HEVC学习_HEVC框架了解
边看边写吧,总觉得看完就忘,什么都有印象但什么都不清楚,总结一点是一点..现在还是一团糟的状态,随时更新吧...

HEVC采用的是混合编码结构,总体来说就是预测、变换编码和熵编码。预测分为帧内和帧间,根据预测结束之后把残差量化然后变换编码,然后用熵编码来节省码率,帧内预测是按左、上、右上的相邻块来预测,帧间预测需要运动估计。使用了环路滤波,和自适应上下文的编码方法。运用了并行处理。
帧的分块使用四叉树结构,最大分块可以是64*64,然后依次按四叉树的规则划分,图像细节越多的部分需要分得越小,最小可至4*4。一个视频图像首先分块,成为编码树单元CTUs(即以前标准中的宏块),然后CTU划分为CU,CU即编码单元,一个CU中的区域共享同样的预测模式(CU可以被看做是CTU的四叉树叶子节点)。PU即预测单元,同个PU中的区域共享同样的预测信息。TU则是变换单元,同个PU中的区域共享同样的变换和量化。
帧内预测共有35中预测模式,包括33个预测方向和DC、平面预测模式。另外,基于上下文的平滑方法也被用于提高预测效率。
帧间预测则是计算运动估计,找出最佳运动估计系数,由Merge模式和可调整的运动矢量预测模式编码(这些方法都有一些候选对象可供挑选)。为了提升运动估计的效率,采用了一个非级联模式的FIR滤波器。采用7抽头或8抽头系数的滤波器对半像素精度或1/4像素精度的亮度像素进行差值,4抽头系数的滤波器对色度像素进行插值。
残差在空间域进行量化和变换,使用DCT变换和蝶形运算提高效率,共有52个等级的量化步长。【重建图像待补充】
CTU:即宏块,由一系列N*N的亮度块和相应的色度块组成,最大尺寸为64*64,
片:一系列CTU组成了片,在一幅图像中,片可以独立于其他片进行解码,也就是说片是一个独立的编码单元。片的最大尺寸可以为整幅图像,但值得注意的是片不一定是矩形。片可以进行分割,片分割有独立的分割片和非独立的分割片。独立的片分割在头部句法中不提及前面的片分割,非独立则相反,在解码时需要依靠其他分割。,在预测时,可以跨越非独立的片分割,使用同一种预测方式,熵编码也不一定要从非独立的片分割的解析过程头部开始。
tile包括一定个数CTU,tile中CTU的排列顺序有raster scan的扫描顺序决定?raster scan 按CTU的分行逐行扫描。 tile可能包含不止一个片中的CTU,相似地,一个片中也包含在不同tile中的CTU
CU:CTU的叶子节点,一个CU中的像素使用同种预测模式(帧内、帧间、skip),CU最大可等于一个CTU,最小可为8*8。非skip模式的CU可以用帧内或帧间方式预测,而skip模式即不采用运动估计和残差信息的帧间模式。CU一定是正方形,划分深度由代价决定,划分到规定的最大深度为止(不一定达到最大深度5,一般为3)。
PU:PU由CU分割,为了贴近真实边界,PU不一定是正方形,可以采取不等分割(在帧间预测中),在帧内预测则是正方形,且有35种预测方向,包括DC和平面。总的来说,CU的大小可以从64*64~4*4,但是为了减少运动补偿的内存带宽,所以4*4分割不用于帧间预测中的PU划分。
TU:TU的结构由CU的另一棵四叉树划分而来,TU一定是方形的,因为TU是量化和变换的单元,它所得到的系数要做DCT变换或哈达玛变换,这就决定了它必须是一个N*N的矩阵。TU的最大划分深度也由头部的句法元素指定。在决定PU的划分时,要计算该划分所对应的TU的计算代价,选取最小的划分,因此TU可作为判断PU划分的依据,一旦PU划分确定,相应的TU也就得到了。在帧间预测中,TU可以大于PU,但是在帧内预测中TU一定小于PU。
帧内预测:
空间预测中,帧内预测依靠该块相邻的已解码的块作为参考数据。所以TU和一个PU使用一样的帧内预测模式对亮度与色度进行预测。对于亮度,编码器会遍历35种预测模式的代价来选择最好的预测方式。对于色度来说,编码器会在5中预测方式中选择,分别为DC、平面、水平、垂直和对于亮度块的预测方式。
亮度:(图)
色度:
| intra_chroma_pred_mode (帧内预测模式) |
Intra prediction direction(预测方向) |
||||
| 0 |
26 |
10 |
1 |
X ( 0 <= X <= 34 ) |
|
| 0 |
34 |
0 |
0 |
0 |
0 |
| 1 |
26 |
34 |
26 |
26 |
26 |
| 2 |
10 |
10 |
34 |
10 |
10 |
| 3 |
1 |
1 |
1 |
34 |
1 |
| 4 |
0 |
26 |
10 |
1 |
X |
用于预测的相邻块在被使用之前必须经过滤波,滤波强度是由帧内预测的模式和块的大小(需变换的块?)决定的,当预测模式为DC或者块的大小是4*4(此处的块是TU?)时,相邻块就不需滤波。如果给定的帧内预测模式和纵向模式(或横向模式)之间的距离小于预定义的阈值时(?),滤波处理就会被启用。阈值的设定依据是变换块的大小,
|
|
nT = 8 |
nT = 16 |
nT = 32 |
| Threshold |
7 |
1 |
0 |
1.strong_intra_smoothing_enable_flagis 被置为1(允许帧内强平滑)
2.变换块的大小为32*32
3.Abs(p[ −1 ][ −1 ] + p[ nT*2−1 ][ −1 ] – 2*p[ nT−1 ][ −1 ] ) < (1 << (BitDepthY − 5 ))[1,2,1]滤波器不适用?
4. Abs( p[ −1 ][ −1 ] + p[ −1 ][ nT*2−1 ] –2*p[ −1 ][ nT−1 ] ) < (1 << ( BitDepthY − 5 ))
帧间预测:
每个按帧间预测方式编码的PU都有一组运动矢量估计和参考图像索引,及用于帧间预测样本产生的参考图像列表的使用标志(有显式和隐式两种表示方式)。当CU用skip模式编码时,CU相当于一个没有明显变换参数的PU,该PU的运动矢量估计和参考图像索引、参考图像列表使用标志都包含于Merge模式。采用Merge模式的目的是寻找运动矢量、参考图像索引和参考图像列表标志能被当前块参考的相邻块(该块的预测方式也必须为帧间预测)。编码器可以在由时域与空域的相邻PU组成的多个候选中选择最佳参考运动系数并发送相应指向该候选的索引。当然,Merge模式可以用于帧间预测的所有情况,并不仅仅限于skip模式。对于任意帧间编码的PU,编码器可以使用Merge模式或者运动系数的显式传输(运动矢量、每个参考图像列表对于的参考图像索引和参考图像列表使用标志对每个PU都是显式可见的。)
Merge模式候选的推导:

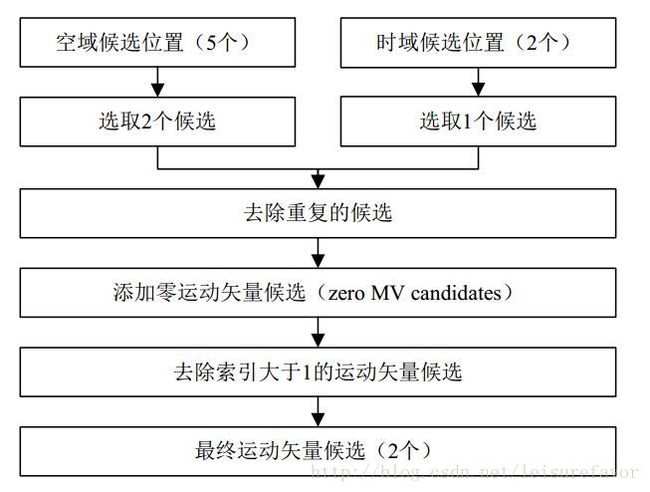
上图的流程如下:
Merge模式的候选有两个来源:
1. 空域有5个候选位置,从这5个位置中选取4个候选,选取的方法是删除与前一个候选具有相同运动信息的位置(顺序见下图。若每个位置都不同?),在同一合并估计区域的点也会被移除,这样的目的是是平行合并处理能顺利进行。由两个2N*N合并而成的位置也会被删除(此为分割冗余)。
2. 时域有2个候选位置,从这2个位置中选取1个候选。(选取规则?)
时域和空域的候选产生之后,如果候选数量未达到解码端规定的PU必须的最大候选数量(该值在片头规定),就会增加一些额外的候选。对于B片来说,双向预测的候选是从时域和空域的候选列表中得出的,对于B片和P片来说,零融合候选被加在候选列表的最后。在挑选候选的过程中,一旦候选数量达到最大候选数量(一般为5),这个过程立即停止。确定了候选之后,最佳合并候选的索引就会被TU(truncated unary?)编码。若CU的大小为8,对当前CU的PU都使用同一个merge候选列表(与2N*2N的候选列表相同)。
在推导空域融合候选的过程中,最多4个候选从图中所标示的位置中选出:
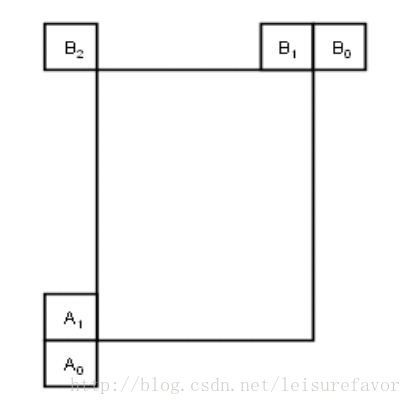
选择顺序为A1→B1→B0 →A0 →(B2)。B2位置仅在A1、B1、B0和A0等位置不可用或者为帧内编码时考虑。
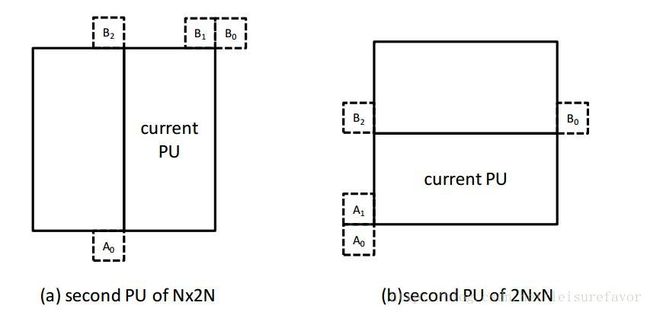
对于N×2N,nL×2N和nR×2N等分割情况下的第二个PU来说,A1位置不予考虑。在这类情况下,推导的顺序为B1 → B0 → A0 →B2。
类似的,对于2N×N,2N×nU和2N×nD等分割情况,B1位置不予考虑:A1→ B0 → A0→B2。
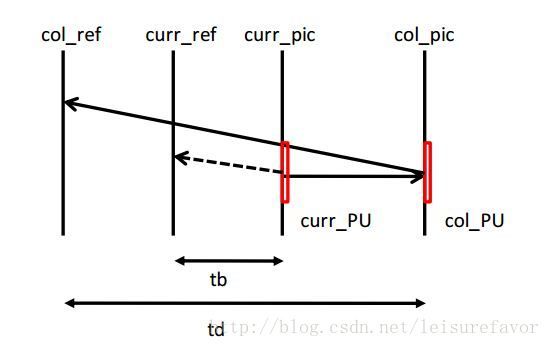
时域候选(不大清楚,待查阅):
在时域融合候选的推导过程中,缩放运动矢量基于给定的参考帧列表(reference picture list)中的具有最小POC(图像序列号)差的两个图像的相同位置(co-located)的PU得出,其中的参考帧列表在slice头中标出(在参考帧列表里寻找与当前帧POC差最小的参考帧,然后看该参考帧该PU的预测信息?)。时域融合候选的缩放运动矢量在下图中以虚线标出,由相同位置PU的运动矢量经由tb和td的缩放产生。tb定义为当前帧和当前帧的参考图像的POC差(即前面所得到的最小差),td定义为相同位置PU所在帧和其参考帧的POC差(参考帧与它的参考帧?)。时域融合候选的参考帧索引设置为A1位置的PU的参考帧索引。如果A1位置的PU不可用或者为帧内编码,则参考帧索引设为0。对于B slice,reference picture list 0的运动矢量和reference picture list 1的运动矢量合并成为双向预测运动融合候选:
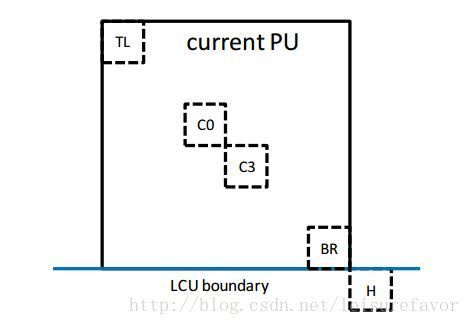
相同位置PU是从C3和H这两个位置中选出的,如下图所示。如果H位置的PU不可用或者帧内编码,又或者超出LCU界限,则使用C3位置的PU。否则,H位置用于推导时域融合候选:
其他候选:双向预测Merge候选和零融合候选。双向预测Merge候选从时空域产生,仅用于B片。For example, two candidates in the original merge candidate list, which have mvL0 and refIdxL0 or mvL1 and refIdxL1, are used to create a combined bi-predictive merge candidate as illustrated in Figure 3-15。这句不理解,需要回顾整理
运动矢量预测:
运动矢量预测利用了相邻PU的运动矢量的空域—时域相关性。为得到运动矢量候选列表(motion vector candidate list),首先检查左侧和上侧的时域相邻PU位置的可用性,然后去除重复的候选,最后加入零矢量使得候选列表为恒定长度。然后,编码器可以从中选出最好的预测,并传递相应的索引。具体过程如下:
运动矢量预测中包含两种候选:空域运动矢量候选和时域运动矢量候选。在空域运动矢量候选的推导中,从5个不同位置的PU的运动矢量中得出2个运动矢量候选。其中,一个运动矢量候选利用当前PU的左侧PU得出,另外一个运动矢量候选从当前PU的上侧PU得出。在时域运动矢量候选的推导中,从2个相同位置的PU(two different co-located positions)的运动矢量中,得到1个运动矢量候选。在初步的空域—时域候选列表出来后,去除其中重复的运动矢量候选。如果候选数目大于2,那么索引大于1的运动矢量候选被从列表中移除(当两个空域候选都有效时,不需要选择时域候选)。如果空域—时域运动矢量候选数目小于2,那么再加上一个零运动矢量候选。
空域运动矢量候选:
在推导空域运动矢量候选的过程中,从图2-8所示的5个PU位置的运动矢量候选中最多选出2个,运动矢量预测的候选位置和运动融合的候选位置相同。当前PU左侧的顺序为A0 → A1 → 缩放的 A0 → 缩放的 A1,上侧的顺序为B0→ B1 → B2 → 缩放的 B0 → 缩放的 B1 → 缩放的 B2。对每一侧,有4种情况可用于运动矢量候选,有2种情况不需要做空域缩放,而另外2种则需要。以下为4中情况的说明:
- 无需空域缩放
1. 相同的参考帧列表和相同的参考帧索引(相同POC)
2. 不同参考帧列表,但相同参考帧(相同POC)
- 空域缩放
3. 相同参考帧列表,但不同参考帧(不同POC)
4. 不同参考帧列表,不同的参考帧(不同POC)
首先检查不需空域缩放的情况,然后检查空域缩放的情况。空域缩放是指不考虑参考帧列表,邻近PU的参考帧和当前PU的参考帧之间的POC的不同。如果左侧候选的所有PU不可用或帧内编码,上侧运动矢量的缩放是允许的,用来帮助左侧和上侧的运动矢量候选的并行推导。否则,上侧运动矢量的空域缩放是不允许的。
在空域缩放过程中,相邻PU的运动矢量的缩放同时域缩放手段类似。主要区别在于参考帧列表和当前PU的索引是作为输入给定的,实际缩放过程同时域缩放相同。
时域运动矢量候选:
与时域融合候选的过程相似,除了参考帧索引的推导不同。参考帧索引发送到解码端。
插值滤波:
亮度像素的插值滤波应用一个8抽头的滤波器来进行1/2像素精度的滤波,用一个7抽头的滤波器进行1/4像素精度的滤波。同样地,一个4抽头基于DCT变换的4抽头插值滤波器被用于1/8精度色度滤波。对于双向预测来说,无论源比特精度的深度是多少,在平均两个预测信号之前,滤波器的输出比特深度一直保持在14比特的精度。实际的平均化处理与所述比特深度还原过程以如下方式隐式完成:
predSamples[ x, y ] =( predSamplesL0[ x, y ] + predSamplesL1[ x, y ] + offset ) >> shift
where shift =( 15 – BitDepth ) and offset =1 << ( shift – 1 )
加权预测:不大理解,待阅读补充
变换和量化:
若不采用无损模式和transform skip模式,缩放量化过程在解码端如下图所示:
![]()
transform skip模式:
![]()
无损模式: r[ x ][ y ] =TransCoeffLevel[ x ][ y ]
变换矩阵:DCT和哈达玛矩阵。采用蝶形运算。
二维逆变换、DST、TS、缩放量化公式具体参考文献。
熵编码:CABAC,与AVC里的基本相似,细节上略有不同,所需的参考更少,但压缩性能与传输速率有所提高。
CABAC的三个步骤:
1.二进制转换:把非二进制语法元素唯一映射到一个二进制码字
2.上下文建模:利用已编码的符号为语法元素选择合适的上下文模型并自动更新概率模型
3基于表格的算术编码:利用查表的方式进行算术编码,有效地避免了乘法运算
环路滤波:
HEVC在环路滤波里设置了两个步骤:去方块滤波和SAO滤波(样点自适应偏移)。去方块滤波的作用是减小方块效应,仅用于方块的边界。SAO的作用是提高重建信号的准确度,应用于所有样本,它的原理是将一个由编码器规定的(查表得到)偏移值有条件地加到每个样本上。
去方块滤波:
滤波过程对于每个CU都一样,先对垂直边缘进行水平滤波,再对水平边缘进行垂直滤波,而且滤波的块一定是8*8,4*4的块不进行去方块滤波(为了降低复杂度,此处与AVC不同)。滤波分为不滤波(边界强度为0)、弱滤波(边界强度为1)和强滤波(边界强度为2),取决于边界效应强度(Bs)和阈值(β和tc)。
既然是对边界进行滤波,就要先找到边界:边界包含PU和TU的边界(CU的边界一定包括在其中),当PU的大小是2NxN(N大于4,一定是4*8以上的尺寸)时且RQT(Residual Quad-tree Transform,一种自适应技术,允许块的大小根据预测残差的特性进行自适应调整,是对AVC中ABT的改进)深度为1(即不进行继续划分)时,8*8大小的TU边界和在CU内部的PU边界都会进行边界滤波。
假设P和Q为需要进行滤波的块,P为左边或上面的块,Q为右边或上面的块(滤PQ的边界),Bs的值会根据P和Q的不同情况得出:
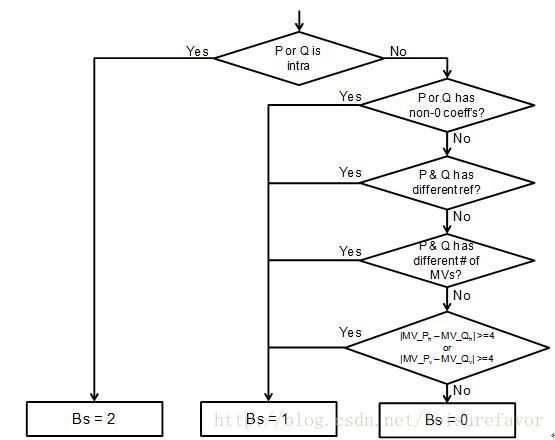
Bs是在4*4的块上计算的,但计算完成后要映射到8*8的网格中,选取的方法是在4*4的块中选Bs最大的一个值,这个值对应的4*4块中的那一行映射到8*8块即为8*8块的边界(The maximum of the twovalues of Bs which correspond to 8 pixels consisting of a line in the 4x4 gridis selected as the Bs for boundaries in the 8x8 grid. )
在CTU的边界上,P或Q的信息可以重复使用,具体如下图:
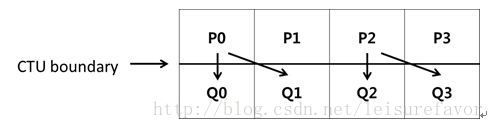
对于Q0来说,P0为上面的块,而对于Q1来说,P0为左边的块,所以可以重复利用,减少内存缓存需求。
阈值β和tc是由β‘和tc‘计算得出的,而β‘和tc‘由Q的亮度变换系数得出,有表可以查询。
在8*8的块中,块被分为两个4行的单元,如下图:
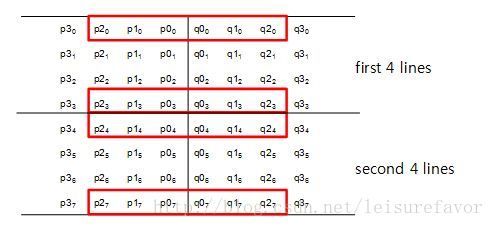
第一个四行两个红框中的像素决定是否对第一个四行进行滤波,第二个四行同理,计算公式为:
dp0 = | p2,0 – 2*p1,0 + p0,0 |
dp3 = | p2,3 – 2*p1,3 + p0,3 |
dq0 = | q2,0 – 2*q1,0 + q0,0 |
dq3 = | q2,3 – 2*q1,3 + q0,3 |
If dp0+dq0+dp3+dq3 < β, 滤波开启 ,强/弱滤波选择进程也开始进行,反之则不滤波。另外,变量dE,dEp1和dEp2也受此关系影响(这几个值有什么用尚不明确):
If dp0 + dp3 < (β + ( β >> 1 )) >> 3, the variable dEp1 is set equal to 1
If dq0 + dq3 < (β + ( β >> 1 )) >> 3, the variable dEq1 is set equal to 1
确定滤波开启之后,进行强滤波或者弱滤波的判断,判断依据仍为上面所用的像素点,判断条件为:
1) 2*(dp0+dq0) <( β >> 2 ), | p30 – p00 | + | q00 – q30 |< ( β >> 3 ) and | p00 – q00 |< ( 5* tC + 1 ) >> 1
2) 2*(dp3+dq3) <( β >> 2 ), | p33 – p03 | + | q03 – q33 |< ( β >> 3 ) and | p03 – q03 |< ( 5* tC + 1 ) >> 1
两个条件都达到则为强滤波,否则为弱滤波。强滤波:滤波后的像素值用如下算式计算(计算时从判断用的P、Q各3个像素增为4个像素)
p0’ = ( p2 + 2*p1 + 2*p0 + 2*q0 + q1 + 4 ) >> 3
q0’ = ( p1 + 2*p0 + 2*q0 + 2*q1 + q2 + 4 ) >> 3
p1’ = ( p2 + p1 + p0 + q0 + 2 ) >> 2
q1’ = ( p0 + q0 + q1 + q2 + 2 ) >> 2
p2’ = ( 2*p3 + 3*p2 + p1 + p0 + q0 + 4 ) >> 3
q2’ = ( p0 + q0 + q1 + 3*q2 + 2*q3 + 4 ) >> 3
弱滤波:不贴公式了,算法去标准里找。
色度滤波:继承亮度滤波的Bs,Bs>1时进行滤波。
SAO(Sample Adaptive Offset):
http://blog.sina.com.cn/s/blog_4ae178ba0101814r.html这篇文章说得很详尽。
主要应用于重构图像。把Frame划分为若干LCU, 然后对每个LCU中每个像素进行SAO操作,将根据其LCU像素特征选择一种像素补偿方式,以减少源图像与重构图像之间的失真。编码器先判断是否需要进行SAO补偿,然后选择SAO的类型(5选1)。。每个可应用SAO操作的CTB都有SAO参数,包括sao_merge_left_flag(=1时,将当前CTB的SAO type和offsets都应用于左边的块),sao_merge_up_flag(与左同理,应用于上边块), SAO type and four offsets.
自适应样点补偿方式分为带状补偿(Band Offset,BO)和边缘补偿(Edge Offset,EO)两大类。
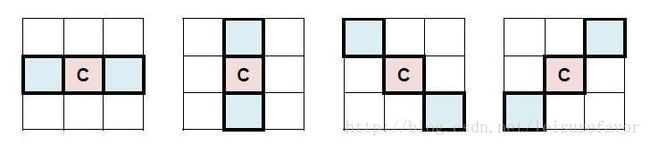
带状补偿将像素值强度等级划分为若干个条带,每个条带内的像素拥有相同的补偿值。进行补偿时根据重构像素点所处的条带,选择相应的带状补偿值进行补偿。边缘补偿主要用于对图像的轮廓进行补偿。它将当前像素点值与相邻的2个像素值进行对比,用于比较的2个相邻像素可以在下图中所示的4种模板中选择(选择标准?),从而得到该像素点的类型。解码端根据码流中标示的像素点的类型信息进行相应的补偿校正。
WPP:主要用于熵编码。当WPP开启时,片先被分成数个CTU行。第一行正常处理,第二行在第一行处理完2个CTU后开始处理,第三行在第二行处理完2个CTU后开始处理。每一行相对前一行都有2个CTU的延迟。WPP提供了一种在适当的层级上(比如说片)并行化的方式。WPP可以提供比并行块更好的压缩效率,而且不会引入块效应。