solr 7.X 与spring-data 3.X整合 --(5)搭建SolrCloud
SolrCloud
对于线上的应用,都会存在大规模的高并发访问,为了应用的高效性,稳定性,可靠性都会将高并发的线上环境搭建为集群模式。同样,Solr也分为单机模式和集群模式(SolrCould)。
SolrCloud提供了分布式索引和搜索的能力,并且支持以下功能:
- 集中管理整个集群的配置
- 查询的自动负载均衡和故障转移
- 集成zookeeper用于集群的协调和配置
SolrCloud是非常灵活的分布式查询和索引,它没有主节点来分别节点,分区和副本。相对的,Solr通过集成zookeeper根据配置文件和Schema来管理这些。查询和更新请求会被发送至每个服务器,然后通过zookeeper来确定哪些服务器将处理这些请求。
SolrCloud工作原理
SolrCloud的关键概念
SolrCloud包含了逻辑概念和物理概念。
逻辑概念
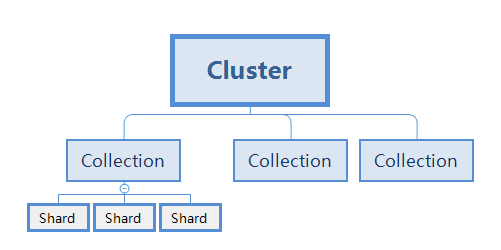
- 一个集群(Cluster)可以包含多个文档集合(Collection)
- 一个文档集合(Collection)可以被分为多个分区(Shard),每个分区只包含部分文档集合的内容
- 集合的分区数量决定了:
- 一个查询请求所能进行并发处理的数量
- 理论上限制了一个集合中所包含的文档数量
物理概念
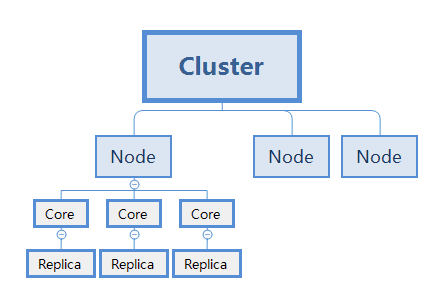
- 一个集群(Cluster)可以包含多个Solr节点(Node),每一个节点都是一个运行的Solr服务的进程实例。
- 每一个节点可以包含多个Core
- 每一个Core都是逻辑分区(Shard)的物理副本(Replica)
- 每一个副本(Replica)都使用集合(Collection)指定相同的配置
- 每个分区(Shard)的副本(Replica)数量决定了:
- 集合中的内置冗余级别,以及集群的容错能力
- 搜索的并发请求数
SolrCloud中的分区和索引数据
如果你的一个节点中存在大量数据,你可以考虑将其拆分成多个分区来存储。
分区是集合的一个逻辑组成,包含了集合中文档的子集,这样集合中的文档都会包含在其中一个分区中。集合中的文档包含在哪个分区中取决于该集合的分区策略。
例如,一个集合中包含“国家”这个字段,那么可以根据“国家”来进行切分。因此同一个国家的文档都存在与同一个分区中。也可以通过文档主键的哈希值,来进行分区。
在SolrCloud之前,Solr是支持分布式搜索,它允许在多个切分中执行痛一个查询,查询是针对整个Solr索引执行的,因此不会从搜索结果中丢失任何文档。所以将一个索引分割成碎片并不完全是一个SolrCloud的概念。SolrCloud的引入改进了分布式的几个问题:
- 将索引分区的动作含有手动处理
- 没有对分布式索引的支持,这意味着需要显示的将文档发送到特定的分区中;Solr自己不知道将文档发送到哪个分区。
- 没有负载均衡和故障转移,所以如果有大量的查询,需要知道在哪里执行它们,如果一个分区挂了,索引也就没了。
SolrCloud解决了这些限制,它支持自动的分发索引和执行查询,同时zookeeper提供了故障转移和负载均衡的能力。另外,每个分区都可以拥有多个副本,因此获得了额外的健壮性。
领导者(Leader)和副本(Replica)
SolrCloud中没有主人和奴隶,每个分去都至少包含一个物理副本,其中一个是领导者。领导者会自动当选,最初是根据先到先得的原则,后面是基于zookeeper来进行选举。
如果一个领导者挂掉,那么另一个副本会自动被选为领导人。
当一个文档被发送到Solr节点(Node)进行索引时,系统首先确定该文档所属的分区,然后哪个节点托管了该分区的领导者。最后将该文档被转发给当前领导者进行索引,并且领导者将更新转发到其他所有副本。
副本类型
默认情况下,如果一个领导者挂了,那么它的所有副本都有资格成为领导者。然而,这是有代价的,如果所有的副本在任何时候都能成为领导者,那么每一个副本都必然要和领导者保持同步。添加到领导者的新文档必须也同时被添加到副本中。如果一个副本被关闭了,或者暂时不可用,后面重新加入到集群中,它前面错过了大量的更新,势必会导致其恢复很缓慢。
当然,对于大多数用户来说,这些问题并不是问题。如果这些副本和领导者同步,那么用例则会表现的更好。如果不是实时同步,那么它根本没有资格成为领导者。
Solr可以在创建集合或添加副本时通过设置副本类型来实现这一点。可用的类型有:
- NRT:默认类型。NRT(NearRealTime)副本维护一个事务日志,并在它本地的索引中写入新的文档。任何这种类型的副本都有资格成为领导者。传统意义上,它也是Solr支持的唯一类型。
- TLOG:这种副本类型也维护一个事务日志,但是没有在本地索引中更改文档。这种类型有助于加速索引,因为在副本中不需要做任何commit。当这种类型的副本需要更新索引时,它通过从领导者复制索引来实现。这种类型的副本,也有资格成为领导者。如果它成为了领导者将首先处理事务日志。它的行为和NRT类型的部分一样。
- PULL:这种类型的副本不维护事务日志,也不维护本地索引的更新。它只从领导者中复制索引。它没有资格成为一个领导者,也不参与领导者的选举。
集群中组合副本类型
有三种副本类型的组合被推荐:
- 全是NRT类型副本
- 全是TLOG类型副本
- TLOG类型和PULL类型副本
全是NRT类型
用于小型及中型集群,甚至是大型集群,其中更新(创建索引)吞吐量不太高。NRT是唯一支持软提交(soft-commits)的副本,所以在需要近实时的时候使用这个组合。
全是TLOG类型
不需要近实时,每个分区的副本数量非常多,但是你仍然希望所有副本都能够处理更新请求,那么使用这种组合。
TLOG类型和PULL类型副本
不需要近实时,每个分区的副本数量非常多,并且你希望在文档更新中增加查询的可用性,即使这意味着暂时服务过时的结果,则使用这种组合。
其他副本类型组合
不推荐其他副本类型的组合。如果分区中有多个副本正在编写自己的索引,而不是从NRT副本中复制,那么领导者的选举就会导致分区的所有副本与领导者不同步,所有的副本都必须复制完整的索引。
搭建zookeeper环境
服务器配置
| hostname | ip | server |
|---|---|---|
| app1 | 192.168.3.160 | centos 6.5 |
| app2 | 192.168.3.161 | centos 6.5 |
| app3 | 192.168.3.162 | centos 6.5 |
软件版本
zookeeper: 3.4.10
下载安装
下载zookeeper至/usr/downloads/
wget -P /usr/downloads/ http://archive.apache.org/dist/zookeeper/zookeeper-3.4.10/zookeeper-3.4.10.tar.gz将下载后的文件解压至/opt/
[root@app1 ~]# tar -zxf /usr/downloads/zookeeper-3.4.5.tar.gz -C /opt/
[root@app1 opt]# mv zookeeper-3.4.10 zookeeper配置
/opt/zookeeper/文件夹下新建data和logs文件夹
[root@app1 zookeeper]# mkdir data
[root@app1 zookeeper]# mkdir logs
复制/opt/zookeeper/conf/下的zoo_sample.cfg文件为zoo.cfg
[root@app1 conf]# cp zoo_sample.cfg zoo.cfg修改/opt/zookeeper/conf/zoo.cfg
[root@app1 conf]# vi zoo.cfg 修改或加入以下内容至zoo.cfg文件
dataDir=/opt/zookeeper/data
dataLogDir=/opt/zookeeper/logs
server.1=app1:2888:3888
server.2=app2:2888:3888
server.3=app3:2888:3888在/opt/zookeeper/data 文件夹下添加myid文件,并写入1
echo '1' > data/myid
复制部署zookeeper
复制zookeeper至app2
[root@app1 ~]# scp -r /opt/zookeeper/ root@app2:/opt/
在app2上修改/opt/zookeeper/data/myid文件内容为2
[root@app2 ~]# echo '2' > /opt/zookeeper/data/myid 复制zookeeper至app3
[root@app1 ~]# scp -r /opt/zookeeper/ root@app3:/opt/
在app2上修改/opt/zookeeper/data/myid文件内容为2
[root@app3 ~]# echo '3' > /opt/zookeeper/data/myid
启动zookeeper
分别在三台服务器执行
[root@app1 ~]# /opt/zookeeper/bin/zkServer.sh start查看状态
[root@app1 ~]# /opt/zookeeper/bin/zkServer.sh status发现启动状态异常
ZooKeeper JMX enabled by default
Using config: /opt/zookeeper/bin/../conf/zoo.cfg
Error contacting service. It is probably not running.
停止服务
[root@app1 ~]# /opt/zookeeper/bin/zkServer.sh stop重新启动,并打印日志
[root@app1 ~]# /opt/zookeeper/bin/zkServer.sh start-forground查看日志后发现报java.net.NoRouteToHostException:No route to host异常,于是检查hosts配置,及防火墙。关闭防火墙后,再次尝试启动后成功运行。
[root@app1 ~]# service iptables stop
搭建SolrCloud环境
安装JDK1.8
Solr 7.x 要求JDK的最低版本必须是JDK 1.8,所以必须在服务器上安装好JDK 1.8。
软件版本
Solr: 7.4.0
下载安装
下载zookeeper至/usr/downloads/
[root@app1 ~]# wget -P /usr/downloads/ http://mirrors.hust.edu.cn/apache/lucene/solr/7.4.0/solr-7.4.0-src.tgz解压至/opt
[root@app1 opt]# tar -zxf /usr/downloads/solr-7.4.0.tgz -C /opt/
[root@app1 opt]# mv solr-7.4.0/ solr尝试启动
[root@app1 ~]# /opt/solr/bin/solr start
笔者虚拟机报出警告
*** [WARN] *** Your open file limit is currently 1024.
It should be set to 65000 to avoid operational disruption.
If you no longer wish to see this warning, set SOLR_ULIMIT_CHECKS to false in your profile or solr.in.sh
*** [WARN] *** Your Max Processes Limit is currently 7685.
It should be set to 65000 to avoid operational disruption.
If you no longer wish to see this warning, set SOLR_ULIMIT_CHECKS to false in your profile or solr.in.sh
WARNING: Starting Solr as the root user is a security risk and not considered best practice. Exiting.
Please consult the Reference Guide. To override this check, start with argument '-force'
/etc/security/limits.conf 文件末尾加上
* soft nofile 65535
* hard nofile 65535
* soft nproc 65535
* hard nproc 65535修改/etc/security/limits.d/90-nproc.conf 内容为
* soft nproc 65535
* hard nproc 65535重启虚拟机,后再次尝试启动Solr,成功。
部署app2, app3
复制/opt/solr 至app2, app3虚拟机,重复以上操作进行部署
[root@app1 ~]# scp -r /opt/solr/ root@app2:/opt/
[root@app1 ~]# scp -r /opt/solr/ root@app3:/opt/搭建SolrCloud环境
修改/opt/solr/server/solr/solr.xml
对三台服务器分别进行修改为对应的值
<str name="host">${host:192.168.3.160}str>修改/opt/solr/bin/solr.in.sh
同样对三台服务器进行修改,去掉ZK_HOST,SOLR_HOST,SOLR_TIMEZONE前面的注释,并给出对应的值
ZK_HOST="app1:2181,app2:2181,app3:2181"
SOLR_HOST="192.168.3.160"
SOLR_TIMEZONE="UTC+8"集群方式启动
前面为了测试Solr是否部署成功,已经用单机进行了启动,首先将Solr停掉。
[root@app1 solr]# /opt/solr/bin/solr stop集群启动
[root@app1 solr]# /opt/solr/bin/solr start -c -z app1:2181,app2:2181,app3:2181 -force执行后查看Solr状态,报出以下异常信息
java.lang.Thread.run(Thread.java:748) [?:1.8.0_171]
Caused by: javax.servlet.UnavailableException: Error processing the request. CoreContainer is either not initialized or shutting down.查看日志,发现原因是zookeeper没有启动,重新启动后,再次执行集群启动命令后成功。
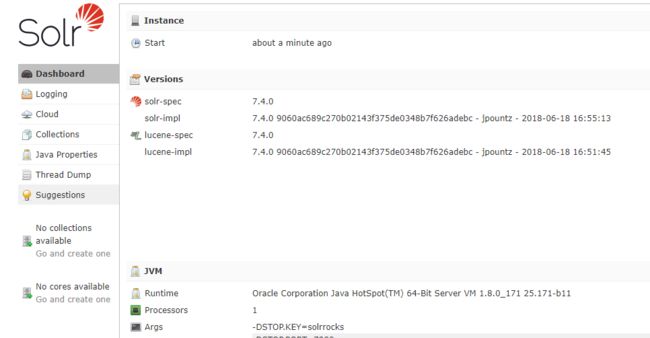
比较前面的界面,可以发现集群启动模式,页面上多了一个cloud菜单。
将剩下的两台服务器app2,app3也进行集群启动操作。
上传配置文件
配置文件通过zookeeper进行管理,由它来进行同步分发,不用对每一个SolrNode就行单独的配置。
先从app1服务器上的/opt/solr/server/solr/configsets/_default/复制一份配置文件
[root@app1 ~]# cp -r /opt/solr/server/solr/configsets/_default/ /opt/solr/server/solr/configsets/alistair_configs
将修改好的配置文件上传至zookeeper
[root@app1 ~]# /opt/solr/bin/solr zk upconfig -d /opt/solr/server/solr/configsets/alistair_configs/ -n alistair_configs -z app1:2181,app2:2181,app3:2181
命令格式为
[root@app1 ~]# /opt/solr/bin/solr zk upconfig -d [要上传的配置文件目录] -n [zookeeper上保存的配置文件名称] -z [zookeeper的集群地址]在zookeeper中查看是否上传成功
通过zkCli.sh 连上任一节点
[root@app1 ~]# /opt/zookeeper/bin/zkCli.sh -server app3:2181连上后执行ls命令,可以看到alistair_configs已被上传至configs目录,且已经被分发至所有节点。
[zk: app3:2181(CONNECTED) 0] ls /
[configs, zookeeper, overseer, aliases.json, live_nodes, collections, overseer_elect, security.json, clusterstate.json, autoscaling, autoscaling.json]
[zk: app3:2181(CONNECTED) 1] ls /configs
[_default, alistair_configs]
[zk: app3:2181(CONNECTED) 2] [root@app1 ~]#
创建集合Collection
创建一个名为alistair_core,配置文件为前面上传的alistair_configs,3个分区,每个分区2个副本的集合。
[root@app1 ~]# /opt/solr/bin/solr create_collection -c alistair_core -n alistair_configs -shards 3 -replicationFactor 2 -force命令格式为
[root@app1 ~]# /opt/solr/bin/solr create-collection -c [新建集合的名字] -n [zookeeper上配置文件的名称] -shards 2 [分区数量] -replicationFactor 2 [副本数量]再次查看Solr界面

配置成功