C++抽象编程——字符串(4)——回文数的检查与Pig Latin游戏
既然我们介绍了那么多的字符串工具,那么我们将它用于编写字符串程序,又会有什么强大之处呢?接下来的两个例子,我们慢慢体会。
Recognizing palindromes
回文数,就是既可以从前面读起,也可以从后面读起来的单词,比如 level,noon。这次,我们的任务就是编写一个程序,用于判断用户输入的是不是回文数,我们用isPalindrome函数来判断,如果isPalindrome("level"),函数返回true,isPalindrome("hello"),返回false。
和大多数编程问题一样,有几个合理的策略解决这个问题(可以参考我递归简介中的文章)。可能的方法尝试首先使用for循环遍历每个位置的上半部分串。然后检查这个字符是
否出现在后半部分的对称位置,有的人第一反应就是,利用两个for循环,然后第一个遍历前半部分,第二个遍历后半部分。嗯,这应该是大多数人的想法,包括我。但是我不得
不佩服那些计算机科学家,他们认为只需要一次的循环为什么要两次呢,所以我们可以看看以下的代码:
bool isPalindrome(string str) {
int n = str.length();
for (int i = 0; i < n / 2; i++) {
if (str[i] != str[n - i - 1]) return false;
}
return true;
}因为每一次的循环,i都在自增1,所以,i越大,n减去i就越小。这个时候str[n-i-1],代表的就是从后面到n/2。为什么还要减去1呢?这是因为字符串是从0开始计算的,末尾的元素
的位置为n-1。其实我们还有一种很好的方法,
就是通过我们前面介绍过的reverse函数,既然一个回文数可以从前面也可以从后面读起来,那么它翻转过后的字符串也肯定与未翻转的字符串一致,因此我们可以写出下面函数
bool isPalindrome(string str) {
return str == reverse(str);
}好了,既然有了两个函数,那就有了比较,那么哪个函数更加高效呢?答案是显而易见的,方法1只遍历了一半的字符就能把结果输出。反观方法2,不但要遍历两次的字符串
还要对字符串进行重组。而在重组的过程中,我们又不知道会不会出现不可预知的错误。那么我们在编程中就抛弃2了吗?错,恰恰相反,我们更加乐意选择方法2,因为在宏观上,它更加体现了函数的复用,而且隐藏了更多的复杂性,我们不用去考虑为什么是str[n-i-1],也不用考虑我们为什么用的是<=,而不是< ,在理解的角度上更符合我们的理解能力。在大型软件中函数复用避免了去写更多的函数,使得程序更加稳定,更加易于修改。通常我们通过牺牲一些性能去换取程序的稳定性和可维护性是值得的。
Translating English to Pig Latin
为了给你更多的感觉如何实现字符串处理应用程序,本节介绍一个从用户那里读取一行文本的C ++程序将该行中的每个单词从英语翻译成Pig Latin,一种化妆语言。 在
拉丁语中,单词是由他们的英国同行通过应用以下规则形成::
1. If the wordcontains no vowels, no translation is done, which means thatthe translated word is the same as the original.
2. If the word begins with a vowel, the function adds the string"way" to the end of the original word.
3. If the word begins with a consonant, the function extracts the stringof consonants up to the first vowel, moves that collection of consonantsto the end
of the word, and adds the string "ay".
翻译一下就是:
1.当单词中不含有元音时候,我们就不用进行转换。
2.如果一个单词以元音开头,那么我们在这个单词后面加way结尾。
3.如果单词以辅音开头,那么我们就遍历这个单词,直到遇到第一个元音,这时把元音之前的字符放到单词的尾部,最后加上ay结尾。
举个例子,如果我们输入一个单词为 scream,那么我们可以观察出来它是由辅音开头的,这时我们就可以按照规则把这个单词分隔开来,就像这样:
然后我们再把scr放在am的后面,最后加上ay结尾,最后的结果就是:

同样的,我们如果遇到的是apple,那么我们只是需要在它的后面加way结尾,就是appleway。
先把代码贴上我们再一起分析一下;
#include
#include
#include
using namespace std;
/* Function prototypes */
string lineToPigLatin(string line);
string wordToPigLatin(string word);
int findFirstVowel(string word);
bool isVowel(char ch);
/* Main program */
int main() {
//cout << "This program translates English to Pig Latin." << endl;
string line;
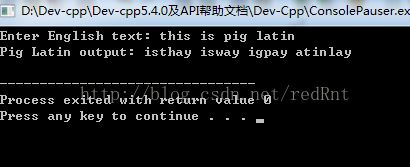
cout << "Enter English text: ";
getline(cin, line);
string translation = lineToPigLatin(line);
cout << "Pig Latin output: " << translation << endl;
return 0;
}
/*将输入的一行单词转换成为 Pig Latin
*将该行中的每个单词转换为Pig Latin,其他字符保持不变。 变量start保持跟踪
*当前单词开始的索引位置。 作为特殊情况,代码开始于-1表示尚未遇到当前字
*的开始。isalpha(ch),是为了保证ch一定是字母,因为我们考虑到输入空格的时
*候应该维持空格
*/
string lineToPigLatin(string line) {
string result; /*用于储存结果*/
int start = -1;
for(int i = 0; i < line.length(); i++) {
char ch = line[i]; /*将每一行的字母分离用于判断*/
if(isalpha(ch)) {
if(start == -1) start = i;
} else{
if(start >=0) {
result += wordToPigLatin(line.substr(start,i-start));
start = -1;
}
result += ch;
}
}
if (start >= 0) result += wordToPigLatin(line.substr(start));
return result;
}
/*将一个单词变为PigLatin数*/
string wordToPigLatin(string word) {
int vp = findFirstVowel(word);
if(vp == -1) {
return word;
}else if(vp ==0) {
return word + "way";
}else{
string head = word.substr(0,vp);
string tail = word.substr(vp);
return tail + head + "ay";
}
}
/*找到第一个元音字母并返回其下标*/
int findFirstVowel(string word) {
for(int i = 0; i <= word.length(); i++) {
if(isVowel(word[i])) return i;
}
return -1;
}
/*判断是否为元音,使用switch语句*/
bool isVowel(char ch) {
switch(ch) {
case 'A': case 'E': case 'I': case'O': case 'U':
case 'a': case 'e': case 'i': case'o': case 'u':
return true;
default:
return false;
}
} 
代码分析
其实整体的思路很清晰,看起来很简单,实际却不是那么简单,我们分析一下代码的执行过程,首先主函数从窗口读入一串字符串,然后主函数调用这个函数
lineToPigLatin(string line)将字符串转化成pig Latin,而lineToPigLatin函数调用wordToPigLatin函数,将每一个单词都转化成pig Latin,而空格等字符就不是字母,所以执行过程中不受影响。
我们应该好好认真分析这一段代码,虽然它很长,但是它提供了将字符串分解成一个个单词的范式。而wordToPigLatin则利用substr函数,将字符串分离为一个个单词
最后利用连接符号将它连接起来。
PS:这也是字符串的最后一个内容,接下来就是总结STL,一个极其强大的数据结构了。