python爬虫前程无忧——数据分析+词云图
要求:
1.爬取字段:职位名称、薪资水平、招聘单位、工作地点、工作经验、学历要求、工作内容(岗位职责)、任职要求(技能要求)。
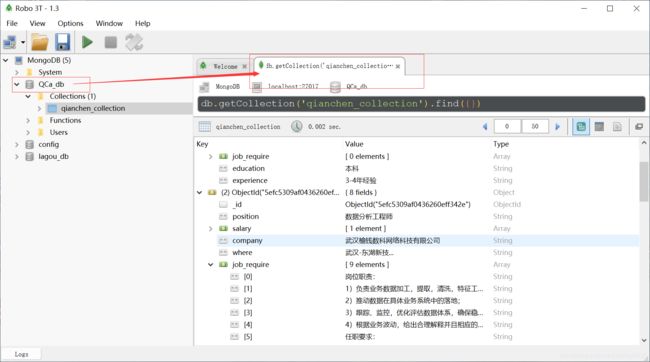
2.数据存储:将爬取的数据存储到MongoDB数据库中。
3.数据分析与可视化:
(1)分析“数据分析”、“大数据开发工程师”、“数据采集”等岗位的平均工资、最高工资、最低工资,并作条形图将结果展示出来;
(2)分析“数据分析”、“大数据开发工程师”、“数据采集”等大数据相关岗位在成都、北京、上海、广州、深圳的岗位数,并做饼图将结果展示出来。
(3)分析大数据相关岗位1-3年工作经验的薪资水平(平均工资、最高工资、最低工资),并做出条形图展示出来;
4.词云图
基本结构图:
scrapy startproject qianchen01
cd qianchen01
scrapy genspider -t crawl qianchen qianchen.com

基本配置:
items.py
import scrapy
class Qianchen01Item(scrapy.Item):
position = scrapy.Field() #职位名称
salary = scrapy.Field() #工资
company = scrapy.Field() #公司名字
where = scrapy.Field() #地点
job_require = scrapy.Field() #工作要求、内容
experience = scrapy.Field() #经验
education = scrapy.Field() #教育
pipelines.py(连接MongoDB)
from pymongo import MongoClient
class Qianchen01Pipeline(object):
# 在open_spider方法中连接MongoDB,创建数据库和集合,也可以在__init__初始化方法中处理这些操作
def open_spider(self, spider):
self.db = MongoClient('localhost', 27017).QCa_db
self.collection = self.db.qianchen_collection
def process_item(self, item, spider):
# 把Item转化成字典方式,然后添加数据
self.collection.insert_one(dict(item))
return item
settings.py
USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4168.2 Safari/537.36'
ROBOTSTXT_OBEY = False
DOWNLOAD_DELAY = 1
ITEM_PIPELINES = {
'qianchen01.pipelines.Qianchen01Pipeline': 300,
}
2.数据存储:将爬取的数据存储到MongoDB数据库中。 qianchen.py
# -*- coding: utf-8 -*-
import scrapy
from qianchen01.items import Qianchen01Item
class QianchenSpider(scrapy.Spider):
name = 'qianchen'
allowed_domains = ['51job.com']
start_urls = ['https://search.51job.com/list/000000,000000,0130%252C7501%252C7506%252C7502,01%252C32%252C38,9,99,%2520,2,1.html?lang=c&stype=&postchannel=0000&workyear=99&cotype=99°reefrom=99&jobterm=99&companysize=99&providesalary=99&lonlat=0%2C0&radius=-1&ord_field=0&confirmdate=9&fromType=&dibiaoid=0&address=&line=&specialarea=00&from=&welfare=']
def parse(self, response):
joblist = response.xpath("//div[@id='resultList']/div[@class='el']")
for job in joblist:
item = Qianchen01Item()
item["position"] = job.xpath("./p/span/a/@title").extract_first() #职位
item["salary"] = job.xpath("./span[@class='t4']/text()").extract() #工资
item["company"] = job.xpath("./span[@class='t2']/a/@title").extract_first() #公司名字
item["where"] = job.xpath("./span[@class='t3']/text()").extract_first() #地点
#详情页面
detail_url = job.xpath("./p/span/a/@href").extract_first()
yield scrapy.Request(url=detail_url, callback=self.parse_detail, meta={"item": item})
next_url = response.xpath("//div[@class='p_in']//li[@class='bk'][2]/a/@href").extract_first()
if not next_url:
return
yield scrapy.Request(url=next_url, callback=self.parse)
def parse_detail(self, response):
item = response.meta["item"]
item["job_require"] = response.xpath("//div[@class='bmsg job_msg inbox']/p/text()").extract()#工作需求
item["education"] = response.xpath("//div[@class='tHeader tHjob']/div/div/p[2]/text()").extract()[2]#学历
item["experience"] = response.xpath("//div[@class='tHeader tHjob']/div/div/p[2]/text()").extract()[1]#经验
yield item
3.数据分析与可视化:
(1)分析“数据分析”、“大数据开发工程师”、“数据采集”等岗位的平均工资、最高工资、最低工资,并作条形图将结果展示出来;
# coding:utf-8
import pymongo # python连接mongodb数据库模块
import re
from wordcloud import WordCloud # 词云图绘制模块
from collections import Counter # 获取数据库链接游标
from pyecharts.charts import Bar, Pie, WordCloud # bar:条形图绘制模块,pie:饼图绘制模块,wordcloud:词云图绘制模块
from pyecharts.render import make_snapshot # 绘图模块
from pyecharts import options as opts, options
myclient = pymongo.MongoClient("localhost", port=27017) # 数据库IP地址
mydb = myclient["QCa_db"] # 数据库名称
mytable = mydb["qianchen_collection"] # 表名称
# 分析相关岗位的平均工资、最高工资、最低工资
# 最低工资
min_salary_list = []
# 最高工资
max_salary_list = []
# 平均工资
average_salary_list = []
# 岗位
addr_list = []
class PyMongoDemo(object):
def diqugangweishu(self):
init_opts: opts.InitOpts = opts.InitOpts()
chengdu_num = 0
beijing_num = 0
shanghai_num = 0
guangzhou_num = 0
shenzhen_num = 0
for i in mytable.find({"position": {"$regex": "大数据开发工程师"}}, {'position', 'where'}):
Workplace = i["position"].split("-")[0]
if "成都" in Workplace:
chengdu_num += 1
elif "北京" in i["position"]:
beijing_num += 1
elif "上海" in i["position"]:
shanghai_num += 1
elif "广州" in i["position"]:
guangzhou_num += 1
elif "深圳" in i["position"]:
shenzhen_num += 1
print(chengdu_num, beijing_num, shanghai_num, guangzhou_num, shenzhen_num)
# all_num = chengdu_num + beijing_num + shanghai_num + guangzhou_num + shanghai_num
data = [("成都", chengdu_num), ("北京", beijing_num), ("上海", shanghai_num), ("广州", guangzhou_num),
("深圳", shenzhen_num)]
num = [chengdu_num, beijing_num, shanghai_num, guangzhou_num, shenzhen_num]
print(data)
# 创建图表对象
pie = Pie()
# 关联数据
pie.add(
# 设置系列名称
series_name="大数据岗位地区分析",
# 设置需要展示的数据
data_pair=data,
# 设置圆环空心部分和数据显示部分的比例
radius=["30%", "70%"],
# 设置饼是不规则的
rosetype="radius"
)
# 设置数据显示的格式
pie.set_series_opts(label_opts=options.LabelOpts(formatter="{b}: {d}%"))
# 设置图表的标题
pie.set_global_opts(title_opts=options.TitleOpts(title="大数据开发工程师"))
# 数据渲染
pie.render('大数据开发工程师区岗位.html')
# 分析大数据相关岗位1-3年工作经验的薪资水平
def fenxi1_3xinzishuiping(self):
choice1 = "万/月"
choice2 = "千/月"
choice = input("请输入你要分析的薪资单位(1:万/月,2:千/月):")
if choice == '1':
choice = choice1
elif choice == '2':
choice = choice2
else:
return choice
print(choice)
for i in mytable.find({
"$or": [{"experience": {"$regex": "1"}}, {"experience": {"$regex": "2"}},
{"experience": {"$regex": "3"}}
], "$and": [{"position": {"$regex": "大数据"}}, {"salary": {"$regex": "{}".format(choice)}}]},
{"position", "salary", "experience"}):
#print(i)
salary1 = i["salary"]
test = "".join(salary1)
min_salary = test.split("-")[0]
# print(min_salary)
max_salary = re.findall(r'([\d+\.]+)', (test.split("-")[1]))[0]
average_salary = "{:.1f}".format((float(min_salary) + float(max_salary)) / 2)
company = i["position"]
# print(company)
min_salary_list.append(min_salary)
max_salary_list.append(max_salary)
average_salary_list.append(average_salary)
addr_list.append(company)
bar = Bar(
init_opts=opts.InitOpts(width="10000px", height="800px"),
)
bar.set_global_opts(
title_opts=opts.TitleOpts(title="大数据相关岗位1-3年工作经验的薪资", subtitle="单位 {}".format(choice)),
xaxis_opts=opts.AxisOpts(axislabel_opts={"rotate": 45}),
)
bar.add_xaxis(addr_list)
bar.add_yaxis("最高薪资", max_salary_list)
bar.add_yaxis("最低薪资", min_salary_list)
bar.add_yaxis("平均薪资", average_salary_list)
bar.render("大数据岗位1-3年工作经验的薪资水平.html")
if __name__ == "__main__":
mongo = PyMongoDemo()
a = 0
b = 0
a = str(input("请输入你要选择的功能(1:分析大数据岗位的地区分布,2:分析大数据相关岗位1-3年工作经验的薪资水平)"))
while True:
if a == '1':
mongo.diqugangweishu()
continue
elif a == '2':
mongo.fenxi1_3xinzishuiping()
continue
else:
print("输入错误,请重新输入!")
break

(2)分析“数据分析”、“大数据开发工程师”、“数据采集”等大数据相关岗位在成都、北京、上海、广州、深圳的岗位数,并做饼图将结果展示出来。
(3)分析大数据相关岗位1-3年工作经验的薪资水平(平均工资、最高工资、最低工资),并做出条形图展示出来;
# coding:utf-8
import pymongo # python连接mongodb数据库模块
import re
from wordcloud import WordCloud # 词云图绘制模块
from collections import Counter # 获取数据库链接游标
from pyecharts.charts import Bar, Pie, WordCloud # bar:条形图绘制模块,pie:饼图绘制模块,wordcloud:词云图绘制模块
from pyecharts.render import make_snapshot # 绘图模块
from pyecharts import options as opts, options
myclient = pymongo.MongoClient("localhost", port=27017) # 数据库IP地址
mydb = myclient["QCa_db"] # 数据库名称
mytable = mydb["qianchen_collection"] # 表名称
# 分析相关岗位的平均工资、最高工资、最低工资
# 最低工资
min_salary_list = []
# 最高工资
max_salary_list = []
# 平均工资
average_salary_list = []
# 岗位
addr_list = []
class PyMongoDemo(object):
def diqugangweishu(self):
init_opts: opts.InitOpts = opts.InitOpts()
chengdu_num = 0
beijing_num = 0
shanghai_num = 0
guangzhou_num = 0
shenzhen_num = 0
for i in mytable.find({"position": {"$regex": "大数据开发工程师"}}, {'position', 'where'}):
Workplace = i["position"].split("-")[0]
if "成都" in Workplace:
chengdu_num += 1
elif "北京" in i["position"]:
beijing_num += 1
elif "上海" in i["position"]:
shanghai_num += 1
elif "广州" in i["position"]:
guangzhou_num += 1
elif "深圳" in i["position"]:
shenzhen_num += 1
print(chengdu_num, beijing_num, shanghai_num, guangzhou_num, shenzhen_num)
# all_num = chengdu_num + beijing_num + shanghai_num + guangzhou_num + shanghai_num
data = [("成都", chengdu_num), ("北京", beijing_num), ("上海", shanghai_num), ("广州", guangzhou_num),
("深圳", shenzhen_num)]
num = [chengdu_num, beijing_num, shanghai_num, guangzhou_num, shenzhen_num]
print(data)
# 创建图表对象
pie = Pie()
# 关联数据
pie.add(
# 设置系列名称
series_name="大数据岗位地区分析",
# 设置需要展示的数据
data_pair=data,
# 设置圆环空心部分和数据显示部分的比例
radius=["30%", "70%"],
# 设置饼是不规则的
rosetype="radius"
)
# 设置数据显示的格式
pie.set_series_opts(label_opts=options.LabelOpts(formatter="{b}: {d}%"))
# 设置图表的标题
pie.set_global_opts(title_opts=options.TitleOpts(title="大数据开发工程师"))
# 数据渲染
pie.render('大数据开发工程师区岗位.html')
# 分析大数据相关岗位1-3年工作经验的薪资水平
def fenxi1_3xinzishuiping(self):
choice1 = "万/月"
choice2 = "千/月"
choice = input("请输入你要分析的薪资单位(1:万/月,2:千/月):")
if choice == '1':
choice = choice1
elif choice == '2':
choice = choice2
else:
return choice
print(choice)
for i in mytable.find({
"$or": [{"experience": {"$regex": "1"}}, {"experience": {"$regex": "2"}},
{"experience": {"$regex": "3"}}
], "$and": [{"position": {"$regex": "大数据"}}, {"salary": {"$regex": "{}".format(choice)}}]},
{"position", "salary", "experience"}):
#print(i)
salary1 = i["salary"]
test = "".join(salary1)
min_salary = test.split("-")[0]
# print(min_salary)
max_salary = re.findall(r'([\d+\.]+)', (test.split("-")[1]))[0]
average_salary = "{:.1f}".format((float(min_salary) + float(max_salary)) / 2)
company = i["position"]
# print(company)
min_salary_list.append(min_salary)
max_salary_list.append(max_salary)
average_salary_list.append(average_salary)
addr_list.append(company)
bar = Bar(
init_opts=opts.InitOpts(width="10000px", height="800px"),
)
bar.set_global_opts(
title_opts=opts.TitleOpts(title="大数据相关岗位1-3年工作经验的薪资", subtitle="单位 {}".format(choice)),
xaxis_opts=opts.AxisOpts(axislabel_opts={"rotate": 45}),
)
bar.add_xaxis(addr_list)
bar.add_yaxis("最高薪资", max_salary_list)
bar.add_yaxis("最低薪资", min_salary_list)
bar.add_yaxis("平均薪资", average_salary_list)
bar.render("大数据岗位1-3年工作经验的薪资水平.html")
if __name__ == "__main__":
mongo = PyMongoDemo()
a = 0
b = 0
a = str(input("请输入你要选择的功能(1:分析大数据岗位的地区分布,2:分析大数据相关岗位1-3年工作经验的薪资水平)"))
while True:
if a == '1':
mongo.diqugangweishu()
continue
elif a == '2':
mongo.fenxi1_3xinzishuiping()
continue
else:
print("输入错误,请重新输入!")
break


4.词云图
1.先从MongoDB把数据拿出来存成txt文件格式(在cmd中运行)
mongoexport -h localhost:27017 -d QCa_db -c qianchen_collection -o D:\qc.txt
# -h :数据库地址,MongoDB 服务器所在的 IP 与 端口,如 localhost:27017
# -d :指明使用的数据库实例,如 test
# -c 指明要导出的集合,如 c1
# -o 指明要导出的文件名,如 E:/wmx/mongoDump/c1.json,注意是文件而不是目录,目录不存在时会一同新建

import jieba
from wordcloud import WordCloud
import matplotlib.pyplot as plt # 绘制图像的模块
import jieba.analyse as anls # 关键词提取
#从MongoDB里面提取数据:
# mongoexport -h localhost:27017 -d QCa_db -c qianchen_collection -o D:\qc.txt
#
# -h :数据库地址,MongoDB 服务器所在的 IP 与 端口,如 localhost:27017
# -d :指明使用的数据库实例,如 test
# -c 指明要导出的集合,如 c1
# -o 指明要导出的文件名,如 E:/wmx/mongoDump/c1.json,注意是文件而不是目录,目录不存在时会一同新建
# 1、读取文本
text = open("D:\\qc.txt", 'r', encoding='utf-8').read()
# 加载停用词表
stopwords = [line.strip() for line in open('words.txt', encoding='UTF-8').readlines()] # list类型
# 分词未去停用词
text_split = jieba.cut(text) # 未去掉停用词的分词结果 list类型
# 去掉停用词的分词结果 list类型
text_split_no = []
for word in text_split:
if word not in stopwords:
text_split_no.append(word)
# print(text_split_no)
text_split_no_str = ' '.join(text_split_no) # list类型分为str
# 基于tf-idf提取关键词
print("基于TF-IDF提取关键词结果:")
keywords = []
for x, w in anls.extract_tags(text_split_no_str, topK=200, withWeight=True):
keywords.append(x)
keywords = ' '.join(keywords) # 转为str
print(keywords)
# 画词云
wordcloud = WordCloud(
# 设置字体,不然会出现口字乱码,文字的路径是电脑的字体一般路径,可以换成别的
font_path="C:/Windows/Fonts/simhei.ttf",
# 设置了背景,宽高
background_color="white", width=1000, height=880).generate(keywords) # keywords为字符串类型
plt.imshow(wordcloud, interpolation="bilinear")
plt.axis("off")
plt.savefig('词云.jpg')
plt.show()
