Sparse Merkle Tree解析
本文转载自知乎专栏:https://zhuanlan.zhihu.com/p/79949990
已获得作者授权。
在libra中关于Sparse Merkle Tree有两种结构,一种在scratchpad中用于交易执行时构造的快照信息,另外是用于用户提供给AC等模块查询账户信息的。这里主要分析后者,由于SMT内容较多,这一篇主要是SMT作用、结构、insert操作的源码分析,关于SMT如何做proof会在下一篇进行源码分析。
SMT(Sparse Merkle Tree)的作用
libra提供了账户体系,并且他宣称是一个带版本的数据库,那么在实现libra的时候,就需要回答如下几个问题1. 如何存储账户。2. 如何根据账户地址查询。3. 如何查询到某个版本下用户的信息(余额等)。4. 如何证明信息是可信的。如果单单满足1、2、3条件,设计一个带版本号的KV存储就能够满足,但是如何满足4并且让整个存储结构不至于太冗余就是一个非常难的问题。对于proof我们也有一定的要求,客户端能否快速的验证请求到的数据,能否在没有存储全量数据下进行验证。
根据libra白皮书中提到的SMT结构,整个账户在逻辑上是通过树的形式进行存储。叶子结点存放指向Account Blob。Account Blob存储了该账户的resource和module信息。这棵树承担了两个功能,索引和proof。通过账户地址从树的root进行查询,查到对应的leaf node。同时SMT带有merkle proof功能,因此兼顾了proof。
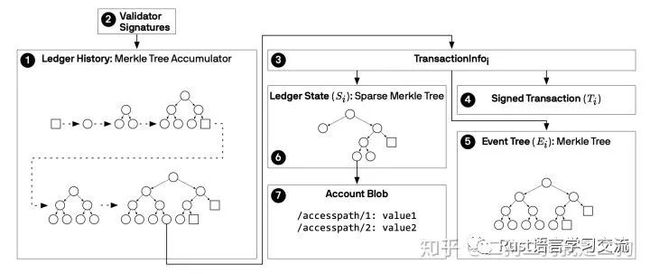
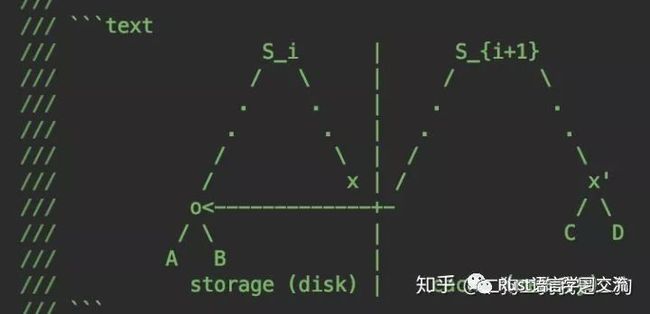
另外,为了实现根据version进行查询,libra并不是显示的在存储时带上version,而是在不同version下构建不同的SMT,新构建的SMT的只会新建修改或新增的账户,对于没有变动的账户,只是指向过去而已。如下图所示,在i+1下,对节点x下的账户C、D有变更,但是对o节点下的账户是没有变更的,因此在构建SMT的时候,新建了x’节点,对于o节点只是做了引用。那么,我们在查询某个版本号对应的账户时,只要找到该版本号对应的SMT的root,再通过root进行检索即可。
SMT结构
SMT一共有三种节点,Branch、Extension、Leaf,这三中节点类型的功能与ethereum的MPT基本是一致的。
Branch节点作为分支节点,一共有16个槽位,每个槽位指向下一个节点。Children中的key表示分支index,value是(HashValue ,bool)元组,HashValue表示指向的节点hash,bool如果为true表示该子节点是leaf节点。
pub struct BranchNode {
// key: child index from 0 to 15, inclusive.
// value: Child node hash and a boolean whose true value indicates the child is a leaf node.
children: Children,
}
pub(crate) type Children = HashMap<u8, (HashValue, bool)>;Extension节点是扩展节点,用来存储公共前缀,比如说两个地址是0xffa0,0xffb0,那么0xff就是这两个地址的公共前缀,通过将0xff作为Extension节点,就可以达到压缩的目的。定义如下,nibble_path用来存储功能前缀,也就是0xff,child用来指向下一个节点。在我们这个例子中,child节点是一个Branch类型,用来指向0xa0和0xb0。由于MPT中存储nibble时用的是hex prefix编码,需要区分nibble长度的奇偶性和子节点类型,所以会额外有个一个字节的前缀,在SMT中没有做这方面的编码,所以nibble就是直接存储公共前缀即可。
pub struct ExtensionNode {
// The nibble path this extension node encapsulates.
nibble_path: NibblePath,
// Represents the next node down the path.
child: HashValue,
}
pub struct NibblePath {
/// The underlying bytes that stores the path, 2 nibbles per byte. If the number of nibbles is
/// odd, the second half of the last byte must be 0.
bytes: Vec<u8>,
/// Indicates the total number of nibbles in bytes. Either `bytes.len() * 2 - 1` or
/// `bytes.len() * 2`.
num_nibbles: usize,
}Leaf节点就是SMT的叶子节点,value表示指向账户blob数据的key。
pub struct LeafNode {
// the full key of this node
key: HashValue,
// the hash of the data blob identified by the key
value_hash: HashValue,
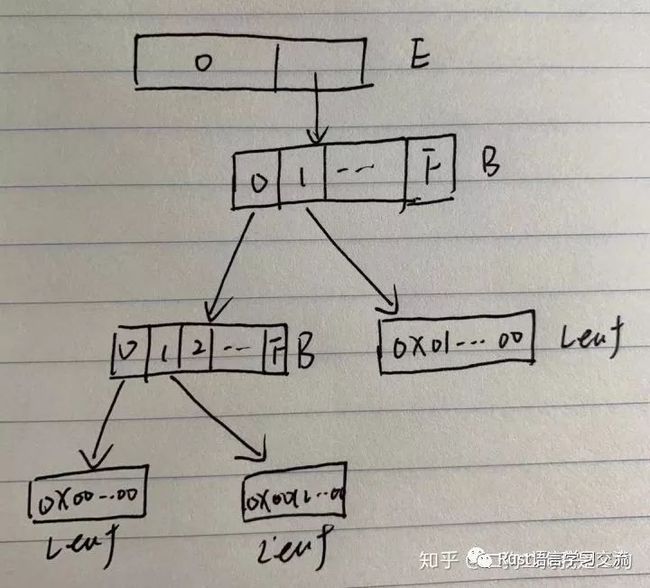
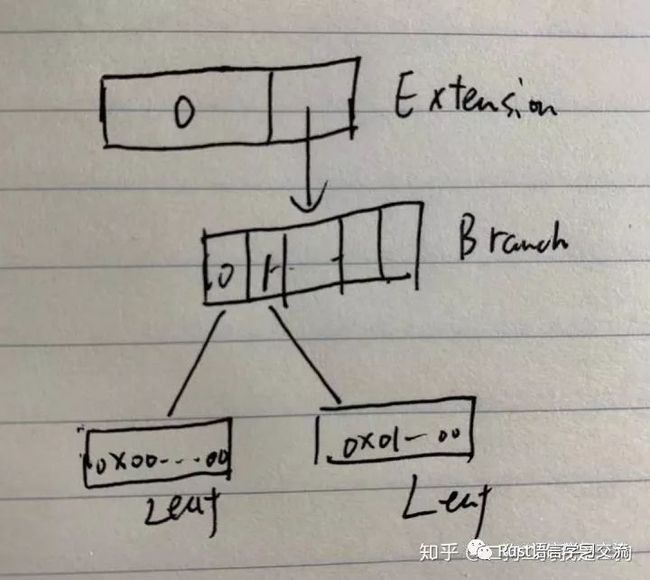
}整体的形式如下图所示,E表示extension节点,B表示Branch节点。下图中E的0表示三个地址0x00..00,0x01..00,0x0012..00的公共前缀,B的0,1表示分支,分别指向开头是0和1的地址。
SMT实现的源码分析
这里主要介绍如何插入(更新)SMT中的节点,以及如何根据用户地址进行带有proof的查询。
insert
关于插入代码的入口在storage/sparse_merkle/src/lib.rs中,blob_set表示带插入的用户地址和blob信息。version表示插入时的版本号,root_hash表示插入的SMT的根节点。
pub fn put_blob_set(
&self,
blob_set: Vec<(HashValue, AccountStateBlob)>,
version: Version,
root_hash: HashValue,
) -> Result<(HashValue, TreeUpdateBatch)> {
let (mut root_hashes, tree_update_batch) =
self.put_blob_sets(vec![blob_set], version, root_hash)?;
let root_hash = root_hashes.pop().expect("root hash must exist");
assert!(
root_hashes.is_empty(),
"root_hashes can only have 1 root_hash inside"
);
Ok((root_hash, tree_update_batch))
}这里我们按照这个put_blob_set->put_blob_sets->put函数跳进的方式,直接看put函数。在这个函数首先会将用户地址转为nibble path,接着从tree cache中获取root信息,并将需要存储的blob信息已kv的形式存储到cache中,这里的k就是blob的hash,也就是插入到SMT中叶子结点的value。接下来通过insert_at函数想SMT中插入一个节点,并返回插入后的SMT的root信息,并更新原有的root。

所以关于插入的工作主要是在insert_at函数中完成的,我们知道SMT有三种类型的节点,因此我们在插入的时候根据root节点的类型,插入的策略也是不一样的。接下来分别进行讨论。
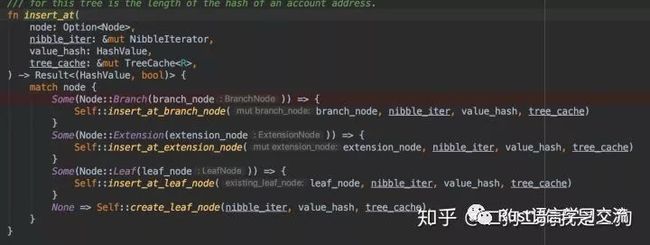
create_leaf_node
如果对于一棵空树来说,那么root节点将不是上述三种,因此执行的分支是create_leaf_node。假设我们第一次插入的地址是0x00...000(一共32个0),此时nibble_path就是32个0,由于此时树是空的,而且也只有一共地址,因此不存在公共前缀和Branch,因此这里只需要根据nibble path和blob信息构建一个叶子节点,并将该叶子节点信息存入到tree cache即可。

此时这棵SMT的结构如下图所示
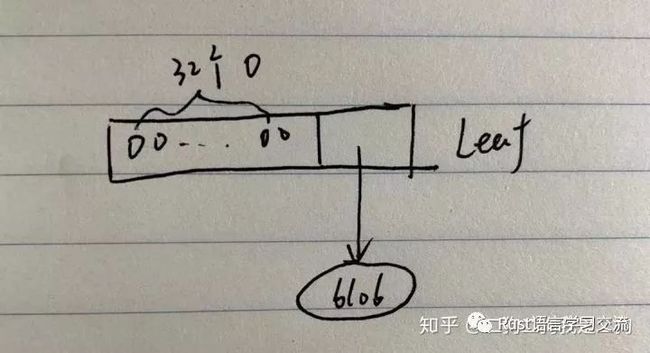
insert_at_leaf_node
在上一步的基础上,我们继续插入blob,假设此时插入的地址是0x01...00,由于上一步插入后此时的root是leaf node类型,因此此时调用的是insert_at_leaf_node函数。
由于代码较长,这里截取成几部分来分析。
这部分代码首先判断了待插入节点的visited nibble与现有的了leaf节点的nibble是否拥有共同前缀,之所以要判断是因为走到这一步了,说明待插入节点和当前的leaf是有共同前缀的,否则应该是在另外的分支,当然除了SMT只有一个账户的情况外。
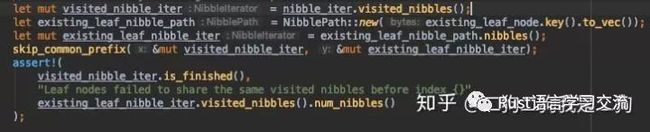
这里简单介绍下NibbleIterator.下面是他的结构体。
pub struct NibbleIterator<'a> {
/// The underlying nibble path that stores the nibbles
nibble_path: &'a NibblePath,
/// The current index, `pos.start`, will bump by 1 after calling `next()` until `pos.start ==
/// pos.end`.
pos: std::ops::Range<usize>,
/// The start index of the iterator. At the beginning, `pos.start == start`. [start, pos.end)
/// defines the range of `nibble_path` this iterator iterates over. `nibble_path` refers to
/// the entire underlying buffer but the range may only be partial.
start: usize,
}nibble path在我们这其实就是地址,比如0x01..00。由于我们在插入节点的时候,会根据地址不断检索,比如0x01..00地址在经过一个Extension为0x0后,他接下来检索的就是0x1..00,这里为了保留上述信息引入了start和pos,如下图所示,start~pos.start表示为已经检索过的nibbles,pos.start~pos.end表示还未检索的内容。
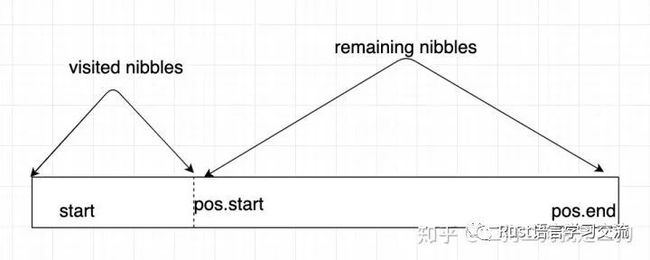
在第一部分代码中,我们先获取待插入node的visited nibbles,在我们场景中该地址是直接插入到leaf node即没有经过检索,因此他的iterator的start和pos.start都是0。接着,调用skip_common_prefix函数,来判断待插入的visited与leaf node的nibble是否有公共前缀。判断的逻辑很简单,依次比较每个nibble是否一样。不过感觉这边用xor操作是不是会更好些,省去了loop。
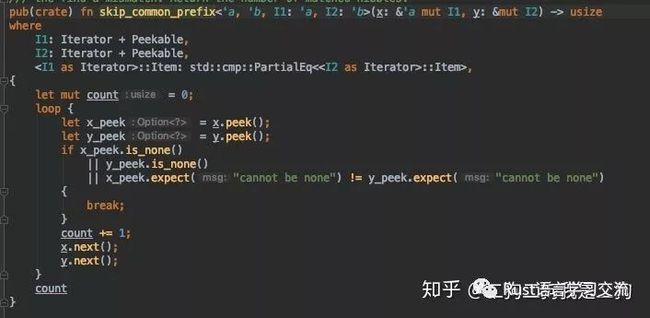
接下来是一个assert宏,如果正常的情况下visited nibble将是existing leaf node nibble的子集,所以应该是is_finished,如果不是子集的话,这个待插入的地址不应该走到leaf这个节点上。
在验证完公共前缀后,接下来就需要判断待插入和leaf的remainning nibble是否有公共前缀了(skip_common_prefix传入的不应该是nibble_iter的remaining nibble吗,有点疑问)。在经过common prefix后,待插入地址和leaf对于remaining nibble的状态应该是一致的,要么都没有remaining nibble,要么都有。

接下来,就需要根据还有无remaining nibble分类讨论
如果nibble_iter.is_finished,那么说明叶子结点也finish了,即待插入的地址就是leaf的地址,所以要做的就是原地更新。
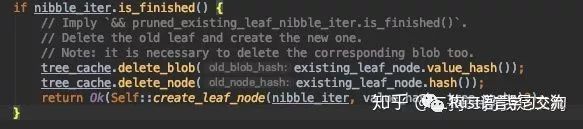
下面就是处理两者不相同的情况,先获取common prefix,也就是pruned_existing_leaf_nibble_iter.visited_nibbles()。接下来部分就是两者不一样的地方,就很简单了,新建个Branch类型节点,然后获取下一个nibble作为branch的index。这里的existing_leaf_index和new_leaf_index就是branch指向这两个leaf的index,并将child指向对应的leaf,最后计算出branch node的hash,插入到tree cache中。

最后,返回到上一步提到的common prefix,如果这个不为空,说明带插入地址和leaf是有公共前缀的,因此需要新建一个Extension节点。具体的做法就是,利用common prefix作为Extension的nibble path,child指向就是上一步构造的那个branch节点的hash,最后同样的,将信息写入cache中。

在插入0x01...00地址后的SMT结构如下,画的比较粗糙。
insert_at_extension_node
在插入完0x01..00地址后,从上图就可以知道,此时root指向的是Extension类型的节点,假设此时我们需要向其插入的地址是0x0012..00。我们还是继续将代码分成几部分来分析。
首先,这里现将这个Extension节点从cache中删除,原因很简单,在向一个Extension类型节点插入的时候,大概率会修改path,所以这里先删了。下一步,我们就需要判断新插入的节点与这个Extension节点是否存在common prefix,如果这个Extension的nibble path是其子集的话,那么待插入节点就可以复用这个Extension了。代码中,extension_nibble_iter是表示这个extension节点的path,这个是需要注意的,接着计算extension与待插入的nibble的common prefix。如果extension_nibble_iter.is_finished,就表示extension的path是待插入的子集,例如extension的path是0x0123,而待插入的地址是0x0001234567..000,假设此时待插入的remaining nibble是0x01234567..00,那么在计算common prefix的时候extension_nibble_iter是完全匹配了,也就是说extension的path是其子集,因此这个extension是可以被复用的。再往下一步,就是找到该extension的child节点(从代码上可以看出,extension的子节点只能是branch类型的节点),接着将待插入地址插入到branch节点中,此时待插入节点的remaining nibble就是0x67...00了,至于insert_at_branch_node函数是如何插入到branch的,会在下面分析。

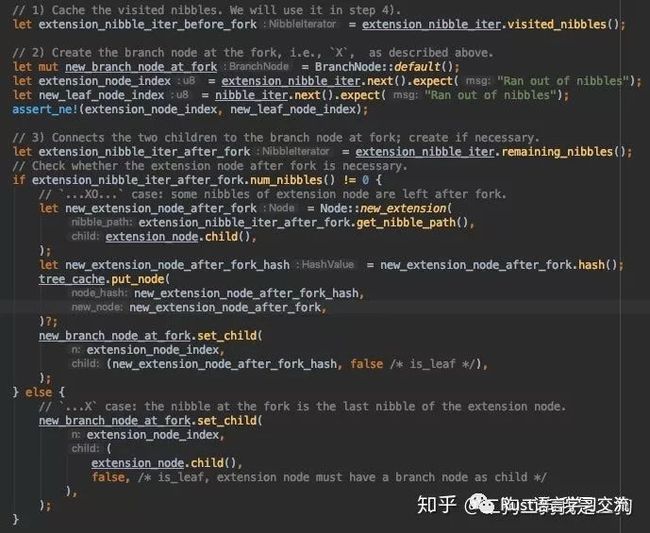
接下来就是处理extension path和待插入nibble中部分重叠的情况了。首先,这种情况肯定是需要一个branch类型的节点来分支原有的extension和待插入的。
假设extension的path是0x1234,待插入的是0x1245,那么经过上一步的common prefix处理后,extension_nibble_iter_before_fork就是0x12,extension_node_index便是remaining nibble(0x34)的第一个也就是3,而new_leaf_node_index则是4。有个地方需要注意,extension_nibble_iter_after_fork是经过next后的,如果不注意这个点,容易误认为当extension_nibble_iter_after_fork.mun_nibbles为0这个条件和上一部分的extension_nibble_iter.is_finished()条件是重叠的。经过next后,extension_nibble_iter_after_fork就是4了。这里之所以要区分extension_nibble_iter_after_fork是否为空,是因为如果不为空,那么extension_nibble_iter_after_fork的path还可以作为他的子节点common prefix。我们继续按照当前这个假设走,此时extension_nibble_iter_after_fork是不为空的,因此他的path可以作为child的common prefix,因此这里又新建了一个extension节点,他的path就extension_nibble_iter_after_fork的path,而child还是这个extension的child。接下来就是将这个新构建的extension节点加入到branch中,并且index是3.
假设,extension的path是0x1234,待插入的是0x1235呢,此时extension_nibble_iter_before_fork是0x123,extension_node_index是4,new_leaf_node_index是5,并且extension_nibble_iter_after_fork为空,这个与上面假设的区别就是,上面的extension_nibble_iter_after_fork不为空,可以通过他来构造一个extension,其child指向原extension的child。但是,一旦为空了,那么原来的extension的path就已经被common prefix和branch的index给替换了,因此原来extension指向的child也就成为没有父亲节点了,因此,我们可以看到在下面代码的else分支中,就是将原来的child的父亲节点指向到新构建的branch中,并且其index就是4.
在处理完extension后,下面就比较简单了,在上一部分已经创了一个branch了,并且对原有的extension的重新构建,并加入到branch中,接下来就是处理待插入的。因为待插入的是作为branch的child,因此这里会新建一个leaf,并将这个leaf作为branch的child。到这一步,已经构建了两层node了,就是branch和原有的extension、待插入的,还剩上一步的common prefix(extension_nibble_iter_before_fork),如果说common prefix不为空,那么我们需要构建一个extension,其child就是branch。最后将这些节点写入cache,就完成了整个过程。

在插入0x0012...00地址后的示意图
insert_at_branch_node
这里分析下insert_at_branch_node的代码,整体来说比较简单,原因在于branch承担的功能是一个分支,不要合并或者分裂,因此这一步的逻辑相对来说比较简洁。
第一步还是老样子,先把branch删了,可能他们不太在意这两次IO吧。先获取next nibble,这个就是branch的index,获取到了child后,也就是获取了具体node的hash,我们利用hash通过tree可以获取到具体的node信息(上面各个insert中,都会将nodehash,node这个kv存储到tree中),接下来就是判断node类型,按照不同类型来处理对应的insert,整个就是一个迭代的过程。完成insert后,将新构建的node插入到branch的槽位中,并更新branch的hash,将kv写入到tree中。

总结
总的来说,SMT逻辑上是一棵树,实际存储是将node的kv信息存储到DB中。看完这个,基本上可以回答上面的1,2,3这三个问题,对于4,我们会在下一篇进行源码分析。