
复制几乎是构成分布式系统,尤其是分布式存储和分布式数据库的关键所在,那么本文就来综合谈论下复制技术。
简单说复制本身可以分为同步复制和异步复制,两者的区别在于前者需要等待所有副本返回写入确认,而后者只需要一个返回确认即可。从用途上,复制可以分为两类,一类用于确保不同副本的表现行为一致(避免divergence),另一类则用于允许不同副本之间的数据差异(divergence不可避免,如Dynomo),先来看看前者。
有若干种手段用于确保不同副本之间的状态一致:
第一种叫主从复制。主从之间可以是异步复制,也可以是同步复制。例如MySQL,在默认情况下采用异步复制,异步复制容易引起数据丢失,比如主从结构中,主节点的写入请求还没有复制到从节点就挂了,当从节点被选为新的主节点之后,在这之前写入没有同步的数据就会被丢失。即便采用了同步复制,也只能提供相对较弱的基本保障,考虑如下情形:主接收写入请求然后发到从节点,从节点写入成功后并发送确认给主,如果此时主节点正准备发送确认信息给客户端时挂了,那么客户端就会认为提交失败,可是从节点已经提交成功了,如果这是从节点被提升为主,那么就出现问题了。
在主从复制结构里,异步复制相比同步复制具备更高的吞吐量和更低延迟,因此,结合同步和异步复制是一个常见选项。
比如Kafka,根据它的声称,这是一个CA系统,也就是同时达到数据一致和高可用。Kafka的复制设计同时包含异步复制和同步复制,同步复制节点组成的集合称为ISR(In-Sync Replicas),只有ISR内的所有节点都对写入确认之后,才算做写成功。当一个节点失效,Leader会通过ZooKeeper感知并把它从ISR 中移除。不过Kafka有一个问题,因为它声称F个节点可以容忍F-1个节点失效,这跟其他系统不同,通常类似的设计只能容忍F/2-1个节点失效,也就是说要确保大多数节点都能正常运行,而Kafka这把这个条件弱化成为只有Leader运行也可以。这样做是有问题的:假设ISR只剩下一个Leader在运行,如果此时Leader跟ZooKeeper的网络连接中断,就会产生一次选举,让ISR之外的节点(那些异步复制节点)加入ISR,通常它会落后此前的Leader不少。当原先的Leader跟ZooKeeper网络连接恢复后,系统就产生脑裂,需要对2个Leader的数据做Merge或者舍弃,后者则会导致数据丢失。
另一个例子来自数据库高可用设计,如下是Joyent的PostgreSQL高可用方案manatee,一个主节点带一个同步复制的从节点,以及若干异步复制从节点,当主节点挂了之后,同步复制节点被选举为主节点,异步复制节点选举一个提升为同步复制,而此前挂掉的节点恢复之后首先加入异步复制集群。
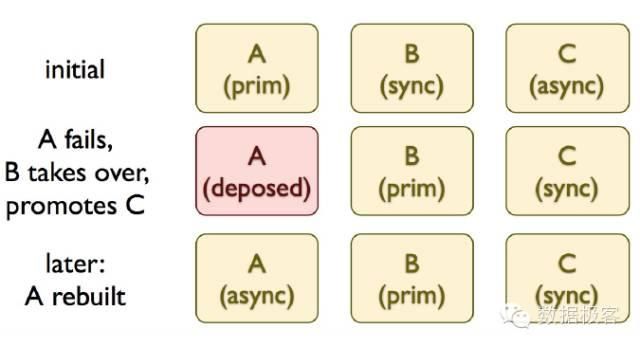
另一个高可用设计MaxScale项目也是类似的设计,直接针对BinLog搭建Replication Proxy,该Proxy同时作为主节点的Slave,以及其他Slave的Master。
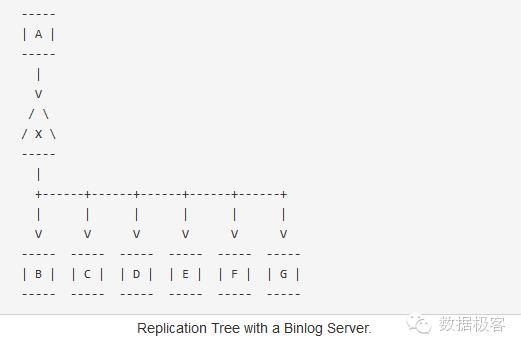
因此可以看出,主从复制对于数据的保障不高,基于主从结构做高可用设计总是一件很困难的事情。
第二种复制手段是通过两阶段提交来提供更高的保障。例如MySQL Cluster就是通过2PC来提供数据同步的。相比之下,主从复制可以看做一阶段提交,因为没有发生错误的回滚。由于2PC很容易因为参与者宕机导致一直阻塞,因此2PC用于复制并不常见。
第三种则引入分区一致性算法Paxos,又叫复制状态机。复制状态机在数据库开发的很多领域都可以遇到,比如Google Megastore,针对不同分区的每次提交采用复制状态机来确保每个分区的全局事务提交时序;Google Spanner在单分区内也采用了类似的设计。复制状态机主要用于满足两点需求:客户端在面对任何一个副本时都具备完全一致的访问行为;每个副本在执行请求时都需要按照完全一致的顺序来进行。
复制状态机通常都是基于复制日志实现的,每一个服务器存储一个包含一系列指令的日志,并且按照日志的顺序进行执行。每一个日志都按照相同的顺序包含相同的指令,所以每一个服务器都执行相同的指令序列。因为每个状态机都是确定的,每一次执行操作都产生相同的状态和同样的序列。保证复制日志相同就是一致性算法的工作了。在一台服务器上,一致性模块接收客户端发送来的指令然后增加到自己的日志中去。它和其他服务器上的一致性模块进行通信来保证每一个服务器上的日志最终都以相同的顺序包含相同的请求,尽管有些服务器会宕机。一旦指令被正确的复制,每一个服务器的状态机按照日志顺序处理他们,然后输出结果被返回给客户端。因此,服务器集群看起来形成一个高可靠的状态机。
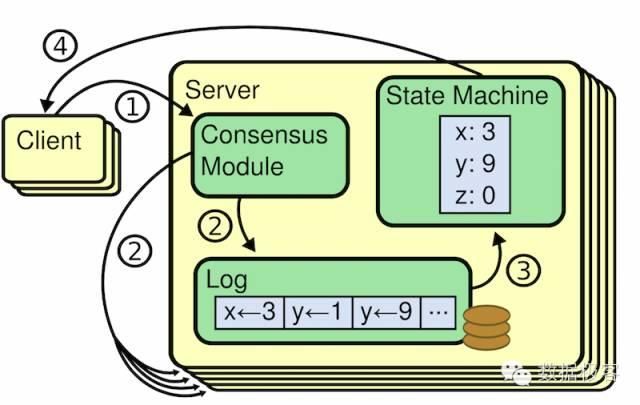
复制状态机如此重要,那么有没有独立的实现呢,ZooKeeper和Raft都是。以ZooKeeper为例,它实现了基于ZAB(ZooKeeper Atomic Broadcasting)协议的复制状态机。Leader产生状态变化后,跟随者产生相应的持久化日志并做确认。当从足够的副本(包含跟随者和Leader)获得ACK确认后,Leader通过发送提交信息进行一次提交。当某副本得到提交信息后,它应用到本地并进行相应的状态调整,所以,在ZooKeeper里进行一次状态确认需要两轮的消息传送,这是消耗很高的工作。
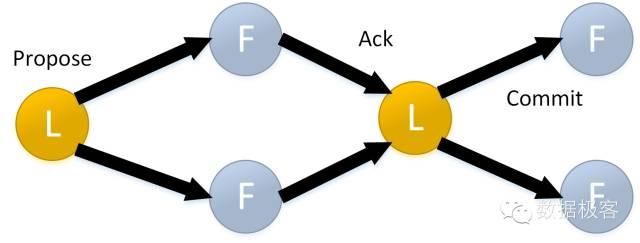
除了在Spanner这种前卫数据库中见到的复制状态机,在常规数据库里我们能见到的很少(拿来做分布式协调者的不算),那么,我们通常见到的MariaDB Galera Cluster是否算复制状态机呢?Galera完全是多主同步复制,复制协议采用Atomic broadcast,而原子多播是复制状态机的一种实现[4]。
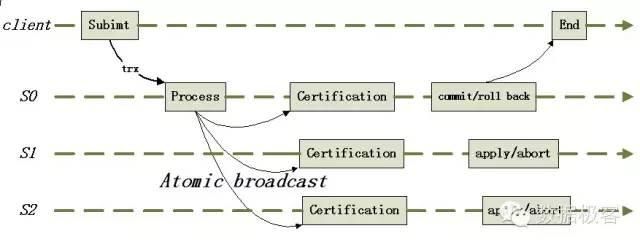
Galera的复制工作如下:
1. 事务在本地节点执行时采取乐观策略,成功广播到所有节点后再做冲突检测
2. 检测出冲突时,本地事务优先被回滚
3. 每个节点独立、异步执行队列中的Write Set
4. 事务T在A节点执行成功返回客户端后,其他节点保证T一定会被执行,因此有可能存在延迟,即虚拟同步
Galera是同步复制方案,事务在本地节点(客户端提交事务的节点)上提交成功时,其它节点保证执行该事务。在提交事务时,本地节点把事务复制到所有节点后,之后各个节点独立异步地进行certification test、事务插入待执行队列、执行事务。然而由于不同节点之间执行事务的速度不一样,长时间运行后,慢节点的待执行队列可能会越积越长,最终可能导致事务丢失。Galera内部实现了flow control,作用就是协调各个节点,保证所有节点执行事务的速度大于队列增长速度,从而避免丢失事务。根据[2]的测试结果,Galera会导致stale read,也不能提供宣称的快照隔离事务级别,因此,选择的时候需要知道它的适用场景。
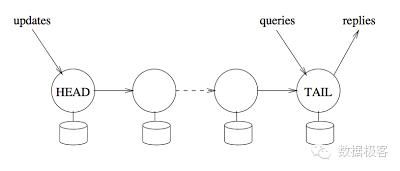
此外,还有一种复制叫做链式复制,本号之前的文章有介绍,它是主从复制的变种,所有读请求都转发到尾部节点响应,所有的写入请求都从头部节点写入,因此所有写入请求都严格按照单一时序进行,而针对尾部的读请求可以做到强一致性。相比复制状态机,链式复制可以提供更高的容错性,因为Paxos是基于多数选举原则的算法,如果系统可以容纳F个节点错误,那么系统中需要有2F+1个副本存在,而链式复制只需要F+1个副本。跟主从复制相比,主从复制中的主节点的角色在简单链式复制中由2个副本承担:头节点负责写入请求的顺序化,尾节点负责响应。这种角色的分工可以产生更低的读延迟和开销,因为只有一个节点负责处理读请求,而且不用等待其余任何副本的写入请求,然而,链式复制的写入延迟会增加,因为需要链上的所有副本都串行写入成功后才可返回响应,这一点要大大低于主从结构。因此,简单链式复制适用于高吞吐量和强一致性要求的场景(高并发读,低延迟写属于被牺牲的方面)。
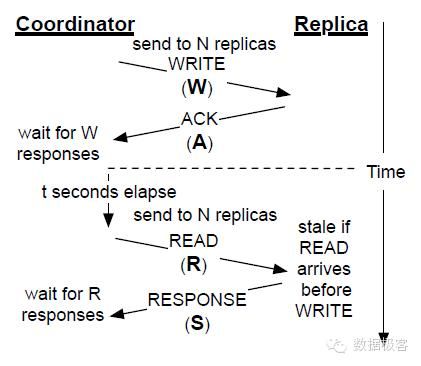
再来看看第二种复制的用途——允许不同副本之间的数据差异。比如在Dynamo系统中,不同副本的数据并不总完全一致,可以按照R+W和N的关系进行Quorum选举。
首先看看强Quorum,就是R+W>N的情况。这种情形是完全可以保证数据读写一致的,正如Amazon Dynamo那样。典型部署如下:在N个节点中,
R=1,W=N,这是针对读优化的场景
R=N,W=1,这是针对写优化的场景
R=N/2,W=N/2+1,这是针对读写适中的场景
例如默认情况下,Riak采用了N=3,R=2以及W=2的配置。
当R+W<=N时,叫做Partial Quorum,通常用于低延迟的服务,此时,读取不一致数据的概率是:
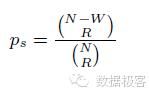
当N的值很大时,不一致的概率就会降低。2012年的文章PBS(Probabilistically Bounded Staleness)就是基于此提出的理论,旨在提供最终一致的程度,并在Cassandra数据库上进行了实现[3],根据测试,N=3时,从R=1, W=1变换到R=2, W=1时,数据不一致的窗口可以从1352 ms降低到202 ms,同时相比R=3,W=1的219ms延迟, R=2,W=1则可以降低到32ms。
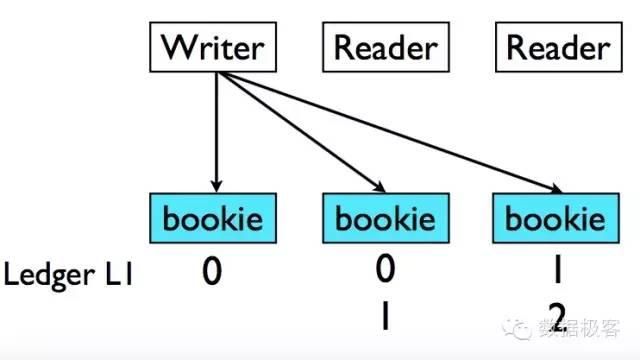
采用Quorum算法可以提供比Paxos更高的吞吐量,例如Apache BookKeeper项目,区别于ZooKeeper基于选举和一致性模块机制的复制状态机,BookKeeper可以服务高吞吐量的分布式日志系统。BookKeeper仍然依赖ZooKeeper作为一致性模块,这个项目已经很多年没有更新了,如果不是看到近期Twitter采用BookKeeper作为其分布式日志核心组件的介绍[1],也不会关注到。在BookKeeper中,引入一个概念叫Ledger,可以把它看作事务日志,对于每个Ledger,都只有唯一的写入者,写入者通过多个被称为Bookie的节点向Ledger同时写入,当大部分Bookie被写入,并且可以通过向不同组的Bookie写入不同数据提高写入并行度。
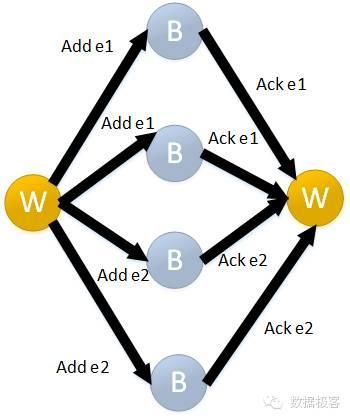
然而对于需要读取的客户端来说,就存在困难,因为它无法知道这些写入的数据是否被正确地复制到了其他副本,所以需要从多个Bookie读取数据才能确保一致。此外,BookKeeper还引入了ZooKeeper来存放被正确复制的最后记录的ID,为避免过于频繁地向ZooKeeper写入数据,该操作仅在Ledger关闭时进行。
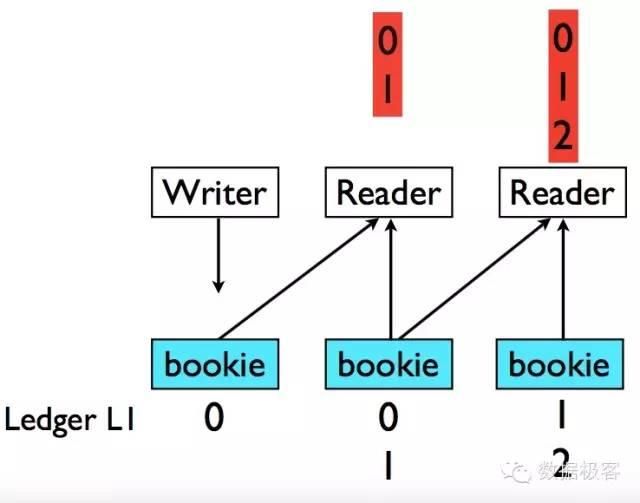
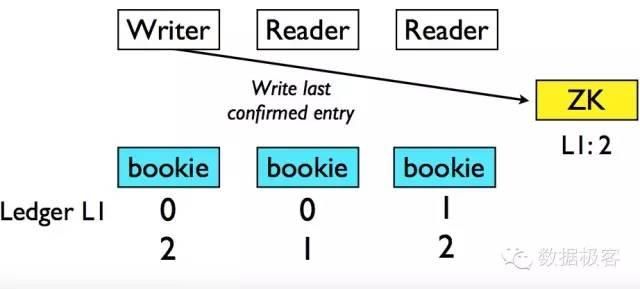
通过一系列优化,尽管通过一致性模块进行协调,但BookKeeper仍然保持了非常高的吞吐量和低延迟---差不多可以达到百万TPS和10毫秒级别,非常适合作为分布式日志和消息队列,Yahoo的Cloud Message Service也基于它进行。
关于复制还应当了解的一个话题叫做CRDT[5],全称叫做Convergent Replicated Data Type,目的是提供不用协调的收敛到一致的数据结构,因此又称为Conflict-free Replicated Data Type。分布式计数器是CRDT数据结构中最常见的一个例子:假设每个用户都能写入到自己的计数器中,当每个用户需要改变它的计数器数值时,它只改变自己的数值,这样就有了并发同时发生的数值增加。因此,这是个分布式系统,那么如何得到最后的整个计数器结果?只要将单独的这些计数器加起来即可—为了得到一个全局整体的计数器,每个节点用户都需要知道彼此另外节点上的计数器值,可以在节点间广播这些值。可是网络不是100%可靠,广播的消息有可能会丢失或延迟到达。解决消息丢失并不容易,让我们来看看如何解决:
1. 在发送方,节点服务器规则地广播它们的状态。
2. 在接收方,我们需要一种方式搞清楚发现消息的重复,节点服务器通过比较接受值和现有值,如果这两个值是相同的表示这是重复的消息,否则就是一个新的消息,更新原来的值即可。
解决延迟消息投递问题需要另外的技巧:假设计算器总是不断向前增加,不允许减少。那么现在该发现当接受到消息应该怎么做了:只要选择接受值和现有值之间最大差值的那个值。这样,每个节点都知道接受到消息后该怎么做,我们有了最终强一致性,因为只要一个节点接受到所有广播消息事件(无论以任何顺序),它会知道计数器当前状态,每个节点的状态也是相同的,没有冲突,所有节点最终会汇聚到相同的值。这就是CRDT的分布式计数器。
CRDT还有其他一些应用场景,具体可以看[5]的综述:
支持加法和减法的计数器
Last-Writer-Win注册器(一个注册器是一个能够存储对象和值的单元) – 基于时间戳merge
Multi-value 注册器 – 基于版本向量merge,如Amazon的Dynamo
Grow-only Set (支持新增和寻找). 这将会表明对于高级类型是有用的构建块。
2P-Set (two-phase两段集合set), 其每个条目能被增加或可选移除,但是不会在其后再次增加
U-Set, (unique set). 2P-Set的简化。
Last-Writer-Wins element Set, 元素条目是有时间戳,有add-set 和 remove-set
PN-Set 为每个元素保留计数器
Observed-Remove Set
Riak以及Akka都有支持CRDT数据结构的工具包[6][7]。
复制的话题非常广泛,几乎涵盖了分布式系统设计的每个方面,下次本号再次涉及该话题时,将重点讲述复制状态机在新型数据库中的具体设计。
[1] http://www.infoq.com/cn/news/2015/09/BookKeeper-Twitter
[2] https://aphyr.com/posts/328-call-me-maybe-percona-xtradb-cluster
[3] http://pbs.cs.berkeley.edu/ Probabilistically Bounded Stalenessfor Practical Partial Quorums
[4] http://www.gpfeng.com/?p=603
[5] A Comprehensive Study of Convergent and Commutative Replicated Data Types
[6] http://docs.basho.com/riak/latest/theory/concepts/crdts
[7] https://github.com/jboner/akka-crdt
本文为头条号作者发布,不代表今日头条立场。