郑重声明:原文参见标题,如有侵权,请联系作者,将会撤销发布!
1、Abstract:
本文主要介绍的是2015年以来关于深度图像/视频编码的代表性工作,主要可以分为两类:深度编码方案以及基于传统编码方案的深度工具。对于深度编码方案,像素概率建模和自动编码器是两种方法,分别可以看作是预测编码方案和变换编码方案。对于深度工具,有几种使用深度学习来执行帧内预测、帧间预测、跨通道预测、概率分布预测、变换、后处理、环内滤波器、上/下采样以及编码优化的建议技术。为了倡导基于深度学习的视频编码研究,本文对我们开发的视频编解码器即深度学习视频编码(Deep Learning Video Coding,DLVC)进行了案例研究。DLVC具有两个深度工具,分别为基于CNN的环路滤波器(CNN-based in-loop filter,CNN-ILF)以及基于CNN的块自适应分辨率编码(CNN-based block adaptive resolution coding,CNN-BARC)。这两种工具都有助于显著提高压缩效率。在随机存取和低延迟配置下,利用这两种深度工具以及其他非深度编码工具,DLVC比HEVC平均节省39.6%和33.0%的比特。
2、Introduction:
A. Image/Video Coding:
有损图像/视频编码解决方案的评价分为两个方面:一是压缩效率,通常用比特数(编码率)来衡量,越低越好;二是产生的损失,通常用重建图像/视频的质量来衡量,与原始图像/视频相比,越高越好。
目前,H.265/HEVC已于2013年正式发布,代表着最先进的图像/视频编码技术。随着视频技术的进步,特别是超高清晰度(ultra-high definition,UHD)视频的普及,迫切需要进一步提高压缩效率,以便在有限的存储空间和有限的传输带宽中容纳UHD视频。因此,在HEVC、MPEG和VCEG组成联合视频专家组(the Joint Video Experts Team,JVET)后,对先进的视频编码技术进行了探索,并开发了联合探索模型(Joint Exploration Model,JEM)进行了研究。此外,自2018年以来,JVET团队一直致力于开发一种新的视频编码标准,即多功能视频编码(Versatile Video Coding,VVC),作为HEVC的继承者。与HEVC相比,VVC可以在保持相同质量的同时节省约50%的比特,特别是对于UHD视频,从而提高压缩效率。然而,值得注意的是,VVC的改进可能以牺牲乘法编码/解码的复杂性为代价。
B. Deep Learning for Image/Video Coding:
本文旨在对最新的基于深度学习的图像/视频编码报告(截至2018年底)进行全面回顾,并对我们开发的原型视频编解码器即深度学习视频编码(DLVC)进行案例研究,以使感兴趣的读者了解现状。读者也可以参考[84]获取关于同一主题的最近发表的评论论文。
C. Preliminaries:
在本文中,我们考虑了自然图像/视频的编码方法,即人们通过日常相机或手机拍摄的图像/视频。虽然这些方法通常都适用,但它们是专门为自然图像/视频设计的,对于其他类型(如生物医学、遥感)来说,它们可能表现不太好。
目前,几乎所有的自然图像/视频都是数字格式。灰度数字图像可以表示为Dm x n,其中m和n是图像的行数(高度)和列数(宽度),D是单个图片元素(像素)的定义域。例如,D={0,1,……,255}是一种常用设置,其中|D|=256=28。因此,像素值可以用一个8位整数表示;因此,未压缩的灰度数字图像每像素有8位(bits-per-pixel,bpp),而压缩后的比特更少。
因为人类的视觉对亮度比色度更敏感,所以YCbCr(YUV)颜色空间比RGB采用的要多得多,U和V通道通常采用下采样以实现压缩。现有的无损编码方法对自然图像的压缩比可以达到1.5~3,明显低于实际需求。因此,引入有损编码来压缩更多的数据,但代价是造成损失。损失可以通过原始图像和重建图像之间的差异来测量,例如,对灰度图像使用均方误差(mean-squared-error,MSE)。此外,重建图像与原始图像相比的质量可以通过峰值信号音调比(peak signal-tonoise ratio,PSNR)来测量。对于彩色图像/视频,通常单独计算Y、U、V的PSNR值。对于视频,通常分别计算不同帧的PSNR值,然后取其平均值。在PSNR的替代中还有其他质量指标,如结构相似性(structural similarity,SSIM)和多尺度SSIM(multi-scale SSIM,MS-SSIM)[126]。
为了比较不同的无损编码方案,只需比较压缩比或结果率(bpp、bps等)。为了比较不同的有损编码方案,有必要同时考虑码率和质量。例如,计算几个不同质量水平下的相对码率,然后对码率进行平均,这是一种常用的方法;平均相对码率被称为Bjontegaard’s delta-rate (BD-rate)[13]。评价图像/视频编码方案还有其他重要方面,包括编码/解码的复杂性、可扩展性、鲁棒性等。
3、Review of deep schemes:
在本节中,我们将回顾一些具有代表性的深度编码方案。一般来说,深度图像编码有两种方法,即像素概率建模和自动编码器。这两种方法在几个深度学习方案中结合在一起。此外,我们还讨论了深度视频编码方案和特殊用途编码方案,其中特殊用途编码方案又可以进一步分为感知编码和语义编码。

A. Pixel Probability Modeling:
根据香农的信息理论[102],无损编码的最优方法可以达到的最小值为- log2p(x),其中p(x)是符号x的概率。为了达到这一目标,人们发明了许多无损编码方法,并且认为算术编码[129]是最理想的方法之一。给定概率 p(x) ,算术编码确保编码码率尽可能接近 - log2p(x) 。因此,剩下的问题是找出概率,但这对于自然图像/视频来说是非常困难的,因为它具有很高的维度。
估计 p(x) 的一种方法是将图像分解为 m x n 像素,并逐个估计这些像素的概率(例如以光栅扫描顺序)。这是一种典型的预测编码策略,注意:
![]()
如图1所示,这里 xi 的条件也称为 xi 的上下文。当图像较大时,条件概率很难估计。简化是为了减少上下文的范围,例如:
![]()
其中。 k 是一种预设定的常数。
众所周知,深度学习擅长解决回归和分类问题。因此,在给定上下文 x1, ... , xi-1 的情况下,建议使用经过训练的深度网络来估计概率 p(xi | x1, ... , xi-1) 。早在2000年就有人提出了这种策略[12]用于其他类型的高维数据,但直到最近才应用于图像/视频。例如,在[58]中,考虑二值图像的概率估计, xi 取 +1 或 -1 ,可以预测每个像素的概率值 p(xi = +1 | x1, ... , xi-1) 。这篇文章提出了一种神经自回归分布估计方法(the neural autoregressive distribution estimator,NADE),即对每个像素使用一个隐层的前馈网络,并在这些网络中共享参数。参数共享也有助于加速每个像素的计算。在[37]中也有类似的工作,其中前馈网络也有跳过隐层的连接,并且参数也被共享。[58]和[37]都对二值化的MNIST数据集(http://yann.lecun.com/exdb/mnist/.)进行了实验。Uria等人[116]将NADE扩展到实值NADE(real-valued NADE,RNADE),其中概率p(xi | x1, ... , xi-1)由高斯混合分布构成,前馈网络需要为高斯混合模型输出一组参数,而不是NADE中的单个值。他们的前馈网络有一个隐层和参数共享,但隐层加入了重新缩放以避免饱和,并使用校正线性单元(rectified linear unit,ReLU)[90]而不是sigmoid。他们还考虑到拉普拉斯混合分布而不是高斯混合分布。他们在 8 x 8 的自然图像进行了实验,其中将像素值加入噪声,转换为真实值。在[117]中,NADE和RNADE通过使用不同的像素顺序以及网络中使用更多隐层来改进。在[120]中,通过使用深度GMM来增强高斯混合模型(the Gaussian mixture model,GMM),RNADE得到了改进。
先进网络的设计是提高像素概率建模的重要课题。在[109]中,提出了基于多维长短期存储器(long short-term memory,LSTM)的网络,以及对条件高斯尺度混合的混合。后者是GMM的一个推广,用于概率建模。LSTM是一种递归神经网络(RNNs),被认为擅长对序列数据进行建模。LSTM的空间变体被用于图像。然后在[118]中,研究了几个不同的网络,包括RNNs和CNNs,分别被称为PixelRNN和PixelCNN。对于PixelRNN,提出了两种LSTM变体,称为行LSTM和对角线BiLSTM,后者专门为图像设计。PixelRNN整合了残差连接[40]来帮助训练高达12层的深度网络。对于PixelRNN,为了适应上下文的形状(见图1),提出了屏蔽卷积(masked convolutions)。PixelCNN也有15层的深度。与之前的作品相比,PixelRNN和PixelCNN更专注于自然图像:他们将像素视为离散值(例如0,1,……,255),并预测离散值的多项式分布;他们处理彩色图像(在RGB颜色空间中);多尺度PixelRNN被提出;它们在CIFAR-10和ImageNet数据集上工作得很好。相当多的研究遵循了PixelRNN和PixelCNN的方法。在[119]中,门控PixelCNN(Gated PixelCNN)被提议改进PixelCNN,并达到与PixelCNN相当的性能,但其复杂性要低得多。在[99]中,PixelCNN++提出了对PixelCNN的以下改进:使用离散化的逻辑混合概率而不是256路多项式分布;下采样用于捕获多分辨率的结构;为加速训练引入了额外的短路连接;正则化采用随机失活(Dropout);一个像素包含RGB。在[18]中,提出了PixelSNAIL,其中随意卷积(casual convolutions)与自我注意力(self attention)相结合。
上面提到的大多数工作都直接模拟像素概率。此外,像素概率可以通过显式或隐式表示作为条件概率建模。也就是说,我们可以估计:

其中 h 是附加条件。还要注意,p(x)=p(h)p(x|h),这意味着建模分为无条件的和有条件的。例如,在[119]中,附加条件可以是由另一个深度网络派生的图像类或高级图像表示。在[56]中,考虑了带有潜在变量的PixelCNN,其中潜在变量来自原始图像:它们可以是原始彩色图像的量化灰度版本,也可以是多分辨率图像金字塔。
对于实际的图像编码方案,在[64]中,采用了一个具有修剪卷积的网络来预测二进制数据的概率,而一个8位的灰度图像(大小为 m x n )被转换成一个 m x n x 8 的二进制立方体,由网络进行处理。该网络类似于PixelCNN,但是三维的。据报道,基于网络的修剪卷积算术编码(The trimmed convolutional network-based arithmetic encoding,TCAE)比以前的非深度无损编码方案(如TIFF、GIF、PNG、JPEG-LS和JPEG 2000-LS)要好。在 Kodak 图像集中,TCAE达到2.00的压缩比。不同的是,在[4]中,CNN用于小波变换域,而不是像素域,即CNN用于从相邻子带内的系数预测小波细节系数。
对于视频编码,在[52]中,PixelCNN被概括为视频像素网络(video pixel network,VPN),用于视频像素概率建模。VPN由CNN编码器(用于预测当前帧)和PixelCNN解码器(用于当前帧内的预测)。CNN编码器在所有层保留输入帧的空间分辨率,以最大化表示能力。采用扩张卷积扩大接收场,更好地捕捉全局运动。随着时间的推移,CNN编码器的输出与一个卷积LSTM相结合,该LSTM还保留了分辨率。PixelCNN解码器使用屏蔽卷积,并在离散像素值上采用多项式分布。
此外,Schiopu等人[101]研究一种无损图像编码方案,他们使用CNN预测像素值,而不是其分布。预测值从实际像素值中减去,从而产生残差,然后进行编码。此外,他们还考虑了CNN预测器和一些非CNN预测器中的自适应选择。
B. Auto-Encoder:
自动编码器源于Hinton和Salakhutdinov[42]的著名工作,通过训练一个由编码部分和解码部分组成的网络进行降维。编码部分将输入的高维信号转换为低维表示,解码部分从低维表示中恢复(不完全)高维信号。自动编码器实现了表示的自动学习,消除了手工制作功能的需要,这也是深度学习最重要的优点之一。
采用自动编码器网络进行有损图像编码似乎很简单:编码和解码都经过训练,我们只需要对学习到的表示进行编码。然而,传统的自动编码器没有针对压缩进行优化,直接使用一个训练好的自动编码器不是一种有效的手段[127]。当我们考虑到压缩需求时,有几个挑战:首先,对低维表示进行量化,然后进行编码,但量化步骤不可微,使得网络训练困难。第二,有损编码是为了在码率和质量之间实现更好的权衡,因此在训练网络时应考虑码率,但码率不容易计算或估计。第三,一个实用的图像编码方案需要考虑可变码率、可伸缩性、编码/解码速度、互操作性等因素。针对这些挑战,近年来进行了大量的研究。
基于自动编码器的图像编码方案的概念图如下图所示,这是一种典型的变换编码策略。

在网络结构上,RNN和CNN是应用最广泛的两类。最具代表性的作品包括:
- Toderici等人[111]提出了一种可变码率图像压缩的通用框架。他们使用二值化来生成代码,并且在训练过程中不考虑码率,即损失只是端到端的失真,用MSE度量。他们的框架确实提供了一个可扩展的编码功能,其中具有卷积和反卷积层的RNN(特别是LSTM),据报道性能良好。对 32 x 32 的缩略图,他们提供了在大规模数据集上的测试结果。后来,Toderici等人[112]提出了一个改进的版本,他们使用PixelRNN[118]这样的神经网络来压缩二进制代码;他们还引入了一个新的门控循环单元(gated recurrent unit,GRU),其灵感来自于残差网络(the residual network,ResNet)[40]。他们在使用MS-SSIM作为质量度量的Kodak图像集上得到了比JPEG更好的结果。Johnston等人[51]进一步改进基于RNN的方法,使用SSIM加权损失函数将隐藏状态启动引入RNN,并启动空间自适应比特率。他们在使用MS-SSIM作为质量度量的Kodak图像集上获得了比BPG更好的效果。Covell等人[22]通过训练允许停止代码的RNN来启用空间自适应比特率。
- Ball'e等人[9]提出了率失真优化图像压缩的通用框架。他们使用多变量量化来生成整数代码,并在训练期间考虑码率,即损失是率失真联合成本,其中失真可能是MSE或其他。为了估计码率,他们在训练过程中使用随机噪声代替量化,并使用噪声“代码”的差分熵作为码率的代表。对于网络结构,采用了广义除数归一化(the generalized divisive normalization,GDN)变换,该变换由线性映射(矩阵乘法)和非线性参数归一化组成。在[8]中验证了GDN对图像编码的有效性。后来,Ball'e等人[10]提出一个改进的版本,其中他们使用3个卷积层,每个卷积层后紧接着下采样和一个GDN操作来实现变换;相应地,使用3个逆GDN+上采样+卷积层来实现反变换。此外,他们还设计了一种算术编码方法来压缩整数码。他们在使用MSE作为质量度量的Kodak图像集上取得了比JPEG和JPEG 2000更好的结果。此外,Ball'e等人[11]通过在自动编码器中加入一个尺度超先验来改进他们的方案,这是受到变分自动编码器的启发[55]。他们使用另一个变换 ha 将 y 转换为 w=ha(y),对 w 进行量化和编码(作为边信息传输),并使用另一个反变换 hs 将解码后的 w ^ 转换为量化后的 y ^ 的估计标准偏差,然后在对 y ^ 进行算术编码时使用。在Kodak图像集上使用PSNR作为质量度量,他们的方法只比BPG稍差。
除[9]外,一些工作还集中于处理不可微量化和/或码率估计。Theis等人[110]采用一种非常简单的方法进行量化:量化通常在前通中进行,但梯度直接通过后通中的量化层。令人惊讶的是,这项工作进展顺利。此外,他们将码率替换成了一个可微的上界。Dumas等人[29]考虑一个随机优胜者全得机制,其中 y 中具有最大绝对值的条目被保留,其他条目被设置为0;然后这些条目被统一量化和压缩。Agustsson等人[2]提出一种从软到硬的矢量量化方案,在该方案中,他们在训练过程中使用软量化(即分配一个表征给具有不同成员值的多个代码),而不是硬量化(即分配一个表征给仅一个代码),并且他们采用退火过程使软量化方法逐渐向硬量化转变。值得注意的是他们的计划利用了矢量量化而其他作品通常采用标量量化。Li等人[65]引入一个用于码率估计的重要性图,重要性图被量化为一个掩模,掩模决定每个位置保留多少比特,因此重要性图的和可以用作编码码率的粗略估计。
除[111]外,一些工作还考虑了可变码率的功能,对不同码率进行较少训练或者不进行训练。在[110]中,引入了比例参数,并针对不同的码率对预训练的自动编码器进行了微调。在[30]中提出了一种由学习得到的独特变换,以及针对不同码率的可变量化步骤。在[15]中,针对所有尺度对多尺度分解变换进行了训练和优化;并提供了码率分配算法,针对目标码率或目标质量因子,确定每个图像块的最佳尺度。此外,可伸缩编码在[146]中的考虑与在[111]中的不同。在[146]中,图像被分解成多个位平面,并被并行转换和量化;为了减少不同位平面之间的相关性,提出了双向组合选通单元。
有几项工作考虑了先进的网络结构和不同的损失函数。Theis等人[110]采用亚像素结构以提高计算效率。Rippel和Bourdev[97]提出了一个金字塔分解,然后是规模间校准网络,它是轻量级的,并且实时运行。除重建损失外,他们还使用了鉴别损失。Snell等人[104]使用MS-SSIM作为损失函数,而不是MSE或平均绝对误差(MAE)来训练自动编码器,他们发现MS-SSIM能够更好地校准感知质量。Zhou等[149]使用更深的网络设计编码器/解码器,并在解码器中使用单独的网络进行后处理。他们还将[11]中的高斯模型替换为拉普拉斯模型。
如前所述,像素概率模型表示预测编码,自动编码器表示变换编码。这两种策略可以结合起来提高压缩效率。Mentzer等人[87]提出了一种实用的无损图像编码方案,利用多层次的自动编码器学习像素概率建模的条件。Mentzer等人[86]将像素概率建模(a 3D PixelCNN)集成到自动编码器中,以估计编码码率,并对PixelCNN和自动编码器进行联合训练。Baig等人[6]在可变码率压缩框架[111]中引入局部上下文图像,该框架实际上是根据块的上下文预测块,假设块按光栅扫描顺序逐个编码/解码。将预测信号加到网络输出信号上,实现 x^ ,即变换编码网络处理预测残差。Minen等人[89]另外考虑各区块之间的码率分配。同样,但以不同的方式,Minnen等人[88]在[11]基础上改进,通过增加超先验与上下文,即他们不仅使用 w^ 而且还使用上下文来预测每次进入 y^ 的概率。他们的方法在使用PSNR作为质量度量的Kodak图像集上优于BPG,这代表了到2018年底的最新技术。Lee等人[60]将上下文自适应熵模型引入超先验W^。
此外,Cheng等人[21]将主成分分析应用于所学的表征中,这实际上是第二个变换。
C. Video Coding:
从2017年开始,对深度视频编码方案进行了一些研究。与图像编码相比,视频编码需要有效的方法来消除图像间的冗余。帧间预测是这些研究中的一个重要问题。运动估计和运动补偿被广泛采用,但直到最近才由经过训练的深度网络实现。
Chen等人[17]似乎是第一个使用经过训练的深度网络作为自动编码器来实现视频编码方案的人。具体来说,他们将视频帧分为 32 x 32 的块,每个块从两种模式中进行选择:帧内编码或帧间编码。如果采用帧内编码,会有一个自动编码器对块进行压缩。如果采用帧间编码,则采用传统的方法进行运动估计和运动补偿,并将残差输入到另一个自动编码器中。对于这两个自动编码器,编码方式是采用哈夫曼方法直接进行量化和编码。这个方案相当粗糙,无法与H.264相比。
Wu等人[131]提出一种具有图像插值的视频编码方案,其中关键帧(I帧)首先由[112]中的深度图像编码方案压缩,然后将其余帧(B帧)按层次顺序进行压缩。对于每个B帧,使用前后两个压缩帧(I帧或之前压缩的B帧)来对当前帧进行“插值”操作:运动信息用于对两个压缩帧进行运动补偿,然后将处理后的两个帧作为边信息发送到可变码率图像编码方案来处理当前帧。据报道,该方案的效果与H.264相当。
Chen等人[20]提出另一个视频编码方案PixelMotionCNN。在他们的方案中,每个帧按时间顺序进行压缩,并且按光栅扫描顺序被分成块。在压缩一个帧之前,前两个压缩帧用于“外推”当前帧。当一个块被压缩时,外推帧连同该块的上下文被发送到PixelMotionCNN以生成当前块的预测信号,然后通过[112]中的可变码率图像编码方案来压缩预测残差。该方案的性能也与H.264相当。
Lu等人[80]提出了一种真正端到端的深度视频编码方案,可以看作是传统视频编码方案的“深化”版本。具体地说,在其方案中,对于要压缩的帧,使用光流估计模块来获取帧与已压缩帧之间的运动信息。运动补偿也由经过训练的网络执行,以生成当前帧的预测信号。对预测残差和运动信息分别采用两个自动编码器进行压缩。整个网络采用单损失函数进行联合优化,即联合率失真成本。据报道,该方案比H.264具有更好的压缩效率,在使用MS-SSIM进行评估时甚至优于HEVC(x265编码器)。
Rippel等人[98]提出了迄今为止最复杂的深度视频编码方案,它继承并扩展了传统视频编码方案的深化版本。其方案具有以下新特点:(1)只有一个自动编码器可以同时压缩运动信息和预测残差;(2)从以前的帧中学习并递归更新的状态;(3)多帧多光流的运动补偿;(4)码率控制算法。据报道,使用MS-SSIM进行评估时,该方案优于HEVC参考软件(HM)。
到2018年底,我们没有观察到任何报告显示,深度视频编码方案在用PSNR评估时优于HM,这似乎是一项艰巨的任务。
D. Special-Purpose Coding:
关于深度方案的研究大多涉及图像/视频编码的信号保真度,即在给定的码率下尽量减少原始图像/视频和重建图像/视频之间的失真,其中失真可以定义为MSE或其他差异。但是,如果我们不关心图像/视频的保真度,我们可能会关心重建图像/视频的感知自然性,或者重建图像/视频在语义分析任务中的效用。后两种质量度量称为感知自然性和语义质量。有一些工作专门为这些质量指标定制图像/视频编码。
1)感知编码:自生成对抗网络(GAN)的兴起[34]以来,深度网络被认为能够生成感知自然图像。利用解码器端的这种能力,可以提高解码图像的感知质量。与普通的GANs中的生成器不同,解码器还应保证解码后的图像与原始图像相似,这就产生了一个受控生成的问题,编码器实际上在编码比特中提供了控制信号。
受到变量自动编码器(the variational auto-encoder,VAE)[55]的启发,Gregor等人[36]提出了一种用于图像生成的Deep Recurrent Attentive Writer(DRAW),它利用RNN作为编码器和解码器扩展了传统的VAE。展开编码器RNN会产生一系列潜在的表示。然后,Gregor等人[35]引入卷积DRAW,观察到它能够将图像转换为一系列越来越详细的表示,范围从全局概念方面到低级细节。因此,他们提出了一种概念性压缩方案,其一个好处是以非常低的比特率实现可信的重建图像。
感知自然性可以由GAN[14]中的鉴别器来评价。一些工作对利用单独的鉴别损失/与MSE或其它损失的联合损失函数进行感知质量深度编码的方案进行了研究。例如,Santurkar等人[100]提出所谓的图像和视频的生成压缩方案。对于图像,他们首先训练一个标准的GAN,然后使用生成器作为解码器,修复它,以最小化MSE和特征损失的总和作为指标训练编码器。对于视频,他们重新使用经过图像训练的编码器和解码器,只传输几个帧,并通过插值恢复解码器端的其他帧。它们的方案能够实现很高的压缩比。Kim等人[54]建立一个新的视频压缩方案,其中一些关键帧通常被压缩(通过H.264),而其他帧则被极度压缩。实际上,边缘是从下采样的非关键帧中提取并传输的。在解码器端,首先对关键帧进行重构,然后对关键帧进行边缘提取。条件GAN通过以边缘为条件的重构关键帧进行训练,然后使用条件GAN生成非关键帧。同样,他们的方案在非常低的比特率下表现良好。
2)语义编码:对保存语义信息或关注语义质量的深度编码方案进行了研究。
Agustsson等人[3]提供了一种基于GAN的极低比特率图像压缩方案。该方案结合了自动编码器和GAN,将解码器和生成器结合在一起。另外,可以将语义标签图用作对编码器的附加输入,并用作鉴别的条件。报告表明,此方案以较高的语义质量对图像进行了重构。在相同码率条件下,在这些图像上进行语义分割比在BPG压缩图像上更加准确。
Luo等人[81]提出一个深度语义图像压缩概念(DeepSIC),将语义信息(e.g.类别)纳入编码位中。这里有两种版本的DeepSIC,都是基于自动编码器实现的。在第一个版本中,从表征y中提取语义信息,并将其编码到比特。在另一个版本中,语义信息不进行编码,而是从解码器端提取量化后的表征y^。Torfason等人[113]用量化后的表征而不是量化后的重建图像来进行语义分析任务(分类和语义分割)。说到这个,解码过程被取消了。他们表示,分类和分割精度值在表征和图像之间非常紧密,但计算复杂性被显著降低。Zhang等人[143]提出了一个深度图像编码方案,同时完成压缩和检索任务。他们的动机是,编码得到的比特不仅可以用于重构图像,还可以在不解码的情况下对图像进行检索。他们使用自动编码器将图像压缩到比特,并使用修改过的分类网络提取二值特征。然后将两个比特部分结合起来,并对用于图像检索的特征提取网络进行微调。其结果表明,在相同的码率下,重构的图像优于JPEG压缩的图像,并且由于微调而提高了检索精度。
Akbari等人[5]设计一个可缩放的图像编码方案,其中编码比特由三层组成。第一层是无损编码的语义分割图;第二层是对原始图像的下采样的无损编码。随着前两层,一个网络被训练来预测原始图像,预测残差被BPG编码为第三层。在用PSNR和MS-SSIM作为质量评价指标的Kodak图像集上,该方案超过了BPG。
Chen和He[19]考虑了利用语义质量度量代替PSNR或感知质量的面部图像深度编码方案。为了这个目的,他们的损失函数有三个部分:MAE,鉴别损失以及语义损失,其中语义损失是通过一个学习到的变换将原始图像和重构图像投影到一个紧凑的欧几里得空间中,并计算它们之间的欧几里得距离。该方案当在以同样的码率进行面部鉴别精度评估时,表现非常好。
4、Review of deep tools:

在这一部分中,我们回顾了一些有代表性的工作,即在传统的编码方案中使用经过训练的深度网络作为工具,或与传统的编码工具一起使用。一般来说,传统的视频编码方案采用混合编码策略,即预测编码和变换编码相结合。如图3所示,输入的视频序列被划分为图片帧,图片帧被划分为块(最大的块称为CTU,在HEVC[108]中可以被分为较小的CUs),块被划分为不同通道(即Y、U、V)。图片帧/块/通道按预先定义的顺序进行压缩,之前压缩的图片帧/块/通道可用于预测以下内容,分别称为帧内预测(块间)、跨通道预测(通道间)和帧间预测(图片间),然后对预测残差进行变换、量化和熵编码,以获得最终的比特。一些辅助信息,如块划分和预测模式,也被熵编码成比特(在图中没有显示)。熵编码步骤采用概率分布预测。由于量化步骤会丢失信息并可能导致伪影,因此建议对重构的视频进行滤波以增强重建的视频,该视频可以在环内(在预测下一个图像帧之前)或在环外(在输出之前)执行。此外,为了减少数据量,图像帧/块/通道可以在压缩前进行下采样,然后进行上采样。最后,编码器需要控制不同的模块,并将它们组合在一起,以实现编码码率、质量和计算速率之间的权衡。编码优化是实际编码系统中的一个重要课题。
训练好的深度网络几乎可以充当图3所示的所有模块,我们在图中指出了深度工具的不同位置。在下面,我们将根据深度工具在整个方案中的使用位置来回顾它们的工作。
A. Intra-Picture Prediction:
帧内预测,是一种预测同一张图片帧中块之间的工具。H.264引入了几种预定义的预测模式,如DC预测和不同方向的外推[128]。编码器可以为每个块选择预测模式,并向解码器发送选择信号。在模式选择时,比较不同模式的编码码率和失真,然后选择率失真成本最小的模式是一种常用的策略。在HEVC中,引入了更多的预测模式[108]。
如图4所示,Li等人[63]提出一个全连接网络用于帧内预测。对于当前的 N x N 块,他们使用上面的 L 行和左边的 L 列,总共 4NL + L2 像素作为上下文。他们使用一个称为New York City Library的图像集来生成训练数据,其中原始图像以不同的量化参数(QPs)进行压缩。在网络训练时,他们研究了两种策略:一个是训练一个包含所有训练数据的模型,另一个是根据HEVC预测模式将训练数据分成两组,分别训练两个模型。这两个模型的策略对于压缩任务效果更好。他们将训练后的网络作为新的预测模式与HEVC模式相结合。测试表明,该方案的BD率比HM下降了3%。
Pfaff等人[94]也采用全连接网络进行帧内预测,但提出将多个网络训练为不同的预测模式。同时,他们提出训练一个单独的网络,其输入也是块的上下文,但输出是不同模式的预测可能性。此外,他们提出对每个基于网络的预测模式使用不同的变换。该方案的性能很高:与改进版本的HM(带有高级块分区)相比,大约降低了6%的BD率。
Hu等人[44]为帧内预测设计了一个渐进空间RNN。与上述工作不同,他们建议利用RNN的顺序建模能力,从上下文到块逐步生成预测。此外,他们还建议使用绝对变换差和(SATD)作为损失函数,并认为SATD与率失真成本的相关性更好。
Cui等人[23]考虑用CNN作帧内预测,或者更具体地说,帧内预测细化。他们使用HEVC预测模式生成预测,然后使用经过训练的CNN来完善预测。值得注意的是,CNN不仅有HEVC的预测,而且还有作为其输入的上下文。这种方法似乎只取得边际收益。
B. Inter-Picture Prediction:
帧间预测,是一种用来在视频帧之间进行预测,从而消除时间冗余的工具。帧间预测是视频编码的核心,它在很大程度上决定了视频编码方案的压缩效率。在传统的视频编码方案中,帧间预测主要由块级运动估计(ME)和运动补偿(MC)实现。给定一个参考帧和一个要编码的块,运动估计将在参考帧中查找与待编码块内的内容最相似的位置,运动补偿则是在找到的位置检索得到对应内容,以便对该块进行预测。许多方法被提出以改进块级运动估计和运动补偿,例如多参考帧、双向预测(即联合使用两个参考帧)、亚像素运动估计和运动补偿等。
受多参考帧的启发,Lin等人[71]通过外推多个参考帧,提出一种新的帧内预测机制。具体地说,他们采用了GANs的拉普拉斯金字塔来从先前压缩的四个帧中外推出一个帧。这个外推帧可以用作其他帧的参考帧。他们报告表明该方法的BD率比HM降低了2%左右。
受双向预测的启发,Zhao等人[148]提出了一种提高预测质量的方法。以前的双向预测只是计算两个预测块的线性组合。他们提出采用训练好的CNN以非线性和数据驱动的方式将这两个预测块结合起来。
受亚像素运动估计和运动补偿的启发,对分数像素插值问题进行了大量的研究,其目的是在参考帧上的分数位置生成虚像素,因为两帧之间的运动不与整数像素对齐。在这里,一个主要的困难是如何准备训练数据,因为分数像素是虚构的。Yan等人[137]提出使用CNN进行半像素插值,其中他们提出一种方法,将高分辨率图像变模糊,然后从模糊图像中采样像素:奇数位置为整数像素,偶数位置为半像素。该方法在[76]中被继承,作者分析了不同模糊度的影响。Zhang等人[141]提出另一种方法,将分数插值公式化为分辨率增强问题。因此,他们对高分辨率的图像进行下采样来得到训练数据。Yan等人[136]考虑另一个公式,将分数像素运动补偿视为帧间回归问题。他们使用视频序列来检索训练数据,在训练过程中,他们依靠分数像素运动估计来对齐不同的帧,使用参考帧作为整数像素,并将当前帧作为分数像素。Yan等人[135]进一步发现分数插值问题的一个关键特征,即其可逆性:如果分数像素可以从整数像素中插值得到,那么整数像素也应该可以从分数像素中插值得到。基于可逆性,他们提出了一种无监督的CNN半像素插值训练方法。
除了提高帧间预测方法外,另一种方法还考虑将帧内预测和帧间预测结合在一起。具体来说,预测信号的生成不仅基于参考帧,而且基于当前帧中的上下文。例如,Huo等人[45]提出使用训练好的CNN来完善帧间预测信号。他们发现,利用待预测块的上下文可以提高预测质量。同样,Wang等人[124]还通过CNN细化帧间预测信号,其中CNN输入包括帧间预测信号、当前块的上下文和帧间预测块的上下文。
C. Cross-Channel Prediction:
跨通道预测是指不同通道之间的预测。在YUV格式中,亮度通道(Y)通常在色度通道(U和V)之前编码。因此,可以从Y预测U,从Y和U预测V。一种传统的方法,称为线性模型(LM),用于跨通道预测。LM的关键思想是,可以使用线性函数从亮度预测色度,但不传输函数的系数;相反,通过执行线性回归从上下文估计色度。这个线性假设似乎过于简化了。
Baig和Torresani[7]研究了图像压缩的彩色化。彩色化是从亮度中预测色度,这是一个不适定的问题,因为一个亮值可以对应多个色度值。因此,他们提出了一个树形结构的CNN,给定一个灰度图像作为输入,它能够生成多个预测(称为多个假设)。当用于压缩时,经过训练的CNN应用于编码器端,产生最佳预测信号的分支作为边信息被编码传输到解码器端。他们将该方法集成到JPEG中,而不改变亮度的编码,实验结果表明,该方法在色度编码方面优于JPEG。
Li等人[67]提出一种类似于LM的跨通道预测方法。特别地,他们设计了一个由全连接部分和卷积部分组成的混合神经网络。前者用于处理上下文,包括三个通道,后者用于处理当前块的亮度通道。融合了两个特征,得到最终的预测结果。这种方法在色度编码上超过LM约2%的BD率。
D. Probability Distribution Prediction:
如前所述,准确的概率估计是熵编码的关键问题。因此,为了提高熵编码效率,许多研究工作利用深度学习进行概率分布预测。这些工作处理不同部分的信息。例如,每个块的帧内预测模式都需要发送到解码器,因此Song等人[106]设计了一个CNN,根据上下文预测帧内预测模式的概率分布。同样,Pfaff等人[94]使用全连接网络,根据上下文预测帧内预测模式的概率分布。如果编码/解码方案允许多个变换,并且每个块可以分配一个变换模式,那Puri等人[96]提出使用CNN预测基于量化变换系数的变换模式的概率分布。在最近的一项研究中,Ma等人[82]考虑量化变换系数的熵编码,特别是直流系数。他们设计了一个CNN,从块的上下文以及块的交流系数来预测块的直流系数的概率分布。
E. Transform:
变换是混合视频编码框架中的一个重要工具,它可以将信号(通常是残差)转换成系数,然后进行量化和编码。视频编码方案一开始采用离散余弦变换(DCT),而后在H.264中用整数余弦变换(ICT)代替。HEVC也采用了ICT,但对 4 x 4 的亮度块采用了整数正弦变换。自适应多重变换和二次变换也有所研究。尽管如此,所有这些变换仍然非常简单。
受自动编码器启发,Liu等人[73]提出了一种基于CNN且类似于DCT的变换方法。该变换由CNN和全连接层组成,其中CNN对输入块进行预处理,全连接层完成变换。在它们的实现中,全连接层由DCT的变换矩阵进行初始化,然后与CNN一起训练。它们使用联合率失真成本来训练网络,其中码率由量化系数的L1范数估计。他们还研究了非对称自动编码器,即编码部分和解码部分不对称,不同于传统的自动编码器。实验结果表明,训练后的变换比固定的DCT变换好,非对称自编码可以有效地实现压缩效率与编码/解码时间之间的权衡。
F. Post- or In-Loop Filtering:
目前广泛使用的图像和视频编码方案大多是有损编码方案,即为了压缩,重建的图像/视频并不完全是原始图像/视频。损失通常是由图3所示的量化过程造成的。当量化步骤较大时,损失也较大,这可能导致重建图像/视频中出现可见的伪影,如阻塞、模糊、响铃、色移和闪烁。滤波是减少这些伪影,提高重建图像/视频质量,从而间接提高压缩效率的工具。对于图像,滤波也被称为后处理,因为它不会改变编码过程。对于视频,根据滤波后的帧是否用作之后帧的参考,滤波分为环内和环外。在HEVC中,提出了两种环内滤波器,即去块滤波器(DF)[91]和样本自适应偏移(SAO)[31]。
基于深度学习的图像/视频编码中,环外或环内滤波占据了大部分相关工作:
- 早期的工作重点是图像编码的后处理,尤其是JPEG。例如,Dong等人[26]提出一个减少压缩伪影的4层CNN,即ARCNN。当质量因子(QF)介于10到40之间时,ARCNN在5幅经典测试图像上的PSNR比JPEG提高了1dB以上。Cavigelli等人[16]使用一个更深的CNN(12层)和分层跳接,对从40到76的QF进行了测试。Wang等人[125]利用JPEG压缩的先验知识,即 8 x 8 块DCT系数的量化,提出了一种基于双域(像素域和变换域)的方法。他们实现了比ARCNN更高的质量和更少的计算时间。在[38]中也对双域处理进行了研究。Guo和Chao[39]提出了一对多网络,它是由感知损失、自然损失和JPEG损失相结合的训练。关于损失函数的另一项工作在[32]中提出,这表明了要像在GAN中一样使用鉴别损失。Ororbia等人[92]提出一种利用训练好的RNN实现的迭代后处理方法。最近,一些工作将JPEG后处理作为图像恢复任务,如去噪或超分辨率,并为一系列图像恢复任务提出不同的网络[78]、[140]、[142]、[144]。
- 在视频编码,尤其是HEVC中,对环外滤波的研究越来越多。Dai等人[24]提出一个用于帧内环外滤波的4层CNN,其中CNN具有可变的滤波器大小和残差连接,并命名为VRCNN。Wang等人[122]使用10层CNN进行环外滤波,训练CNN对图像进行滤波,并在视频帧上使用训练好的CNN。Yang等人[138]提出分别为I帧和P帧训练不同的CNN模型,并验证其增益。Jin等人[50]提出除了MSE损失外,额外使用鉴别损失。Li等人[62]提出将一些边信息传送给解码器,以便从以前训练过的一组模型中为每帧选择一个模型。此外,Yang等人[139]提出为了在后处理过程中利用帧间的相关性,可以通过将多个相邻帧输入到CNN来增强帧的后处理效果。Wang等人[123]也考虑到帧间的相关性,但使用的是多尺度卷积LSTM。尽管上述工作仅将解码后的帧作为CNN的输入,He等人[41]建议将块划分信息连同解码帧一起输入到CNN中。Kang等人[53]也将块划分信息输入到CNN中,设计了多尺度网络。Ma等人[83]向CNN输入帧内预测信号和解码后的残差信号。Song等人[107]将QP和解码帧输入到CNN中(他们还对网络参数进行量化,以确保不同计算平台之间的一致性)。在[114]中提出了一个不同的工作,它没有直接增强解码帧;相反,他们提出计算编码器端的压缩残差(即原始视频减去解码视频,以区别于预测残差),并训练自动编码器对压缩残差进行编码并发送到解码器端。据报道,他们的方法在特定领域的视频序列上表现良好,例如视频游戏流服务。
- 将基于CNN的滤波器集成到编码循环中更具挑战性,因为滤波后的帧将作为参考,并会影响其他编码工具。Park和Kim[93]训练了一个三层CNN作为HEVC的环路滤波器。他们为两个QP范围分别训练两个模型:20–29和30–39,并根据其QP为每个帧选用一个模型。在DF后应用CNN,并关闭SAO。他们还设计了两个基于CNN的滤波器的应用案例:一个案例中,滤波器基于图片顺序计数(POC)应用于指定的帧;另一个案例中,滤波器针对每个帧进行测试,如果提高了质量,则应用它,在这种情况下,每个帧都将一个二进制标志发送给解码器。Meng等人[85]使用LSTM作为环内滤波器,该滤波器在HEVC中的DF之后和SAO之前应用。该网络以块划分信息和解码后的帧作为输入,并结合MS-SSIM损失和MAE损失进行训练。Zhang等人[145]提出一个残差快速通道CNN(RHCNN),用于HEVC中的环内滤波。基于RHCNN的滤波器在SAO后应用。他们分别为I、P和B帧训练不同的RHCNN模型。他们还将QPs划分为多个范围,并为每个范围培训一个单独的模型。Dai等人[25]提出一个叫做VRCNN-ext的深层CNN,用于HEVC中的环内滤波。他们为I帧和P/B帧设计了不同的策略:基于CNN的滤波器取代了I帧的DF和SAO,但在DF之后和SAO之前应用于带CTU和CU级别控制的P/B帧。在CTU级别,每个CTU都有一个二进制标志,用于控制基于CNN的滤波器的开/关;如果该标志为关,则在CU级别,使用二进制分类器来决定是否为每个CU打开基于CNN的滤波器。Jia等人[46]还考虑在HEVC中使用深层CNN进行环内滤波。该滤波器在SAO之后应用,并由帧和CTU级别标志控制。如果帧级别标志为“关闭”,则省略相应的CTU级别标志。此外,他们训练多个CNN模型,并训练一个内容分析网络,为每个CTU决定一个模型,这节省了CNN模型选择的部分。
G. Down- and Up-Sampling:
视频技术的一个趋势是在不同的维度上提高分辨率,例如空间分辨率(即像素数)、时间分辨率(即帧率)和像素值分辨率(即比特深度)。分辨率的提高导致数据量的成倍增加,这对视频传输系统提出了巨大的挑战。当传输带宽受到限制时(例如使用2G或3G移动网络),通常的做法是在编码前降低视频分辨率,在解码后提高视频分辨率。这被称为基于上下采样的编码策略。上下采样可以在空间域、时间域、像素值域或这些域的组合中执行。传统的上下采样滤波器通常是手工制作的。最近,有人提议将深层网络训练为高效视频编码的上下采样滤波器。相关研究分为两类。
第一类的重点是将深层网络训练为仅上采样滤波器,同时仍使用手工制作的下采样滤波器。这是受超分辨率成功的启发,例如[27]。例如,在[1]中,提出了一种联合空间和像素值的下采样,其中空间下采样是通过手工制作的低通滤波器实现的,像素值下采样是通过按位右移实现的。在编码器端,使用支持向量机来决定是否对每个帧执行下采样。在解码器方面,CNN接受了训练,可以将解码后的视频上采样到原始分辨率。在[69]中,Li等人只考虑空间下采样,这也是一个手工制作的滤波器,并训练CNN的上采样。但与[1]不同,他们提出了一种块自适应分辨率编码(BARC)框架。具体来说,对于帧内的每个块,它们考虑两种编码模式:下采样后编码和直接编码。编码器可以为每个块选择一个模式,并向解码器发送所选模式的信号。此外,在下采样编码模式下,他们进一步设计了两个子模式:使用手工制作的简单滤波器进行上采样,和使用经过训练的CNN进行上采样。子模式也向解码器发出信号。Li等人[69]研究的BARC仅针对I帧。后来,Lin等人[72]扩展了P帧和B帧的BARC框架,构建了一个完整的基于BARC的视频编码方案。当上述工作在像素域中执行下采样时,Liu等人[77]建议在残差域中进行下采样,即对帧间预测残差进行下采样,并由经过训练的CNN在考虑预测信号的情况下对残差进行上采样。它们也遵循BARC框架。
第二类不仅训练上采样,还训练下采样过滤器,以允许更多的灵活性。例如,在[47]中,研究了具有两个CNN的压缩框架。第一个CNN对图像进行下采样,然后由现有图像编码器(如JPEG和BPG)压缩下采样图像,然后解码,第二个CNN对解码图像进行上采样。这个框架的一个缺点是它不能接受端到端的训练,因为图像编码器/解码器不可区分。为了解决这个问题,Jiang等人[47]选择优化两个CNN。不同的是,Zhao等人[147]使用实际上是CNN的虚拟编解码器来近似编码器/解码器的功能,并将其进行取代;他们还插入CNN,在上采样CNN之前执行后处理;他们的方案是完全卷积的,并且可以进行端到端的训练。此外,Li等人[68]在训练过程中,只需去掉编码器/解码器,并只保留两个CNN,考虑到下采样图像会被压缩,他们提出了一种新的训练正则化损失,要求下采样图像与理想的低通和抽取(用手工滤波器近似)没有太大的不同。在对CNN进行上下采样联合训练时,验证了正则化损失对图像编码的有效性。
H. Encoding Optimizations:
上述深度工具旨在提高压缩效率,特别是在保持相同的PSNR的同时降低比特率。还有一些针对不同方面的深度工具。在本小节中,我们将回顾几个针对三个不同目标的深度工具:快速编码、码率控制和感兴趣区域(ROI)编码。由于这些工具只在编码器端使用,所以我们将它们统称为编码优化工具。
1)快速编码:对于最先进的视频编码标准H.264和HEVC,解码器计算简单,但编码器更复杂。这是因为越来越多的编码模式被引入到视频编码标准中,并且每个块可以被分配一个不同的模式。每个块的模式都被发送给解码器,因此解码器只需要计算给定的模式。但是,为了找到每个块的模式,编码器通常需要比较多个可选模式,并选择最佳模式,在这种模式下,率失真度要求最优。因此,如果编码器进行穷尽搜索,那么压缩效率最高,但计算复杂度也可能很高。任何一个实际的编码器都会采用启发式算法来寻找一个更好的模式,在这种模式下机器学习,特别是深度学习会有所帮助。
Liu等人[79]介绍了HEVC帧内编码器的硬件设计,其中他们采用经过训练的CNN来帮助确定CU划分模式。特别是在HEVC帧内编码中,CTU递归地划分成CUs,形成四叉树结构。他们训练好的CNN将根据CU内的内容和指定的QP决定是否拆分32 x 32/16 x 16/8 x 8的CU。实际上,这是一个二元决策问题。Xu等人[134]另外考虑到HEVC帧内编码器,提出了一个提前终止的分级CNN和一个提前终止的分级LSTM,分别帮助确定I帧和P/B帧的CU划分模式。Jin等人[49]同样考虑到CU划分模式的决定,但对于输入的VVC而不是HEVC,因为在VVC中,四叉树-二叉树(QTBT)结构是为CU划分设计的,这比HEVC更复杂。他们训练CNN对32 x 32的CU进行5路的分类,不同的分类表示不同的树深度。Xu等人[133]研究H.264到HEVC转码的CU划分模式决策。他们设计了一个层次化的LSTM网络,从H.264编码比特中提取的特征来预测CU划分模式。
Song等人[105]研究一种基于CNN的HEVC编码器快速帧内预测模式决策方法。他们训练CNN,根据内容和指定的QP,得出每个8 x 8/4 x 4块的最可能模式列表,然后通过正常的率失真优化过程从列表中选择一个模式。
2)码率控制:在传输带宽有限的情况下,视频编码器试图产生不会溢出带宽的比特。这就是所谓的码率控制要求。
一种传统的码率控制方法是根据R-λ模型[61]将比特分配给不同的块。在该模型中,每个块要确定两个参数α和β。以前,这些参数是通过经验公式估计的。在[66]中,Li等人提出训练CNN来预测每个CTU的参数。实验结果表明,该方法具有较高的压缩效率和较低的码率控制误差。
Hu等人[43]尝试利用强化学习方法来控制帧内码率。他们对码率控制问题和增强学习问题进行了类比:将块的纹理复杂度和比特平衡视为环境状态,将量化参数视为代理需要采取的行动,块的负失真被认为是立即的奖励。他们训练神经网络作为代理。
3)ROI编码:ROI是指图像中感兴趣的区域。在图像压缩中,通常要求ROI中的内容质量较高,而非ROI中的内容质量较低。许多图像编码方案,如JPEG和JPEG 2000,都支持ROI编码。然后,如何确定ROI是一个研究问题,并已经通过深度学习解决。Prakash等人[95]提出一种基于CNN的方法来生成多尺度ROI(MS-ROI)图,以指导后续的JPEG编码。他们在使用一个训练过的图像分类网络对图像进行处理,选择图像分类网络预测的前五个类,并确定与这些类对应的区域。因此,他们的MS-ROI图显示了与语义分析相关的显著区域。
5、Case study of DLVC:
现在来看看我们开发的DLVC的案例研究,这是一个原型视频编解码器。事实上,DLVC是为响应联合呼吁提出的视频压缩提案而开发的,其能力超过了HEVC。现在,DLVC的源代码已经发布供将来研究(https://github.com/fvc2018/dlvc, http://dlvc.bitahub.com/.)。DLVC是在JEM软件的基础上开发的,比JEM有很多改进,特别是它有两个深度编码工具:基于CNN的环路滤波器(CNN-ILF)和基于CNN的块自适应分辨率编码(CNN-BARC),这两个工具都是基于经过训练的CNN模型。DLVC方案如图5所示。在本节中,我们将重点介绍两个深度工具。有关DLVC的更多技术细节,请参见技术报告[132]。

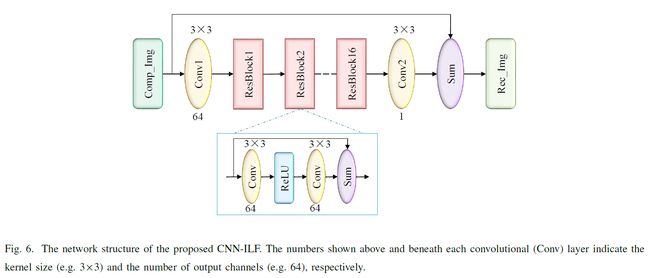
A. CNN-Based In-Loop Filter:
正如第III-F节所提到的,目前已经对使用经过训练的CNN模型进行环外或环内滤波进行了大量的研究。CNN-ILF代表了我们在这方面的努力。
我们提议的CNN-ILF的网络结构如图6所示。受[70]中SR网络的启发,我们设计了一个深度CNN,共有16个残差块(ResBlocks)和2个卷积层,共34层。每个ResBlock由两个由ReLU映射分隔的卷积层和一个跳过连接组成。整个网络具有从输入到输出的全局跳过连接。这些跳跃连接对于训练一个有效的网络和加速训练中的收敛至关重要。
为了训练网络,我们使用了一组自然图像,并在不同的QPs下通过DLVC帧内编码(关闭所有的环内滤波器)压缩每个图像。我们为每个QP训练一个单独的模型。我们只使用亮度组件进行训练,但是训练后的模型在压缩期间用于亮度和色度通道。我们将图像分成70 x 70个子图像,并对这些子图像进行置乱,以准备训练数据。损耗函数为MSE,即网络输出图像与原始未压缩图像之间的误差。我们使用随机梯度下降算法训练网络直到收敛。
我们将训练模型应用于DLVC。CNN-ILF在去块滤波器之后和样本自适应偏移之前应用。不同的QPs对应不同的模型,每个帧根据帧的QP选择一个模型。对于每个CTU,有两个二进制标志分别控制亮度和色度的CNN-ILF的开/关。这些标志在编码器端决定并传输到解码器。
B. CNN-Based Block Adaptive Resolution Coding:
CNN-BARC是一种基于上下采样的编码工具,它使用经过训练的CNN模型作为上下采样滤波器。在DLVC中,CNN-BARC仅用于帧内编码。每个CTU都决定了下采样编码或直接编码模式,下采样编码模式有两个子模式:使用CNN进行下采样和上采样,使用简单的内插滤波器进行下采样和上采样。所有模式和子模式都由编码器决定,并向解码器发出信号。
上下采样网络如图7所示。具体来说,向下采样CNN(CNN-DS)有10个卷积层,其中第一层的步幅为2,以实现2x的向下尺寸。CNN-DS也接受残差学习,但这里的原始图像是双三次下采样,作为跳过连接。上采样CNN(CNN-US)类似于[70]中的SR网络,具有16个ResBlock、3个卷积层、1个反卷积层和一个全局跳过连接。
CNN-DS和CNN-US分四步进行训练。首先,我们去除CNN-DS中的卷积层,使其成为一个简单的双三次下采样,并训练CNN-US最小化端到端的MSE(即原始图像和下采样的上采样图像之间的误差)。第二,我们添加CNN-DS的层,固定CNN-US的参数,训练CNN-DS最小化端到端的MSE。第三,我们同时对CNN-DS和CNN-US的参数进行微调,采用两种损耗的组合:一种是端到端的MSE,另一种是下采样的MSE(即双三次下采样图像和网络下采样图像之间的误差),后者作为一种正则化界限。第四,我们确定了CNN-DS的参数,并在不同的QPs下,通过DLVC帧内编码(关闭所有的环内滤波器)压缩下采样图像。对于每个QP,我们训练一个单独的CNN-US模型。
DLVC编码器中有两个关于CNN-BARC的模式选择步骤。第一种是决定下采样和上采样(子)模式,第二种能决定是否执行下采样。我们比较了不同模式下的率失真成本进行决策。码率是编码比特数,失真是原始CTU和重建CTU之间的MSE。为了公平比较,我们总是以原始分辨率计算失真。最后但并非最不重要的是,在帧内压缩之后,我们再次对下采样编码的CTU执行上采样。有关CNN-BARC的更多详情,请参见[68]、[69]。

C. Compression Performance:
我们在JVET推荐的10个视频序列上测试了DLVC的压缩性能。这些序列按空间分辨率分为A类和B类:5个序列具有UHD(3840 x 2160)分辨率,另外5个序列具有HD(1920 x 1080)分辨率。测试了不同的编码配置,包括全帧内(AI)、低延迟(LD)和随机存取(RA)。我们将DLVC与HEVC参考软件(HM版本16.16,https://hevc.hhi.fraunhofer.de/svn/svn HEVCSoftware/tags/HM-16.16/. 及其变体,以及JEM版本7.0,https://jvet.hhi.fraunhofer.de/svn/svn HMJEMSoftware/tags/HM-16.6-JEM-7.0/. )进行了比较,并使用BD率[13]来测量相对压缩效率。
表II给出了与HEVC相比,DLVC的BD率结果。显然,DLVC大大提高了压缩效率。考虑到Y通道,在RA和LD配置下,DLVC平均比HEVC降低39.6%和33.0%的BD率。结果表明,用DLVC代替HEVC,在不降低重建质量的前提下,可以使比特降低30%以上。

表III给出了与JEM相比,DLVC(文件编号J0032)的BD率结果。为了进行比较,我们还将响应联合提案要求的其他提案的BD率结果包括在内。考虑到Y通道,在RA和LD配置下,DLVC的平均BD率分别比JEM降低10.1%和11.8%。从BD率的角度来看,DLVC是最佳方案之一。
表IV验证了拟议的CNN-ILF的有效性。具体地说,我们使用了一个HM的变体,它添加了QTBT结构,其优于vanilla HM。我们将CNN-ILF集成到锚中,并打开/关闭CNN-ILF进行比较。如表所示,CNN-ILF实现了显著的BD率降低:在RA、LD、AI配置下,Y通道的平均值分别为5.5%、5.2%、6.4%。
表V验证了拟议的CNN-BARC的有效性。我们使用HM的另一个变体添加了四叉树-二叉树-三叉树(QTBTTT)结构,这进一步优于HM加QTBT。我们将CNN-BARC集成到锚中,并打开/关闭CNN-BARC进行比较。如图所示,CNN-BARC在AI配置下实现了显著的BD率降低:Y通道的平均值为5.4%。由于CNN-BARC仅应用于帧内,因此RA和LD配置下的BD率不那么显著。
6、Perspectives and conclusions:
A. Open Problems:
- 深度方案或深度工具。我们应该雄心勃勃地期望深度方案成为视频编码的未来,还是应该对传统非深度方案中的深度工具感到满意?换言之,非深度方案能否完全被深度方案取代?就目前而言,这个问题的答案可能是“不”,因为深度方案一般不会优于非深度方案的视频编码。但是随着研究的不断深入,答案可能会通过两种方式变成“是”:第一,深度方案可能会被改进到明显优于非深度方案;第二,传统编码方案(如HEVC)中的编码工具可能都会被相应的深度工具所取代,从而导致“深度的”“比以前更好的编码方案。根据我们的主观感受,第二种方法可能更实用。



- 压缩效率与计算复杂性。将现有的深度工具与传统非深度方案中的深度工具进行比较,可以发现前者的计算复杂度远高于后者。高复杂性确实是深度学习的一个普遍问题,也是一个关键问题,它阻碍了在有限计算资源(如移动电话)的情况下采用深度网络。目前,这个一般性问题有两个方面:一是开发新型、高效、紧凑的深度网络,保持高性能(即视频编码的压缩效率),但需要的计算量要少得多;二是提倡采用为深度网络专门设计的硬件。
- 对感知自然性或语义质量的优化。为自然视频设计的编码方案通常用于人类观看,例如电视、电影、微视频。对于这些方案来说,重建视频的质量应该根据人类感知进行评估是很自然的。然而,对于传统的非深度编码方案,最广泛采用的质量度量仍然是PNSR,这与人类的感知能力的对应程度很低。对于深度方案或深度工具,已经做了一些工作来优化它们的感知自然性,例如使用鉴别损失。此外,还有一些编码方案,用于自动语义分析而不是人的观看,例如监视视频编码。对于这些方案,质量度量应为语义质量[74],这在很大程度上还未被探索。特别值得注意的是,我们发现信号保真度、感知自然度和语义质量之间存在着权衡[75],这意味着优化目标应与实际需求相一致。
- 专业性和普遍性。从一个极端来看,一个编码方案对任何类型的视频都是最好的吗?答案是“否”,这是由于没有免费午餐定理,这是在机器学习文献[130]中声明的,也适用于压缩。另一个极端是,我们能为每一个视频制定一个特殊的编码方案吗?更不用说实际的困难,这种编码“策略”是无用的,因为它只不过是为每个视频分配一个标识符。在这两个极端之间是实用和有用的编码方案。也就是说,编码方案在某种程度上既具有特殊性,又具有普遍性。对于深度方案和深度工具,这意味着训练数据必须经过精心挑选,以反映感兴趣的数据领域。这方面的研究是值得期待的。
- 多个深度工具的联合设计。目前,大多数深度工具都是单独设计的,但是一旦它们被联合应用,它们就可能无法很好地协作,甚至可能相互冲突。这个根本原因是多个编码工具确实是相互依赖的。例如,不同的预测工具产生不同的预测,导致残差信号的变化,因此处理残差信号的变换工具的性能不同。理想情况下,应联合设计多个深层工具。但是,这可能很困难,因为工具之间的依赖关系很复杂。
B. Future Work:
在可预见的未来,对视频编码技术的要求仍在不断提高。对于娱乐业来说,虚拟现实和增强现实应用程序都在寻求处理新数据的技术,如深度地图、点云、3D表面等。对于监控而言,智能分析的需求推动了视频分辨率的提升。为了科学观测,越来越多的观测仪器直接与录像机相连,产生大量的视频数据。所有这些要求推动视频编码的发展,以实现更高的压缩效率、更低的计算复杂性和更智能地集成到视频分析系统中。我们相信基于深度学习的视频编码技术对于这些具有挑战性的目标是有希望的。特别是,我们期望建立一个基于深度网络的整体框架,并集成图像/视频采集、编码、处理、分析和理解,这确实是模仿人类视觉系统的。
Reference:
[1] M. Afonso, F. Zhang, and D. R. Bull, “Video compression based on spatio-temporal resolution adaptation,” IEEE Transactions on Circuits and Systems for Video Technology, vol. 29, no. 1, pp. 275–280, 2019.
[2] E. Agustsson, F. Mentzer, M. Tschannen, L. Cavigelli, R. Timofte, L. Benini, and L. V. Gool, “Soft-to-hard vector quantization for end-to-end learning compressible representations,” in NIPS, 2017, pp. 1141–1151.
[3] E. Agustsson, M. Tschannen, F. Mentzer, R. Timofte, and L. V. Gool, “Extreme learned image compression with GANs,” in CVPR Workshops, 2018, pp. 2587–2590.
[4] E. Ahanonu, “Lossless image compression using reversible integer wavelet transforms and convolutional neural networks,” Master’s thesis, University of Arizona, 2018.
[5] M. Akbari, J. Liang, and J. Han, “DSSLIC: Deep semantic segmentation-based layered image compression,” in ICASSP, 2019, pp. 2042–2046.
[6] M. H. Baig, V. Koltun, and L. Torresani, “Learning to inpaint for image compression,” in NIPS, 2017, pp. 1246–1255.
[7] M. H. Baig and L. Torresani, “Multiple hypothesis colorization and its application to image compression,” Computer Vision and Image Understanding, vol. 164, pp. 111–123, 2017.
[8] J. Ball´e, “Efficient nonlinear transforms for lossy image compression,” in PCS, 2018, pp. 248–252.
[9] J. Ball´e, V. Laparra, and E. P. Simoncelli, “End-to-end optimization of nonlinear transform codes for perceptual quality,” in PCS. IEEE, 2016, pp. 1–5.
[10] ——, “End-to-end optimized image compression,” arXiv preprint arXiv:1611.01704, 2016.
[11] J. Ball´e, D. Minnen, S. Singh, S. J. Hwang, and N. Johnston, “Variational image compression with a scale hyperprior,” arXiv preprint arXiv:1802.01436, 2018.
[12] Y. Bengio and S. Bengio, “Modeling high-dimensional discrete data with multi-layer neural networks,” in NIPS, 2000, pp. 400–406.
[13] G. Bjontegaard, “Calcuation of average PSNR differences between RD-curves,” VCEG, Tech. Rep. VCEG-M33, 2001.
[14] Y. Blau and T. Michaeli, “The perception-distortion tradeoff,” in CVPR, 2018, pp. 6228–6237.
[15] C. Cai, L. Chen, X. Zhang, and Z. Gao, “Efficient variable rate image compression with multi-scale decomposition network,” IEEE Transactions on Circuits and Systems for Video Technology, DOI: 10.1109/TCSVT.2018.2880492, 2018.
[16] L. Cavigelli, P. Hager, and L. Benini, “CAS-CNN: A deep convolutional neural network for image compression artifact suppression,” in IJCNN. IEEE, 2017, pp. 752–759.
[17] T. Chen, H. Liu, Q. Shen, T. Yue, X. Cao, and Z. Ma, “DeepCoder: A deep neural network based video compression,” in VCIP. IEEE, 2017, pp. 1–4.
[18] X. Chen, N. Mishra, M. Rohaninejad, and P. Abbeel, “PixelSNAIL: An improved autoregressive generative model,” in ICML, 2018, pp. 863–871.
[19] Z. Chen and T. He, “Learning based facial image compression with semantic fidelity metric,” Neurocomputing, vol. 338, pp. 16–25, 2019.
[20] Z. Chen, T. He, X. Jin, and F. Wu, “Learning for video compression,” IEEE Transactions on Circuits and Systems for Video Technology, DOI: 10.1109/TCSVT.2019.2892608, 2019.
[21] Z. Cheng, H. Sun, M. Takeuchi, and J. Katto, “Deep convolutional autoencoder-based lossy image compression,” in PCS. IEEE, 2018, pp. 253–257.
[22] M. Covell, N. Johnston, D. Minnen, S. J. Hwang, J. Shor, S. Singh, D. Vincent, and G. Toderici, “Target-quality image compression with recurrent, convolutional neural networks,” arXiv preprint arXiv:1705.06687, 2017.
[23] W. Cui, T. Zhang, S. Zhang, F. Jiang, W. Zuo, Z. Wan, and D. Zhao, “Convolutional neural networks based intra prediction for HEVC,” in DCC. IEEE, 2017, p. 436.
[24] Y. Dai, D. Liu, and F. Wu, “A convolutional neural network approach for post-processing in HEVC intra coding,” in MMM. Springer, 2017, pp. 28–39.
[25] Y. Dai, D. Liu, Z.-J. Zha, and F. Wu, “A CNN-based in-loop filter with CU classification for HEVC,” in VCIP, 2018, pp. 1–4.
[26] C. Dong, Y. Deng, C. C. Loy, and X. Tang, “Compression artifacts reduction by a deep convolutional network,” in ICCV, 2015, pp. 576–584.
[27] C. Dong, C. C. Loy, K. He, and X. Tang, “Learning a deep convolutional network for image super-resolution,” in ECCV. Springer, 2014, pp. 184–199.
[28] R. D. Dony and S. Haykin, “Neural network approaches to image compression,” Proceedings of the IEEE, vol. 83, no. 2, pp. 288–303, 1995.
[29] T. Dumas, A. Roumy, and C. Guillemot, “Image compression with stochastic winner-take-all auto-encoder,” in ICASSP. IEEE, 2017, pp. 1512–1516.
[30] ——, “Autoencoder based image compression: can the learning be quantization independent?” in ICASSP. IEEE, 2018, pp. 1188–1192.
[31] C.-M. Fu, E. Alshina, A. Alshin, Y.-W. Huang, C.-Y. Chen, C.-Y. Tsai, C.-W. Hsu, S.-M. Lei, J.-H. Park, and W.-J. Han, “Sample adaptive offset in the HEVC standard,” IEEE Transactions on Circuits and Systems for Video technology, vol. 22, no. 12, pp. 1755–1764, 2012.
[32] L. Galteri, L. Seidenari, M. Bertini, and A. Del Bimbo, “Deep generative adversarial compression artifact removal,” in ICCV, 2017, pp. 4826–4835.
[33] R. Girshick, J. Donahue, T. Darrell, and J. Malik, “Rich feature hierarchies for accurate object detection and semantic segmentation,” in CVPR, 2014, pp. 580–587.
[34] I. Goodfellow, J. Pouget-Abadie, M. Mirza, B. Xu, D. Warde-Farley, S. Ozair, A. Courville, and Y. Bengio, “Generative adversarial nets,” in NIPS, 2014, pp. 2672–2680.
[35] K. Gregor, F. Besse, D. J. Rezende, I. Danihelka, and D. Wierstra, “Towards conceptual compression,” in NIPS, 2016, pp. 3549–3557.
[36] K. Gregor, I. Danihelka, A. Graves, D. Rezende, and D. Wierstra, “DRAW: A recurrent neural network for image generation,” in ICML, 2015, pp. 1462–1471.
[37] K. Gregor and Y. LeCun, “Learning representations by maximizing compression,” arXiv preprint arXiv:1108.1169, 2011.
[38] J. Guo and H. Chao, “Building dual-domain representations for compression artifacts reduction,” in ECCV. Springer, 2016, pp. 628–644.
[39] ——, “One-to-many network for visually pleasing compression artifacts reduction,” in CVPR, 2017, pp. 3038–3047.
[40] K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” in CVPR, 2016, pp. 770–778.
[41] X. He, Q. Hu, X. Zhang, C. Zhang, W. Lin, and X. Han, “Enhancing HEVC compressed videos with a partition-masked convolutional neural network,” in ICIP. IEEE, 2018, pp. 216–220.
[42] G. E. Hinton and R. R. Salakhutdinov, “Reducing the dimensionality of data with neural networks,” Science, vol. 313, no. 5786, pp. 504–507, 2006.
[43] J.-H. Hu, W.-H. Peng, and C.-H. Chung, “Reinforcement learning for HEVC/H.265 intra-frame rate control,” in ISCAS. IEEE, 2018, pp. 1–5.
[44] Y. Hu, W. Yang, M. Li, and J. Liu, “Progressive spatial recurrent neural network for intra prediction,” arXiv preprint arXiv:1807.02232, 2018.
[45] S. Huo, D. Liu, F. Wu, and H. Li, “Convolutional neural network-based motion compensation refinement for video coding,” in ISCAS, 2018, pp. 1–4.
[46] C. Jia, S. Wang, X. Zhang, S. Wang, J. Liu, S. Pu, and S. Ma, “Content-aware convolutional neural network for in-loop filtering in high efficiency video coding,” IEEE Transactions on Image Processing, DOI: 10.1109/TIP.2019.2896489, 2019.
[47] F. Jiang, W. Tao, S. Liu, J. Ren, X. Guo, and D. Zhao, “An end-to-end compression framework based on convolutional neural networks,” IEEE Transactions on Circuits and Systems for Video Technology, vol. 28, no. 10, pp. 3007–3018, 2018.
[48] J. Jiang, “Image compression with neural networks–A survey,” Signal Processing: Image Communication, vol. 14, no. 9, pp. 737–760, 1999.
[49] Z. Jin, P. An, L. Shen, and C. Yang, “CNN oriented fast QTBT partition algorithm for JVET intra coding,” in VCIP. IEEE, 2017, pp. 1–4.
[50] Z. Jin, P. An, C. Yang, and L. Shen, “Quality enhancement for intra frame coding via CNNs: An adversarial approach,” in ICASSP. IEEE, 2018, pp. 1368–1372.
[51] N. Johnston, D. Vincent, D. Minnen, M. Covell, S. Singh, T. Chinen, S. Jin Hwang, J. Shor, and G. Toderici, “Improved lossy image compression with priming and spatially adaptive bit rates for recurrent networks,” in CVPR, 2018, pp. 4385–4393.
[52] N. Kalchbrenner, A. van den Oord, K. Simonyan, I. Danihelka, O. Vinyals, A. Graves, and K. Kavukcuoglu, “Video pixel networks,” in ICML, 2017, pp. 1771–1779.
[53] J. Kang, S. Kim, and K. M. Lee, “Multi-modal/multi-scale convolutional neural network based in-loop filter design for next generation video codec,” in ICIP, 2017, pp. 26–30.
[54] S. Kim, J. S. Park, C. G. Bampis, J. Lee, M. K. Markey, A. G. Dimakis, and A. C. Bovik, “Adversarial video compression guided by soft edge detection,” arXiv preprint arXiv:1811.10673, 2018.
[55] D. P. Kingma and M. Welling, “Auto-encoding variational bayes,” arXiv preprint arXiv:1312.6114, 2013.
[56] A. Kolesnikov and C. H. Lampert, “Latent variable PixelCNNs for natural image modeling,” arXiv preprint arXiv:1612.08185, 2016.
[57] A. Krizhevsky, I. Sutskever, and G. E. Hinton, “Imagenet classification with deep convolutional neural networks,” in NIPS, 2012, pp. 1097–1105.
[58] H. Larochelle and I. Murray, “The neural autoregressive distribution estimator,” in Proceedings of the Fourteenth International Conference on Artificial Intelligence and Statistics, 2011, pp. 29–37.
[59] Y. LeCun, Y. Bengio, and G. Hinton, “Deep learning,” Nature, vol. 521, no. 7553, pp. 436–444, May 2015.
[60] J. Lee, S. Cho, and S.-K. Beack, “Context-adaptive entropy model for end-to-end optimized image compression,” arXiv preprint arXiv:1809.10452, 2018.
[61] B. Li, H. Li, L. Li, and J. Zhang, “ domain rate control algorithm for high efficiency video coding,” IEEE Transactions on Image Processing, vol. 23, no. 9, pp. 3841–3854, 2014.
[62] C. Li, L. Song, R. Xie, and W. Zhang, “CNN based post-processing to improve HEVC,” in ICIP. IEEE, 2017, pp. 4577–4580.
[63] J. Li, B. Li, J. Xu, R. Xiong, and W. Gao, “Fully connected network-based intra prediction for image coding,” IEEE Transactions on Image Processing, vol. 27, no. 7, pp. 3236–3247, 2018.
[64] M. Li, S. Gu, D. Zhang, and W. Zuo, “Enlarging context with low cost: Efficient arithmetic coding with trimmed convolution,” arXiv preprint arXiv:1801.04662, 2018.
[65] M. Li, W. Zuo, S. Gu, D. Zhao, and D. Zhang, “Learning convolutional networks for content-weighted image compression,” in CVPR, 2018, pp. 673–681.
[66] Y. Li, B. Li, D. Liu, and Z. Chen, “A convolutional neural network-based approach to rate control in HEVC intra coding,” in VCIP. IEEE, 2017, pp. 1–4.
[67] Y. Li, L. Li, Z. Li, J. Yang, N. Xu, D. Liu, and H. Li, “A hybrid neural network for chroma intra prediction,” in ICIP, 2018, pp. 1797–1801.
[68] Y. Li, D. Liu, H. Li, L. Li, Z. Li, and F. Wu, “Learning a convolutional neural network for image compact-resolution,” IEEE Transactions on Image Processing, vol. 28, no. 3, pp. 1092–1107, 2019.
[69] Y. Li, D. Liu, H. Li, L. Li, F. Wu, H. Zhang, and H. Yang, “Convolutional neural network-based block up-sampling for intra frame coding,” IEEE Transactions on Circuits and Systems for Video Technology, vol. 28, no. 9, pp. 2316–2330, 2018.
[70] B. Lim, S. Son, H. Kim, S. Nah, and K. M. Lee, “Enhanced deep residual networks for single image super-resolution,” in CVPR Workshops, 2017, pp. 136–144.
[71] J. Lin, D. Liu, H. Li, and F. Wu, “Generative adversarial network-based frame extrapolation for video coding,” in VCIP, 2018, pp. 1–4.
[72] J. Lin, D. Liu, H. Yang, H. Li, and F. Wu, “Convolutional neural network-based block up-sampling for HEVC,” IEEE Transactions on Circuits and Systems for Video Technology, DOI: 10.1109/TCSVT.2018.2884203, 2018.
[73] D. Liu, H. Ma, Z. Xiong, and F. Wu, “CNN-based DCT-like transform for image compression,” in MMM. Springer, 2018, pp. 61–72.
[74] D. Liu, D. Wang, and H. Li, “Recognizable or not: Towards image semantic quality assessment for compression,” Sensing and Imaging, vol. 18, no. 1, pp. 1–20, 2017.
[75] D. Liu, H. Zhang, and Z. Xiong, “On the classification-distortion-perception tradeoff,” arXiv preprint arXiv:1904.08816, 2019.
[76] J. Liu, S. Xia, W. Yang, M. Li, and D. Liu, “One-for-all: Grouped variation network based fractional interpolation in video coding,” IEEE Transactions on Image Processing, vol. 28, no. 5, pp. 2140–2151, 2019.
[77] K. Liu, D. Liu, H. Li, and F. Wu, “Convolutional neural network-based residue super-resolution for video coding,” in VCIP, 2018, pp. 1–4.
[78] P. Liu, H. Zhang, K. Zhang, L. Lin, and W. Zuo, “Multi-level wavelet-CNN for image restoration,” in CVPR Workshops, 2018, pp. 773–782.
[79] Z. Liu, X. Yu, Y. Gao, S. Chen, X. Ji, and D. Wang, “CU partition mode decision for HEVC hardwired intra encoder using convolution neural network,” IEEE Transactions on Image Processing, vol. 25, no. 11, pp. 5088–5103, 2016.
[80] G. Lu, W. Ouyang, D. Xu, X. Zhang, C. Cai, and Z. Gao, “DVC: An end-to-end deep video compression framework,” in CVPR, 2019.
[81] S. Luo, Y. Yang, Y. Yin, C. Shen, Y. Zhao, and M. Song, “DeepSIC: Deep semantic image compression,” in International Conference on Neural Information Processing. Springer, 2018, pp. 96–106.
[82] C. Ma, D. Liu, X. Peng, and F. Wu, “Convolutional neural network-based arithmetic coding of DC coefficients for HEVC intra coding,” in ICIP, 2018, pp. 1772–1776.
[83] L. Ma, Y. Tian, and T. Huang, “Residual-based video restoration for HEVC intra coding,” in BigMM. IEEE, 2018, pp. 1–7.
[84] S. Ma, X. Zhang, C. Jia, Z. Zhao, S. Wang, and S. Wang, “Image and video compression with neural networks: A review,” IEEE Transactions on Circuits and Systems for Video Technology, DOI: 10.1109/TCSVT.2019.2910119, 2019.
[85] X. Meng, C. Chen, S. Zhu, and B. Zeng, “A new HEVC in-loop filter based on multi-channel long-short-term dependency residual networks,” in DCC. IEEE, 2018, pp. 187–196.
[86] F. Mentzer, E. Agustsson, M. Tschannen, R. Timofte, and L. V. Gool, “Conditional probability models for deep image compression,” in CVPR, 2018, pp. 4394–4402.
[87] ——, “Practical full resolution learned lossless image compression,” arXiv preprint arXiv:1811.12817, 2018.
[88] D. Minnen, J. Ball´e, and G. Toderici, “Joint autoregressive and hierarchical priors for learned image compression,” in NIPS, 2018, pp. 10 794–10 803.
[89] D. Minnen, G. Toderici, M. Covell, T. Chinen, N. Johnston, J. Shor, S. J. Hwang, D. Vincent, and S. Singh, “Spatially adaptive image compression using a tiled deep network,” in ICIP. IEEE, 2017, pp. 2796–2800.
[90] V. Nair and G. E. Hinton, “Rectified linear units improve restricted boltzmann machines,” in ICML, 2010, pp. 807–814.
[91] A. Norkin, G. Bjontegaard, A. Fuldseth, M. Narroschke, M. Ikeda, K. Andersson, M. Zhou, and G. van der Auwera, “HEVC deblocking filter,” IEEE Transactions on Circuits and Systems for Video Technology, vol. 22, no. 12, pp. 1746–1754, 2012.
[92] A. G. Ororbia, A. Mali, J. Wu, S. O’Connell, D. Miller, and C. L. Giles, “Learned neural iterative decoding for lossy image compression systems,” arXiv preprint arXiv:1803.05863, 2018.
[93] W.-S. Park and M. Kim, “CNN-based in-loop filtering for coding efficiency improvement,” in IEEE Image, Video, and Multidimensional Signal Processing Workshop. IEEE, 2016, pp. 1–5.
[94] J. Pfaff, P. Helle, D. Maniry, S. Kaltenstadler, W. Samek, H. Schwarz, D. Marpe, and T. Wiegand, “Neural network based intra prediction for video coding,” in Applications of Digital Image Processing XLI, vol. 10752. International Society for Optics and Photonics, 2018, p. 1075213.
[95] A. Prakash, N. Moran, S. Garber, A. DiLillo, and J. Storer, “Semantic perceptual image compression using deep convolution networks,” in DCC. IEEE, 2017, pp. 250–259.
[96] S. Puri, S. Lasserre, and P. Le Callet, “CNN-based transform index prediction in multiple transforms framework to assist entropy coding,” in EUSIPCO. IEEE, 2017, pp. 798–802.
[97] O. Rippel and L. Bourdev, “Real-time adaptive image compression,” in ICML, 2017, pp. 2922–2930.
[98] O. Rippel, S. Nair, C. Lew, S. Branson, A. G. Anderson, and L. Bourdev, “Learned video compression,” arXiv preprint arXiv:1811.06981, 2018.
[99] T. Salimans, A. Karpathy, X. Chen, and D. P. Kingma, “PixelCNN++: Improving the PixelCNN with discretized logistic mixture likelihood and other modifications,” arXiv preprint arXiv:1701.05517, 2017.
[100] S. Santurkar, D. Budden, and N. Shavit, “Generative compression,” in PCS. IEEE, 2018, pp. 258–262.
[101] I. Schiopu, Y. Liu, and A. Munteanu, “CNN-based prediction for lossless coding of photographic images,” in PCS. IEEE, 2018, pp. 16–20.
[102] C. E. Shannon, “A mathematical theory of communication,” Bell System Technical Journal, vol. 27, no. 3, pp. 379–423, 1948.
[103] A. Skodras, C. Christopoulos, and T. Ebrahimi, “The JPEG 2000 still image compression standard,” IEEE Signal Processing Magazine, vol. 18, no. 5, pp. 36–58, 2001.
[104] J. Snell, K. Ridgeway, R. Liao, B. D. Roads, M. C. Mozer, and R. S. Zemel, “Learning to generate images with perceptual similarity metrics,” in ICIP. IEEE, 2017, pp. 4277–4281.
[105] N. Song, Z. Liu, X. Ji, and D. Wang, “CNN oriented fast PU mode decision for HEVC hardwired intra encoder,” in GlobalSIP. IEEE, 2017, pp. 239–243.
[106] R. Song, D. Liu, H. Li, and F. Wu, “Neural network-based arithmetic coding of intra prediction modes in HEVC,” in VCIP, 2017, pp. 1–4.
[107] X. Song, J. Yao, L. Zhou, L. Wang, X. Wu, D. Xie, and S. Pu, “A practical convolutional neural network as loop filter for intra frame,” in ICIP. IEEE, 2018, pp. 1133–1137.
[108] G. J. Sullivan, J.-R. Ohm, W.-J. Han, and T. Wiegand, “Overview of the high efficiency video coding (HEVC) standard,” IEEE Transactions on Circuits and Systems for Video Technology, vol. 22, no. 12, pp. 1649–1668, 2012.
[109] L. Theis and M. Bethge, “Generative image modeling using spatial LSTMs,” in NIPS, 2015, pp. 1927–1935.
[110] L. Theis, W. Shi, A. Cunningham, and F. Husz´ar, “Lossy image compression with compressive autoencoders,” arXiv preprint arXiv:1703.00395, 2017.
[111] G. Toderici, S. M. O’Malley, S. J. Hwang, D. Vincent, D. Minnen, S. Baluja, M. Covell, and R. Sukthankar, “Variable rate image compression with recurrent neural networks,” arXiv preprint arXiv:1511.06085, 2015.
[112] G. Toderici, D. Vincent, N. Johnston, S. J. Hwang, D. Minnen, J. Shor, and M. Covell, “Full resolution image compression with recurrent neural networks,” in CVPR, 2017, pp. 5306–5314.
[113] R. Torfason, F. Mentzer, E. Agustsson, M. Tschannen, R. Timofte, and L. V. Gool, “Towards image understanding from deep compression without decoding,” arXiv preprint arXiv:1803.06131, 2018.
[114] Y.-H. Tsai, M.-Y. Liu, D. Sun, M.-H. Yang, and J. Kautz, “Learning binary residual representations for domain-specific video streaming,” in AAAI, 2018, pp. 7363–7370.
[115] P. Tudor, “MPEG-2 video compression,” Electronics & Communication Engineering Journal, vol. 7, no. 6, pp. 257–264, 1995.
[116] B. Uria, I. Murray, and H. Larochelle, “RNADE: The real-valued neural autoregressive density-estimator,” in NIPS, 2013, pp. 2175–2183.
[117] ——, “A deep and tractable density estimator,” in ICML, 2014, pp. 467–475.
[118] A. van den Oord, N. Kalchbrenner, and K. Kavukcuoglu, “Pixel recurrent neural networks,” in ICML, 2016, pp. 1747–1756.
[119] A. van den Oord, N. Kalchbrenner, O. Vinyals, L. Espeholt, A. Graves, and K. Kavukcuoglu, “Conditional image generation with PixelCNN decoders,” in NIPS, 2016, pp. 4790–4798.
[120] A. van den Oord and B. Schrauwen, “Factoring variations in natural images with deep Gaussian mixture models,” in NIPS, 2014, pp. 3518–3526.
[121] G. K. Wallace, “The JPEG still picture compression standard,” IEEE Transactions on Consumer Electronics, vol. 38, no. 1, pp. xviii–xxxiv, 1992.
[122] T. Wang, M. Chen, and H. Chao, “A novel deep learning-based method of improving coding efficiency from the decoder-end for HEVC,” in DCC. IEEE, 2017, pp. 410–419.
[123] T. Wang, W. Xiao, M. Chen, and H. Chao, “The multi-scale deep decoder for the standard HEVC bitstreams,” in DCC. IEEE, 2018, pp. 197–206.
[124] Y. Wang, X. Fan, C. Jia, D. Zhao, and W. Gao, “Neural network based inter prediction for HEVC,” in ICME. IEEE, 2018, pp. 1–6.
[125] Z. Wang, D. Liu, S. Chang, Q. Ling, Y. Yang, and T. S. Huang, “D3: Deep dual-domain based fast restoration of JPEG-compressed images,” in CVPR, 2016, pp. 2764–2772.
[126] Z. Wang, A. C. Bovik, H. R. Sheikh, and E. P. Simoncelli, “Image quality assessment: From error visibility to structural similarity,” IEEE Transactions on Image Processing, vol. 13, no. 4, pp. 600–612, 2004.
[127] Y. Watkins, O. Iaroshenko, M. Sayeh, and G. Kenyon, “Image compression: Sparse coding vs. bottleneck autoencoders,” in IEEE Southwest Symposium on Image Analysis and Interpretation. IEEE, 2018, pp. 17–20.
[128] T. Wiegand, G. J. Sullivan, G. Bjontegaard, and A. Luthra, “Overview of the H.264/AVC video coding standard,” IEEE Transactions on Circuits and Systems for Video Technology, vol. 13, no. 7, pp. 560–576, 2003.
[129] I. H. Witten, R. M. Neal, and J. G. Cleary, “Arithmetic coding for data compression,” Communications of the ACM, vol. 30, no. 6, pp. 520–541, 1987.
[130] D. H. Wolpert and W. G. Macready, “No free lunch theorems for optimization,” IEEE Transactions on Evolutionary Computation, vol. 1, no. 1, pp. 67–82, 1997.
[131] C.-Y. Wu, N. Singhal, and P. Kr¨ahenb¨uhl, “Video compression through image interpolation,” in ECCV, 2018, pp. 416–431.
[132] F. Wu, D. Liu et al., “Description of SDR video coding technology proposal by University of Science and Technology of China, Peking University, Harbin Institute of Technology, and Wuhan University,” JVET, Tech. Rep. JVET-J0032, 2018.
[133] J. Xu, M. Xu, Y. Wei, Z. Wang, and Z. Guan, “Fast H.264 to HEVC transcoding: A deep learning method,” IEEE Transactions on Multimedia, DOI: 10.1109/TMM.2018.2885921, 2018.
[134] M. Xu, T. Li, Z. Wang, X. Deng, R. Yang, and Z. Guan, “Reducing complexity of HEVC: A deep learning approach,” IEEE Transactions on Image Processing, vol. 27, no. 10, pp. 5044–5059, 2018.
[135] N. Yan, D. Liu, B. Li, H. Li, T. Xu, and F. Wu, “Convolutional neural network-based invertible half-pixel interpolation filter for video coding,” in ICIP, 2018, pp. 201–205.
[136] N. Yan, D. Liu, H. Li, B. Li, L. Li, and F. Wu, “Convolutional neural network-based fractional-pixel motion compensation,” IEEE Transactions on Circuits and Systems for Video Technology, vol. 29, no. 3, pp. 840–853, 2019.
[137] N. Yan, D. Liu, H. Li, and F. Wu, “A convolutional neural network approach for half-pel interpolation in video coding,” in ISCAS. IEEE, 2017, pp. 1–4.
[138] R. Yang, M. Xu, T. Liu, Z. Wang, and Z. Guan, “Enhancing quality for HEVC compressed videos,” IEEE Transactions on Circuits and Systems for Video Technology, DOI: 10.1109/TCSVT.2018.2867568, 2018.
[139] R. Yang, M. Xu, Z. Wang, and T. Li, “Multi-frame quality enhancement for compressed video,” in CVPR, 2018, pp. 6664–6673.
[140] K. Yu, C. Dong, L. Lin, and C. C. Loy, “Crafting a toolchain for image restoration by deep reinforcement learning,” in CVPR, 2018, pp. 2443–2452.
[141] H. Zhang, L. Song, Z. Luo, and X. Yang, “Learning a convolutional neural network for fractional interpolation in HEVC inter coding,” in VCIP. IEEE, 2017, pp. 1–4.
[142] K. Zhang, W. Zuo, Y. Chen, D. Meng, and L. Zhang, “Beyond a Gaussian denoiser: Residual learning of deep CNN for image denoising,” IEEE Transactions on Image Processing, vol. 26, no. 7, pp. 3142–3155, 2017.
[143] Q. Zhang, D. Liu, and H. Li, “Deep network-based image coding for simultaneous compression and retrieval,” in ICIP. IEEE, 2017, pp. 405–409.
[144] Y. Zhang, L. Sun, C. Yan, X. Ji, and Q. Dai, “Adaptive residual networks for high-quality image restoration,” IEEE Transactions on Image Processing, vol. 27, no. 7, pp. 3150–3163, 2018.
[145] Y. Zhang, T. Shen, X. Ji, Y. Zhang, R. Xiong, and Q. Dai, “Residual highway convolutional neural networks for in-loop filtering in HEVC,” IEEE Transactions on Image Processing, vol. 27, no. 8, pp. 3827–3841, 2018.
[146] Z. Zhang, Z. Chen, J. Lin, and W. Li, “Learned scalable image compression with bidirectional context disentanglement network,” arXiv preprint arXiv:1812.09443, 2018.
[147] L. Zhao, H. Bai, A. Wang, and Y. Zhao, “Learning a virtual codec based on deep convolutional neural network to compress image,” arXiv preprint arXiv:1712.05969, 2017.
[148] Z. Zhao, S. Wang, S. Wang, X. Zhang, S. Ma, and J. Yang, “Enhanced bi-prediction with convolutional neural network for high efficiency video coding,” IEEE Transactions on Circuits and Systems for Video Technology, DOI: 10.1109/TCSVT.2018.2876399, 2018.
[149] L. Zhou, C. Cai, Y. Gao, S. Su, and J. Wu, “Variational autoencoder for low bit-rate image compression,” in CVPR Workshops, 2018, pp. 2617–2620.