存在一个不足,在消费者中,总是通过while True死循环并且上锁的方法去判断钱够不够。上锁是一个很耗费CPU资源的行为。因此这种方式不是最好的。还有一种更好的方式便是使用threading.Confition来实现。threading.Condition可以在没有数据的时候处于阻塞等待状态。一旦有合适的数据了,还可以使用notify相关的函数来通知其他处于等待状态的线程。这样就可以不用做一些无用的上锁和解锁的操作。可以提高程序的性能。首先对threading.Condition相关的函数做个介绍,threading.Condition类似threading.Lock,可以在修改全局数据的时候进行上锁,也可以在修改完毕后进行解锁。以下将一些常用的函数做个简单的介绍:
acquire:上锁。release:解锁。wait:将当前线程处于等待状态,并且会释放锁。可以被其他线程使用notify和notify_all函数唤醒。被唤醒后会继续等待上锁,上锁后继续执行下面的代码。notify:通知某个正在等待的线程,默认是第1个等待的线程。notify_all:通知所有正在等待的线程。notify和notify_all不会释放锁。并且需要在release之前调用。
Condition版生产者与消费者模式代码如下:
import threading, time
import random
gMoney = 1000
gCondotion = threading.Condition()
gTotalTimes = 10
gTimes = 0
class Producer(threading.Thread):
def run(self):
global gMoney
global gTimes
global gCondotion
while True:
money = random.randint(100, 1000)
gCondotion.acquire()
if gTimes >= gTotalTimes:
gCondotion.release()
print('当前生产者总共生产%s次' % gTimes)
break
gMoney += money
print('%s生产了%d元,现在总额为%d' % (threading.current_thread(), money, gMoney))
gTimes += 1
time.sleep(0.5)
gCondotion.notify_all()
gCondotion.release()
class Consumer(threading.Thread):
def run(self):
global gCondotion
global gMoney
global gTimes
while True:
money = random.randint(100, 1000)
gCondotion.acquire()
while gMoney < money:
if gTimes >= gTotalTimes:
gCondotion.release()
return
print('%s准备消费%d元钱,剩余%s元。余额不足' % (threading.current_thread(), money, gMoney))
gCondotion.wait()
gMoney -= money
print('%s消费了%d元钱,剩余%s元。' % (threading.current_thread(), money, gMoney))
gCondotion.release()
time.sleep(0.5)
def main():
for i in range(3):
t = Consumer(name='消费者线程%s' % threading.current_thread())
t.start()
for i in range(3):
t = Producer(name='生产者线程%s' % threading.current_thread())
t.start()
if __name__ == '__main__':
main()
1.10、Queue线程安全队列:
在线程中,访问一些全局变量,加锁是一个经常的过程。如果你是想把一些数据存储到某个队列中,那么Python内置了一些线程安全的模块叫做queue模块。Python中的queue模块中提供了同步的、线程安全的队列类,包括FIFO(先进先出)队列Queue,LIFO(后入先出)队列LifoQueue。这些队列都实现了锁原语(可以理解为原子操作,即要么不做,要么都做完),能够在多线程中直接使用。可以使用队列来实现线程间的同步。相关的函数如下:
- 初始化
Queue(maxsize):创建一个先进先出队列。
qsize():返回队列的大小。empty():判断队列是否为空。full():判断队列是否满了。get():从队列中取最后一个数据。put():将一个数据放到队列中。- 参数
block:在get()和put()中,有一个参数block,默认为true,作用是当queue为空的时候,是否阻塞直到queue中存在数据。
1.11、使用生产者与消费者模式多线程下载表情包
# encoding: utf-8
import requests, os, re
from urllib import request
from lxml import etree
import threading
from queue import Queue
class Producer(threading.Thread):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36'
}
def __init__(self, page_queue, img_queue, *args, **kwargs):
super(Producer, self).__init__(*args, **kwargs)
self.page_queue = page_queue
self.img_queue = img_queue
def run(self):
while True:
if self.page_queue.empty():
break
url = self.page_queue.get()
self.parse_page(url)
def parse_page(self, url):
response = requests.get(url, headers=self.headers)
text = response.text
html = etree.HTML(text)
imgs = html.xpath('//div[@class="page-content text-center"]//img[@class!="gif"]')
for img in imgs:
img_url = img.get('data-original')
alt = img.get('alt')
alt = re.sub(r'[,,\.。\??\*!!]', '', alt)
ext = os.path.splitext(img_url)[1]
filename = alt + ext
print(filename + ' 下载完成!')
self.img_queue.put((img_url, filename))
class Consumer(threading.Thread):
def __init__(self, page_queue, img_queue, *args, **kwargs):
super(Consumer, self).__init__(*args, **kwargs)
self.page_queue = page_queue
self.img_queue = img_queue
def run(self):
while True:
if self.img_queue.empty() and self.page_queue.empty():
break
img_url, filename = self.img_queue.get()
request.urlretrieve(img_url, 'images/' + filename)
def main():
page_queue = Queue(100)
img_queue = Queue(1000)
for i in range(1, 101):
url = 'http://www.doutula.com/photo/list/?page={}'.format(i)
page_queue.put(url)
for i in range(5):
t = Producer(page_queue, img_queue)
t.start()
for i in range(5):
t = Consumer(page_queue, img_queue)
t.start()
if __name__ == '__main__':
main()
1.12、GIL全局解释器锁:
Python自带的解释器是CPython。CPython解释器的多线程实际上是一种假的多线程(在多核CPU中,只能利用一核,不能利用多核)。同一时刻只有一个线程在执行,为了保证同一时间只有一个线程在执行,在CPython解释器中有一个东西叫做GIL,叫做全局解释器锁。这个解释器锁是有必要的。因为CPython解释器的内存管理不是线程安全的。当然除了CPython解释器,还有其他解释器,有些解释器是没有GIL锁的,如下:
Jython:用Java实现的python解释器。不存在GIL锁。IronPython:用.net实现的python解释器。不存在GIL锁。PyPy:用python实现的python解释器。存在GIL锁。
GIL虽然是一个假的多线程。但是在处理一些IO操作(比如文件读写和网络请求)还是可以在很大程度上提高效率的。在IO操作上建议使用多线程提供效率。在一些CPU计算操作上不建议使用多线程,而建议使用多线程。
2、动态网页数据抓取
2.01、什么是AJAX:
AJAX(Asynchronouse JavaScript And XML)异步JavaScript和XML。用于在后台与服务器进行少量数据交换,Ajax可以使网页实现异步更新。这意味着可以在不重新加载整个网页的情况下,对网页的某个部分进行更新。传统的网页(不使用Ajax)如果需要更新内容,必须重载整个页面。因为传统的在传输数据格式方面,使用的是XML语法。因此叫做Ajax,其实现在数据交互基本上都是使用JSON。使用Ajax加载的数据,即使使用了JS,将数据渲染到了浏览器中,在右键->查看网页源代码还是不能通过Ajax加载的数据,只能看到使用这个url加载的html代码。
2.02、获取Ajax数据的方式:
- 直接分析
Ajax调用的接口。然后通过代码请求这个接口。
- 利用
Selenium+chromedriver模拟浏览器行为获取数据。
方式
优点
缺点
分析接口
直接可以请求到数据。不需要做一些解析工作。代码量少,性能高
分析接口比较复杂,特别是一些通过js混淆的接口,要有一定的js功底。容易被发现是爬虫。
selenium直接模拟浏览器的行为。浏览器能请求到的,使用selenium也能请求到。爬虫更稳定
代码量多。性能低
2.03、Selenium+chromedriver获取动态数据:
Selenium相当于一个机器人。可以模拟人类在浏览器中的一些行为,自动处理浏览器上的一些行为,比如点击,填充数据,删除cookie等。chromedriver是一个Chrome浏览器的驱动程序,使用它才可以驱动浏览器,当然针对不同的浏览器有不同的driver。
2.04、安装Selenium和chromedriver:
-
安装seenium:selenium有很多语言版本,有java、ruby、python等。
pip install selenium
-
安装chromedriver:下载完成后,放大不需要权限的纯英文目录下就可以了。(PS:可以放到python安装目录下的Scripts目录下,这样相当于设置到了环境变量中了,不需要在代码中重新指定)
2.05、快速入门:
现在以一个简单的获取边度首页的例子来讲下selenium和chromedriver如何快速入门:
from selenium import webdriver
#chromedriver的绝对路径,如果在环境变量中存在,则不需要指定
driver_path = r'D:\路径'
#初始化一个driver,并且指定chromedriver的路径
driver = webdriver.Chrome(executable_path=driver_path)
#请求网页
driver.get('https://www.baidu.com')
# 通过page_source获取网页源码
print(driver.page_source)
2.06、selenium常用操作:
更多教程:https://selenium-python.readthedocs.io/installation.html#introduction
2.06-1、关闭页面:
driver.close():关闭当前页面。driver.quit():退出整个浏览器。
2.06-2、定位元素:
-
find_element_by_id:根据id查找某个元素。等价于:
submitTag = driver.find_element_by_id('su')
submitTag = driver.find_element(By.ID,'su')
-
find_element_by_class_name:根据类名查找元素。等价于:
submitTag = driver.find_element_by_class_name('su')
submitTag = driver.find_element(By.CLASS_NAME,'su')
-
find_element_by_name:根据name属性的值来查找元素。等价于:
submitTag = driver.find_element_by_name('email')
submitTag = driver.find_element(By.NAME,'email')
-
find_element_by_tag_name:根据标签名来查找元素。等价于:
submitTag = driver.find_element_by_tag_name('div')
submitTag = driver.find_element(By.TAG_NAME,'div')
-
find_element_by_xpath:根据xpath语法来获取元素。等价于:
submitTag = driver.find_element_by_xpath('//div')
submitTag = driver.find_element(By.XPATH,'//div')
-
find_element_by_css_selector:根据css选择器选择元素。等价于:
submitTag = driver.find_element_by_css_selector('//div')
submitTag = driver.find_element(By.CSS_SELECTOR,'//div')
要注意,find_element是获取第一个满足条件的元素。find_elements是获取所有满足条件的元素。
2.06-3、操作表单元素:
-
操作输入框:分为两步。第一步:找到这个元素。第二步:使用send_keys(value),将数据填充进去。示例如下:
inputTag = driver.find_element_by_id('kw')
inputTag.send_keys('python')
使用clear方法可以清除输入框中的内容。示例如下:
inputTag.clear()
-
操作checkbox:因为要选中checkbox标签,在网页中是通过鼠标点击的。因此想要选中checkbox标签,那么先选中这个标签,然后执行click事件。示例如下:
rememberTag = driver.find_element_by_name('rememberMe')
rememberTag.click()
-
选择select:select元素不能直接点击。因为点击后还需要选中元素。这时候selenium就专门为select提供了一个类selenium.webdriver.support.ui.Select。将获取到的元素当成参数传到这个类中,创建这个对象。以后就可以使用这个对象进行选择了。示例如下:
from selenium.webdriver.support.ui import Select
#选中这个标签,然后使用Select创建对象
selectTag = Select(driver.find_element_by_name('jumpMenu'))
#根据索引选择
selectTag.select_by_index(1)
#根据值选择
selectTag.select_by_value('http://www.baidu.com')
#根据可视的文本选择
selectTag.select_by_visible_text('百度')
#取消选中的所有选项
selectTag.deselect_all()
-
操作按钮:操作按钮有很多种方式。比如单机、右击、双击等。最常用的就是点击,直接调用click函数。示例如下:
inputTag = driver.find_element_by_id('su')
inputTag.click()
2.07、鼠标行为链:
有时候对鼠标的操作可能要有很多步,那么这时候就可以使用鼠标行为链类ActionChains来完成。比如现在将鼠标移动到某个元素上并执行点击事件。示例如下:
inputTag = driver.find_element_by_id('kw')
submitTag = driver.find_element_by_id('su')
actions = ActionChains(driver)
actions.move_to_element(inputTag)
actions.send_keys_to_element(inputTag,'python')
actions.move_to_element(submitTag)
actions.click(submitTag)
actions.perform()
还有更多的鼠标操作。
click_and_hold(element):点击但不松开鼠标。context_click(element):右键点击。double_click(element):双击。
更多方法:https://selenium-python.readthedocs.io/api.html
2.08、Cookie操作:
-
获取所有的cookie:
for cookie in driver.get_cookies():
print(cookie)
-
根据cookie的key获取value:
value = driver.get_cookie(key)
-
删除所有的cookie:
driver.delect_all_cookies()
-
删除某个cookie:
driver.delect_cookie(key)
2.09、页面等待:
现在的网页越来愈多采用了Ajax技术,这样程序便不能确定何时某个元素完全加载出来了。如果实际页面等待事件过长导致某个dom元素还没出来,但是你的代码直接使用了这个WebElement,那么就会抛出NullPointer的异常。为了解决这个问题。所有Selenium提供了两种等待方式:一种是隐式等待、一种是显式等待。
-
隐式等待:调用driver.implicitly_wait定义等待时长。那么在获取任何元素之前,会先等待定义时长的时间。示例如下:
driver = webdriver.Chrome()
#等待10秒
driver.implicitly_wait(10)
#请求网页
driver.get('https://www.baidu.com')
-
显式等待:显式等待式表明某个条件成立后才执行获取元素的操作。也可以在等待的时候指定一个最大等待时间,如果超过这个时间那么就跑出一个异常。显式等待应该使用selenium.webdriver.support.excepted_conditions期望的条件和selenium.webdriver.support.ui.WebDriverWait来配合完成。示例如下:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import excepted_conditions as EC
driver = webdriver.Chrome()
driver.get('http://somedomain/url_that_delays_loading')
try:
element = WebDriverWait(driver,10).until(
EC.presence_of_element_located(By.ID,'myDynamicElement')
)
finally:
driver.quit()
-
一些其他的等待条件:
presence_of_element_located:某个元素已经加载完毕,即需要的元素已存在。presence_of_all_element_located:网页中所有满足条件的元素都加载完毕 了。element_to_be_clickable:某个元素可以点击了。
更多条件参考:https://selenium-python.readthedocs.io/waits.html
2.10、切换页面:
有时候窗口中有很多子tab页面。这时候肯定需要进行切换。selenium提供了一个叫做switch_to.window来进行切换,具体切换到哪一个页面,可以从driver.window_handles中找到。示例如下:
#打开一个新的页面
self.driver.execute_script('window.open("%s")'%url)
#仅仅打开新的页面并没有用,driver的源码仍然指向旧的页面。
#所以需要使用driver.switch_to.window来切换到指定的窗口
#从driver.window_handles中取出具体的第几个窗口
#切换到新的页面
self.driver.switch_to.window(self.driver.window_handles[1])
driver.window_handles:是一个列表,他会按照driver打开的顺序来存储窗口的句柄。
2.11、设置代理IP:
有时候频繁爬取一些网页。服务器发现你是爬虫后会封掉你的IP地址。这时候我们可以更改代理IP。更改代理IP,不同的浏览器有不同的方式。这个以Chrome为例:
from selenium import webdriver
options = webdriver.ChromeOptions()
options.add_argument('--procy-server=http://110.73.2.248:8123')
driver_path = 'chromedriver路径'
driver = webdriver.Chrome(executable_path=driver_path,chrome_options=options)
driver.get('http://httpbin.org/ip')
2.12、WebElement元素:
from selenium.webdriver.remote.webelement imort WebElement类是每个获取出来的元素的所属类。
一些常用的属性:
get_attribute():这个标签的某个属性的值。screentshot获取当前页面的截图。这个方法只能在driver上使用。
driver的对象类也是继承自WebElement。
3、图形验证码识别技术:
阻碍我们爬虫的。有时候正是在登陆或请求一些数据的时候的图形验证码。将图片翻译成文字一般被称为光学文字识别(Optical Character Recognition),简写为OCR。实现OCR的库不是很多,特别是开源库。这里使用一个比较优秀的图像识别开源库:Tesseract。
3.01、Tesseract:
Tesseract是一个OCR库,目前由谷歌赞助。Tesseract是目前公认最优秀、最准确的开源OCR库。Tesseract具有很高的识别度,也具有很高的灵活性,他可以通过训练识别任何字体。
Window系统下安装:
在以下链接下载可执行文件,然后点击下一步安装即可。
3.02、设置环境变量:
安装完成后,如果想要在命令行中使用Tesseract,那么应该设置环境变量。Mac和Linux在安装的时候会默认设置好。在Windows下把tesseract.exe所在路径添加到PATH环境变量中。
还有一个环境变量需要设置,把训练的数据文件路径也添加到环境变量中。在环境变量中新建TESSDATA_PREFIX,值为D:\Tesseract-OCR\tessdata。
注意:D:\Tesseract-OCR\tessdata文件夹存放的时训练好的语言数据包,把需要的语言包下载好放进去即可。
3.03、在命令行中使用tesseract识别图像:
如果想要在cmd下能够使用tesseract命令,那么需要把tesseract.exe所在路径添加到PATH环境变量中。然后可以使用命令:tesseract 图片路径 解析结果文件路径。
tesseract a.png a
#默认输出的文件时txt文件
tesseract a.png a.txt -l chi_sim
#-l 用于指定识别语言
那么就会识别出a.png中的文字,并且把文字写入到a.txt中。如果不想写入文件直接想在终端显示,那么不用加文件名就可以了。
3.04、在代码中使用tesseract是被图像:
在python中操作tesseract。需要安装一个库,叫做pytesseract。通过pip安装即可。
并且,需要读取图片,需要借助第三方库PIL。通过pip安装。
使用pytesseract将图片上的文字转换为文本文字的示例如下:
#导入pytesseract
import pytesseract
#导入Image库
from PIL import Image
#指定tesseract.exe所在路径
pytesseract.pytesseract.tesseract_cmd = r'D:\Tesseract-OCR\tesseract.exe'
#打开图片
image = Image.open('a.png')
#调用image_to_string将图片内容转换为文字
text = pytesseract.image_to_string(image)
print(text)
3.05、用pytesseract识别图形验证码实现自动登陆拉勾网:
# encoding: utf-8
import pytesseract, time
from PIL import Image
from urllib import request
def main():
while True:
url = 'https://passport.lagou.com/vcode/create?from-register&refresh=1513082291955'
# 指定tesseract.exe的路径
pytesseract.pytesseract.tesseract_cmd = r'D:\Tesseract-OCR\tesseract.exe'
request.urlretrieve(url, 'images/captche.png')
# 打开图片
image = Image.open('images/captche.png')
# 将图片作为参数,转换,lang可以指定语言
text = pytesseract.image_to_string(image)
print(text)
time.sleep(3)
if __name__ == '__main__':
main()
#第五章 Scrapy框架架构
1、Scrapy框架介绍:
写一个爬虫,需要做很多事情。比如:发送网络请求、数据解析、数据存储、反反爬虫机制(更换代理IP、设置请求头等)、异步请求等。这些工作如果每次都要自己从零开始写的话,比较浪费时间。因此Scrapy把一些基础的东西封装好了,在它上面写爬虫可以变的更加高效(爬取效率和开发效率)。因此真正在公司里,一下上了量的爬虫,都是使用Scrapy框架来解决。
1.01、Scrapy架构图:
- 流程图(1):
[外链图片转存失败(img-yELZWzi5-1565236629158)(http://s1.51cto.com/wyfs02/M00/8D/E7/wKioL1iuxx-w7yzWAAERDnl3dTM370.jpg “scrapy流程图”)]
- 流程图(2):
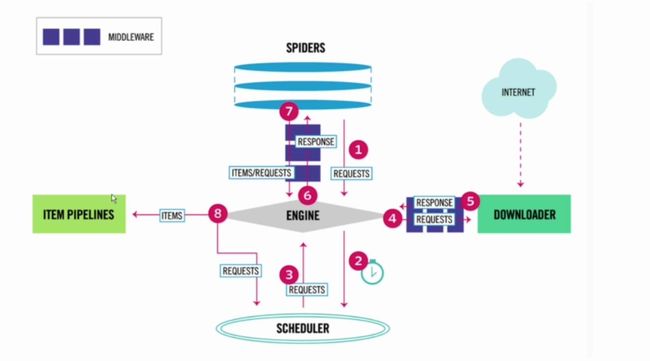
1.02、Scrapy框架模块功能:
Scrapy Engin(引擎):Scrapy框架的核心部分。负责在Spider和ItemPipeline、Downloader、Scheduler中间通信、传递数据等。Spider(爬虫):发送需要爬取的链接给引擎,最后引擎把其他模块请求回来的数据再发送给爬虫,爬虫就去解析想要的数据。这个部分是我们开发者自己写的,因为要爬取哪些链接,页面总的哪些数据是我们想要的,由程序员自己决定。Scheduler(调度器):负责接收引擎发送过来的请求,并按照一定的方式进行排列和整理,负责调度请求的顺序等。Downloader(下载器):负责接收引擎传过来的下载请求,然后去网络上下载对应的数据再交还给引擎。Item Pipeline(管道):负责将Spider传递过来的数据进行保存。具体保存在哪,根据需求决定。Downloader Middlewares(下载中间件):可以扩展下载器和引擎之间通信功能的中间件。Spider Middlewares(Spider中间件):可以扩展引擎和爬虫之间的通信功能的中间件。
2、Scrapy快速入门
2.01、安装和文档:
-
安装:通过pip install scrapy安装即可。
-
Scrapy官方文档:https://scrapy-chs.readthedocs.io/zh_CN/latest
注意:
- 在
ubuntu上安装scrapy之前,需要先安装以下依赖:
sudo apt-get install python-dev python-pip libxml2-dev libxslt1-dev zlib1g-dev libffi-dev libssl-dev,然后再通过pip install scrapy安装。
- 如果在
windows系统下,提示这个错误ModuleNotFoundError: No module named 'win32api',那么使用以下命令解决:
pip install pypiwin32。
- 安装
Scrapy时报错:Failed building wheel for Twisted,解决办法参考:https://blog.csdn.net/abebetter/article/details/74626486。
2.02、快速入门:
2.02-1、创建项目:
要使用Scrapy框架创建项目,需要通过命令来创建。首先进入到你想把项目存放的目录下,然后使用命令创建:
scrapy startproject [项目名称]
以下介绍项目的主要文件的作用:
items.py:用来存放爬虫爬取下来的数据的模型。middlewares.py:用来存放各种中间件的文件。pipelines.py:用来将items的模型存储到本地磁盘中。settings.py:本爬虫的一些配置信息(比如请求头、多久发送一次请求、IP代理池等)。scrapy.cfg:项目的配置文件。spiders包:以后所有的爬虫文件,都是存放到这里。
2.03、使用Scrapy框架爬取糗事百科段子:
2.03-1、使用命令创建一个爬虫:
scrapy gensipder qsbk "qiushibaike.com"
#scrapy gensiper [爬虫名] [爬取的域名]
创建一个名字叫做qsnk的爬虫,并且能爬取的网页只会限制在qiushibaike.com域名下。
2.03-2、爬虫代码解析:
import scrapy
class QsbkSpider(scrapy.Spider):
name = 'qsbk'
allowed_domains = ['qiushibaike.com']
start_urls = ['http://qiushibaike.com/']
def parse(self,response):
pass
要创建一个Spider,那么必须自定义一个类,继承自scrapy.Spider,然后再这个类中定义三个属性和一个方法。
name:这个爬虫的名字,名字必须是唯一的。allowed_domain:允许的域名。爬虫只会爬取这个域名下的网页,其他不是这个域名下的网页会被自动忽略。start_urls:爬虫从这个变量中的url开始爬取。parse:引擎会把下载器下载回来的数据扔给爬虫解析,爬虫再把数据传给这个parse方法。这个是固定写法。这个方法的作用有两个,第一个是提取想要的数据。第二个是生成下一个请求的url。
2.03-3、修改settings.py代码:
在做一个爬虫之前,一定要记得修改settings.py中的设置/两个地方是强烈建议要设置的。
REBOTSTXT_OBEY设置为False,默认的是True。即遵守机器协议,那么在爬虫的时候,服务器就知道你这个请求时爬虫发出的。DEFAULT_REQUEST_HEADERS添加User-Agent。伪造浏览器请求头。
2.03-4、完成的代码:
-
爬虫代码:
import scrapy
from qiushibaike.items import QiushibaikeItem
class QsbkSpider(scrapy.Spider):
name = 'qsbk'
allowed_domains = ['qiushibaike.com']
start_urls = ['https://www.qiushibaike.com/text/page/1/']
base_url = 'https://www.qiushibaike.com'
def parse(self, response):
content_left = response.xpath('//div[@id="content-left"]/div')
for contentL in content_left:
author = contentL.xpath('.//h2/text()').get().strip()
content = ''.join(contentL.xpath('.//div[@class="content"]/span[1]//text()').getall()).strip()
item = QiushibaikeItem(author=author,content=content)
yield item
next_url = content_left.xpath('//ul[@class="pagination"]/li[last()]/a/@href').get()
if not next_url:
return
else:
yield scrapy.Request(self.base_url+next_url,callback=self.parse)
-
items.py代码:
import scrapy
class QiushibaikeItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
author = scrapy.Field()
content = scrapy.Field()
-
pipeline.py代码:
import json
class QiushibaikePipeline(object):
def __init__(self):
self.items = []
def open_spider(self, spider):
print('爬虫开始运行...')
def process_item(self, item, spider):
self.items.append(item)
print('='*30)
return item
def close_spider(self, spider):
with open('qsbk.json','w',encoding='utf-8')as fp:
json.dump(self.items,fp,ensure_ascii=False)
2.03-5、运行scrapy项目:
-
在cmd终端中运行:
进入项目所在的路径,然后scrapy crawl [爬虫名字]即可运行。
-
在代码中运行:
新建一个py文件,比如start.py。
from scrapy import cmdline
cmdline.execute('scrapy crawl qsbk'.split)
2.04、爬虫中的注意事项:
-
response是一个scrapy.http.response.html.HtmlResponse对象。可以执行xpath和css语法提取数据。
-
提取出来的数据,是一个Selector或者是SelectorList对象。如果想要提取内容,应该执行get或getall方法。
-
get方法:获取的是Selector中的第一个文本。返回的是一个str类型。
-
getall方法:获取的是Selector中的所有文本。返回的是一个列表。
-
如果数据解析回来,要传给pipeline处理,那么可以使用yield返回。或者是手机所有的item,最后统一使用return返回。
-
item:建议在items.py中定义好模型,然后再爬虫中使用模型进行数据返回。
-
pipeline:专门用来保存数据的。其中有三个方法经常使用,
open_spider(self,spider):当爬虫被启动时执行。process_item(self,spider):当爬虫中有item传过来的时候调用。close_spider(self,spider):当爬虫结束时候被调用。
要激活pipeline,应该在settings.py中,设置ITEM.PIPELINES。示例如下:
ITEM_PIPELINES = {
'qiushibaike.pipelines.QiushibaikePipeline': 300,
}
2.05、json数据保存
保存json数据的时候,可以使用这两个类,让操作变的更简单。
-
JsonItemExportor:这个是每次把数据添加到内存中。最后统一写入到磁盘中。好处是,存储的诗句是一个满足json规则的数据。坏处是,如果数据量比较大,那么会比较耗内存。
from scrapy.exporters import JsonItemExporter
class QiushibaikePipeline(object):
def __init__(self):
self.fp = open('duanzi.json', 'wb')
self.exporter = JsonItemExporter(self.fp,ensure_ascii=False,encoding='utf-8')
self.exporter.start_exporting()
def open_spider(self, spider):
print('爬虫开始运行...')
def process_item(self, item, spider):
self.exporter.export_item(item)
return item
def close_spider(self, spider):
self.exporter.finish_exporting()
self.fp.close()
print('爬虫结束运行...')
-
JsonLinesItemExporter::这个是每次调用export_item的时候就把这个item存储到磁盘中。坏处是一个字典是一行,整个文件不是一个满足json规则的文件。好处是每次处理数据的时候就直接写入到磁盘中,不会耗费内存,数据也比较安全。
from scrapy.exporters import JsonLinesItemExporter
class QiushibaikePipeline(object):
def __init__(self):
self.fp = open('duanzi.json', 'wb')
self.exporter = JsonLinesItemExporter(self.fp,ensure_ascii=False,encoding='utf-8')
def open_spider(self, spider):
print('爬虫开始运行...')
def process_item(self, item, spider):
self.exporter.export_item(item)
return item
def close_spider(self, spider):
self.fp.close()
print('爬虫结束运行...')
3、CrawlSpider
在上一个爬虫中,我们是自己在解析完整个页面后获取下一个页面的url,然后重新发送一个请求。有时候我们想要这样做,只要满足某个条件的url,都给我进行爬取。那么这时候我们就可以通过CrawlSpider来帮我们完成了。CrawlSpider继承自Spider,只不过在此的基础上进行增加了新的功能,可以定义爬取的url规则,以后scrapy碰到满足条件的url都进行爬取,而不用手动的yield Request。
###3.01、创建CrawlSpider爬虫:
之前创建爬虫的方式是通过scrapy genspider [爬虫名字] [域名]的方式创建的。如果想要创建CrawlSpider爬虫,那么应该通过以下命令创建:
scrapy genspider -t crawl [爬虫名字] [域名]
3.02、LinkExtractors链接提取器:
使用LinkExtractors可以不用程序员自己提取想要的url,然后发送请求。这些工作都可以交给LinkExtractors,他会在所有爬的页面中找到满足规则的url,实现自动爬取。以下对LinkExtractors类做一个简单的介绍:
class scrapy.linkextractors.LinkExtractor(
allow = (),
deny = (),
allow_domains = (),
deny_domains = (),
deny_extensions = None,
restrict_xpath = (),
tags = ('a','area'),
attrs = ('href'),
canonicalize = True,
unique = True,
process_value = None
)
**主要参数讲解: **
-
allow:运行的url。所有满足这个正则表达式的url都会被提取。
-
deny:禁止的url。所有满足这个正则表达式的url都不会被提取。
-
allow_domains:允许的域名。只有在这个里面的域名的url才会被提取。
-
deny_domains:禁止的域名,所有在这个域名里面的url都不会被提取。
-
restrict_xpaths:严格的xpath,和allow共同过滤链接。
3.03、Rule规则类:
定义爬虫的规则类。以下对这个类做一个简单介绍:
class scrapy.spiders.Rule(
link_extractor,
callback = None,
cb_kwargs = None,
follow = None,
process_links = None,
process_request = None
)
主要参数讲解:
link_extractor:一个LinkExtractor对象,用于定义爬虫规则。callback:满足这个规则的url,应该要执行哪个回调函数。因为CrawlSpider使用了parse作为回调函数,因此不要覆盖parse作为自己的回调函数。即,不要在Crawlspider中创建parse函数,防止覆盖。follow:指定根据该规则从response中提取的链接是否需要跟进。process_links:从link_extractor中获取到链接后会传递给这个函数,用来过滤不需要爬取的链接。
3.04、微信小程序社区CrawlSpider案例
# -*- coding: utf-8 -*-
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
from wx_cx.items import WxCxItem
class WxSpiderSpider(CrawlSpider):
name = 'wx_spider'
allowed_domains = ['wxapp-union.com']
start_urls = ['http://www.wxapp-union.com/portal.php?mod=list&catid=2&page=1']
rules = (
Rule(LinkExtractor(allow=r'.+mod=list&catid=2&page=\d'),follow=True),
Rule(LinkExtractor(allow=r'.+article-.+\.html'),callback='parse_detail',follow=False),
)
def parse_detail(self, response):
title = response.xpath('//h1[@class="ph"]/text()').get().strip()
author_p = response.xpath('//p[@class="authors"]')
author = author_p.xpath('./a/text()').get().strip()
pub_time = author_p.xpath('./span/text()').get().strip()
article_content = response.xpath('//td[@id="article_content"]//text()').getall()
content = ''.join(article_content).strip()
item = WxCxItem(title=title,author=author,pub_time=pub_time,content=content)
yield item
3.05、CrawlSpider注意要点:
需要使用LinkExtractor和Rule。这两个东西决定爬虫具体走向。
allow设置规则的方法:要能够限制在我们想要的url上面。不要跟其他的url产生相同的正则表达式即可。- 什么情况下使用
follow:如果在爬取页面的时候,需要将满足当前条件的url再进行跟进,那么就设置为True。否则设置为False。
- 什么情况下该指定
callback:如果这个url对应的页面,只是为了获取更多详情也的url,并不需要提取里面的数据,那么可以不指定callback。如果想要获取url对应页面中的数据,那么就需要指定一个callback。
4、Scrapy Shell
我们想要再爬虫中使用xpath、beautifulsoup、正则表达式、css选择器等来提取想要的数据。但是因为scrapy是一个比较重的框架。每次运行起来都要等待一段时间。因此要去验证我们写的提取规则是否正确,是一个比较麻烦的事。因此Scrapy提供了一个shell,用来方便的测试规则。当然也不仅仅局限于这一个功能。
4.01、打开Scrapy Shell:
打开cmd终端,进入到Scrapy项目所在的目录,然后进入到Scrapy框架所在的虚拟环境中,输入命令**scrapy shell [页面链接]**。就会进入到scrapy的shell环境中。在这个环境中,你可以跟在爬虫的parse方法中一样提取数据了。
5、Request和Response对象
5.01、Request对象:
class Request(object_ref):
def __init__(self, url, callback=None, method='GET', headers=None, body=None,
cookies=None, meta=None, encoding='utf-8', priority=0,
dont_filter=False, errback=None, flags=None):
self._encoding = encoding # this one has to be set first
self.method = str(method).upper()
self._set_url(url)
self._set_body(body)
assert isinstance(priority, int), "Request priority not an integer: %r" % priority
self.priority = priority
if callback is not None and not callable(callback):
raise TypeError('callback must be a callable, got %s' % type(callback).__name__)
if errback is not None and not callable(errback):
raise TypeError('errback must be a callable, got %s' % type(errback).__name__)
assert callback or not errback, "Cannot use errback without a callback"
self.callback = callback
self.errback = errback
self.cookies = cookies or {}
self.headers = Headers(headers or {}, encoding=encoding)
self.dont_filter = dont_filter
self._meta = dict(meta) if meta else None
self.flags = [] if flags is None else list(flags)
Request对象在我们写爬虫的爬虫,爬取一页的数据需要重新发送一个请求的时候调用。这个类需要传递一些参数,其中比较常用的参数有:
url:这个request对象发送请求的url。callback:在下载器下载完相应的数据后执行的回调函数。method:请求的方法。默认为GET方法,可以设为为其他方法。headers:请求头,对于一些固定的设置,放在settings.py中指定就可以了。对于那些非固定的,可以在发送请求的时候指定。meta:比较常用。用于在不同请求之间传递数据用的。encoding:编码。默认为utf-8,使用默认的就可以了。dot_filter:表示不由调度器过滤。默认的是去重的,设置为True即是取消去重功能。在执行多次重复的请求的时候用的比较多。errback:在发生错误的时候执行的函数。
5.02、Response对象:
Response对象一般是由Scrapy给你自动构建的。因此开发者不需要关心如何创建Response对象,而是如何使用它。Response对象有很多属性,可以用来提取数据的。主要有以下属性:
meta:从其他请求传过来的meta属性,可以用来保持多个请求之间的数据连接。encoding:返回当前字符串编码和解码的格式。text:将返回来的数据作为unicode字符串返回。body:将返回的数据作为bytes字符串返回。xpath:xpath选择器。css:css选择器。
5.03、发送POST请求:
有时候我们想要在请求数据的时候发送post请求,那么这时候需要使用Request的子类FormRequest来实现。如果想要在爬虫一开始的时候就发送POST请求,那么需要在爬虫类中重写start_requests(self)方法,并且不再调用start_urls里的url。
5.04、模拟登录
-
模拟登录豆瓣网(识别验证码)
import scrapy
from urllib import request
import requests
from base64 import b64encode
class DoubanSpider(scrapy.Spider):
name = 'douban_spider'
allowed_domains = ['douban.com']
start_urls = ['https://accounts.douban.com/login']
login_url = 'https://accounts.douban.com/login'
profile_url = 'https://www.douban.com/people/185770912/'
edit_signature = 'https://www.douban.com/j/people/185770912/edit_signature'
def parse(self, response):
formdata = {
'source': 'None',
'redir': 'https: // www.douban.com',
'form_email': '[email protected]',
'form_password': 'douban123456',
'login': '登录'
}
captcha_id = response.xpath('//input[@name="captcha-id"]/@value').get()
if captcha_id:
formdata['captcha-id'] = captcha_id
captcha_url = response.xpath('//img[@id="captcha_image"]/@src').get()
print(captcha_url)
captcha_solution = self.request_captcha(captcha_url)
formdata['captcha-solution'] = captcha_solution
yield scrapy.FormRequest(self.login_url, formdata=formdata, callback=self.parse_after_login)
def parse_after_login(self, response):
if response.url == 'https://www.douban.com/':
yield scrapy.Request(self.profile_url, callback=self.edit_sign)
print('登录成功...')
else:
print('登录失败...')
def edit_sign(self, response):
if response.url == self.profile_url:
ck = response.xpath('//input[@name="ck"]/@value').get()
print(ck)
data = {
'ck': ck,
'signature': '我能自动识别验证码登录。'
}
yield scrapy.FormRequest(self.edit_signature, formdata=data, callback=self.parse_none)
print('修改函数执行完毕...')
else:
print('没有进入个人中心..')
def parse_none(self, response):
pass
def request_captcha(self, captcha_url):
request.urlretrieve(captcha_url, 'captcha.png')
formdata = {}
with open('captcha.png', 'rb') as fp:
data = fp.read()
image = b64encode(data)
formdata['v_pic'] = image
url = 'http://yzmplus.market.alicloudapi.com/fzyzm?v_type=cn'
headers = {
'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8',
'Authorization': 'APPCODE ' + 'e7f54965c4bb4d33be184256240e90ab',
}
response = requests.post(url, data=formdata, headers=headers)
result = response.json()['v_code']
return result
import scrapy
from urllib import request
import requests
from base64 import b64encode
class DoubanSpider(scrapy.Spider):
name = 'douban_spider'
allowed_domains = ['douban.com']
start_urls = ['https://accounts.douban.com/login']
login_url = 'https://accounts.douban.com/login'
profile_url = 'https://www.douban.com/people/185770912/'
edit_signature = 'https://www.douban.com/j/people/185770912/edit_signature'
def parse(self, response):
formdata = {
'source': 'None',
'redir': 'https: // www.douban.com',
'form_email': '[email protected]',
'form_password': 'douban123456',
'login': '登录'
}
captcha_id = response.xpath('//input[@name="captcha-id"]/@value').get()
if captcha_id:
formdata['captcha-id'] = captcha_id
captcha_url = response.xpath('//img[@id="captcha_image"]/@src').get()
print(captcha_url)
captcha_solution = self.request_captcha(captcha_url)
formdata['captcha-solution'] = captcha_solution
yield scrapy.FormRequest(self.login_url, formdata=formdata, callback=self.parse_after_login)
def parse_after_login(self, response):
if response.url == 'https://www.douban.com/':
yield scrapy.Request(self.profile_url, callback=self.edit_sign)
print('登录成功...')
else:
print('登录失败...')
def edit_sign(self, response):
if response.url == self.profile_url:
ck = response.xpath('//input[@name="ck"]/@value').get()
print(ck)
data = {
'ck': ck,
'signature': '我能自动识别验证码登录。'
}
yield scrapy.FormRequest(self.edit_signature, formdata=data, callback=self.parse_none)
print('修改函数执行完毕...')
else:
print('没有进入个人中心..')
def parse_none(self, response):
pass
def request_captcha(self, captcha_url):
request.urlretrieve(captcha_url, 'captcha.png')
formdata = {}
with open('captcha.png', 'rb') as fp:
data = fp.read()
image = b64encode(data)
formdata['v_pic'] = image
url = 'http://yzmplus.market.alicloudapi.com/fzyzm?v_type=cn'
headers = {
'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8',
'Authorization': 'APPCODE ' + 'e7f54965c4bb4d33be184256240e90ab',
}
response = requests.post(url, data=formdata, headers=headers)
result = response.json()['v_code']
return result
6、下载文件和图片
Scrapy为下载item中包含的文件(比如在爬取到产品时,同样也想保存对应的图片)提供了一个可重用的item pipelines。这些pipeline有些共同的方法和结构(我们称之为media pipeline)。一般来说你会使用Files Pipeline就会使用Images Pipeline。
6.01、为什么选择scrapy内置的下载文件的方法:
- 避免查询下载已经下载过的数据。
- 可以方便的指定文件的存储路径。
- 可以将下载的图片转换成通用格式。比如
png或jpg。
- 可以方便的生成缩略图。
- 可以方便的检测图片的宽和高,确保他们满足最小的限制。
- 异步下载,效率非常高。
6.02、下载文件的Files Pipeline:
当使用Files Pipeline下载文件的时候,按照以下步骤来完成:
- 定义好一个
Item,然后再这个item中定义两个属性,分别为file_urls以及files。file_urls是用来存储需要下载的文件的url链接,需要给一个列表。
- 当文件下载完成后,会把文件下载的相关信息存储到
item的files属性中。比如下载路径、下载的url和文件的校验码等。
- 再配置文件
settings.py中配置FILES_STORE,这个配置是用来设置文件下载下来的路径。
- 启动
pipeline:在ITEM_PIPELINES中设置scrapy.pipeline.files.FilesPipeline:1。此为系统自带的pipeline,若自定义了继承自ImagesPipeline的新的pipeline,可以使用'[项目名].pipelines.BmwImagePipeline': 1。
6.03、下载图片的Images Pipeline:
当使用Images Pipeline下载图片的时候,按照以下步骤来完成。
- 定义好一个
Item,然后在这个item中定义好两个属性,分别为image_urls以及images。image_urls是用来存储需要下载的图片的url链接,需要给一个列表。
- 当图片下载完成后,会把文件下载的相关信息存储到
item的images属性中。比如下载路径、下载的url和文件的校验码等。
- 再配置文件
settings.py中配置IMAGES_STORE,这个配置是用来设置图片下载下来的路径。
- 启动
pipeline:在ITEM_PIPELINES中设置scrapy.pipeline.images.ImagesPipeline:1,此为系统自带的pipeline,如果是自定义的继承自ImagesPipeline的新的pipeline,可以使用'[项目名].pipelines.BmwImagePipeline': 1来启动。
直接下载的话,图片会统一放在full目录下,为了更改图片路径,可以自定义一个pipeline类且继承自ImagesPipeline。然后重写file_path方法。
注意:要在settings.py中更改ITEM_PIPELINES内容为当前的pipeline。
示例代码:
class BmwImagePipeline(ImagesPipeline):
# 这个方法是发送下载请求的。
# 目的是为了将图片分类绑定到request对象上。
def get_media_requests(self, item, info):
request_objs = super(BmwImagePipeline, self).get_media_requests(item,info)
for request_obj in request_objs:
request_obj.item = item
return request_objs
# 这个方法是下载的时候,获取下载路径的。
# 将更改的目录返回即可
def file_path(self, request, response=None, info=None):
path = super(BmwImagePipeline, self).file_path(request,response,info)
# 因为重写get_media_requests方法,将item绑定到了request,所以可以直接获取item
category = request.item.get('category')
category_path = os.path.join(settings.IMAGES_STORE,category)
if not os.path.exists(category_path):
os.mkdir(category_path)
image_name = path.replace('full/','')
image_path = os.path.join(category_path,image_name)
return image_path
7、Dowloader Middlewares(下载器中间件)
7.01、process_request(self,request,spider):
这个方法是下载器在发送请求之前执行的。一般可以在这个里面设置随机代理IP等。
- 参数:
request:发送请求的request对象。spider:发送请求的spider对象。
- 返回值:
- 返回
None:如果返回None,Scrapy将继续处理该request,执行其他中间件中的相应方法,知道合适的下载器处理函数被调用。
- 返回
Response对象:Scrapy将不会调用任何其他的process_request方法,将直接返回这个response对象。已经激活的中间件的process_response()方法则会在每个response返回时被调用。
- 返回
Request对象:不再使用之前的request对象去下载数据,而是根据现在返回的request对象返回的数据。
- 如果这个方法中抛出了异常,则会调用
process_exception方法。
7.02、process_response(self,request,response,spider):
这个时下载器下载的数据到引擎中间会执行的方法。
- 参数:
request:request对象。response:被处理的response对象。spider:spider对象。
- 返回值:
- 返回
Response对象:会将这个新的response对象传给其他的中间件,最终传给爬虫。
- 返回
Request对象:下载器链接被切断,返回的request会重新被下载器调度下载。
- 如果抛出一个异常,那么调用
request的errback方法,如果没有指定这个方法,那么会抛出一个异常。
7.03、随机请求头中间件:
爬虫在频繁访问一个页面的时候,这个请求头如果一直保存一致。那么很容易被服务器发现,从而禁止掉这个请求头的访问。因此我们要在访问中国页面之前随机的更改请求头,这样才可以避免爬虫被抓。随机更改请求头,可以在下载中间件中实现。在请求发送给服务器之前,随机的选择一个请求头。这样就可以避免总使用一个请求头了。示例如下:
class UserAgentDownloaderMiddleware(object):
# User-Agent随机请求头中间件
USER_AGENTS = [
'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36',
'Mozilla/5.0 (Macintosh; U; Intel Mac OS X 10_6_8; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50',
'Mozilla/5.0 (iPhone; U; CPU iPhone OS 4_3_3 like Mac OS X; en-us) AppleWebKit/533.17.9 (KHTML, like Gecko) Version/5.0.2 Mobile/8J2 Safari/6533.18.5'
'Mozilla/4.0 (compatible; MSIE 6.0; ) Opera/UCWEB7.0.2.37/28/999',
'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; 360SE)'
]
def process_request(self, request, spider):
user_agent = random.choice(self.USER_AGENTS)
request.headers['User-Agent'] = user_agent
7.04、IP代理池中间件
购买代理:
在以下代理商中购买代理:
- 快代理。
- 芝麻代理。
- 等。
class IPProxyDownloadMiddle(object):
PROXY = ["http://112.4.151.73:8888","http://136.228.128.6:34841","http://47.100.52.185:80"]
def process_request(self, request, spider):
# proxy = self.get_proxy()
proxy = random.choice(self.PROXY)
print('当前的ip是:'+proxy)
request.meta['proxy'] = proxy
8、Scrapy中的MySQL异步存储:
普通的数据库操作比较慢,可以使用Twisted提供的ConnectionPool进行异步存储。
import pymysql
from twisted.enterprise import adbapi
from pymysql import cursors
class JianshuTwistedPipeline(object):
def __init__(self):
dbparans = {
'host': '127.0.0.1',
'port': 3306,
'user': 'root',
'password': 'root',
'database': 'jianshu',
'charset': 'utf8',
'cursorclass': cursors.DictCursor
}
self.dbpool = adbapi.ConnectionPool('pymysql', **dbparans)
self._sql = None
@property
def sql(self):
if not self._sql:
self._sql = """
insert into article(id,title,avatar,author,article_id,pub_time,origin_url,content)
values(null,%s,%s,%s,%s,%s,%s,%s)
"""
return self._sql
return self._sql
def process_item(self, item, spider):
defer = self.dbpool.runInteraction(self.insert_item,item)
defer.addErrback(self.handle_error,item,spider)
return item
def insert_item(self,cursor,item):
cursor.execute(self.sql, (
item['title'], item['avatar'], item['author'], item['article_id'], item['pub_time'], item['origin_url'],
item['content']))
def handle_error(self,error,item,spider):
print('发生错误:',error)
第六章Scrapy-Redis分布式爬虫
1、Redis数据库介绍:
###1.01、 概述:
redis是一种nosql数据库,他的数据是保存在内存中,同时redis可以定时把内存数据同步到磁盘,即可以将数据持久化,并且他比memcached支持更多的数据结构(string,list列表[队列和栈],set[集合],sorted set[有序集合],hash(hash表))。相关参考文档:http://redisdoc.com/index.html
1.02、redis使用场景:
- 登录会话存储:存储在
redis中,与memcached相比,数据不会丢失。
- 排行版/计数器:比如一些秀场类的项目,经常会有一些前多少名的主播排名。还有一些文章阅读量的技术,或者新浪微博的点赞数等。
- 作为消息队列:比如
celery就是使用redis作为中间人。
- 当前在线人数:显示当前系统有多少在线人数等。
- 一些常用的数据缓存:比如在
BBS论坛中,板块不会经常变化,但是每次访问首页都要先从MySQL中获取数据,可以提前在redis中缓存起来,不用每次都请求数据库。
- 把前200篇文章缓存或者评论缓存:一般用户浏览网站,只会浏览前面一部分文章或者评论,那么可以把前面200篇文章和对应的评论缓存起来。用户访问超过的,就访问数据库,并且以后文章超过200篇,则把之前的文章删除。
- 好友关系:微博的好友关系使用
redis开发。
- 发布和订阅功能:可以用来做聊天软件。
1.03、redis和memcached比较:
memcached
redis
类型
纯内存缓存系统
内存磁盘同步数据库
数据类型
在定义value是就要固定数据类型
不需要
虚拟内存
不支持
支持
过期策略
支持
支持
存储数据安全
不支持
可以将数据同步到dump.db中
灾难恢复
不支持
可以将磁盘中的数据恢复到内存中
分布式
支持
主从同步
订阅与发布
不支持
支持
1.04、redis在ubuntu系统中的安装与启动
-
安装:
sudo apt-get install redis-server
-
卸载:
sudo apt-get purge --auto-renove redis-server
-
启动:redis安装后,默认会自动启动,可以通过以下命令查看:
ps aux|grep redis
如果想自己手动启动,可以通过以下命令进行启动:
sudo service redis-server start
-
停止:
sudo service redis-server stop
1.05、对redis的操作
对redis的操作可以用两种方式,第一种采用redis-cli(redis客户端),第二种方式采用编程语言,比如python,php,和java等。
1.05-1、使用redis-cli对redis进行操作
-
字符串操作:
-
启动redis:
sudo service redis-server start
-
连接上redis-server:
redis-cli -h [ip] [端口]
-
添加:
set key value
如:
set username fdk
将字符串值value关联到key。如果key已经持有其他值,set命令就覆写旧值,无视其类型。并且默认的过期时间是永久,即用不过期。
-
删除:
del key
如:
del username
-
设置过期时间:
expire key timeout(单位:秒)
也可以在设置值的时候,一并指定过期时间:
set key EX timeout
或:
setex key timeout value
-
查看过期时间:
ttl key
如:
ttl username
-
查看当前redis中的所有key:
key *
-
列表操作:
-
在列表左边添加元素:
lpush key value
将值value插入到列表key的表头。如果key不存在,一个空的列表会被创建并执行lpush操作。当key存在但不是列表类型时,将返回一个错误。
-
在列表右边添加元素:
rpush key value
将值value插入到列表key的表尾。如果key不存在,一个空的列表会被创建并执行rpush操作。当key存在但不是列表类型时,将返回一个错误。
-
查看列表的元素:
lrange key start stop
返回列表key中指定区间内的元素,区间以偏移量start和stop指定,如果要左边的第一个到最后的一个lrange key 0 -1。
-
移除列表中的元素:
-
移除并返回列表key的头元素:
lpop key
-
移除并返回列表的尾元素:
rpop key
-
移除并返回列表key的中间元素:
lrem key count value
将删除key这个列表中,count个值为value的元素
-
指定返回第几个元素:
lindex key index
将返回key这个列表中,索引为index的这个元素。
-
获取列表中的元素个数:
llen key
如:
llen languages
-
删除指定元素:
lrem key count value
如:
lrem languages 0 php
根据参数count的值,移除列表中与参数value相等的元素。count的值可以时以下几种:
count > 0:从表头开始向表尾搜索,移除与value相等的元素,数量为count。count < 0:从表尾开始向表头搜索,移除与value相等的元素,数量为count的绝对值。count = 0: 移除表中所有与value相等的值。
-
set集合操作:
-
添加元素:
sadd set value value2....
如:
sadd team xiaotou1 xiaotou2
-
查看元素:
smembers set
如:
smembers team
-
移除元素:
srem set membet...
如:
srem team xiaotou1 xiaotou2
-
查看集合中的元素个数:
scard set
如:
scard team1
-
获取多个集合的交集:
sinter set1 set2
如:
sinter team1 team2
-
获取多个集合的并集:
sunion set1 set2
如:
sunion team1 team2
-
获取多个集合的差集:
sdiff set1 set2
如:
sdiff team1 team2
-
hash哈希操作:
-
添加一个新值:
hset key field value
如:
hset website baidu baidu.com
将哈希表key中的域field的值设为value。
如果key不存在,一个新的哈希表被创建并进行hash操作。如果域field已经存在于哈希表中,旧值将被覆盖。
-
获取哈希中field对应的值:
hget key field
如:
hget website baidu
-
删除field中的某个field:
hdel key field
如:
hdel website baidu
-
获取某个哈希中所有的field和value:
hgetall key
如:
hgetall website
-
获取某个哈希中所有的field:
hkeys key
如:
hkeys website
-
获取某个哈希中所有的值:
hvals key
如:
hvals website
-
判断哈希中是否存在某个field:
hexists key field
如:
hexists website baidu
-
获取哈希中总共的键值对:
hlen field
如:
hlen website
-
事务操作:Redis事务可以一次执行多个命令,事务具有以下特征:
-
隔离操作:事务中的所有命令都会序列化、按顺序执行,不会被其他命令打扰。
-
原子操作:事务中的命令要么全部被执行,要么全部都不执行。
-
开启一个事务:
multi
-
执行事务:
exec
-
取消事务:
discard
会将multi后所有的命令取消。
-
监视一个或者多个key:
watch key...
监视一个(或多个)key,如果在事务执行之前这个(或这些)key被其他命令所改动,那么事务将被打断。
-
取消所有key的监视:
unwatch
-
发布/订阅操作:
-
给某个频道发布消息:
publish channel message
-
订阅某个频道的消息:
subscribe channel
-
持久化:redis提供了两种数据备份方式,一种是RDB,另一种是AOF,以下将详细介绍这两种备份策略:
RDB
AOF
开启关闭
开启:默认开启。关闭:把配置文件中所有的save都注释,就是关闭
开启:在配置文件中appendonly yes即开启了aof,为no关闭。
同步机制
可以指定某个时间内发生多少个命令进行同步。比如1分组内发生了2次命令,就做一次同步。
每秒同步或者每次发生命令后同步
存储内容
存储的是redis里面的具体的值
储存的是执行的写操作命令
存储文件的路径
根据dir以及rdbfilename来指定路径和具体的文件名
根据dir以及appendfilename来指定路径和具体的文件名
优点
(1) 存储数据到文件中会进行压缩,文件体积比aof小。(2) 因为存储的是redis具体的值,并且会经过压缩,因此在恢复的时候速度比AOF快。(3) 非常适用于备份
(1) AOF的策略是每秒钟或者每次发生写操作的时候都会同步,因此技术服务器故障,最大只会丢死1秒的数据。(2) AOF存储的是Redis命令,并且是直接追加到aof文件后面,因此每次备份的时候只要添加新的数据进去就可以了。(3) 如果AOF文件比较大了,那么Redis会进行重写,只保留最小的命令集合
缺点
(1) RDB在多少时间内发生了多少写操作的时候就会触发同步机制,因为采用压缩机制,RDB在同步的时候都重新保存整个Redis中的数据,因此一般会设置在最好5分钟才保存一次数据。在这种情况下,一旦服务器故障,会造成5分钟的数据丢失。(2) 在数据保存进RDB的时候,Redis会fork出一个子进程用来同步,在数据量比较大的时候,可能非常耗时。
(1) AOF文件因为没有压缩,因此体积比RDB大。(2) AOF是在每秒或者每次写操作都进行备份,因此如果并发量比较大,效率可能变慢。(3) AOF文件因为存储的是命令,因此在灾难恢复的时候Redis会重新运行AOF中的命令,速度不及RDB。
更多
http://doc.redisfans.com/topic/persistence.html
-
给redis指定密码:在redis.conf配置文件中,设置requirepass password(想设置的密码),那么客户端连接的时候,需要使用密码:
-
使用密码连接(一):先登录,后用auth password授权。
> redis-cli -p 127.0.0.1 -p 6379
redis> set username xxx
(error) NOAUTH Authentication requires.
redis> auth password
redis> set uaername xxx
OK
-
使用密码连接(二):在连接时直接使用-a password指定密码进行连接。
> redis-cli -p 127.0.0.1 -p 6379 -a [密码]
-
其他机器连接redis:
如果想要让其他机器连接本机的redis服务器,那么应该在redis.conf配置文件中,指定bind 本机IP。这样别的机器就能连接成功了。
1.05-2、Python操作redis
-
安装python-redis:
pip install python-redis
-
新建一个文件比如redis_test.py,然后初始化一个redis示例变量,并且在Ubuntu虚拟机中开启redis。比如虚拟机的IP地址为192.168.174.130。示例代码如下:
# 从redis包中导入Redis类
from redis import Redis
# 初始化redis实例变量
xtredis = Redis(host='192.168.174.130',port=6379)
-
对字符串的操作:操作redis的方法名称,和redis-cli一样,以下时简单介绍:
# 添加一个值进去,并且设置过期时间为60秒,如果不设置,则永不过期
xtredis.set('username','fdk',ex=60)
# 获取一个值
xtredis.get('username')
# 删除一个值
xtredis.delete('username')
# 给某个值自增1
xtredis.set('read_count',1)
xtredis.incr('read_count')
# 给某值自减1
xtredis.decr('read_count')
-
对列表的操作:同字符串操作,所有的方法的名称跟使用和redis-cli一样。
# 给languages这个列表左边添加一个python
xtredis.lpush('languages','python')
# 给languages这个列表右边添加一个PHP
xtredis.rpush('languages','php')
# 获取languages列表中的所有值
print(xtredis.lrange('languages',0,-1))
-
对集合的操作:
# 给集合team添加元素
xtredis.sadd('team',xiaotou1)
xtredis.sadd('team',xiaotou2)
xtredis.sadd('team',xiaotou3)
#查看集合中所有的元素
print(xtredis.smembers('team'))
-
对哈希(hash)的操作:
# 给website这个哈希中添加baidu
xtredis.hset('website','baidu','www.baidu.com')
# 给website中添加Google
xtredis.hset('website','google','www.google.com')
# 获取website这个哈希中的所有值
print(xtredis.hgetall('website'))
-
事务(管道)操作:redis支持事务操作,即一些操作只有全部完成,才算完成。否则执行失败,python操作redis也时很简单,示例代码如下:
# 定义一个管道实例
pip = xtredis.pipeline()
# 做第一步操作,给BankA自增长1
pip.incr('BankA')
# 做第二步操作,给BankB自减少1
pip.decr('BankB')
# 执行事务
pip.execute()
2、Scrapy-Redis分布式爬虫组件:
Scrapy是一个框架,它本身是不支持分布式的。如果我们想要做分布式的爬虫,就需要借助一个组件叫做Scrapy-Redis,这个组件正是利用了Redis可以分布式的功能,集成到Scrapy框架中,使得爬虫可以进行分布式。可以充分利用资源(多个IP、更多带宽、同步爬取)来提高爬虫的爬行效率。
2.01、分布式爬虫的优点:
- 可以充分利用多台机器的带宽。
- 可以充分利用多台机器的IP地址。
- 多台机器工作,爬取效率更高。
2.02、分布式爬虫必须要解决的问题:
- 分布式爬虫是好几台机器在同时运行,如何保证不同的机器爬取页面的时候不会出现重复爬取的问题。
- 同样,分布式爬虫在不同的机器上运行,在把数据爬完后如何保证保存在同一个地方。
2.03、安装:
pip install scrapy_redis
2.04、Scrapy-Redis架构:
2.05、ubuntu爬虫服务器部署:
- 首先在
ubuntu中安装项目环境。
- 安装
redis。
- 安装
scrapy。
- 将项目打包,在
ubuntu使用rz命令将打包的项目导入进来。
- 运行爬虫。
- 在
redis服务器中设置redis_key的值。然后爬虫服务器会自动下载。
- 可以将存在
redis中的数据进行处理,然后存入MongoDB或MySQL中。
2.06、编写Scrapy-Redis分布式爬虫:
要将Scrapy项目变成一个Scrapy-Redis项目只需修改以下三点就可以了。
-
将爬虫的类从scrapy.Spider变成scrapy_redis.spider.RedisSpider;或者是将scrapy.CrawlSpider变成scrapy_redis.spiders.RedisCrawlSpider。
-
将爬虫中的start_urls删掉。增加一个redis_key = "xxx",例如redis_key = "ftx:start_urls"。 这个redis_key是为了以后在redis中控制爬虫的启动的。爬虫的第一个url,就是在redis中通过这个发送出去的。
-
在配置文件中增加如下配置:
# Scrapy-Redis相关配置
# 确保request存储到redis中
SCHEDULER = "scrapy_redis.scheduler.Scheduler"
# 确保所有爬虫共享相同的去重指纹
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.REPDupeFilter"
# 设置redis为item pipeline
ITEM_PIPELINES = {
'scrapy_redis.pipelines.RedisPipeline' : 300
}
# 在redis中保持scrapy-redis用到的队列,不会清理redis中的队列,从而可以实现暂停和恢复的功能
SCHEDULER_PERSIST = True
# 设置连接redis信息
REDIS_HOST = '127.0.0.1'
REDIS_PORT = 6379
-
运行爬虫:
- 在爬虫服务器上。进入爬虫文件所在的路径,然后输入命令:
scrapy runspider [爬虫名字]。
- 在
Redis服务器上,推入一个开始的url链接:redis-cli> lpush [redis_key] start_url开始爬取。