C语言:哈希表
1、文章声明:
本文是基于链地址法建立的哈希表。文章中若存在错误,欢迎各路大佬指正。本文涉及二级指针,链表等内容。该方面的知识点,可以参考文章:
数据结构:单链表的相关操作-CSDN博客
C语言:利用二级指针动态创建二维矩阵-CSDN博客
2、哈希表的介绍:
哈希表其实可以理解成一种映射,通过映射关系来存储数据,有点类似于Python中的字典。常见的如数组,链表等存储结构,他们查询数据都有一个特点,往往需要进行比较和判断,就是用“=”,“<”,“>”此类符号来逐步确定目标数据在存储结构中的位置。这也就导致利用这些存储结构进行查询时时间复杂度一般是O(n)。
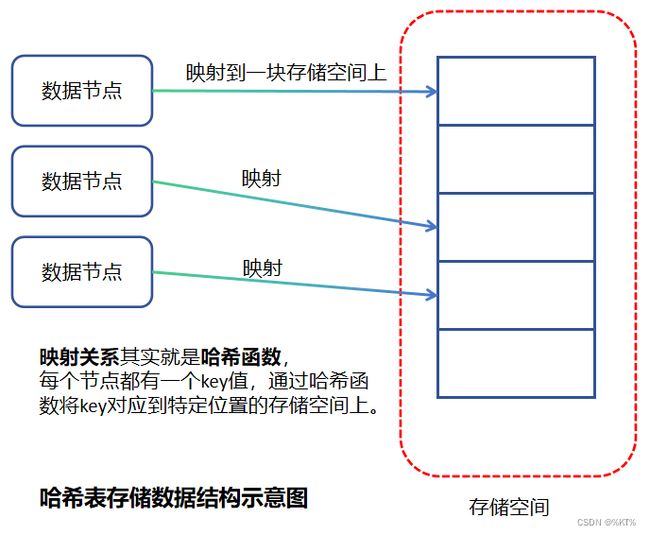
而在用哈希表存储数据时,对于每一个数据节点都会设置一个独一无二的key值,然后根据哈希函数,将每一个节点映射到一块存储空间上。所以理想情况下,当每一个节点都对应一个存储空间时,那么查询的时间复杂度是O(1),因为只要输入key值,就能立马查到对应的数据。
3、哈希冲突:
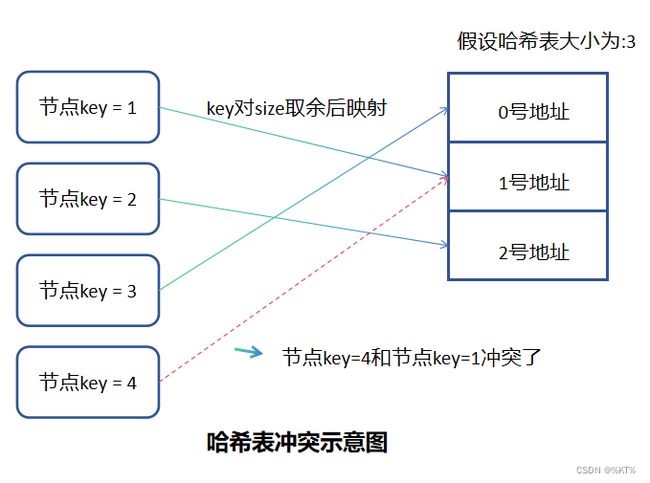
但是一般建立哈希表时,不会建立一个和节点数目一样大小的哈希表,而是会建立一个小于节点数的哈希表。这样的话,就会产生哈希冲突——也就是多个节点映射到了同块地址空间。
针对哈希冲突,常见的解决方法有:开放定址法、再哈希法、链地址法。本文示例所采用的方法是链地址法。
4、哈希函数:
这里介绍一种常用的哈希函数:取余法。计算公式为:key%size = 存储位置。
这里的size就是哈希表的大小。
5、链地址法原理:
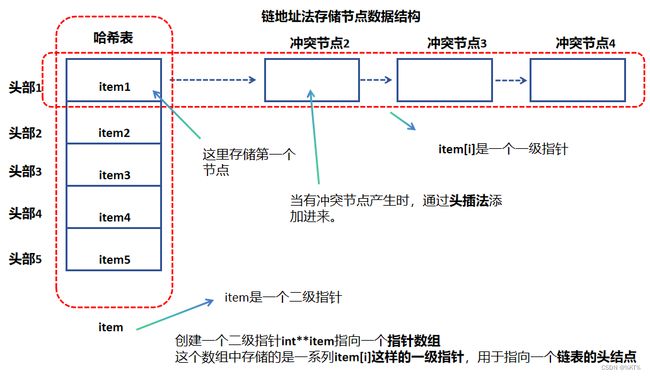
采用链地址法的解决思路也很简单,就是将冲突节点,通过链表的方法,“挂”在同一个冲突位置,形成一个“槽”或者“桶”。“槽”本质上是一个链表。这样,虽然时间复杂度可能不是O(1),但也小于O(n),是一种非常高效的存储策略。
6、数据节点结构示意图:
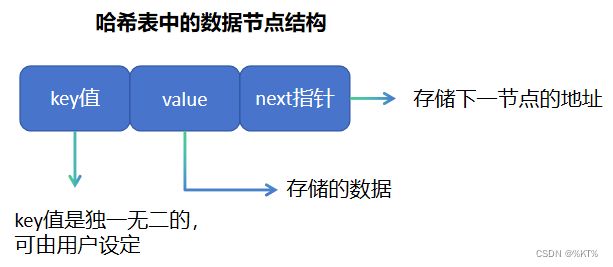
就像链表中的节点包含数据域和指针域一样,哈希表中的数据节点包含三部分:key值,value值和指向下一节点的指针next。
6.1节点结构体定义方式:
typedef struct Node //定义哈希表中存储数据的结构,称为桶/槽位,就类比于链表中的节点
{
int key;//用来确定索引的
int value;//存储的数据
struct Node* next;//节点的下一个节点 因为在解决哈希冲突时,采用的是链地址法,所以需要这样定义
}Node;
7、哈希表结构体的定义:
定义了节点的结构体,还需要定义哈希表结构体,用来实例化一个哈希表。类比于教师学生结构体关系一样,教师名下会有很多年学生,一个哈希表结构体下会有很多节点。
哈希表结构体中需要声明哈希表的大小,以及一个二级指针,这个二级指针指向一个指针数组。这个指针数组就是用来存储前面提到指向一系列链表的头结点的指针。
7.1哈希表结构体的定义:
typedef struct HashTable
{
int size;//指定哈希表中作为头部节点的个数
struct HashTable** item; //哈希表中需要设定一个二级指针,用于指向一个指针数组,这个指针数组的大小就是size,
//item指针数组中包含多个指针,每个指针指向一个链表的头节点,存储着可能冲突的节点(类似邻接表,二维矩阵的结构)}HashTable;
8、完整源码及详细注释:
#include
#include
typedef struct Node //定义哈希表中存储数据的结构,称为桶/槽位,就类比于链表中的节点
{
int key;//用来确定索引的
int value;//存储的数据
struct Node* next;//节点的下一个节点 因为在解决哈希冲突时,采用的是链地址法,所以需要这样定义
}Node;
typedef struct HashTable
{
int size;//指定哈希表中作为头部节点的个数
struct HashTable** item; //哈希表中需要设定一个二级指针,用于指向一个指针数组,这个指针数组的大小就是size,
//item指针数组中包含多个指针,每个指针指向一个链表的头节点,存储着可能冲突的节点(类似邻接表,二维矩阵的结构)
}HashTable;
//哈希表的初始化
void init(HashTable* table, int size) //传入一个实例化的哈希表,和指定的哈希表大小
{
table->size = size;
table->item = (Node**)malloc(size * sizeof(Node*));//item指针数组,类型是Node类型
for (int i = 0; i < size; i++)
{
table->item[i] = NULL;
}
}
//哈希函数
unsigned int HashFunction(HashTable*table ,int key)
{
return key % table->size;
}
void insert(HashTable*table,int key,int value)
{
unsigned int index = HashFunction(table, key);//根据哈希函数获取头部节点的索引
//头插法添加新节点
Node* newnode = (Node*)malloc(sizeof(Node));
newnode->key = key;
newnode->value = value;
//头插 这里的table.item[i]也是一个节点(最前面的一个节点)
newnode->next = table->item[index];
table->item[index] = newnode;
}
int search(HashTable*table,int key)
{
unsigned int index = HashFunction(table, key);
//创建一个指针指向对应的index头部
Node* current = table->item[index];
while (current != NULL)
{
if (current->key == key) //key是唯一的,找到了对应的key节点
{
return current->value; //返回该节点的value值
}
else
{
current = current->next;
}
}
return INT_MIN;
}
// 释放内存
void FreeHash(HashTable*table)
{
//每个节点都要释放
for (int i = 0; i < table->size; i++)
{
Node* current = table->item[i];
while (current!= NULL)
{
Node* temp = current;
current = current->next;
free(temp);
}
}
free(table->item);
}
void get_result(int number)
{
if (number == INT_MIN)
{
printf("哈希表中未找到该节点!\n");
}
else
{
printf("查询结果为:%d\n",number);
}
}
int main()
{
HashTable table;
init(&table, 10);
insert(&table,1, 10);
insert(&table, 2, 200);
insert(&table, 22, 300);
int result = search(&table, 23);
int result2 = search(&table, 22);
get_result(result);
get_result(result2);
return 0;
} 9、补充说明:
上面的这种链地址法结构,和图的邻接表结构类似,和利用二级指针创建二维矩阵的过程存在一定区别,注意区分。