数据挖掘学习日记6·以K-means为例的聚类算法基本流程
聚类分析
总述
聚类分析和回归和分类不同,是一种无监督的方法,将数据对象划分为不同的类,类称为“簇”,簇的集合称为聚类。聚类分析算法使同一类的数据彼此相似,不同类之间的彼此相异,相似性和相异性的度量如下。
对象之间的相似性/相异性
对象之间的相似性和相异性常用相异度矩阵来表示,相异度矩阵中的d(x,y)表示对象x与对象y的相异程度。
数值型数据的相似性/相异性
通常,使用距离来表示两个对象之间的相似性/相异性,距离的计算方法有多种,其中最常用的是欧式距离(欧基里德距离),而欧式距离又由闵可夫斯基距离到出。闵可夫斯基(Minkowski)距离如下所示:
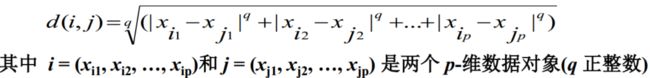
当q=1时,则为曼哈坦(Manhattan)距离:
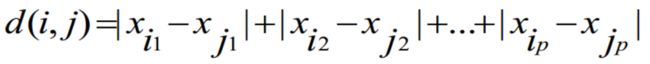
q=2时,则为欧式距离(Euclidean):
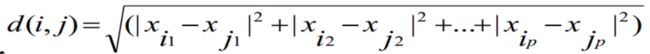
显然,上述闵可夫斯基距离公式只适用于数值类型的数据。
在文档分析时,通常会使用若干维的向量来表示一份文档,每一维表示一个词语的词频,显然这些数据是极不对称的,且存在大量的零。这种场景下,优先选择余弦相似度来表征对象之间的相似性:
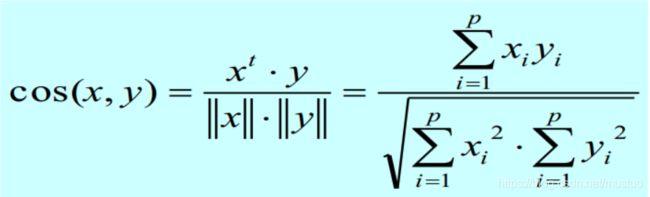
标称数据的相似性/相异性
标称数据有多种取值,是二元变量的推广,可以取多于两种状态。标称数据的相似性/相异性可以通过以下方法得到:
一、简单匹配

即,用两个对象之间的失配率来表示相异性。
二、预处理后使用数值型数据计算方法
有如下预处理方法:
- 对标称数据的每一个状态,创建一个新的二元变量。
- 离散化与归一化:通过数据分层与离散化,再将数据归一化到[0,1]数据范围内
>>扩展阅读 如何度量数据的相似性和相异性
【问】如果一个类中有多个样本,如何计算类与类之间的距离?
可以通过计算簇的形心(如计算样本均值),来确定簇中心。
应用场景
聚类分析已经广泛应用于许多应用领域,包括商务智能、图像模式识别、Web搜索、生物学和安全。
除此之外还应用在数据洞察、数据预处理和离群点检测中。
商务智能
早先,人人的手机资费套餐都是相同的,“雨露均沾”。但现在,往往会有不同的套餐供选择。
我们在选择手机资费套餐的时候,会从多种多种套餐中挑出一款最合适的。何为最合适?即对自己而言最合算的。
例如,如果上网多,就会选择无限流量套餐;老人家不上网,但打电话多,就会选择通话资费优惠的电话套餐,等等。
又或者有从众者,懒于繁琐的比较,直接选择和朋友一样的套餐——“哎呀,咱俩生活习惯相似,你选啥我也选啥吧。”
因此,运营商市场部门会实现对用户进行分类,“对症下药”对不同类型的客户推出针对性强的套餐。
图像模式识别
比如手写体识别。对于相同的字,每个人的书写习惯不尽相同。可以通过聚类方法收集同一文字的子类,建立“变体库”,使用基于子类的多个模型提高整体识别的准确率。
Web搜索
Web搜索的结果非常的庞大,关键词搜索往往会返回大量命中对象。可以使用聚类将结果进行分组,改以简明的形式来呈现。
数据洞察
使用聚类可以发现一些意料外的模式,可自动地发现分组,因此聚类又称“自动分类”。
异常点检测
在数据预处理中,需要去除噪声(离群点),可以采用的有统计学方法和聚类方法。
1.基于统计学方法:检查最值、均值、方差,数据可视化。
2.基于距离方法:设置一个中心对象和距离阈值,将与中心对象距离超过阈值的数据对象判定为孤立点(孤立岛)。
K-means算法
k-means算法,即k-均值算法是一种基于形心的技术,使用划分方法将数据集D中的对象分配到k个簇中,并使用一个目标函数来评估划分质量,使得簇内对象相互相似,而与其他簇中的对象相异——即,簇内高相似性,簇间低相似性。
k-means算法使用簇的形心(簇内点的均值,当数据为标称类型时使用众数)代表簇,使用簇内变差(簇中对象与形心差的平方和)度量簇的质量。
和穷举算法不同,k-means使用启发式的算法进行计算,因此不能保证算法收敛于全局最优解,并且它常常终止于一个局部最优解。
k-means算法流程概述
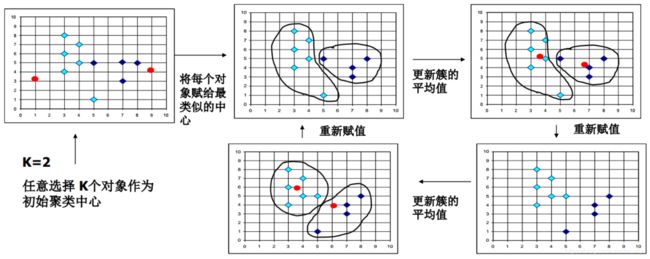
- 在数据集D中随机地选择k个对象,每个对象代表一个簇的初始均值或中心。其余每个对象根据与簇中心的欧氏距离,分配到最近的簇中。
- 迭代地改编簇内变差:对每个簇,根据上次迭代分配到的簇对象,重新计算均值(将对象的x值和y值分别取平均得到新的簇中心)。
- 将更新后的均值作为新的簇中心,重新分配所有对象。
- 迭代继续,直到分配稳定——本轮形成的簇与前一轮形成的簇相同(所有对象所属的类标签或所有簇中心不再改变)。
算法缺陷
- 仅当簇的均值有定义时才能使用。当涉及标称属性的数据时,均值可能无定义,此时可以使用k-均值的变体k-众数(k-modes),使用簇众数取带均值来更新聚类标称数据。
- 必须事先给出要生成簇数k,或者提供k值的近似范围,使用分析技术确定最佳的k值。
- 不适合发现非凸状的簇,或者大小差别很大的簇。
- 算法对噪声敏感。