PEAX: Interactive Visual Pattern Search in Sequential Data Using Unsupervised Deep Representation Le
论文传送门
视频
代码
作者
哈佛大学工程与应用科学学院
- Fritz Lekschas
- Daniel Haehn (马萨诸塞大学)
- Hanspeter Pfister
诺华生物医学研究所
- Brant Peterson
- Eric Ma
哈佛大学医学院
- Nils Gehlenborg
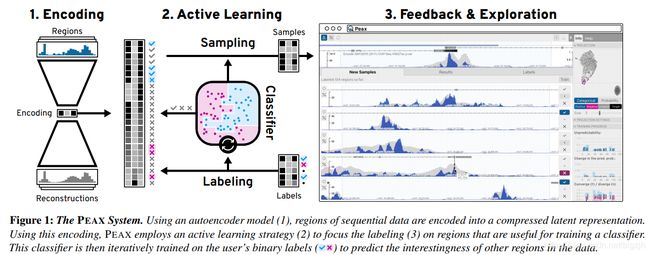
摘要
我们介绍了PEAX,一种基于特征的新颖技术,用于在序列数据(例如时间序列或映射到基因组序列的数据)中进行交互式视觉模式搜索。由于存在很大的搜索空间,模式的视觉复杂性以及用户对相似性的感知,因此以视觉方式通过相似性搜索模式通常具有挑战性。例如,在基因组学中,研究人员试图将多元顺序数据中的模式与细胞或病原体过程联系起来,但是由于缺乏真实数据和高方差,因此自动模式检测不可靠。我们已经开发了卷积自动编码器,用于顺序数据中区域的无监督表示学习,与现有的相似性度量相比,它可以捕获复杂模式的更多视觉细节。利用这种学习到的表示作为顺序数据的特征,我们随附的可视化查询系统可以对模式搜索进行交互式反馈驱动的调整,以适应用户的感知相似性。PEAX使用主动学习采样策略,收集用户生成的二类相关性反馈。该反馈用于训练二分类的模型,以最终找到表现出类似于搜索目标的模式的其他区域。我们通过基因组学案例研究来证明PEAX的功能,并与八位领域专家一起进行用户研究报告,以评估PEAX的可用性和实用性。此外,我们在另外两个用户研究中评估了学习到的特征表示对于视觉相似性搜索的有效性。我们发现,与其他常用技术相比,我们的模型检索到的相似模式明显更多。
Introduction
当搜索空间大、数据复杂或搜索查询难以形式化时,从视觉上搜索序列数据中的模式可能是一项挑战。

距离度量:
- 欧几里德距离欧氏距离
- 动态时间规整
没有单一的算法考虑人类对时间序列相似性的判断。
为了应对这些挑战,我们提出了一种新的基于特征的方法,利用卷积自动编码器模型来评估序列数据中视觉模式的相似性。
由于分析师主观感知的相似性是未知的,我们开发了 PEAX,一个可视化的查询系统,它通过二进制相关反馈交互式地学习模式搜索的分类器。
我们将我们的技术应用于两个表观基因组数据集,并演示了 PEAX 如何用于探索生物现象。为了评估我们的方法,我们首先评估了自动编码器在顺序模式中重建视觉特征的能力。
此外,我们通过与 8 位表观基因组学领域专家的面对面用户研究,评估了 PEAX 的可用性和有用性。
Related Work
序列数据中模式搜索的相似性度量已被广泛研究。相似性搜索技术包括基于距离和基于特征的方法。PEAX 不使用基于草图的策略,因为很难精确绘制复杂的模式。相似性的概念在很大程度上取决于用户的心理模型,可能无法用客观的相似性度量很好地捕捉。交互式视觉机器学习是一种通过用户交互来调整 VQS 结果的强大技术。在我们的工作中,我们使用基于不确定性采样的交互式二类标记的主动学习采样策略。
Goals and Tasks
PEAX 的主要目标是在序列数据中找到显示目标模式实例的区域。由于分类器是基于用户的主观标签进行交互训练的,因此没有关于何时停止训练过程的客观度量。因此,用户需要了解训练进度,以决定何时停止训练。
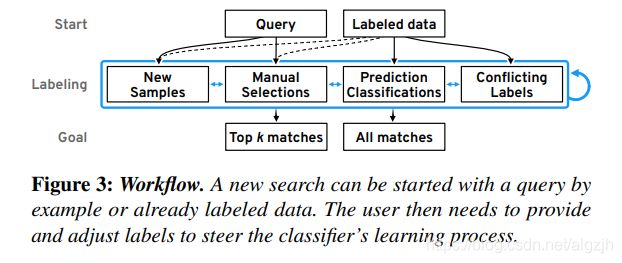
用户可以从一个示例查询开始,也可以从一组标记数据开始。为了得到一组匹配的窗口,用户必须提供标签,以便训练分类器和引导模式搜索。
高级交互任务
- 自由浏览和探索,以便能够获得数据的概述和查找搜索询问。
- 识别分类器的预测,以便能够理解当前匹配的模式是什么。
- 比较窗口以识别潜在相关窗口之间的相似或不同之处。
- 将窗口上下文化,以理解模式的更广泛影响,提高手动分配标签的可信度,并找到相关窗口。
- 可视化学习进度,突出标注的影响,并告知经过训练的分类器的状态。
- 显示潜在表示实现查询模式的视觉特征是否被捕获的能力。
Representation Learning
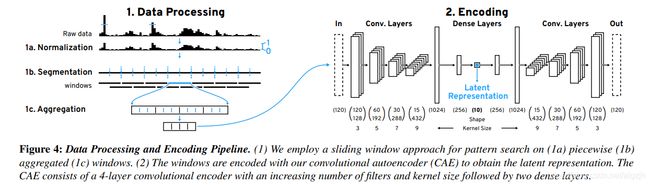
我们将数值限制在 99.9%以去除罕见的异常值,然后将数据缩放至[0,1]。然后我们将数据分成固定长度 l 的重叠窗口。
重叠由步长 s 和步长频率 f 控制。
f = l s f=\frac{l}{s} f=sl
下采样本身已被证明是一种有效的相似性搜索策略。
预处理窗口用于训练CAE(Convolutional Autoencoder,卷积自动编码器)。CAE 由编码器和解码器模型组成,其中编码器试图学习输入数据的变换,解码器能够尽可能最好地将其重构为原始输入。
Active Learning
PEAX 采用两种抽样策略来选择未标记的窗口,这些窗口随后被显示给分析师进行标记。
数据处理和编码管道
平均距离:
avg dist ( w , k ) = norm ( ∑ i k ( ∥ w − nn i ( w ) ∥ ) / k ) \operatorname{avg} \operatorname{dist}(w, k)=\operatorname{norm}\left(\sum_{i}^{k}\left(\left\|w-\operatorname{nn}_{i}(w)\right\|\right) / k\right) avgdist(w,k)=norm(∑ik(∥w−nni(w)∥)/k)
最小化分数:
avg dist ( u , k ) + norm ( max ( ∥ S − S ˉ ∥ ) − ∥ S − u ∥ ) \operatorname{avg} \operatorname{dist}(u, k)+\operatorname{norm}(\max (\|S-\bar{S}\|)-\|S-u\|) avgdist(u,k)+norm(max(∥S−Sˉ∥)−∥S−u∥)
不确定性:
uncertainty ( u ) + avg dist ( u , k ) + norm ( ∥ q − u ∥ ) (u)+\operatorname{avg} \operatorname{dist}(u, k)+\operatorname{norm}(\|q-u\|) (u)+avgdist(u,k)+norm(∥q−u∥)
+ norm ( max ( ∥ S − S ˉ ∥ ) − ∥ S − u ∥ ) +\operatorname{norm}(\max (\|S-\bar{S}\|)-\|S-u\|) +norm(max(∥S−Sˉ∥)−∥S−u∥)
我们选择使用随机森林分类器。为了衡量分类过程,我们记录了总体不确定性、预测概率的总体变化以及预测概率的差异。
The User Interface

- Query View
- List View
- Embedding View
- Progress View
Implementation
- JavaScript
- React
- HiGlass
- Regl
- WegGL
- Flask
- Scikit-Learn
- Sqlite
- Keras with TensorFlow
Use Cases: Epigenomics

Evaluation
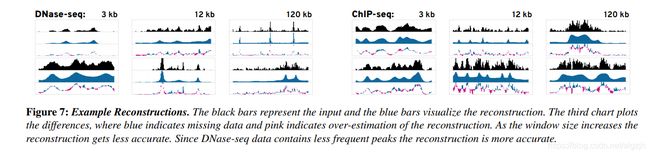
- Reconstruction
- Similarity Comparison
- Usability & Usefulness


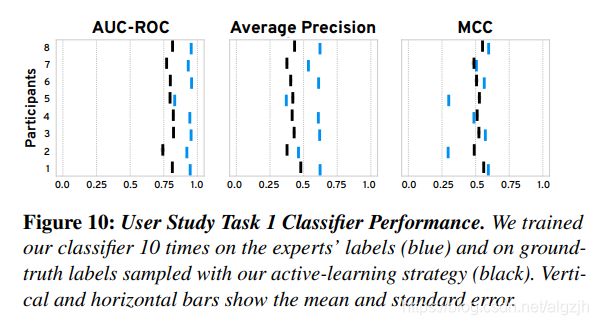
Discussion
我们不是使用深度学习技术来预测数据集固定组合中特定模式类型的存在,而是使用深度学习来增强人类智能,以在多变量序列数据中搜索模式。我们的方法通过提供学习的潜在表示和主动学习的分类器来提高视觉模式搜索的性能。拥有一个通过模式相似性对大型序列数据集进行一般性探索的工具,可以提出新的问题,发现以前无法检测到的模式,并补充高度专业化的模式检测器的工作。
目前,PEAX 可以扩展到多达一百万个窗口。为了确保交互性,PEAX 对数据进行预处理,对于普通笔记本电脑上的一百万个窗口来说,这大约需要 25-30 分钟。
Conclusions and Future Work
我们提出了 PEAX,这是一种在序列数据中进行交互式视觉模式搜索的新技术和工具。我们发现,我们的卷积自动编码器模型学习一种潜在的表示,这种表示在相似性搜索方面比现有技术更有效。
在未来的工作中,我们希望比较不同自动编码器的性能。未来工作的一个令人兴奋的途径是系统地测试不同主题内部和之间的 hu-man 标签的变化。此外,将 PEAX 扩展到多用户系统并研究多用户对标签和学习过程的影响也是很有意思的。