Python字符串(str)功能详细分析
Python字符串(str)功能详细分析
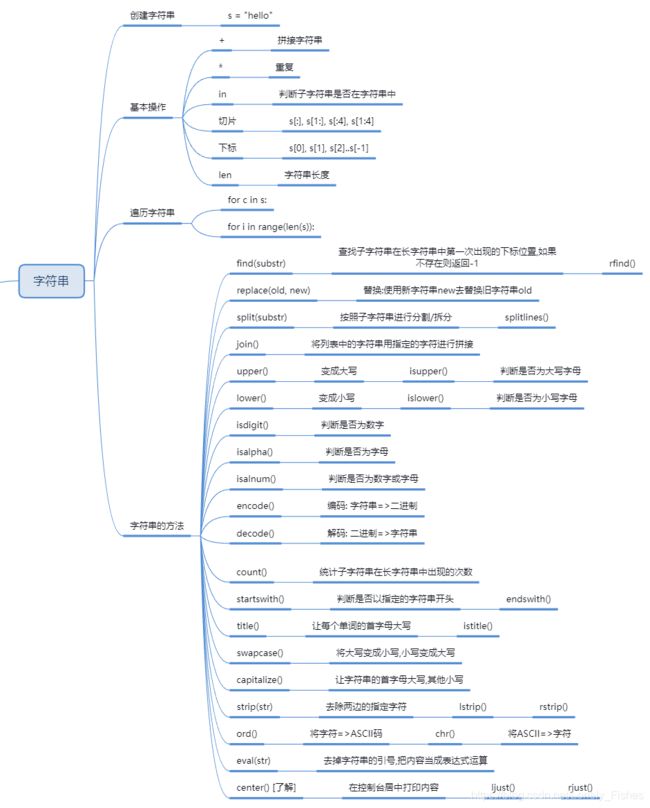
一、string字符串
1.概述
由多个字母,数字,特殊字符组成的有限序列
在Python中,使用单引号或者双引号都可以表示字符串
注意:没有单符号的数据类型
示例: ‘a’ “a”
2.创建字符串
代码演示:
str1 = "hello" str2 = "abc1234" str3 = "***fhhg%%%" str4 = "中文"
3.字符串运算
代码演示:
#1.+ 字符串连接 s1 = "welcome" s2 = " to China" print(s1 + s2) #注意:在Python中,使用+。只能是字符串和字符串之间,和其他数据类型使用的话不支持,其他类型运算要求也是一样,都要求是相同的数据类型 #print("abc" + 10) # False #print("123" + 1) #print(1 + "12" + 12) #print("hello" + True) #2. * 字符串重复 s3 = "good" print(s3 * 3) #3.获取字符串中的某个字符 """ 类似于列表和元组的使用,通过索引来获取指定位置的字符 注意索引的取值范围【0~长度, -1】,不能索引越界 访问方式:字符串名称[索引] """ s4 = "abcdef" print(s4[1]) #print(s4[10]) #IndexError: string index out of range #获取字符串的长度:len() #遍历字符串,和list,tuple的用法完全相同,通常与for循环搭配使用 for element in s4: print(element) for index in range(0,len(s4)): print(s4[index]) for index,str in enumerate(s4): # 枚举法 print(index,str) #4.截取字符串【切片】,与列表操作一致 str1 = "hello world" #指定区间 print(str1[3:7]) #从指定位置到结尾,包含指定位置 print(str1[3:]) #从开头到指定位置,但是不包含指定位置 print(str1[:7]) str2 = "abc123456" print(str2[2:5]) #c12 print(str2[2:]) #c123456 print(str2[2::2]) #c246 print(str2[::2]) #ac246 print(str2[::-1]) #654321cba 倒序 print(str2[-3:-1]) #45 -1表示最后一个字符 #5.判断一个子字符串是否在原字符串中 #in not in str3 = "today is a good day" print("good" in str3) # True print("good1" not in str3) # False
4.格式化输出
通过%来改变后面字母或者数字的含义,%被称为占位符
%d 整数
%f 浮点型,特点:可以指定小数点后的位数
%s 字符串
代码演示:
#6.格式化输出 num = 10 string1 = "hello" print("string1=",string1,"num=",num) #注意:变量的书写顺序尽量和前面字符串中出现的顺序保持一致 print("string1=%s,num=%d"%(string1,num)) f = 12.247 print("string1=%s,num=%d,f=%f"%(string1,num,f)) #需求:浮点数保留小数点后两位 print("string1=%s,num=%d,f=%.2f"%(string1,num,f)) #round(12.247,2)
5.常用转义字符
通过\来改变后面字母或者特殊字符的含义
\t 相当于tab键
\n 相当于enter键
\b 相当于backspace
代码演示:
#7.转义字符 string2 = "hello\tworld" string21 = "hello world" print(string2) print(string21) #换行:\n 多行注释 string3 = "hello\nPython" string31 = """hello python2354623 """ print(string3) print(string31) #需求:"hello" print("\"hello\"") #C:\Users\Administrator\Desktop\SZ-Python1805\Day6\视频 print("C:\\Users\\Administrator\\Desktop") #注意;如果一个字符串中有多个字符需要转义,则可以在字符串的前面添加r,可以避免对字符串中的每个特殊字符进行转义 print(r"C:\Users\Administrator\Desktop")
6.常用功能
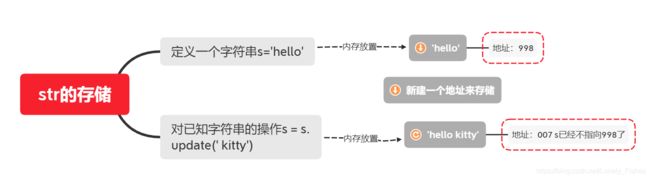
注意:字符串是不能修改的,除了在后面合并和新增。所以字符串的操作都会生成一个新的变量来存放。
6.1获取长度和次数
代码演示:
#1.计算字符串长度 len #类似于list和tuple的中获取长度的用法 str1 = "hfufhja" l = len(str1) print(l) #2,计算某个字符或者子字符串在原字符串中出现的次数 count str2 = "this is a good day good day" #count(str,[start,end]) #在整个字符串中进行查找 print(str2.count("day")) #在指定区间内进行查找 print(str2.count("day",3,10))
6.2大小写转换
代码演示:
#注意:使用字符串中的功能,一般情况下,都是生成一个新的字符串,原字符串没有发生任何变化 #3.大小写字母转换 #lower() 将字符串中的大写字母转换为小写 s = "Today Is a Good day" s = s.lower() print(astr31) #upper() 将字符串中小写字母转换为大写 str2 = "Today Is a Good day" astr2 = str2.upper() print(astr2) #swapcase() 将字符串中小写字母转换为大写,大写字母转换为小写 str33 = "Today Is a Good day" astr33 = str33.swapcase() print(astr33) #capitalize() 将一句英文中首单词的首字母转化为大写,其他小写 str34 = "today Is a Good day" astr34 = str34.capitalize() print(astr34) #title() 将一句英文中每个单词的首字母大写 str35 = "today is a good day" astr35 = str35.title() print(astr35)
6.3整数和字符串转换
代码演示:
#4.字符串和数字之间的转换 #int() float() str() #eval(str) 将str转换为有效的表达式,参与运算,并返回运算结果 num1 = eval("123") print(num1) #print("123") print(type(num1)) print(int("123")) #eval和int将+和-当做正负号处理,但是eval函数做运算的时候数据类型因该是'数值' print(eval("+123")) print(int("+123")) print(eval("-123")) print(int("-123")) #将12+3字符串转换为了有效的表达式,并运算了结果 print(eval("12+3")) #15 #不成立 #print(int("12+3")) #ValueError: invalid literal for int() with base 10: '12+3' print(eval("12-3")) #9 #print(int("12-3")) #ValueError: invalid literal for int() with base 10: '12-3' #print(eval("a123")) #NameError: name 'a123' is not defined #print(int("a123")) #ValueError: invalid literal for int() with base 10: 'a123' #总结:注意区分eval和int【eval:转换有效的表达式 int:将字符串转换为整型】
6.4填充
代码演示:
#5.填充 #center(width[,fillchar]) 返回一个指定宽度的居中字符串,width是填充之后整个字符串的长度,fillchar为需要填充的字符串,默认使用空格填充 str1 = "hello" print(str1.center(20)) print(str1.center(10,"*")) #ljust(width[,fillchar]) 返回一个指定宽度的字符串,将原字符串居左对齐,width是填充之后整个字符串的长度 print(str1.ljust(40,"%")) #rjust width[,fillchar]) 返回一个指定宽度的字符串,将原字符串居右对齐,width是填充之后整个字符串的长度 print(str1.rjust(40,"%")) #zfill(width) 返回一个指定宽度的字符串,将原字符串居右对齐,剩余的部分使用的数字0填充 print(str1.zfill(40))
6.5查找
代码演示:
#6.查找【掌握】 str2 = "abcdefhello123hello" #find(str[,start,end]) 从左到右依次检测,str是否在原字符串中,,也可以指定查找的范围 #特点;得到的子字符串第一次出现的开始字符的下标,如果查找不到则返回-1 print(str2.find("hello")) #6 print(str2.find("e")) print(str2.find("yyy")) #-1 print(str2.find("e",3,10)) #rfind(str[,start,end]) 类似于find,从右向左进行检测 print(str2.rfind("hello")) #14 #index 和find的使用基本相同,唯一的区别在于如果子字符串查找不到,find返回-1,而index则直接报错 print(str2.index("hello")) #print(str2.index("yyy")) #ValueError: substring not found #rindex 和rfind的使用基本相同 #max(str) 获取str中最大的字母【在ASCII码表中的顺序】 #"abcdefhello123hello" print(max(str2)) str3 = "46732647" print(max(str3)) #min(str) 获取str中最小的字母【在ASCII码表中的顺序】
6.6提取
代码演示:
#7.提取字符串 #strip(str) 使用str作为条件提取字符串,除了两头指定的字符串 str1 = "********today is *********a good day*******" print(str1.strip("*")) #today is *********a good day #lstrip(str) 提取字符串,除了左边的指定字符串 str11 = "********today is *********a good day*******" print(str11.lstrip("*")) #rstrip() str12 = "********today is *********a good day*******" print(str12.rstrip("*"))
6.7分割和合并
代码演示:
# split():拆分/分割 返回一个拆分之后的列表
s = 'how are you'
list1 = s.split() # ['how', 'are', 'you']
list1 = s.split(' ') # ['how', 'are', '', 'you']
list1 = s.split('are') # ['how ', ' you']
list1 = s.split('hello') # ['how are you']
list1 = s.split('you') # ['how are ', '']
list1 = s.split('o', 1) # ['h', 'w are you']
print(list1)
# splitlines():按行拆分
s = '''
论语
学而不思则罔,
思而不学则殆。
有朋自远方来,
不亦乐乎
'''
print(s.splitlines()) # ['', '论语', '学而不思则罔,', '思而不学则殆。', '有朋自远方来,', '不亦乐乎']
print(s.splitlines(True)) # ['\n', '论语\n', '学而不思则罔,\n', '思而不学则殆。\n', '有朋自远方来,\n', '不亦乐乎\n']
print(s.split('\n')) # ['', '论语', '学而不思则罔,', '思而不学则殆。', '有朋自远方来,', '不亦乐乎', '']
# 合并:
# join():将列表中的所有字符串用指定的连接字符串连接起来
l = ['', '论语', '学而不思则罔,', '思而不学则殆。', '有朋自远方来,', '不亦乐乎', '']
print(''.join(l))
print('\n'.join(l))
# print("+".join([1,2,3])) # 报错
6.8替换
代码演示:
#9.替换 #replace(old,new,[max]) 用new的字符串将old的字符串替换掉.max表示可以替换的最大次数【从左到右】 str1 = "this is a easy test test test test" print(str1.replace("test","exam")) print(str1.replace("test","exam",2)) # 字符串的加密 #使用场景:在一定情境下,可以实现字符串的简单加密,加密规则可以自定义 #maketrans() 定义加密,创建字符映射的转换表,结果为字典,通过key:value的方式 #translate(table) t = str.maketrans("aco","123") print(t) #{97: 49, 99: 50, 111: 51} str2 = "today is a good day" print(str2.translate(t)) #t3d1y is 1 g33d d1y
6.9判断
代码演示:
#10.判断 #isalpha() 如果字符串中至少包含一个字符并且所有的字符都是字母,才返回True print("".isalpha()) print("abc".isalpha()) print("abc123".isalpha()) #False #isalnum 如果字符串中至少包含一个字符并且所有字符都是字母或者数字的时候才返回True print("".isalnum()) #False print("abc".isalnum()) print("abc123".isalnum()) print("123".isalnum()) print("1abc".isalnum()) print("1abc¥".isalnum()) #False #isupper 如果字符串中至少包含一个字符并且出现的字母必须是大写字母才返回True,数字的出现没有影响 print("".isupper()) print("aBC".isupper()) print("123A".isupper()) #True print("abc".isupper()) #islower #istitle 每个单词的首字母必须全部大写才返回True print("Good Day".istitle()) print("good Day".istitle()) #isdigit() 【掌握】 如果字符串中只包含数字,则返回True print("abc123".isdigit()) print("2364".isdigit()) #需求:将用户从控制台输入的字符串转化为整型【全数字】 str = input() if str.isdigit(): int(str) print("yes")
6.10前缀和后缀
代码演示:
#11.前缀和后缀【掌握】 子字符串是连续的,返回值是bool类型 #startswith str1 = "helloPython" print(str1.startswith("hello")) #endswith print(str1.endswith("on"))
6.11编解码
代码演示:
#12.字符串编码和解码 #注意:主要针对的是中文 #encode() 默认的编码格式为utf-8 str2 = "this is 千锋教育" print(str2.encode()) print(str2.encode("utf-8")) print(str2.encode("gbk")) #decode() bytes对象 #\xe5\x8d\x83\xe9\x94\x8b\xe6\x95\x99\xe8\x82\xb2 #print(r"\xe5\x8d\x83\xe9\x94\x8b\xe6\x95\x99\xe8\x82\xb2".decode()) 错误
6.12ASCII码转换
代码演示:
#13.ASCII吗的转换 #ord() print(ord("A")) print(ord("0")) #chr() print(chr(65)) print(chr(110))