我们在读取文件夹下面的文件时,有时是希望能够按照相应的顺序来读取,但是 file_lists=os.listdir()返回的文件名不一定是顺序的,也就是说结果是不固定的。就比如读取下面这些文件,希望能够按照图中的顺序进行读取,但是
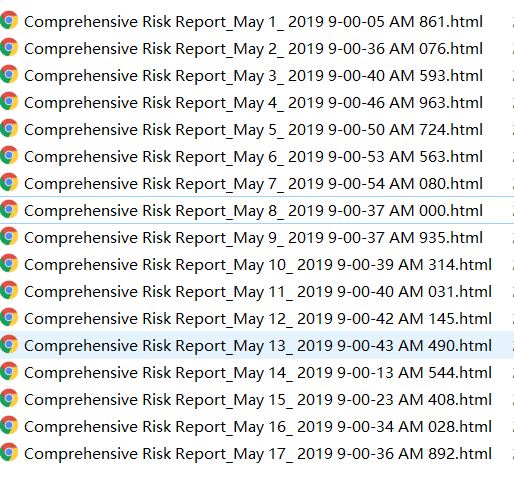
得到的结果却是这样:
['Comprehensive Risk Report_May 10_ 2019 9-00-39 AM 314.html',
'Comprehensive Risk Report_May 11_ 2019 9-00-40 AM 031.html',
'Comprehensive Risk Report_May 12_ 2019 9-00-42 AM 145.html',
'Comprehensive Risk Report_May 13_ 2019 9-00-43 AM 490.html',
'Comprehensive Risk Report_May 14_ 2019 9-00-13 AM 544.html',
'Comprehensive Risk Report_May 15_ 2019 9-00-23 AM 408.html',
'Comprehensive Risk Report_May 16_ 2019 9-00-34 AM 028.html',
'Comprehensive Risk Report_May 17_ 2019 9-00-36 AM 892.html',
'Comprehensive Risk Report_May 1_ 2019 9-00-05 AM 861.html',
'Comprehensive Risk Report_May 2_ 2019 9-00-36 AM 076.html',
'Comprehensive Risk Report_May 3_ 2019 9-00-40 AM 593.html',
'Comprehensive Risk Report_May 4_ 2019 9-00-46 AM 963.html',
'Comprehensive Risk Report_May 5_ 2019 9-00-50 AM 724.html',
'Comprehensive Risk Report_May 6_ 2019 9-00-53 AM 563.html',
'Comprehensive Risk Report_May 7_ 2019 9-00-54 AM 080.html',
'Comprehensive Risk Report_May 8_ 2019 9-00-37 AM 000.html',
'Comprehensive Risk Report_May 9_ 2019 9-00-37 AM 935.html']
而且在采用 file_lists.sort() 以及 sorted(file_lists()) 后,结果还是如此.
这是因为文件排序都是按字符串来的,不会特意给你分成数字,根据文件中字符在ascii码中的顺序,并且将字符串中每个字符作比较,得到结果。上面的 11和1_的问题,1相同,而后一位1在_前面,如果换成减号-那它就在1前面,或者将序号放在最后,那排序就正常了,这就是按中间字符排序会出现乱七八糟问题的原因
这时就需要自己根据文件自定义排序:
# 读取文件并进行排序
filelists = os.listdir(path)
sort_num_first = []
for file in filelists:
sort_num_first.append(int(file.split("_")[1].split(" ")[1])) # 根据 _ 分割,然后根据空格分割,转化为数字类型
sort_num_first.sort()
print(sort_num_first)
sorted_file = []
for sort_num in sort_num_first:
for file in filelists:
if str(sort_num) == file.split("_")[1].split(" ")[1]:
sorted_file .append(file)
思路很简单,就是把文件名根据 _ 和 空格 分割,得到中间的数字,然后进行排序;然后将排好的数字一一对应到相应的文件名,就得到了排好了的文件。