利用pytorch分析不同的optimizer
神经网络优化器主要是为了优化我们的神经网络,它可以加速我们训练网络。一个optimizer包含几个常用的参数,比如学习率,权重衰减等。详细的参数详解可以参考torch.optim的中文文档。
四种optimizer :SGD(随机梯度下降),Momentum,RMSprop,Adam.
SGD:每次随机选取数据样本进行学习,每次只随机选择一个样本来更新模型参数,因此每次的学习是非常快速的,并且可以进行在线更新。随机梯度下降最大的缺点在于每次更新可能并不会按照正确的方向进行,因此可以带来优化波动(扰动)。随机梯度下降所带来的波动有个好处就是,对于类似盆地区域(即很多局部极小值点)那么这个波动的特点可能会使得优化的方向从当前的局部极小值点跳到另一个更好的局部极小值点,这样便可能对于非凸函数,最终收敛于一个较好的局部极值点,甚至全局极值点。
Momentum(动量)
利用SGD的时候,有时候会下降的非常慢,并且可能会陷入到局部最小值中。
动量的引入就是为了加快学习过程,特别是对于高曲率、小但一致的梯度,或者噪声比较大的梯度能够很好的加快学习过程。动量的主要思想是积累了之前梯度指数级衰减的移动平均(前面的指数加权平均),下面用一个图来对比下,SGD和动量的区别
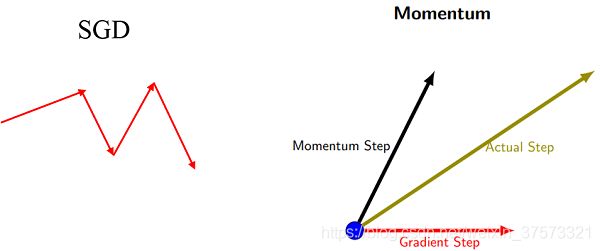
区别: SGD每次都会在当前位置上沿着负梯度方向更新(下降,沿着正梯度则为上升),并不考虑之前的方向梯度大小等等。而动量(moment)通过引入一个新的变量 v vv 去积累之前的梯度(通过指数衰减平均得到),得到加速学习过程的目的。
RMSprop
RMSProp算法的全称叫 Root Mean Square Prop。初步解决了优化中摆动幅度大的问题,所谓的摆动幅度就是在优化中经过更新之后参数的变化范围。
Adam
Adam(Adaptive Moment Estimation)自适应时刻估计方法算法是将Momentum算法和RMSProp算法结合起来使用的一种算法,能计算每个参数的自适应学习率。这个方法不仅存储了AdaDelta先前平方梯度的指数衰减平均值,而且保持了先前梯度M(t)的指数衰减平均值。
1,构建一个数据
import torch
import torch.utils.data as Data
import torch.nn.functional as F
import matplotlib.pyplot as plt
# torch.manual_seed(1) # 为CPU设置种子用于生成随机数,以使得结果是确定的。
#torch.cuda.manual_seed(args.seed)#为当前GPU设置随机种子;如果使用多个GPU,应该使用#torch.cuda.manual_seed_all()为所有的GPU设置种子。
LR = 0.01 #学习率
BATCH_SIZE = 32 #每次放进网络的数据大小
EPOCH = 12 #整个数据集被运行几次
# 构建的数据
x = torch.unsqueeze(torch.linspace(-1, 1, 1000), dim=1)
y = x.pow(2) + 0.1*torch.normal(torch.zeros(*x.size()))
# 显示构建的数据
plt.scatter(x.numpy(), y.numpy())
plt.show()

2.把数据集放入torch的数据集里面
torch_dataset = Data.TensorDataset(x, y)
loader = Data.DataLoader(dataset=torch_dataset, batch_size=BATCH_SIZE, shuffle=True, num_workers=2,) #shuffle=True 把数据打乱, num_worker>1,启动多线程读取数据
3,定义神经网络
class Net(torch.nn.Module):
def __init__(self):
super(Net, self).__init__()
self.hidden = torch.nn.Linear(1, 20) # hidden layer
self.predict = torch.nn.Linear(20, 1) # output layer
def forward(self, x):
x = F.relu(self.hidden(x)) # activation function for hidden layer
x = self.predict(x) # linear output
return x
4.训练和显示四种optimizer
if __name__ == '__main__':
# different nets
net_SGD = Net()
net_Momentum = Net()
net_RMSprop = Net()
net_Adam = Net()
nets = [net_SGD, net_Momentum, net_RMSprop, net_Adam]
# different optimizers
opt_SGD = torch.optim.SGD(net_SGD.parameters(), lr=LR)
opt_Momentum = torch.optim.SGD(net_Momentum.parameters(), lr=LR, momentum=0.8)
opt_RMSprop = torch.optim.RMSprop(net_RMSprop.parameters(), lr=LR, alpha=0.9)
opt_Adam = torch.optim.Adam(net_Adam.parameters(), lr=LR, betas=(0.9, 0.99))
optimizers = [opt_SGD, opt_Momentum, opt_RMSprop, opt_Adam]
loss_func = torch.nn.MSELoss()
losses_his = [[], [], [], []] # record loss
# training
for epoch in range(EPOCH):
print('Epoch: ', epoch)
for step, (b_x, b_y) in enumerate(loader): # for each training step
for net, opt, l_his in zip(nets, optimizers, losses_his):
output = net(b_x) # get output for every net
loss = loss_func(output, b_y) # compute loss for every net
opt.zero_grad() # clear gradients for next train
loss.backward() # backpropagation, compute gradients
opt.step() # apply gradients
l_his.append(loss.data.numpy()) # loss recoder
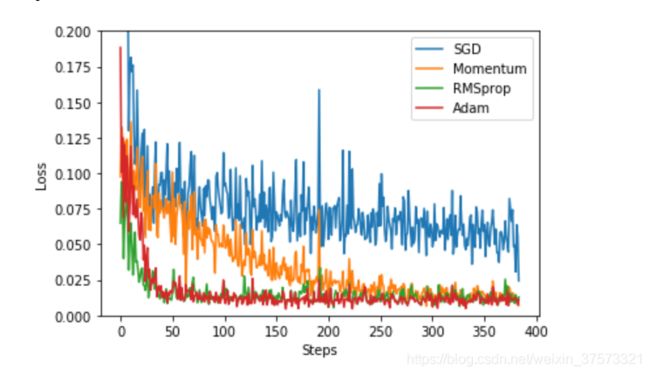
labels = ['SGD', 'Momentum', 'RMSprop', 'Adam']
for i, l_his in enumerate(losses_his):
plt.plot(l_his, label=labels[i])
plt.legend(loc='best')
plt.xlabel('Steps')
plt.ylabel('Loss')
plt.ylim((0, 0.2))
plt.show()
总结
我们应该使用哪种优化器?
在构建神经网络模型时,选择出最佳的优化器,以便快速收敛并正确学习,同时调整内部参数,最大程度地最小化损失函数。
Adam在实际应用中效果良好,超过了其他的自适应技术。
如果输入数据集比较稀疏,SGD、NAG和动量项等方法可能效果不好。因此对于稀疏数据集,应该使用某种自适应学习率的方法,且另一好处为不需要人为调整学习率,使用默认参数就可能获得最优值。
如果想使训练深层网络模型快速收敛或所构建的神经网络较为复杂,则应该使用Adam或其他自适应学习速率的方法,因为这些方法的实际效果更优。