聚类算法之KMeans(Java实现)
KMeans算法的基本思想是初始随机给定K个簇中心,按照最邻近原则把待分类样本点分到各个簇。然后按平均法重新计算各个簇的质心,从而确定新的簇心。一直迭代,直到簇心的移动距离小于某个给定的值。
当初始簇心选行不好时,KMeans的结果会很差,所以一般是多运行几次,按照一定标准(比如簇内的方差最小化)选择一个比较好的结果。
下图给出对坐标点的聚类结果:
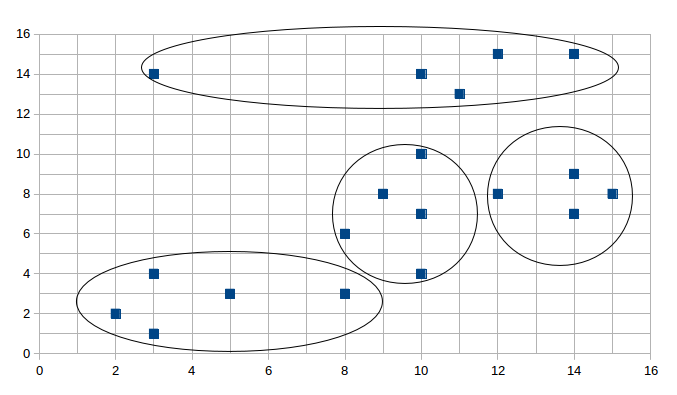
下面给出核心算法的代码:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
|
/**
* Author: Orisun
* Date: Sep 10, 2011
* FileName: KMeans.java
* Function:
*/
package
orisun;
import
java.io.File;
import
java.util.ArrayList;
import
java.util.Iterator;
import
java.util.Random;
public
class
KMeans {
int
k;
// 指定划分的簇数
double
mu;
// 迭代终止条件,当各个新质心相对于老质心偏移量小于mu时终止迭代
double
[][] center;
// 上一次各簇质心的位置
int
repeat;
// 重复运行次数
double
[] crita;
// 存放每次运行的满意度
public
KMeans(
int
k,
double
mu,
int
repeat,
int
len) {
this
.k = k;
this
.mu = mu;
this
.repeat = repeat;
center =
new
double
[k][];
for
(
int
i =
0
; i < k; i++)
center[i] =
new
double
[len];
crita =
new
double
[repeat];
}
// 初始化k个质心,每个质心是len维的向量,每维均在left--right之间
public
void
initCenter(
int
len, ArrayList
Random random =
new
Random(System.currentTimeMillis());
int
[] count =
new
int
[k];
// 记录每个簇有多少个元素
Iterator
while
(iter.hasNext()) {
DataObject object = iter.next();
int
id = random.nextInt(
10000
)%k;
count[id]++;
for
(
int
i =
0
; i < len; i++)
center[id][i] += object.getVector()[i];
}
for
(
int
i =
0
; i < k; i++) {
for
(
int
j =
0
; j < len; j++) {
center[i][j] /= count[i];
}
}
}
// 把数据集中的每个点归到离它最近的那个质心
public
void
classify(ArrayList
Iterator
while
(iter.hasNext()) {
DataObject object = iter.next();
double
[] vector = object.getVector();
int
len = vector.length;
int
index =
0
;
double
neardist = Double.MAX_VALUE;
for
(
int
i =
0
; i < k; i++) {
// double dist = Global.calEuraDist(vector, center[i], len);
// //使用欧氏距离
double
dist = Global.calEditDist(vector, center[i], len);
// 使用编辑距离
if
(dist < neardist) {
neardist = dist;
index = i;
}
}
object.setCid(index);
}
}
// 重新计算每个簇的质心,并判断终止条件是否满足,如果不满足更新各簇的质心,如果满足就返回true.len是数据的维数
public
boolean
calNewCenter(ArrayList
int
len) {
boolean
end =
true
;
int
[] count =
new
int
[k];
// 记录每个簇有多少个元素
double
[][] sum =
new
double
[k][];
for
(
int
i =
0
; i < k; i++)
sum[i] =
new
double
[len];
Iterator
while
(iter.hasNext()) {
DataObject object = iter.next();
int
id = object.getCid();
count[id]++;
for
(
int
i =
0
; i < len; i++)
sum[id][i] += object.getVector()[i];
}
for
(
int
i =
0
; i < k; i++) {
if
(count[i] !=
0
) {
for
(
int
j =
0
; j < len; j++) {
sum[i][j] /= count[i];
}
}
// 簇中不包含任何点,及时调整质心
else
{
int
a=(i+
1
)%k;
int
b=(i+
3
)%k;
int
c=(i+
5
)%k;
for
(
int
j =
0
; j < len; j++) {
center[i][j] = (center[a][j]+center[b][j]+center[c][j])/
3
;
}
}
}
for
(
int
i =
0
; i < k; i++) {
// 只要有一个质心需要移动的距离超过了mu,就返回false
// if (Global.calEuraDist(sum[i], center[i], len) >= mu) { //使用欧氏距离
if
(Global.calEditDist(sum[i], center[i], len) >= mu) {
// 使用编辑距离
end =
false
;
break
;
}
}
if
(!end) {
for
(
int
i =
0
; i < k; i++) {
for
(
int
j =
0
; j < len; j++)
center[i][j] = sum[i][j];
}
}
return
end;
}
// 计算各簇内数据和方差的加权平均,得出本次聚类的满意度.len是数据的维数
public
double
getSati(ArrayList
int
len) {
double
satisfy =
0.0
;
int
[] count =
new
int
[k];
double
[] ss =
new
double
[k];
Iterator
while
(iter.hasNext()) {
DataObject object = iter.next();
int
id = object.getCid();
count[id]++;
for
(
int
i =
0
; i < len; i++)
ss[id] += Math.pow(object.getVector()[i] - center[id][i],
2.0
);
}
for
(
int
i =
0
; i < k; i++) {
satisfy += count[i] * ss[i];
}
return
satisfy;
}
public
double
run(
int
round, DataSource datasource,
int
len) {
System.out.println(
"第"
+ round +
"次运行"
);
initCenter(len,datasource.objects);
classify(datasource.objects);
while
(!calNewCenter(datasource.objects, len)) {
classify(datasource.objects);
}
datasource.printResult(datasource.objects, k);
double
ss = getSati(datasource.objects, len);
System.out.println(
"加权方差:"
+ ss);
return
ss;
}
public
static
void
main(String[] args) {
DataSource datasource =
new
DataSource();
datasource.readMatrix(
new
File(
"/home/orisun/test/dot.mat"
));
datasource.readRLabel(
new
File(
"/home/orisun/test/dot.rlabel"
));
// datasource.readMatrix(new File("/home/orisun/text.normalized.mat"));
// datasource.readRLabel(new File("/home/orisun/text.rlabel"));
int
len = datasource.col;
// 划分为6个簇,质心移动小于1E-8时终止迭代,重复运行7次
KMeans km =
new
KMeans(
4
, 1E-
10
,
7
, len);
int
index =
0
;
double
minsa = Double.MAX_VALUE;
for
(
int
i =
0
; i < km.repeat; i++) {
double
ss = km.run(i, datasource, len);
if
(ss < minsa) {
minsa = ss;
index = i;
}
}
System.out.println(
"最好的结果是第"
+ index +
"次。"
);
}
}
|