项目实例---随机森林在Kaggle实例:Titanic中的应用(一)
在前两篇文章介绍了决策树和随机森林的原理、流程和算法之后,这里将以随机森林为例,探索数据挖掘算法在项目中的应用,尤其是在kaggle项目中进行数据挖掘的一般流程。
1、分析项目背景
项目背景的熟悉对于我们理解影响分析目标的因素十分重要,甚至可以发觉一些常规资料中没有提出来的因素。
该项目的页面
泰坦尼克的沉没发生在1912年4月15日,包括海员在内,船上共2224个人,遇难1502年,幸存722人。这么多人遇难的原因之一是事故发生后船上没有足够的救生艇。事后的调查数据显示,似乎有一些类型的人幸存的可能性更大,比如妇女、孩子、上层阶级的乘客。
这个项目的目标就是通过这些调查数据,利用数据挖掘算法来建立船上人员生存概率的模型,并利用训练的模型对测试数据中乘客的生存情况进行预测(调查数据已经过处理,并分成训练集-这部分带标签,及测试集-这部分标签被抹去),提交预测结果后系统会给出预测精度。
插入点题外话:泰坦尼克上有8个中国人,其中6人生还,对比其他人这是一个极高的生还率;当时的英美媒体出于转移人们注意力的需要,强行污蔑他们是卑鄙窃取上救生艇机会的人,他们一生都被扣上“自私的种族”的帽子,这6个中国人成了英美两国家喻户晓的“丑陋人物”。中国在当时是积分积弱的国家,船上的8个人都是劳工,共用一张船票,挤在三等舱里。他们的主要工作是烧锅炉。他们怎么可能有优先上救生艇的机会?被污蔑后他们根本没有发声的机会,他们更可能连自己被污蔑都不知道,因为回国后他们就要回到当时那种水深火热的生活中去。后来的调查还原了真相,这6个中国人里,有5个是乘坐一艘已经破了的小船逃命的。当时因为这条船已经破了,人们都认为没法救命,只有这5个人在万般无奈之下想努力试一试。他们将这条破船扔下海,然后跳上去,紧紧抱住这条船,把它当成大海中的一块浮木,漂浮在大海上。幸运的是,他们终于遇上了一艘救生艇,被救了上来。而另外一个中国人,则是紧紧抱住了一块门板,直到遇上救生艇获救。本文中的主要流程及程序参考该文。
2、训练数据基本特点的统计分析
2.1样本数据初探
数据在这里,我们用到的两个文件分别是train.csv和test.csv,分别存放着训练数据集(有标签)和测试数据集(无标签)。下载数据后可以看到数据如下的样子:
| PassengerId | Survived | Pclass | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 0 | 3 | Braund, Mr. Owen Harris | male | 22 | 1 | 0 | A/5 21171 | 7.25 | S | |
| 2 | 1 | 1 | Cumings, Mrs. John Bradley (Florence Briggs Thayer) | female | 38 | 1 | 0 | PC 17599 | 71.2833 | C85 | C |
| 3 | 1 | 3 | Heikkinen, Miss. Laina | female | 26 | 0 | 0 | STON/O2. 3101282 | 7.925 | S |
训练集数据共有891个样本,测试集数据418个样本,这里测试集数据占总样本约1/3。这个比例是不固定的,建议在1/5~1/3之间;同时可以看到总共有1309个样本,而事故发生时船上共有2224人,因而不是所有人的数据都被包含进本项目中。
下面看看各特征代表的意思:
| 变量名称 | PassengerId | Survived | Pclass | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 中文翻译 | 乘客ID | 是否幸存 | 舱位等级 | 姓名 | 性别 | 年龄 | 兄弟姐妹个数 | 父母子女个数 | 船票 | 票价 | 船舱名称 | 登船港口 |
| 变量类型 | int | int | int | chr | chr | num | int | int | chr | num | chr | chr |
| 变量描述 | 按顺序编号,如1,2,3……可能是数据据录入数据库时产生的主键,无意义 | 样本标签,取0,1,0代表遇难,1代表幸存 | 舱位等级包括1,2,3级,舱位等级高舱内设施可能会更好一点,便利性可能也会更好,因而可能和幸存概率很有关系 | 姓名可能能一定程度反映出一定人的身份,身份与他的经济能力即与舱位好坏等挂钩,在发生事故后可能与受保护的程序有关,比如为社会做出特殊贡献的人先走,比如特殊人才先走 | 性别可能也与幸存率有关,社会的普遍做法是女士优先 | 年龄也可能与幸存率有关,社会普遍做法是老人小孩优先,更可能是小孩优先 | 船上兄弟姐妹的个数也可能与幸存率有关,家里独子的可能更容易获得上救生艇的机会 | 船上父母子女的个数也可能与幸存率有关,也是人多获得上救生艇机会更大,而父母一般会将机会给子女 | 船票反映出来的也是位置舱位等情况,道理是一样的 | 票价同船票和舱位等级的效果 | 船舱名称反映出的也是设施等条件,比如好的船舶可能有更便利的逃生门或者配备了更多的救生艇 | 登船港口可能也能与一个人的身份国籍等有关联进而可能与逃生率关联 |
以上便是对数据的最初步的认识,如果有兴趣可以更深入了解当时船上人员的背景信息及特征变量各类型的具体意思,比如哪个字母代表哪个港口,从这个港口一般登船的会是什么人,等等,为上表中的特征变量可能对分析目标(幸存率)的影响做支撑。
2.2各特征的基本统计分析
2.2.1 加载数据
# 加载数据
##### 加载训练和测试数据
#####--------------------------------------------------------------------------------------------------
#这里读入数据的时候我们没有做任何的处理(像去除空值这些)
train=pd.read_csv("./train.csv")
test=pd.read_csv("./test.csv")
#查看样本数和特征数
#train_num,train_var_num=np.shape(train)
#test_num,test_var_num=np.shape(test)
#print("训练集:有",train_num,"个样本","每个样本有",train_var_num,"个变量.")
#print("测试集:有",test_num,"个样本","每个样本有",test_var_num,"个变量.")
print(train.info())
print(test.info())我们可以对数据进行进一步的查看,如下:
#训练集
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 891 entries, 0 to 890
Data columns (total 12 columns):
PassengerId 891 non-null int64
Survived 891 non-null int64
Pclass 891 non-null int64
Name 891 non-null object
Sex 891 non-null object
Age 714 non-null float64
SibSp 891 non-null int64
Parch 891 non-null int64
Ticket 891 non-null object
Fare 891 non-null float64
Cabin 204 non-null object
Embarked 889 non-null object
dtypes: float64(2), int64(5), object(5)
memory usage: 83.6+ KB
None
#测试集
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 418 entries, 0 to 417
Data columns (total 11 columns):
PassengerId 418 non-null int64
Pclass 418 non-null int64
Name 418 non-null object
Sex 418 non-null object
Age 332 non-null float64
SibSp 418 non-null int64
Parch 418 non-null int64
Ticket 418 non-null object
Fare 417 non-null float64
Cabin 91 non-null object
Embarked 418 non-null object
dtypes: float64(2), int64(4), object(5)
memory usage: 36.0+ KB
None可以看到训练训练集有 891 个样本 每个样本有 12 个变量;测试集有 418 个样本 每个样本有 11 个变量。
从变量类型来有浮点型有2个,这类特征为连续型变量,后续在统计分布和缺失值的处理上与整型和符号型是不一样的;整型特征有4个、符号型有5个,这两类在统计分布和缺失值处理上大体相似。
从缺失值来看,Age和Cabin在训练集和测试集中都有较多的缺失值,而Embarked在训练集中有两个缺失值,Fare在测试集中有一个缺少值;对于缺少值的处理也有不同的方法,比如如果某一特征缺失值很多,通过初步分析又分析跟分析目标关联性不大,可以考虑剔除该特征,或者用其他与他相关的特征来代替;对于少量的连续型特征可以考虑用均值、中值代替,也可以找与它相关性很强的特征中对应样本的值来替代等方法;对于少量的离散形或符号型特征缺失值,可考虑使用出现频率最高的符号值来替代。后面在特征工程中有专门的内容来处理缺失值。
2.2.2 去除离群点
离群点对后面的数据建模有比较大的影响,尤其是在回归建模中。因而应当尽量去除数据中的离群点。
在这个项目中由于测试数据用来考核的,不能删除任何一个数据,因而我们只需要在训练集中去除离群点。
离群点的去除本身就是一个学问,有很多方法,这里只采用一种比较简单的方法,四分位极差法(比上分位小于1.5倍四分位极差或比下分位大1.5倍四分位极差则为离散点)。
去除离群点
这里选取了”Age”,”SibSp”,”ParCh”,”Fare”四个数值型变量;另一个数值型变量舱位等级没选是因为该变量只有1、2、3级不可能有离群点,其他符号型变量诸如性别、登录港口,也只有有限的类型,一般不可能离群,也没有必要分析是否离群。
#去除离群点
#####--------------------------------------------------------------------------------------------------
#离群点检测
def detect_outliers(df,n,features):
'''
输入:
df:数据框,为需要检测的样本集
n:正整数,样本特征超出四分位极差个数的上限,有这么多个特征超出则样本为离群点
features:列表,用于检测是否离群的特征
输出:
'''
outlier_indices=[]
outlier_list_col_index=pd.DataFrame()
#对每一个变量进行检测
for col in features:
#计算四分位数相关信息
Q1=np.percentile(df[col],25)
Q3=np.percentile(df[col],75)
IQR=Q3-Q1
#计算离群范围
outlier_step=1.5*IQR
#计算四分位数时如果数据上有空值,这些空值也是参与统计的,所以统计出来的Q1、Q3、IQR这些数据有可能是NAN,但是这并不要紧,在判断是否大于或小于的时候跟NAN比较一定是false,因而样本并不会因为空值而被删除掉
#空值会在后面特征工程时再做处理
#找出特征col中显示的离群样本的索引
outlier_list_col=df[(df[col]Q3+outlier_step)].index
#额外存储每一个特征在各样本中的离群判断
temp=pd.DataFrame((df[col]Q3+outlier_step),columns=[col])
#将索引添加到一个综合列表中,如果某个样本有多个特征出现离群点,则该样本的索引会多次出现在outlier_indices里
outlier_indices.extend(outlier_list_col)
#额外存储每一个特征在各样本中的离群判断,方便查看数据
outlier_list_col_index=pd.concat(objs=[outlier_list_col_index,temp],axis=1)
#选出有n个以上特征存在离群现象的样本
outlier_indices=Counter(outlier_indices)
multiple_outliers=list(k for k,v in outlier_indices.items() if v>n)
return multiple_outliers,outlier_list_col_index
#获取离群点
outliers_to_drop,outlier_col_index=detect_outliers(train,2,["Age","SibSp","Parch","Fare"])
#这里选取了"Age","SibSp","ParCh","Fare"四个数值型变量;另一个数值型变量舱位等级没选是因为该变量只有1、2、3级不可能有离群点,其他符号型变量诸如性别、登录港口,也只有有限的类型,一般不可能离群,也没有必要分析是否离群。 离群点详细信息:
print(train.loc[outliers_to_drop])
print(outlier_col_index.loc[outliers_to_drop])#查看哪个特征对样本成为离群点有决定作用.| PassengerId | Survived | Pclass | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 27 | 28 | 0 | 1 | Fortune, Mr. Charles Alexander | male | 19.0 | 3 | 2 | 19950 | 263.00 | C23 C25 C27 | S |
| 88 | 89 | 1 | 1 | Fortune, Miss. Mabel Helen | female | 23.0 | 3 | 2 | 19950 | 263.00 | C23 C25 C27 | S |
| 159 | 160 | 0 | 3 | Sage, Master. Thomas Henry | male | NaN | 8 | 2 | CA. 2343 | 69.55 | NaN | S |
| 180 | 181 | 0 | 3 | Sage, Miss. Constance Gladys | female | NaN | 8 | 2 | CA. 2343 | 69.55 | NaN | S |
| 201 | 202 | 0 | 3 | Sage, Mr. Frederick | male | NaN | 8 | 2 | CA. 2343 | 69.55 | NaN | S |
| 324 | 325 | 0 | 3 | Sage, Mr. George John Jr | male | NaN | 8 | 2 | CA. 2343 | 69.55 | NaN | S |
| 341 | 342 | 1 | 1 | Fortune, Miss. Alice Elizabeth | female | 24.0 | 3 | 2 | 19950 | 263.00 | C23 C25 C27 | S |
| 792 | 793 | 0 | 3 | Sage, Miss. Stella Anna | female | NaN | 8 | 2 | CA. 2343 | 69.55 | NaN | S |
| 846 | 847 | 0 | 3 | Sage, Mr. Douglas Bullen | male | NaN | 8 | 2 | CA. 2343 | 69.55 | NaN | S |
| 863 | 864 | 0 | 3 | Sage, Miss. Dorothy Edith “Dolly” | female | NaN | 8 | 2 | CA. 2343 | 69.55 | NaN | S |
下面对样本成为离群点的原因进行分析
| PassengerId | Age | SibSp | Parch | Fare | |
|---|---|---|---|---|---|
| 27 | 28 | False | True | True | True |
| 88 | 89 | False | True | True | True |
| 159 | 160 | False | True | True | True |
| 180 | 181 | False | True | True | True |
| 201 | 202 | False | True | True | True |
| 324 | 325 | False | True | True | True |
| 341 | 342 | False | True | True | True |
| 792 | 793 | False | True | True | True |
| 846 | 847 | False | True | True | True |
| 863 | 864 | False | True | True | True |
从上表中可以看到,在10个离群样本中,Age并不是原因,而SibSp,Parch,Fare三个特征在每一个样本中都表现出离群。详情可利用简单的统计信息查看。
print(train.describe())| PassengerId | Survived | Pclass | Age | SibSp | Parch | Fare | |
|---|---|---|---|---|---|---|---|
| count | 891.000000 | 891.000000 | 891.000000 | 714.000000 | 891.000000 | 891.000000 | 891.000000 |
| mean | 446.000000 | 0.383838 | 2.308642 | 29.699118 | 0.523008 | 0.381594 | 32.204208 |
| std | 257.353842 | 0.486592 | 0.836071 | 14.526497 | 1.102743 | 0.806057 | 49.693429 |
| min | 1.000000 | 0.000000 | 1.000000 | 0.420000 | 0.000000 | 0.000000 | 0.000000 |
| 25% | 0.000000 | 0.000000 | 2.000000 | 20.125000 | 0.000000 | 0.000000 | 7.910400 |
| 50% | 446.000000 | 0.000000 | 3.000000 | 28.000000 | 0.000000 | 0.000000 | 14.454200 |
| 75% | 668.500000 | 1.000000 | 3.000000 | 38.000000 | 1.000000 | 0.000000 | 31.000000 |
| max | 891.000000 | 1.000000 | 3.000000 | 80.000000 | 8.000000 | 6.000000 | 512.329200 |
从上表中可以看到,在训练数据中:
Survived上看,Survived只能取0、1,到中位数的时候仍然还是0,下分位数才到1,说明训练数据样本中,幸存率在1/4~1/2之间,结合均值0.383838,幸存率大概在1/3左右;
Pclass上看,Pclass只能取1、2、3级,但均值为2.308642,说明绝大数乘客为三等票,结合四位数,可知这一比例在大于5/8;
Age上看,891个样本只有714个统计数字,说明有183个缺失值;最小值是0.420000周岁,最大值是80.000000周岁,说明船上有刚出生没多久的小孩,也有年纪很大的老人;20.125000-38.000000周岁占了一半,且平均年龄是29.699118周岁,说明青壮年为主;
SibSp上看,超过一半的人没有兄弟姐妹或配偶在船上,但也有比较多的,最多的是8个;1个以下的占了3/4,但均值是0.523008,说明有不少人有1个兄弟姐妹在船上,可能也有一些大于1个的。
Parch上看,超3/4的人没有父母或子女在船上,也有个别比较多的,最大值是6个,但均值是0.381594,说明这种情况很少,更可能是1个;
Fare上看,最小值是0,说明有没花钱上船的;3/4的人的票价低于31,但均值却是32.204208,主要原因是高票价的人虽然少,但它们的数值较大,最大的是512.329200,这些票价拉高了整体票价;
离群分析:
Age上看,没有样本表现出离群;尽管有183个缺失值,这此缺失值并不影响离群分析,或者说离群分析的时候不会把缺失值排除掉;
SibSp上看,10个样本在SibSp上均表现出离群,对比SibSp值及SibSp在训练集中的统计信息,SibSp大于等3个就离群了,在这一特征上有很多样本表现出离群,而最终离群点的确定是几个特征综合选出来的;所以并不代表删除离群点后SibSp只会小于等于2个;
Parch上看,10个样本在Parch上均表现出离群,对比Parch的具体值及Parch在训练集中的统计信息,Parch大于等于2个就离群了,同样,在这一特征上有很多样本表现出离群,而最终离群点的确定是几个特征综合选出来的;所以并不代表说明删除离群点后Parch只会小于等于1个,尤其是Parch的四分位数都为0,四分位极差也为0,这种情况下,只要大于0的值就会被视为离群样本;
Fare上看,10个样本在Fare上均表现出离群,对比Fare的具体值及Fare在训练集中的统计信息,Fare大于等于69.55时就离群了;
可以看到这种定义离群的方法还需要改进。
删除离群点:
#train = train.drop(outliers_to_drop, axis = 0).reset_index(drop=True)2.2.3 整合训练集和测试集
这一步没有特别意义,只是为了后面在有的内容统计和值的处理上更方便,也可以不整合而对每个数据集单独处理。
但是整合需要在训练集剔除离群点后再做,因为测试集是不需要剔除离群点。
train_len,train_var_num=np.shape(train)
dataset=pd.concat(objs=[train,test],axis=1).reset_index(drop=True)
#数据集缺失值用NAN填充
dataset=dataset.fillna(np.nan)2.2.4 删除离群点后整体查看数据
查看整个数据集缺失值
#整个数据集缺失值
Age 256 0.197075
Cabin 1007 0.775212
Embarked 2 0.001540
Fare 1 0.000770
Name 0 0.000000
Parch 0 0.000000
PassengerId 0 0.000000
Pclass 0 0.000000
Sex 0 0.000000
SibSp 0 0.000000
Survived 418 0.321786
Ticket 0 0.000000
dtype: int64
#训练样本缺失值
PassengerId 0 0.000000
Survived 0 0.000000
Pclass 0 0.000000
Name 0 0.000000
Sex 0 0.000000
Age 170 0.192963
SibSp 0 0.000000
Parch 0 0.000000
Ticket 0 0.000000
Fare 0 0.000000
Cabin 680 0.771850
Embarked 2 0.002270
dtype: int64从整个数据集和训练集的缺失值来看,仍然是Age和Cabin缺失值较多,并且在训练样本中的比例与整个数据集中的比例基本一致;训练中2个样本的Embarked缺失,测试集中一个Fare值缺失;整体数据集中Survived有418个缺失值是因为测试集样本类别标签已被抹除。
再重点看看训练集
print(train.info())特征详情如下:
<class 'pandas.core.frame.DataFrame'>
Int64Index: 881 entries, 0 to 890
Data columns (total 12 columns):
PassengerId 881 non-null int64
Survived 881 non-null int64
Pclass 881 non-null int64
Name 881 non-null object
Sex 881 non-null object
Age 711 non-null float64
SibSp 881 non-null int64
Parch 881 non-null int64
Ticket 881 non-null object
Fare 881 non-null float64
Cabin 201 non-null object
Embarked 879 non-null object
dtypes: float64(2), int64(5), object(5)
memory usage: 89.5+ KB
None去除离群点后训练集基本统计信息:
print(train.describe())| PassengerId | Survived | Pclass | Age | SibSp | Parch | Fare | |
|---|---|---|---|---|---|---|---|
| count | 881.000000 | 881.000000 | 881.000000 | 711.000000 | 881.000000 | 881.000000 | 881.000000 |
| mean | 446.713961 | 0.385925 | 2.307605 | 29.731603 | 0.455165 | 0.363224 | 31.121566 |
| std | 256.617021 | 0.487090 | 0.835055 | 14.547835 | 0.871571 | 0.791839 | 47.996249 |
| min | 1.000000 | 0.000000 | 1.000000 | 0.420000 | 0.000000 | 0.000000 | 0.000000 |
| 25% | 226.000000 | 0.000000 | 2.000000 | 20.250000 | 7.895800 | 0.000000 | 7.910400 |
| 50% | 448.000000 | 0.000000 | 3.000000 | 28.000000 | 0.000000 | 0.000000 | 14.454200 |
| 75% | 668.000000 | 1.000000 | 3.000000 | 38.000000 | 1.000000 | 0.000000 | 30.500000 |
| max | 891.000000 | 1.000000 | 3.000000 | 80.000000 | 5.000000 | 6.000000 | 512.329200 |
从以上的基本统计信息可以看到,去除离群点后对Age和Fare这类连续变量的分布几乎没有影响,但对SibSp和Parch的分布产生一定改变,这其实也是我们删除离群点的原因。
2.2.5 特征之间的相关性初探
目前只能对数值型特征计息相关系数,初步探寻特征之间的关联,尤其是与是否幸存的关联性。
g=sns.heatmap(train[["Survived","Age","SibSp","Parch","Pclass","Fare"]].corr(),annot=True,fmt = ".2f",cmap = "coolwarm")
plt.show()结果如下

从上图可以看到,Pclass和Survived成负相关,即3等票的幸存率要小于1等票;Fare和 Survived成正相关,即票价越高,可能越能幸存;Age,SibSp,Parch与Survived几乎不相关,但是并不意味着这些特征就没有用处,整体上的不相关可能是因为数据的“正”“负”抵消产生而看起来不相关;比如年龄,虽然整体上与Survived相关性不大,但可能局部会产生相关性,比如小孩就很容易幸存。
Age和SibSp、Parch、Pclass、Fare都有一定的相关性,因为生育有年龄特点,年龄在一定程序上也能跟经济能力相关,经济能力又跟船票等级和票价这些相关,因为这些数据展现出来的特点跟我们的生活经验是吻合的。
SibSp和Age、Parch、Fare有一定相关性。
Parch和Age、SibSp、Fare相关
Pclass和Age、Fare相关
Fare和Age、SibSp、Parch、Pclass相关,这其他成其以Fare和Pclass的相关性最大。
虽然特征之前的相关性分析对于确定特征和最终的幸存率没有直接关系,但这对于特征工程很有指导意义。
2.3 各特征与分析目标的关联分析
2.3.1 年龄Age与生存率的关系
# 特征之间的相关性初探
#####--------------------------------------------------------------------------------------------------
#年龄Age与生存率的关系
g=sns.kdeplot(train["Age"][(train["Age"].notnull())&(train["Survived"]==0)],color="Red",shade=True)
g=sns.kdeplot(train["Age"][(train["Age"].notnull())&(train["Survived"]==1)],color="Blue",shade=True,ax=g)
g.set_xlabel("Age")
g.set_ylabel("Frequency")
g=g.legend(["Not Survived","Survived"])
plt.show()结果如下图

从上图中可以看到,在幸存都中年龄较小的乘客所占比重明显要高于遇难者年龄较小的乘客所占比重,而遇难者中20几岁乘客所占比重明显要高于幸存者中20几岁乘客所占比重,另一段在另外遇难者中60-80岁乘客所占比重也要高于幸存者中60-80乘客所占比重。
所有说,尽管从Age与Survived的相关系数看,两者几乎不相关,但不代表,幸存率在年龄中没有区别。
2.3.2 性别Sex与生存率的关系
#性别Sex与生存率的关系
g=sns.barplot(data=train,x="Sex",y="Survived")
g.set_ylabel("Survival Probability")
plt.show()结果如下

从图上可以看到女性幸存率远远高于男姓幸存率,性别将是对结果的预测产生比较大的权重。
#进一步查看
print(train[["Sex","Survived"]].groupby("Sex").mean())
Survived
Sex
female 0.747573
male 0.1905592.3.3 船上兄弟姐妹或配偶数量SibSp与生存率的关系
# 船上兄弟姐妹或配偶数量SibSp与生存率的关系
g=sns.barplot(data=train,x="SibSp",y="Survived")
g.set_ylabel("Survival Probability")
plt.show()结果如下

从图上可以看到,似乎船上兄弟姐妹人数比较少的时候幸存概率更大。
2.3.4 船上父母或子女数量Parch与生存率的关系
#船上父母或子女数量Parch与生存率的关系
g=sns.barplot(data=train,x="Parch",y="Survived")
g.set_ylabel("Survival Probability")
plt.show()结果如下

从图上看,船上父母或子女数量为1到3个的时候幸存率会更高一些,没有或有很多个时幸存率会低一点。
2.3.5 船票等级Pclass与生存率的关系
#船票等级Pclass与生存率的关系
g=sns.barplot(data=train,x="Pclass",y="Survived")
g.set_ylabel("Survival Probability")
plt.show()结果如下

从图上可以明显看到不同的船票等级中幸存率是不同的,而且大致成反比例关系。
2.3.6 票价Fare与生存率的关系
#票价Fare与生存率的关系
g=sns.kdeplot(train["Fare"],color="Green",shade=True)
g=sns.kdeplot(train["Fare"][train["Survived"]==0],color="red",shade=True,ax=g)
g=sns.kdeplot(train["Fare"][train["Survived"]==1],color="blue",shade=True,ax=g)
g.set_xlabel("Fare")
g.set_ylabel("Frequency")
g=g.legend(["All","Not Survived","Survived"])
plt.show()结果如下
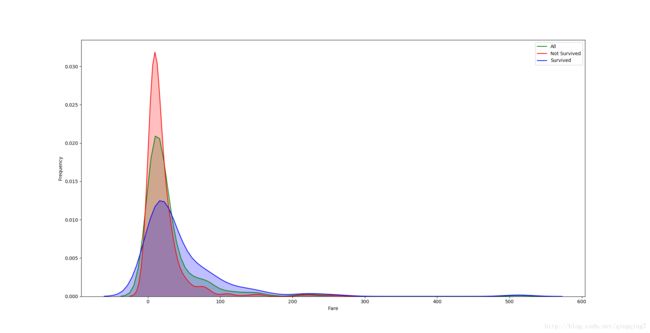
从图上可以明显看到不同票价在幸存率上的区别,主要分为两段,遇难者在低票价区的概率相对幸存者在低票价区的概率明显要高,而幸存者在高票价区的概率明显要比遇难者在高票价区的概率要高。
同时从图上可以看到票价的分布存在长尾,相对正态分布严重偏斜,这种分布在很多算法中会导致该特征产生过高的权重(高于它应该享有的待遇),对该特征进行log变换可以纠正偏斜。
我们同时在训练集和测试集进行变换,由于测试集中存在一个缺失值,可以先将该缺失值补上,这里采用中值填充。
#Fare特征的缺失值进行填充
dataset["Fare"]=dataset["Fare"].fillna(dataset["Fare"].median())#这里用到了整个数据集
test["Fare"]=test["Fare"].fillna(dataset["Fare"].median())#利用柱形图来查看log变换前Fare在整个数据集中的分布
g=sns.distplot(dataset["Fare"],color="M",label="Skewness:%.2f"%(dataset["Fare"].skew()))
g.legend(loc="best")
plt.show()结果如下:
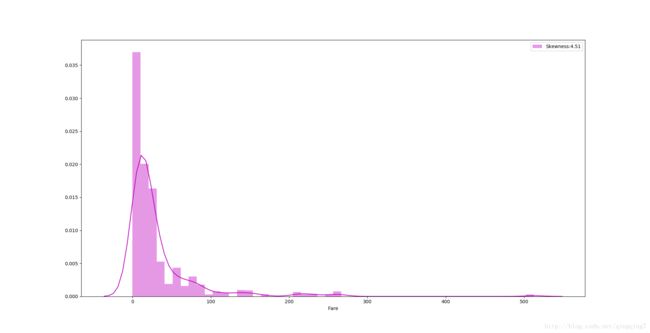
可以看到很明显的长尾,偏斜度达4.51
#下面利用log函数进行数据变换
dataset["Fare"]=dataset["Fare"].map(lambda i:np.log(i) if i>0 else 0)#map()函数具体将元素进行映射的功能
#查看变换后的数据分布
g=sns.distplot(dataset["Fare"],color="M",label="Skewness:%.2f"%(dataset["Fare"].skew()))
g.legend(loc="best")
plt.show()结果如下:
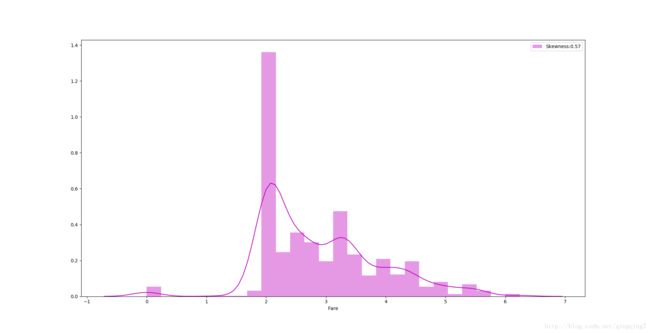
可以看到数据的偏斜得到很大程度的改善。
2.3.7 登录港口Embarked与生存率的关系
#训练集中数据存在两个缺失值,我们可以采用出现频率最大的港口来填充缺失值。因而需要先查看数据整体情况
print(dataset["Embarked"].describe())结果如下:
count 1297
unique 3
top S
freq 904
Name: Embarked, dtype: object可以看到出现频率最大的港口“S”
#缺失值填充
dataset["Embarked"]=dataset["Embarked"].fillna(dataset["Embarked"].describe().top)
train["Embarked"]=train["Embarked"].fillna(dataset["Embarked"].describe().top)
print(dataset["Embarked"].isnull().sum())
print(train["Embarked"].isnull().sum())可以看到填充后缺失值为0。
下面来查看Embarked与生存率的关系。
#查看Embarked与生存率的关系
g=sns.barplot(data=train,x="Embarked",y="Survived")
g.set_ylabel("Survival Probability")
plt.show()结果如下:

可以看到从港口“C”登船的乘客生存率最高。可能是从Cherbourg(C)港口登船的乘客比Queenstown (Q)和Southampton (S)登船的乘客买一等票的比例更高。可以进一步核查。
# 进一步查看 Pclasst和Embarked的关系
g=sns.factorplot(data=train,x="Pclass",col="Embarked",size=6,kind="count",palette="muted")
g.despine(left=True)
g = g.set_ylabels("Count")
plt.show()结果如下:

可以看到“C”港口登船的乘客中一等票的比例确实要比其他两个港口高很多。
2.3.8 船舱Cabin与生存率的关系
船舱是符号型变量,可以试着查看其变量(最好之前先查看该变量值有多少类,如果类别太多就不适合直接统计,需要进一步处理)。
print(train["Cabin"].describe())结果如下:
count 201
unique 147
top B96 B98
freq 4
Name: Cabin, dtype: object唯一值有147个,因而不能直接统计,将在后面特征工程中做处理。
2.3.8 姓名和船票信息由于是比较散乱的符号型变量不便于统计,需要做进一步处理.
3、 缺失值填充
这里包括缺失值的填充和一些符号值的数值化(符号值不需要急着数值化,后面的特征工程会进行哑变量处理,但有时为了分析的需要会提前处理)。
前面在分析相关性的时候,我们已经对Fare、Embarked缺失值进行了填充,现在对其他特征的缺失值填充。
3.1 对年龄Age进行填充
Age在整个数据集中有1007个缺失值,但通过前面的分析知道,年龄可能与生存率存在一定程度的相关性。所有直接把这一特征丢弃可能对于后面模型的预测不利。
这里可以通过找到与年龄相近的特征,然后查看相近特征对应位置的值,再找到相近特征中其他位置中与该位置值相等的位置,我们要填充的特征可能在这些位置上有值,利用这些值来对缺失值进行填充是一个可行的办法。
下面我们需要找到与Age相近的特征。
为了度量Age与性别Sex的相关性,将Age数值化(即将符号变量转换为哑变量)
#性别Sex的数值化
dataset["Sex"]=dataset["Sex"].map({"male":0,"female":1})
train["Sex"]=train["Sex"].map({"male":0,"female":1})考虑到Embarked与年龄关联不大,暂时不进行处理。这里需要考察与Age相关联的变量有Sex、SibSp、Parch、Plcass,从之前的相关性分析可以看到,票价Fare与年龄Age也存在一定相关性,但比较SibSp、Parch、Plcass与Age的相关性会小很多,而且Fare是连续型变量,要找到该特征上的两个相等值会更困难一点,当然可以做一定的近似来匹配位置。但这里没有将其放入Age的关联分析里面。
#Age与Sex的相关性分析
g=sns.factorplot(data=dataset,x="Sex",y="Age",kind="box")
plt.show()结果如下:

从上可以看到年龄的分布与性别几乎没有关系。
#Age与SibSp的相关性分析
g=sns.factorplot(data=dataset,x="SibSp",y="Age",kind="box")
plt.show()结果如下:

从图上可以看到,兄弟姐妹不同的个数下年龄的分布是不一样的,可以将SibSp的值与Age做对应来匹配Age中的缺失值。这种匹配是有误差和一定浮动范围的,但如果通过多个特征一起来
#Age与Parch的相关性分析
g=sns.factorplot(data=dataset,x="Parch",y="Age",kind="box")
plt.show()
从图上可以看到,父母子女在船上的个数不同,年龄的分布也有区分,这个也可以用来和Age做对应。
#Age与Pclass的相关性分析
g=sns.factorplot(data=dataset,x="Pclass",y="Age",kind="box")
plt.show()结果如下:

从图上可以看到,不同船票等级中年龄分布是不一样的,虽然有重叠,还是可以用来和Age做对应。
#填充Age缺失值
#获取Age缺失值索引
index_NaN_age=list(dataset["Age"][dataset["Age"].isnull()].index)
for i in index_NaN_age:
age_med=dataset["Age"].median()#如果通过关联特征找不到匹配的值,则用整个数据的中值填充
age_pred=dataset["Age"][((dataset["SibSp"]==dataset.iloc[i]["SibSp"])&(dataset["Parch"]==dataset.iloc[i]["Parch"])&(dataset["Pclass"]==dataset.iloc[i]["Pclass"]))].median()
if not np.isnan(age_pred):
dataset["Age"].iloc[i]=age_pred
else:
dataset["Age"].iloc[i]=age_med
#填充值后再看一次Age在不同Survived下的分布情况
g=sns.factorplot(data=dataset,x="Survived",y="Age",kind="violin")
plt.show()结果如下:
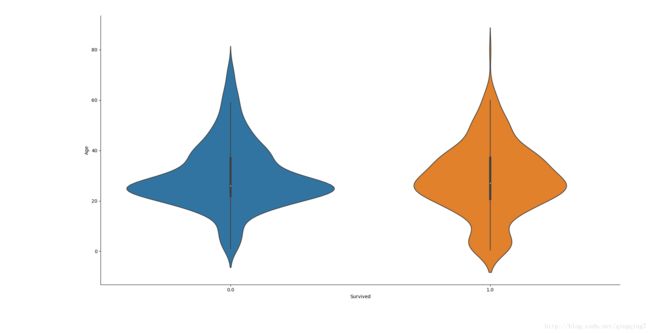
从图上还是可以看到在年经较小的人群中幸存概率会更大一点(更宽),年轻人中遇难可能性更大(中部更宽),遇难和幸存的人年龄中值其实也是有轻微差别。
利用密度图会更清楚一点。

从图上可以看到,Age填充值后,与未填充前比较,整体分布未有较大改变,在一定程度上放大了30几到40几岁在遇难和幸存之间的差异。
3.2 对Carbine进行填充
Carbine缺失值将结合特征工程一并进行。