基于深度学习的驾驶行为预测方法
基于深度学习的驾驶行为预测方法
- 1 概述
- 2 深度学习算法
- 3 驾驶行为预测建模
- 4 结论
- 5 参考文献
- 6 python LSTM程序
- 7 python LSTM模型调用
1 概述
在汽车前向仿真中会用到纵向驾驶员模型,根据当前的实际车速与目标车速控制踏板行程得到需求转矩。纵向驾驶员模型的作用除了更好地跟踪目标工况,还要反映驾驶员的实际操纵行为,从而使整车仿真模型能更好地反映实车的运行特征[1]。对驾驶员操纵行为的预测难于用简单的公式来描述,如果有大量的路谱数据,包括实车行驶过程的海拔、车速、发动机转速、油门开度等信息,可以用机器学习算法获得驾驶员的行为预测模型,根据历史路谱数据对下一时刻的油门等进行预测。
机器学习就是把无序的数据转换成有用的信息[2],机器学习的算法有很多,比如K-近邻算法、朴素贝叶斯算法、支持向量机、决策树、神经网络、深度学习等。选择什么样的算法取决于任务和数据,对于驾驶行为预测,采用深度学习中的长短时记忆网络(long short-term meory,LSTM)特别合适。LSTM网络是循环神经网络中的一个重要结构[3],特别适合处理和预测时序数据。
2 深度学习算法
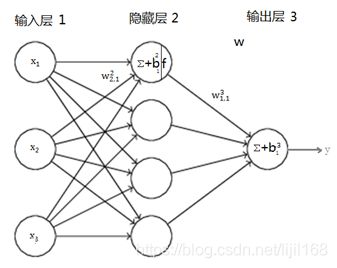
深度学习源自“古老”的神经网络技术,目前大家所熟知的“深度学习”基本上是深层神经网络的一个代名词[3]。神经网络本质上是基于数据的建模方法,对一个如图1所示的系统,输入为变量X,输出为变量Y,假如有m个样本(Xi,Yi),i=1到m,我们可以用待定系数W构造一个函数f,用于表示从变量X到变量Y之间的变换关系,将Xi代入f可以得到预测的输出Yi‘,即Yi‘=f(W,Xi),样本结果Yi与预测结果Yi‘之差为预测的残差ei,即ei=Yi- Yi‘= Yi- f(W,Xi),显然,残差越小则表示我们预测的越准确,也就是我们构造的函数f越接近于真实的系统模型。残差是自变量为待定系数W的函数ei= Yi- f(W,Xi),因为Xi和Yi已知。考虑到要尽可能使所有的残差都最小,我们需要构造另一个关于W的函数,通常被称为损失函数(也有叫惩罚函数的),常用的是均方差损失函数,即所有残差的均方,![]()
,显然,损失函数值越小越好,对损失函数求极小值,就可得到最优的W,从而得到最优的预测函数f。神经网络有很多种结构,其目的都是为了构造合适的函数,通过网络中各层的神经元实现X到Y的变换。


如何求损失函数的极小值呢,最常用的方法是梯度下降法[4],打个比方,假如我们优化的函数就象个山坡,求山坡的最低位置就是我们优化的目标,当我们从山坡上下山去寻找最低点时,首先要考虑的是下山的方向,最陡的方向是下山最快的方向,也就是函数梯度下降的方向,梯度下降法就是先求得函数的梯度,然后沿梯度下降的方向调整权重和偏置,更新网络权重和偏置后,再进行下一步优化计算,直到得到最优的权重和偏置。
损失函数的梯度为损失函数的偏导数组成的向量,当网络较深,单元数较多时,权重和偏置的数量很多,求损失函数的所有偏导数十分困难,对这种问题,误差反向传播算法(Error Back Propagation,简称BP)具有重大的意义,BP算法由Verbos在1974年首先提出,此后由Rumelhart等在1986年重新发明,掀起了神经网络的第二次高潮[4],直到今天,BP算法仍是神经网络的最重要算法[5]。下面以图2所示的神经网络为例来探讨BP算法是如何工作的,定义l层第k个神经元的误差[5]为



可见,损失函数对神经元权重的偏导数等于神经元的误差与上一层输入信号的乘积。
公式(6)、(10)、(11)、(12)就是BP算法的四个公式,根据公式(6)得到输出层的神经元的误差,根据公式(10)将输出层的误差反向传播得到所有神经元的误差,再根据公式(11)(12)根据神经元的误差得到损失函数对偏置和权重的偏导数,进而求得损失函数的梯度。
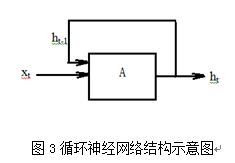
图2所示的神经网络两相邻层间所有神经元全部相连,称为全连接网络,因为信号只能从输入层向隐藏层再向输出层传播,所以又称为前向网络,这种网络如果直接采用多隐层构造深度学习的网络,则难于直接用经典算法(例如标准BP算法)进行训练,因为误差在多隐层内反向传播时,往往会“发散”(diverge)而不能收敛到稳定状态[4]。考虑到驾驶行为预测依据的路谱数据是一时序数据,采用深度学习网络中的循环神经网络(Recurrent Neural Network,RNN)比较合适,与前向网络相比,RNN仅仅神经元结构不同,如图3所示,神经元的输出会增加到下一时刻的输入,这样t时刻的信息可能传播到很远,即组成很深的神经网络,但由于各时刻的神经元共用权重及偏置,网络可以采用BP算法进行训练。
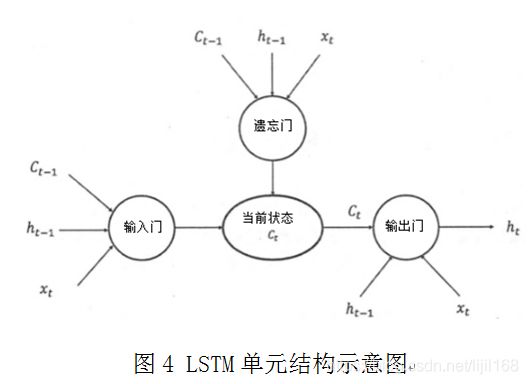
循环神经网络可以更好地利用传统神经网络结构所不能建模的信息,但同时,也带来了更大的技术挑战——长期依赖问题,在很多的任务上,采用LSTM结构的循环神经网络比标准的神经网络表现更好,它采用三“门”的特殊网络结构,如图4所示[3]。
3 驾驶行为预测建模
基于Tensorflow深度学习框架,利用Python编程,建立驾驶行为预测的LSTM网络模型。首先,整理路谱数据,含海拔、车速、发动机转速、油门开度,并进行归一化处理,结果如图5所示,把数据分成两部分,一部分用于训练模型,一部分用于测试模型。
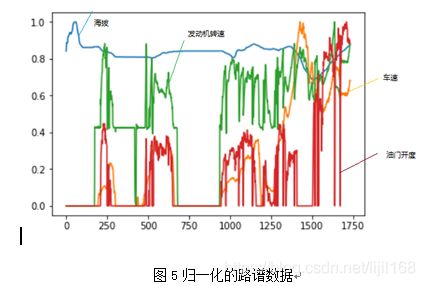
建立LSTM网络模型,采用一个LSTM神经元,含256个隐藏单元,将前28个时刻的路谱数据作为输入,下一个时刻的油门开度作为输出,采用均方误差做损失函数,用训练数据进行100轮训练后,用训练数据进行测试,预测的油门开度和实际的油门开度见图,6,两者吻合的较好。然后用测试数据进行测试,结果见图7,两者吻合的也较好,但是在大油门开度情况下,偏差相对较大,观察图5所示的路谱数据,大油门的路谱数据量很少,对损失函数的贡献较小,所以对大油门的学习情况相对较差。
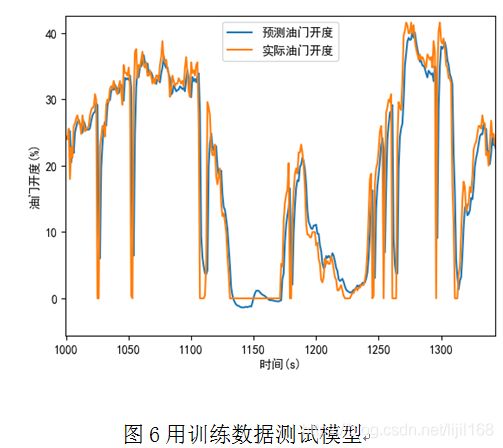
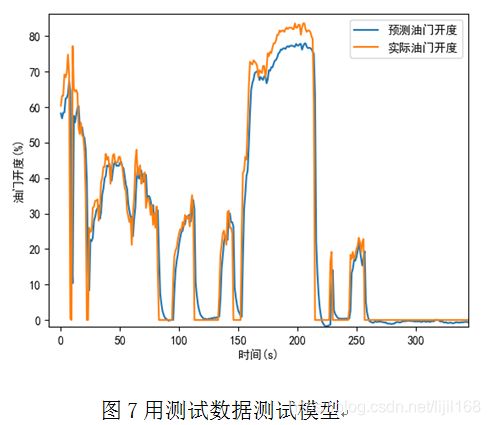
4 结论
本文对神经网络的前向传播和误差反向传播算法进行了详细的推导,针对驾驶行为预测问题建立了LSTM网络模型,并用训练数据和测试数据对训练好的模型进行了测试,预测的油门开度和实际的油门开度吻合的较好,表明用深度学习实现驾驶行为预测是可行的,这为下一步进行更深入的研究打下了一定的基础。
5 参考文献
1 沈沛鸿、赵治国、郭秋伊.基于ANFIS的工况跟踪用驾驶员模型开发.汽车工程.2019.07
2 Peter Harrington著、李锐 李鹏、曲亚东译.机器学习实战.人民邮电出版社. 2013.6
3 郑泽宇、粱博文、顾思宇.TensorFlow:实战Google深度学习框架.电子工业出版社.2018.2
4 周志华.机器学习. 清华大学出版社.2016
5 Michael Nielsen.Neural Networks and Deep Learning.neuralnetworksanddeeplearning.com.
6 python LSTM程序
# coding=utf-8
import os
os.environ["TF_CPP_MIN_LOG_LEVEL"]='2' # ֻ��ʾ warning �� Error
###data (30000,4),(1000,4),(1000,4):
import numpy as np
import tensorflow as tf
from tensorflow.contrib import rnn
import pandas as pd
#define constants
#28个时间步,根据前28个时刻的输入路谱预测下一时刻的油门:
TIME_STEPS=28
#hidden LSTM units
NUM_HIDDEN=20
#输入4个特征:
NUM_INPUT=4
#learning rate for adam
LEARNING_RATE=0.001
#输出一个特征,下一时刻的油门:
NUM_OUTPUT=1
#size of batch
BATCH_SIZE=256
TRAINING_EPOCHS=100#
#从路谱中截取一系列TIME_STEPS=28个值作为训练的样本::
#X (:,28,4);
#y (:,1)
def generate_data(seq):
X=[]
y=[]
for i in range(len(seq)-TIME_STEPS):
X.append(seq[i:i+TIME_STEPS,:])
y.append([seq[i+TIME_STEPS,-1]])
return np.array(X,dtype=np.float32),np.array(y,dtype=np.float32)
#seq[i:i+TIME_STEPS,:]是二维数组,不用再在外面加【】
#seq[i+TIME_STEPS,-1]是0维数组=值,需要在外面加【】变成一维表
###:文件数据处理:
H_V_n_a_MAX=[433.15,75.246,1764.25,100.]
file_path = r'C:\Users\li\workspace\temp\e\ttt\data.xlsx'
dataFrame = pd.read_excel(file_path)
data=dataFrame.values[:,1:] #二维数组
#数据归一化:
data=data/H_V_n_a_MAX
#trainData_in (:,28,4);
#trainData_out (:,1)
trainData_in,trainData_out=generate_data(data)
#weights and biases of appropriate shape to accomplish above task
#out_weights=tf.Variable(tf.random_normal([NUM_HIDDEN,NUM_OURPUT]))
#双向神经网络的权重为单向的2倍尺度:
out_weights=tf.Variable(tf.random_normal([2*NUM_HIDDEN,NUM_OUTPUT]))
out_bias=tf.Variable(tf.random_normal([NUM_OUTPUT]))
#defining placeholders
#input image placeholder:
x_input=tf.placeholder("float",[None,TIME_STEPS,NUM_INPUT],name='x_input')
#input label placeholder:
y_desired=tf.placeholder("float",[None,NUM_OUTPUT])
#processing the input tensor from [BATCH_SIZE,NUM_STEPS,NUM_INPUT] to "TIME_STEPS" number of [BATCH-SIZE,NUM_INPUT] tensors!:
#对输入的一个张量的第二维解包变成TIME_STEPS个张量!:
x_input_step=tf.unstack(x_input ,TIME_STEPS,1)
#defining the network:
#def BiRNN(x_input_step,out_weights,out_bias):
#lstm_layer=rnn.BasicLSTMCell(NUM_HIDDEN,forget_bias=1.0)
#正向神经元:
lstm_fw_cell=rnn.BasicLSTMCell(NUM_HIDDEN,forget_bias=1.0)
#反向神经元:
lstm_bw_cell=rnn.BasicLSTMCell(NUM_HIDDEN,forget_bias=1.0)
#outputs,_=rnn.static_rnn(lstm_layer,x_input_step,dtype="float32")
#构建双向LSTM网络:
outputs,_,_=rnn.static_bidirectional_rnn( lstm_fw_cell,lstm_bw_cell,x_input_step,dtype="float32")
#converting last output of dimension [batch_size,num_hidden] to [batch_size,num_classes] by out_weight multiplication
z_prediction= tf.add(tf.matmul(outputs[-1],out_weights),out_bias,name='y_output')
#z_prediction=BiRNN(x_input_step, out_weights, out_bias)
#注意!z_prediction经softmax归一化后才是最终的输出,用于和标签比较,下面的损失函数中用了softmax哈交叉熵,跳过了求y_output这一步:
#y_output=tf.nn.softmax(z_prediction,name='y_output')
#loss_function:
#loss=tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits_v2(logits=z_prediction,labels=y_desired),name='loss')
loss=tf.losses.mean_squared_error(labels=y_desired,predictions=z_prediction)
#optimization
opt=tf.train.AdamOptimizer(learning_rate=LEARNING_RATE).minimize(loss)
#model evaluation
#correct_prediction=tf.equal(tf.argmax(z_prediction,1),tf.argmax(y_desired,1))
#accuracy=tf.reduce_mean(tf.cast(correct_prediction,tf.float32))
#以下汇总一些参数用于TensorBoard:
for value in [loss]:
tf.summary.scalar(value.op.name,value) #汇总的标签及值
summary_op=tf.summary.merge_all() #汇总合并
#initialize variables:
init=tf.global_variables_initializer()
with tf.Session() as sess:
# 生成一个写日志的writer,并将当前的tensorflow计算图写入日志。
# tensorflow提供了多种写日志文件的API
summary_writer=tf.summary.FileWriter(r'C:\temp\log_simple_stats',sess.graph)
sess.run(init)
num_batches=int(len(trainData_in)/BATCH_SIZE)
for epoch in range(TRAINING_EPOCHS):
for i in range(num_batches):
batch_x=trainData_in[i*BATCH_SIZE:(i+1)*BATCH_SIZE]
batch_x=batch_x.reshape((BATCH_SIZE,TIME_STEPS,NUM_INPUT))#
batch_y=trainData_out[i*BATCH_SIZE:(i+1)*BATCH_SIZE]
#优化及日志结果!!!!!!:::::
_,summary=sess.run([opt,summary_op], feed_dict={x_input: batch_x, y_desired: batch_y})
#写日志,将结果添加到汇总:
summary_writer.add_summary(summary,global_step=epoch*num_batches+i)
if i %10==0:
#acc=sess.run(accuracy,feed_dict={x_input:batch_x,y_desired:batch_y})
los=sess.run(loss,feed_dict={x_input:batch_x,y_desired:batch_y})
print('epoch:%4d,'%epoch,'%4d'%i)
#print("Accuracy ",acc)
print("Loss ",los)
print("__________________")
print("Finished!")
#print("Test Accuracy ",sess.run(accuracy,\
# feed_dict={x_input:testData_in.reshape((-1,TIME_STEPS,NUM_INPUT)),\
# y_desired:testData_out}))
saver=tf.train.Saver()
save_path=saver.save(sess,'../data')
print('Model saved to %s' % save_path)
summary_writer.close()
7 python LSTM模型调用
# coding=utf-8
import os
os.environ["TF_CPP_MIN_LOG_LEVEL"]='2' # ֻ��ʾ warning �� Error
###data (30000,4),(1000,4),(1000,4):
import numpy as np
import tensorflow as tf
import pandas as pd
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif']=['SimHei'] #用来正常显示中文标签
plt.rcParams['axes.unicode_minus']=False #用来正常显示负号
TIME_STEPS=28
NUM_INPUT=4
#从路谱中截取一系列TIME_STEPS=28个值作为训练的样本::
#X (:,28,4);
#y (:,1)
def generate_data(seq):
X=[]
y=[]
for i in range(len(seq)-TIME_STEPS):
X.append(seq[i:i+TIME_STEPS,:])
y.append([seq[i+TIME_STEPS,-1]])
return np.array(X,dtype=np.float32),np.array(y,dtype=np.float32)
#seq[i:i+TIME_STEPS,:]是二维数组,不用再在外面加【】
#seq[i+TIME_STEPS,-1]是0维数组=值,需要在外面加【】变成一维表
###:文件数据处理:
H_V_n_a_MAX=[433.15,75.246,1764.25,100.]
file_path = r'C:\Users\li\workspace\temp\e\ttt\data_temp.xlsx'
dataFrame = pd.read_excel(file_path,sheet_name=0)
data=dataFrame.values[:,1:] #二维数组
#数据归一化:
data=data/H_V_n_a_MAX
#testData_in (:,28,4);
#testData_out (:,1)
testData_in,testData_out=generate_data(data)
sess=tf.InteractiveSession()
new_saver=tf.train.import_meta_graph('../data.meta')
new_saver.restore(sess, '../data')
tf.get_default_graph().as_graph_def()
x_input=sess.graph.get_tensor_by_name('x_input:0')
y_output=sess.graph.get_tensor_by_name('y_output:0')
try_input=testData_in[:]
try_desired=testData_out[:]
print(try_desired)
try_predictions=y_output.eval(feed_dict={x_input:\
np.array([try_input]).reshape((-1,TIME_STEPS,NUM_INPUT))})
print(try_predictions)
plt.figure()
plt.plot(try_predictions*100,label=u'预测油门开度')
plt.plot(try_desired*100,label=u'实际油门开度')
plt.ylabel(u'油门开度(%)')
plt.xlabel(u'时间(s)')
plt.legend()
plt.show()