使用SpringBoot整合ES
整合ES的要求很低,只要能发送请求,那它就能操作ES,因此,下面来分析一下那种整合ES的方式更为优雅高效
ES端口选择
ES服务器有两个可选端口,一个是9200(HTTP),一个是9300(TCP),可以通过操作TCP连接来通过9300端口进行ES操作,但是官方不建议使用9300来进行操作,后续版本会废弃相关的jar包,因此我们的端口选择只能是9200
第三方工具选择
既然是只能操作9200端口,那也就是能发送HTTP请求的工具都是可以的(比如都可以使用postman来进行es操作)
- JestClient:版本更新慢,更新周期长(非官方)
- RestTemplate:Spring提供可以发送任何HTTP请求,但是操作ES麻烦,需要拼接字符串
- HTTPClient,OKHTTP:也是发送HTTP请求的工具
- Elasticsearch-Rest-Client:官方的RestClient,对ES操作进行了封装,使用简单,版本更新也比较及时(最终选择)。
使用SpringBoot整合
在mall-parent下新建一个服务mall-search
添加依赖
org.elasticsearch.client
elasticsearch-rest-high-level-client
7.4.2
完成后查看发现有些的版本不符合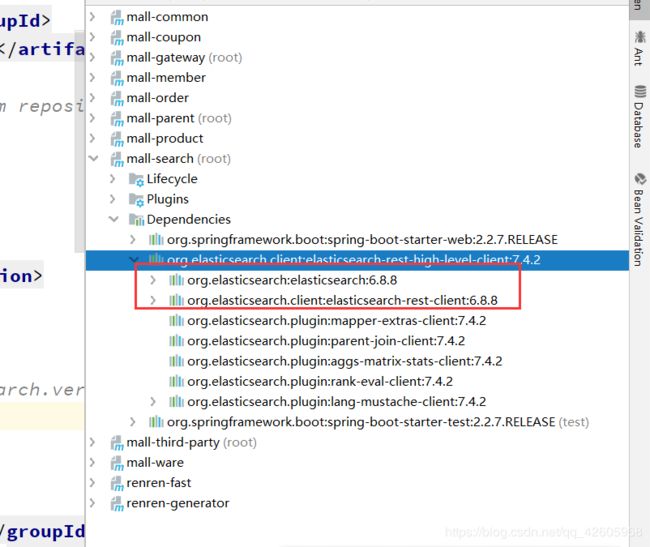
原因是SpringBoot对其版本也进行了管理,需要重新覆盖管理
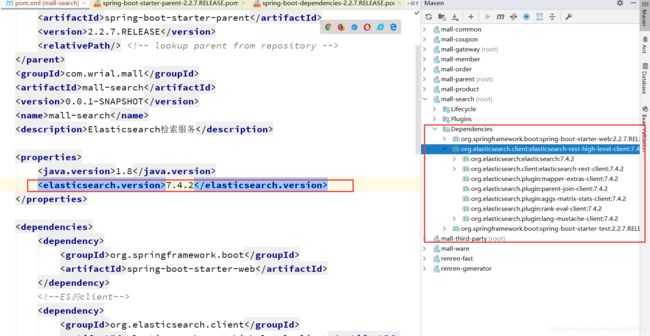
导入依赖后配置RestHighLevelClient
@Configuration
public class MallElasticSearchConfig {
@Bean
public RestHighLevelClient esRestClinet(){
RestHighLevelClient client = new RestHighLevelClient(
RestClient.builder(
new HttpHost("120.27.240.223", 9200, "http")));
return client;
}
}
使用Test测试
@SpringBootTest
class MallSearchApplicationTests {
@Autowired
private RestHighLevelClient client;
@Test
public void testES(){
System.out.println(client);
}
}
可以打印出RestHighLevelClient对象说明成功

API测试
index测试
/**
* 测试存储
*/
@Test
public void testIndexData() throws IOException {
IndexRequest indexRequest = new IndexRequest("users");
indexRequest.id("1");
// indexRequest.source("userName", "zhangsan", "age", "18");
User user = new User();
user.setAge(18);
user.setUserName("lisi");
user.setGender("男");
String jsonString = JSONObject.toJSONString(user);
// 必须指定XContentType
indexRequest.source(jsonString, XContentType.JSON);
// 执行
IndexResponse response = client.index(indexRequest, MallElasticSearchConfig.COMMON_OPTIONS);
// 获取响应数据
System.out.println(response);
}
@Data
class User {
private String userName;
private String gender;
private Integer age;
}

index是保存更新二合一的,第二次就是更新操作,version等会变化
复杂检索
得到bank索引下的,address含有mill的人,并对这些人进行年龄的值分布聚合和计算这些人的平均薪资聚合
/**
* 测试检索
*/
@Test
public void testSearch() throws IOException {
// 创建检索请求
SearchRequest searchRequest = new SearchRequest();
// 指定索引
searchRequest.indices("bank");
// 指定DSL
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
searchSourceBuilder.query(QueryBuilders.matchQuery("address", "mill"));
// 按照年龄的值分布进行聚合
searchSourceBuilder.aggregation(AggregationBuilders.terms("aggAge").field("age").size(10));
// 计算平均薪资
searchSourceBuilder.aggregation(AggregationBuilders.avg("balanceAvg").field("balance"));
System.out.println("检索条件"+searchSourceBuilder.toString());
searchRequest.source(searchSourceBuilder);
// 同步执行(也可以使用异步)
SearchResponse searchResponse = client.search(searchRequest, MallElasticSearchConfig.COMMON_OPTIONS);
//分析结果
System.out.println(searchResponse);
}

经验证后和在Kibana中的结果是一样的。
查询及分析结果的解析
/**
* 测试检索
*/
@Test
public void testSearch() throws IOException {
// 创建检索请求
SearchRequest searchRequest = new SearchRequest();
// 指定索引
searchRequest.indices("bank");
// 指定DSL
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
searchSourceBuilder.query(QueryBuilders.matchQuery("address", "mill"));
// 按照年龄的值分布进行聚合
searchSourceBuilder.aggregation(AggregationBuilders.terms("aggAge").field("age").size(10));
// 计算平均薪资
searchSourceBuilder.aggregation(AggregationBuilders.avg("balanceAvg").field("balance"));
System.out.println("检索条件" + searchSourceBuilder.toString());
searchRequest.source(searchSourceBuilder);
// 同步执行(也可以使用异步)
SearchResponse searchResponse = client.search(searchRequest, MallElasticSearchConfig.COMMON_OPTIONS);
//分析结果
System.out.println(searchResponse);
// 获取所有命中的结果
SearchHits hits = searchResponse.getHits();
SearchHit[] hitsHits = hits.getHits();
for (SearchHit hit : hitsHits) {
String string = hit.getSourceAsString();
Account account = JSONObject.parseObject(string, Account.class);
System.out.println("account:"+account);
}
// 获取分析信息
Aggregations aggregations = searchResponse.getAggregations();
Terms aggAge = aggregations.get("aggAge");
aggAge.getBuckets().forEach((bucket)->{
String keyAsString = bucket.getKeyAsString();
System.out.println("年龄为"+keyAsString+"有"+bucket.getDocCount()+"人");
});
Avg avg = aggregations.get("balanceAvg");
System.out.println("平均薪资为"+avg.getValue());
}
@Data
@ToString
static class Account{
private int account_number;
private int balance;
private String firstname;
private String lastname;
private int age;
private String gender;
private String address;
private String employer;
private String email;
private String city;
private String state;
}
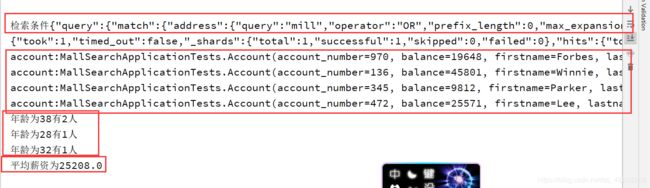
就可以基于这样的方式使用Java操作ES了!