Windows MapReduce 开发环境搭建以及运行实战
一 插件配置
1 将插件hadoop-eclipse-plugin-2.7.3.jar放入到D:\Program\eclipse-mars\eclipse\plugins目录下。
2 重启eclipse,会发现Prefernces中多一个Hadoop Map/Reduce插件。
3 在windows下安装Hadoop
下载https://mirrors.cnnic.cn/apache/hadoop/core/hadoop-2.7.4/hadoop-2.7.4.tar.gz
注意:该Hadoop的版本和Linux的Hadoop的版本保持一致。
将hadoop-2.7.4.tar.gz解压到D:\Program\hadoop-2.7.4目录下。
4 相关文件替换
在https://github.com/SweetInk/hadoop-common-2.7.1-bin中下载winutils.exe,libwinutils.lib 拷贝到%HADOOP_HOME%\bin目录 。
在https://github.com/SweetInk/hadoop-common-2.7.1-bin中下载hadoop.dll,并拷贝到c:\windows\system32目录中。
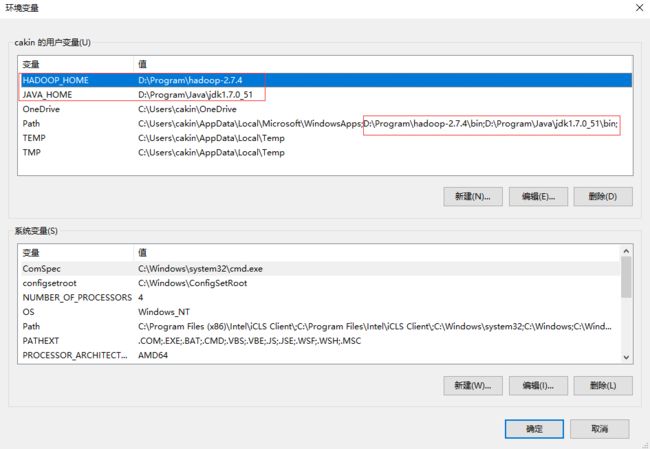
5 配置widows下的环境变量
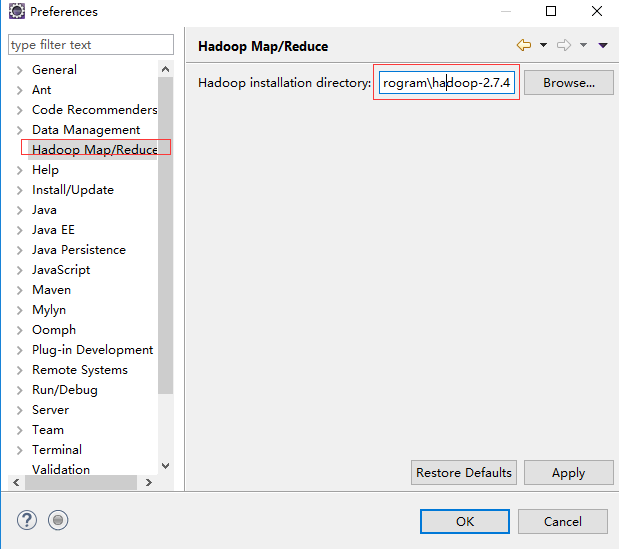
6 在elipse中配置hadoop的安装路径,截图如下:
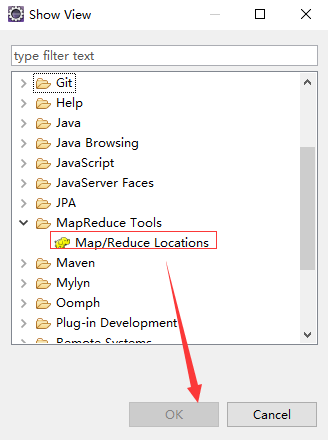
7 选择windows->show view->other,然后按照下面截图操作
8 在elipse下配置hadoop
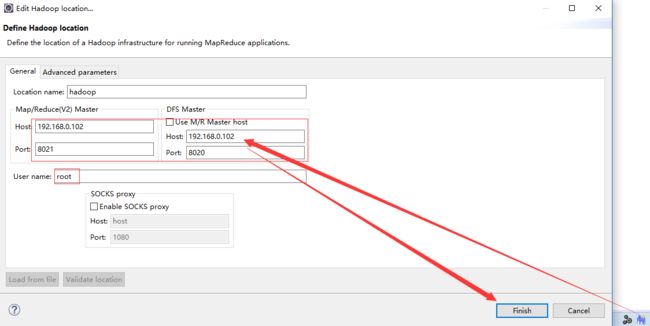
这里的8020和core-site.xml保持一致。
9 连接成功后elipse呈现如下截图
注意:为了防止连接失败,有3个点需要注意
第1点:配置etc\hostname,配置如下
centos
第2点:配置etc\hosts,配置如下
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.0.102 centos
第3点:配置core-site.xml,配置如下
二 关闭Linux上的YARN,修改为在windows本地运行
[root@master sbin]# ./stop-yarn.sh
stopping yarn daemons
stopping resourcemanager
127.0.0.1: \S
127.0.0.1: Kernel \r on an \m
127.0.0.1: stopping nodemanager
no proxyserver to stop
[root@master sbin]# jps
4912 NameNode
6064 Jps
5195 SecondaryNameNode
5038 DataNode
三 优化MapReduce程序
package com.cakin.mapreduce.wc;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.Mapper.Context;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class WordcountApp {
public static class MyMapper extends Mapper {
/**
* map阶段的业务逻辑处理就写在map()方法中
* maptask会对每一行输入数据调用一次我们自定义的map()方法
* @throws InterruptedException
*/
private Text word = new Text();
private IntWritable one = new IntWritable(1);
@Override
protected void map(LongWritable key,Text value,Context context) throws IOException, InterruptedException{
//将maptask传递给我们的文本内容先转换成string
String line=value.toString();
//按照空格行切割单词
String[] words=line.split(" ");
//将单词输出为<单词,1>
for(String w:words) {
word.set(w);
//将单词作为key,将次数1作为Value,以便于后续的数据分发,可以根据单词分发,以便于相同单词会到相同的reduce task
context.write(word,one);
}
}
}
public static class MyReducer extends Reducer {
/**
*
*
*
* 入参key:是一组单词的kv对应的key,将相同单词的一组传递,如此时key是hello,那么参数二是一个迭代器,一组数
* @throws InterruptedException
* @throws IOException
*/
private IntWritable sum= new IntWritable();
@Override
protected void reduce(Text key,Iterable values ,Context context) throws IOException, InterruptedException {
int count=0;
/**
Iterator iterator=values.iterator();
while(iterator.hasNext()) {
count+=iterator.next().get();
}
*/
for(IntWritable value:values) {
count+=value.get();
}
sum.set(count);
context.write(key, sum);
}
}
public static void main(String[] args) throws IllegalArgumentException, IOException, ClassNotFoundException, InterruptedException {
if(args.length <2)
{
args= new String[]{
"hdfs://192.168.0.102:8020/input",
"hdfs://192.168.0.102:8020/output1"
};
}
Configuration conf=new Configuration();
/*
* 集群中节点都有配置文件
conf.set("mapreduce.framework.name.", "yarn");
conf.set("yarn.resourcemanager.hostname", "mini1");
*/
Job job=Job.getInstance(conf);
//jar包在哪里,现在在客户端,传递参数
//任意运行,类加载器知道这个类的路径,就可以知道jar包所在的本地路径
job.setJarByClass(WordcountApp.class);
//指定本业务job要使用的mapper/Reducer业务类
job.setMapperClass(MyMapper.class);
job.setReducerClass(MyReducer.class);
//指定mapper输出数据的kv类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
//指定最终输出的数据kv类型
job.setOutputKeyClass(Text.class);
job.setOutputKeyClass(IntWritable.class);
//指定job的输入原始文件所在目录
FileInputFormat.setInputPaths(job, new Path(args[0]));
//指定job的输出结果所在目录
FileOutputFormat.setOutputPath(job, new Path(args[1]));
//将job中配置的相关参数及job所用的java类在的jar包,提交给yarn去运行
//提交之后,此时客户端代码就执行完毕,退出
//job.submit();
//等集群返回结果在退出
boolean res=job.waitForCompletion(true);
System.exit(res?0:1);
//类似于shell中的$?
}
}
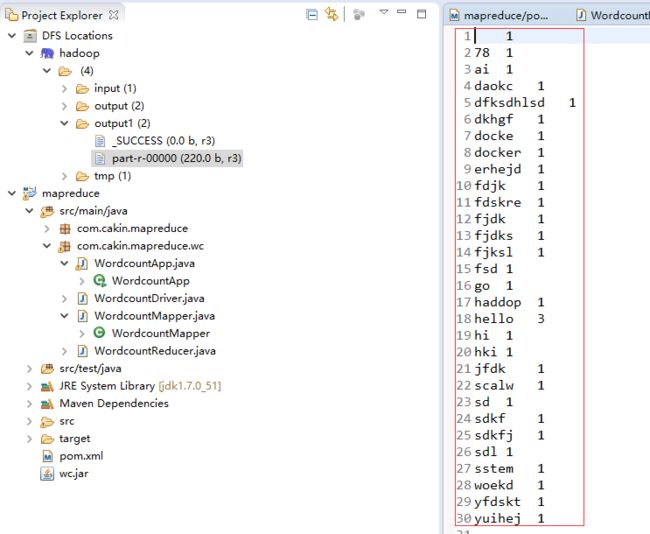
四 MapReduce运行结果
五参考文档
http://www.jikexueyuan.com/course/2686.html
http://www.jikexueyuan.com/course/2116.html
https://www.cnblogs.com/supiaopiao/p/7240308.html
http://blog.csdn.net/fly_leopard/article/details/51250443
http://blog.csdn.net/yunlong34574/article/details/21331927
http://blog.csdn.net/xiaoxiao315/article/details/72920705
http://blog.csdn.net/kangkangwanwan/article/details/78491242?locationNum=4&fps=1